类死循环导致进程阻塞
楔子
在实践篇一中我们看到了两个表象都是和 CPU 相关的生产问题,它们基本也是我们在线上可能遇到的这一类问题的典型案例,而实际上这两个案例也存在一个共同点:我们可以通过 Node.js 性能平台 导出进程对应的 CPU Profile 信息来进行分析定位问题,但是实际在线上的一些极端情况下,我们遇到的故障是没有办法通过轻量的 V8 引擎暴露的 CPU Profile 接口(仅部分定制的 AliNode runtime 版本支持,详见下文)来获取足够的进程状态信息进行分析的,此时我们又回到了束手无策的状态。
本章节将从一个生产环境下 Node.js 应用出现进程级别阻塞导致的不再提供服务的问题场景来给大家展示下如何处理这类相对极端的应用故障。
本书首发在 Github,仓库地址:https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,云栖社区会同步更新。
最小化复现代码
这个例子稍微有些特殊,我们首先给出生产案例的最小化复现代码,有兴趣的同学可以亲自运行一番,这样结合下文的此类问题的排查过程,能更加清晰的看到我们面对这样的问题时的排查思路,问题最小代码如下,基于 Egg.js :
'use strict';
const Controller = require('egg').Controller;class RegexpController extends Controller {async long() {const { ctx } = this;// str 模拟用户输入的问题字符串let str = '<br/> ' +' 早餐后自由活动,于指定时间集合自行办理退房手续。';str += '<br/> <br/>' +' <br/> ' +' <br/>';str += ' <br/>' +' ' +' ' +' <br/>';str += ' <br/> <br/>';str += ' ' +' ' +' 根据船班时间,自行前往暹粒机场,返回中国。<br/>';str += '如需送机服务,需增加280/每单。<br/>';const r = str.replace(/(^(\s*?<br[\s\/]*?>\*?)+|(\s*?<br[\s\/]*?>\s*?)+?$)/igm, '');ctx.body = r;}
}module.exports = RegexpController;问题应用状态
其实这个例子对应的问题场景可能很多 Node.js 开发者都遇到过,它非常有意思,我们首先来看下出现这类故障时我们的 Node.js 应用的状态。当我们收到在平台配置的 CPU 告警信息后,登录性能平台进入对应的告警应用找到出问题的 CPU 非常高的进程:然后点击 数据趋势 按钮查看此进程当前的状态信息:
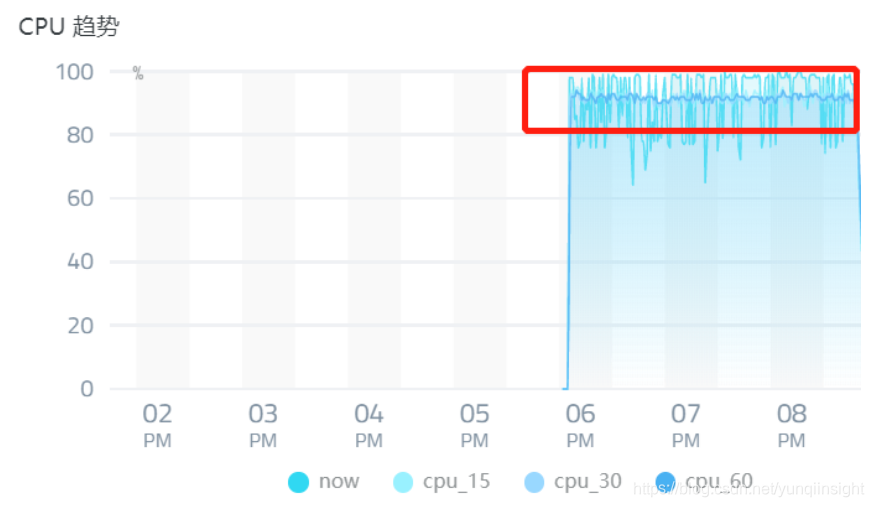
可以看到进程的 CPU 使用率曲线一直处于近乎 100% 的状态,此时进程不再响应其余的请求,而且我们通过跳板机进入生产环境又可以看到进程其实是存活的,并没有挂掉,此时基本上可以判断:此 Node.js 进程因为在执行某个同步函数处于阻塞状态,且一直卡在此同步函数的执行上。
Node.js 的设计运行模式就是单主线程,并发靠的是底层实现的一整套异步 I/O 和事件循环的调度。简单的说,具体到事件循环中的某一次,如果我们在执行需要很长时间的同步函数(比如需要循环执行很久才能跳出的
while循环),那么整个事件循环都会阻塞在这里等待其结束后才能进入下一次,这就是不推荐大家在非初始化的逻辑中使用诸如fs.readFileSync等同步方法的原因。
排查方法
这样的问题其实非常难以排查,原因在于我们没办法知道什么样的用户输入造成了这样的阻塞,所以本地几乎无法复现问题。幸运的是,性能平台目前有不止一种解决办法处理这种类死循环的问题,我们来详细看下。
I. CPU Profile
这个分析方法可以说是我们的老朋友了,因为类死循环的问题本质上也是 CPU 高的问题,因此我们只要对问题进程抓取 CPU Profile,就能看到当前卡在哪个函数了。需要注意的是,进程假死状态下是无法直接使用 V8 引擎提供的抓取 CPU Profile 文件的接口,因此工具篇章节的 正确打开 Chrome devtools 一节中提到的 v8-profiler 这样的第三方模块是无法正常工作的。
不过定制过的 AliNode runtime 采用了一定的方法规避了这个问题,然而遗憾的是依旧并不是所有的 AliNode runtime 版本都支持在类死循环状态下抓取 CPU Profile,这里实际上对大家使用的 Runtime 版本有要求:
- AliNode V3 版本需要 >= v3.11.4
- AliNode V4 版本需要 >= v4.2.1
- AliNode V1 和 V2 版本不支持
如果你的线上 AliNode runtime 版本恰好符合需求,那么可以按照前面 Node.js 性能平台使用指南 提到的那样,对问题进程抓取 3 分钟的 CPU Profile,并且使用 AliNode 定制的火焰图分析: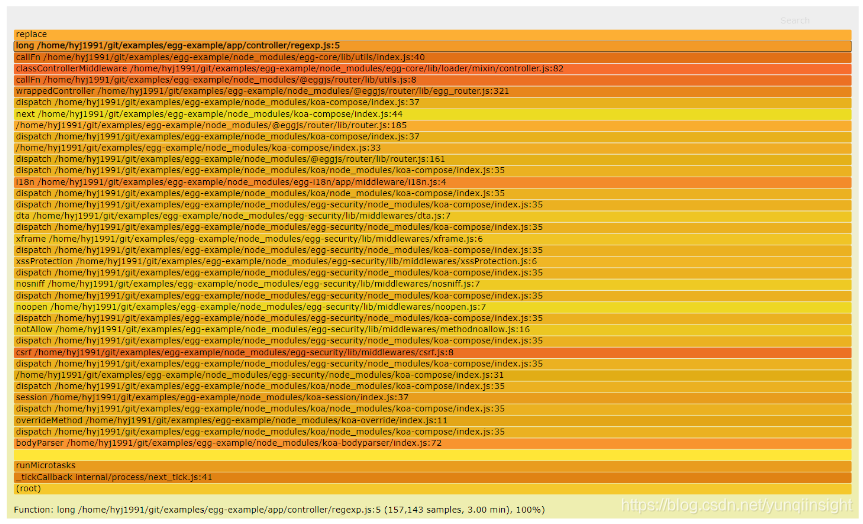
这里可以看到,抓取到的问题进程 3 分钟的 CPU 全部耗费在 long 函数里面的 replace 方法上,这和我们提供的最小化复现代码一致,因此可以判断 long 函数内的正则存在问题进行修复。
II. 诊断报告
诊断报告也是 AliNode 定制的一项导出更多更详细的 Node.js 进程当前状态的能力,导出的信息也包含当前的 JavaScript 代码执行栈以及一些其它进程与系统信息。它与 CPU Profile 的区别主要在两个地方:
- 诊断报告主要针对此刻进程状态的导出,CPU Profile 则是一段时间内的 JavaScript 代码执行状态
- 诊断报告除了此刻 JavaScript 调用栈信息,还包含了 Native C/C++ 栈信息、Libuv 句柄和部分操作系统信息
当我们的进程处于假死状态时,显然不管是一段时间内还是此时此刻的 JavaScript 执行状况,必然都是卡在我们代码中的某个函数上,因此我们可以使用诊断报告来处理这样的问题,当然诊断报告功能同样也对 AliNode runtime 版本有所要求:
- AliNode V2 版本需要 >= v2.5.2
- AliNode V3 版本需要 >= v3.11.8
- AliNode V4 版本需要 >= v4.3.0
- AliNode V1 版本不支持
- 且要求:Agenthub/Egg-alinode 依赖的 Commandx 版本 >= v1.5.3
如果你使用的 AliNode runtime 版本符合要求,即可进入平台应用对应的实例信息页面,选中问题进程:
然后点击 诊断报告 即可生成此刻问题进程的状态信息报告:

诊断报告虽然包含了很多的进程和系统信息,但是其本身是一个相对轻量的操作,故而很快就会结束,此时继续点击 转储 按钮将生成的诊断报告上传至云端以供在线分析展示:
继续点击 分析 按钮查看 AliNode 定制的分析功能,展示结果如下: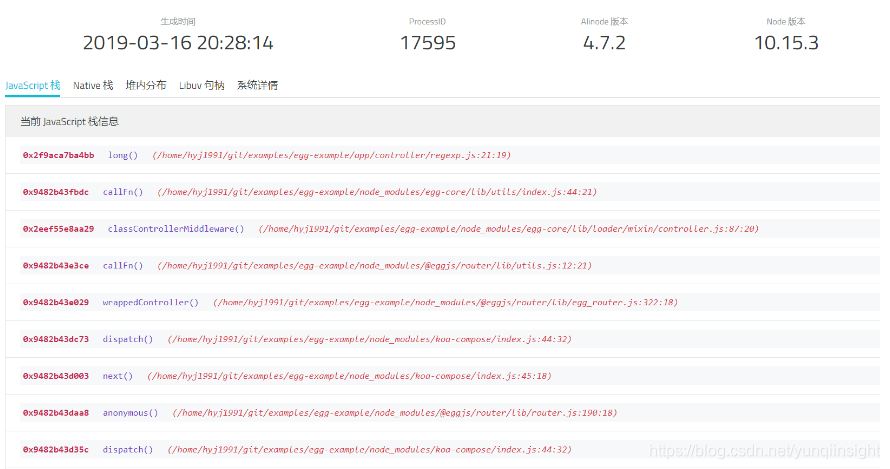
结果页面上面的概览信息比较简单,我们来看下 JavaScript 栈 页面的内容,这里显然也告诉我们当前的 JS 函数卡在 long 方法里面,并且比 CPU Profile 更加详细的是还带上了具体阻塞在 long 方法的哪一行,对比我们提供给大家的最小复现代码其实就是执行 str.replace 这一行,也就是问题的正则匹配操作所在的地方。
III. 核心转储分析
其实很多朋友看到这里会有疑惑:既然 CPU Profile 分析和诊断报告已经能够找到问题所在了,为什么我们还要继续介绍相对比较重的核心转储分析功能呢?
其实道理也很简单,不管是类死循环状态下的 CPU Profile 抓取还是诊断报告功能的使用,都对问题进程的 AliNode runtime 版本有所要求,而且更重要的是,这两种方法我们都只能获取到问题正则的代码位置,但是我们无法知道什么样的用户输入在执行这样的正则时会触发进程阻塞的问题,这会给我们分析和给出针对性的处理造成困扰。因此,这里最后给大家介绍对 AliNode runtime 版本没有任何要求,且能拿到更精准信息的核心转储分析功能。
首先按照预备章节的核心转储一节中提到的 手动生成 Core dump 文件的方法,我们对问题进程进行 sudo gcore <pid> 的方式获取到核心转储文件,然后在平台的详情页面,将鼠标移动到左边 Tab 栏目的 文件 按钮上,可以看到 Coredump 文件 的按钮:
点击后可以进入 Core dump 文件列表页,然后点击上方的 上传 按钮进行核心转储文件的上传操作:
这里需要注意的是,请将 Core dump 文件以 .core 结尾重命名,而对应的 Node 可执行文件以 .node 结尾重命名,推荐的命名方式为 <os info>-<alinode/node>-<version>.node,方便以后回顾,比如 centos7-alinode-v4.7.2.node 这种。最后 Core dump 文件和 Node 可执行文件之间必须是 一一对应 的关系。这里一一对应指的是:这份 Core dump 文件必须是由这个 Node 可执行文件启动的进程生成的,如果这两者没有一一对应,分析结果往往是无效信息。
因为 Core dump 文件一般来说都比较大,所以上传会比较慢,耐心等待至上传完毕后,我们就可以使用 AliNode 定制的核心转储文件分析功能进行分析了,点击 分析 按钮即可:

此时我们在新打开的分析结果页面可以看到如下的分析结果展示信息:
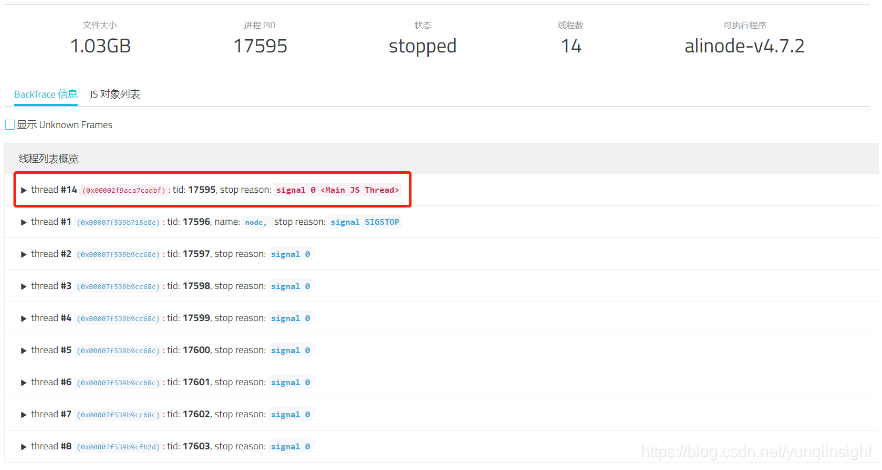
这个页面的各项含义在工具篇的 Node.js 性能平台使用指南的 [最佳实践——核心转储分析]() 一节已经解释过,这里不再赘述,这里直接展开 JavaScript 栈信息:
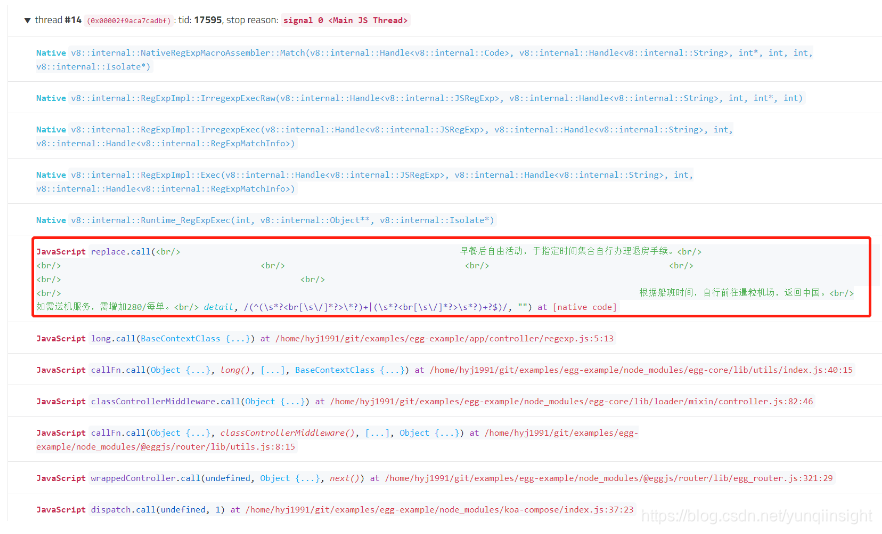
这里可以看到得到的结论和前面的 CPU Profile 分析以及诊断报告分析一致,都能定位到提供的最小复现代码中的 long 方法中的异常正则匹配,但是核心转储文件分析比前面两者多了导致当前 Node.js 进程产生问题的异常字符串: "<br/> 早餐后自由活动,于指定时间集合自行办理退房手续。<br/> <br/> <br/> <br/> <br/> <br/> <br/> <br/> 根据船班时间,自行前往暹粒机场,返回中国。<br/>如需送机服务,需增加280/每单。<br/>" ,有了这个触发正则执行异常的问题字符串,我们无论是构造本地复现样例还是进一步分析都有了重要的信息依靠。
分析问题
上一节中我们采用了 Node.js 性能平台提供的三种不同的方式分析定位到了线上应用处于假死状态的原因,这里来简单的解释下为什么字符串的正则匹配会造成类死循环的状态,它实际上异常的用户输入触发了 正则表达式灾难性的回溯,会导致执行时间要耗费几年甚至几十年,显然不管是那种情况,单主工作线程的模型会导致我们的 Node.js 应用处于假死状态,即进程依旧存活,但是却不再处理新的请求。
关于正则回溯的原因有兴趣的同学可以参见 小心别落入正则回溯陷阱 一文。
结尾
其实这类正则回溯引发的进程级别阻塞问题,本质上都是由于不可控的用户输入引发的,而 Node.js 应用又往往作为 Web 应用直接面向一线客户,无时不刻地处理千奇百怪的用户请求,因此更容易触发这样的问题。
相似的问题其实还有一些代码逻辑中诸如 while 循环的跳出条件在一些情况下失效,导致 Node.js 应用阻塞在循环中。之前我们就算知道是进程阻塞也难以方便的定位到具体的问题代码以及产生问题的输入,现在借助于 Node.js 性能平台 提供的核心转储分析能力,相信大家可以比较容易地来解决这样的问题。
原文链接
本文为云栖社区原创内容,未经允许不得转载。


作为触发器来触发函数计算)

)



| 博文精选)










