概述
etcd是一个开源的分布式的kv存储系统, 最近刚被cncf列为沙箱孵化项目。etcd的应用场景很广,很多地方都用到了它,例如kubernetes就用它作为集群内部存储元信息的账本。本篇文章首先介绍我们优化的背景,为什么我们要进行优化, 之后介绍etcd内部存储系统的工作方式,之后介绍本次具体的实现方式及最后的优化效果。
优化背景
由于阿里巴巴内部集群规模大,所以对etcd的数据存储容量有特殊需求,之前的etcd支持的存储大小无法满足要求, 因此我们开发了基于etcd proxy的解决方案,将数据转储到了tair中(可类比redis))。这种方案虽然解决了数据存储容量的问题,但是弊端也是比较明显的,由于proxy需要将数据进行搬移,因此操作的延时比原生存储大了很多。除此之外,由于多了tair这个组件,运维和管理成本较高。因此我们就想到底是什么原因限制了etcd的存储容量,我们是否可以通过技术手段优化解决呢?
提出了如上问题后我们首先进行了压力测试不停地像etcd中注入数据,当etcd存储数据量超过40GB后,经过一次compact(compact是etcd将不需要的历史版本数据删除的操作)后发现put操作的延时激增,很多操作还出现了超时。监控发现boltdb内部spill操作(具体定义见下文)耗时显著增加(从一般的1ms左右激增到了8s)。之后经过反复多次压测都是如此,每次发生compact后,就像世界发生了停止,所有etcd读写操作延时比正常值高了几百倍,根本无法使用。
etcd内部存储工作原理
etcd存储层可以看成由两部分组成,一层在内存中的基于btree的索引层,一层基于boltdb的磁盘存储层。这里我们重点介绍底层boltdb层,因为和本次优化相关,其他可参考上文。
etcd中使用boltdb作为最底层持久化kv数据库,boltdb的介绍如下:
Bolt was originally a port of LMDB so it is architecturally similar.
Both use a B+tree, have ACID semantics with fully serializable transactions, and support lock-free MVCC using a single writer and multiple readers.
Bolt is a relatively small code base (<3KLOC) for an embedded, serializable, transactional key/value database so it can be a good starting point for people interested in how databases work。如上介绍,它短小精悍,可以内嵌到其他软件内部,作为数据库使用,例如etcd就内嵌了boltdb作为内部存储k/v数据的引擎。
boltdb的内部使用B+ tree作为存储数据的数据结构,叶子节点存放具体的真实存储键值。它将所有数据存放在单个文件中,使用mmap将其映射到内存,进行读取,对数据的修改利用write写入文件。数据存放的基本单位是一个page, 大小默认为4K. 当发生数据删除时,boltdb不直接将删掉的磁盘空间还给系统,而是内部将他先暂时保存,构成一个已经释放的page池,供后续使用,这个所谓的池在boltdb内叫freelist。例子如下:
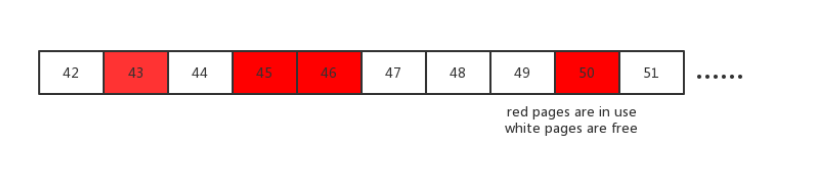
红色的page 43, 45, 46, 50 页面正在被使用,而page 42, 44, 47, 48, 49, 51 是空闲的,可供后续使用。
如下etcd监控图当etcd数据量在50GB左右时,spill 操作延时激增到了8s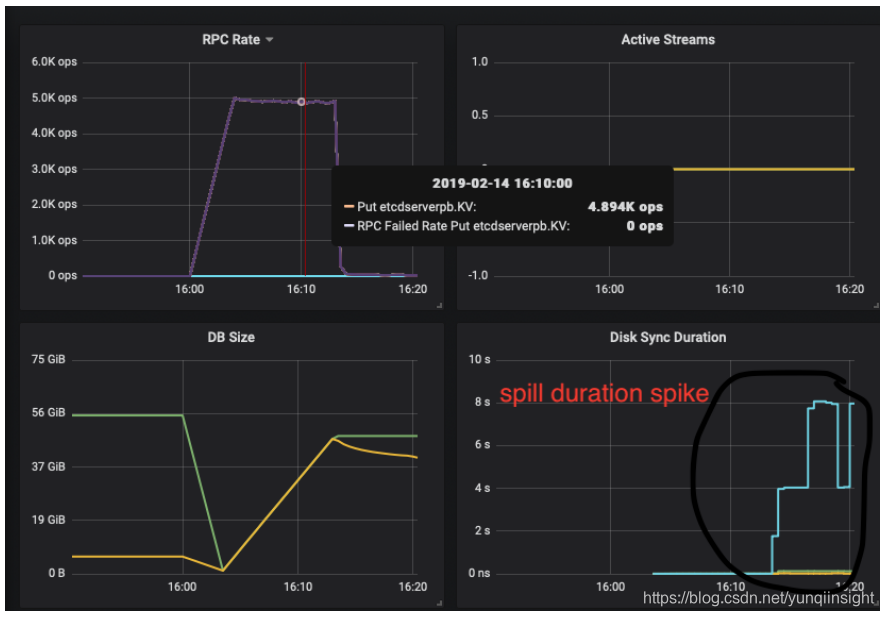
问题分析
由于发生了用户数据的写入, 因此内部B+ tree结构会频繁发生调整(如再平衡,分裂合并树的节点)。spill操作是boltdb内部将用户写入数据commit到磁盘的关键一步, 它发生在树结构调整后。它释放不用的page到freelist, 从freelist索取空闲page存储数据。
通过对spill操作进行更深入细致的调查,我们发现了性能瓶颈所在, spill操作中如下代码耗时最多:
// arrayAllocate returns the starting page id of a contiguous list of pages of a given size.
// If a contiguous block cannot be found then 0 is returned.
func (f *freelist) arrayAllocate(txid txid, n int) pgid {...var initial, previd pgidfor i, id := range f.ids {if id <= 1 {panic(fmt.Sprintf("invalid page allocation: %d", id))}// Reset initial page if this is not contiguous.if previd == 0 || id-previd != 1 {initial = id}// If we found a contiguous block then remove it and return it.if (id-initial)+1 == pgid(n) {if (i + 1) == n {f.ids = f.ids[i+1:]} else {copy(f.ids[i-n+1:], f.ids[i+1:]) # 复制f.ids = f.ids[:len(f.ids)-n]}...return initial}previd = id}return 0
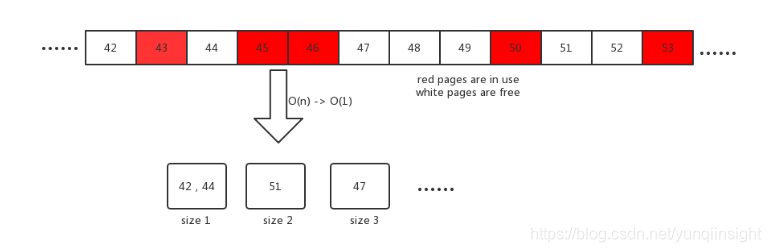
}之前etcd内部内部工作原理讲到boltdb将之前释放空闲的页面存储为freelist供之后使用,如上代码就是freelist内部page再分配的函数,他尝试分配连续的n个page页面供使用,返回起始页page id。 代码中f.ids是一个数组,他记录了内部空闲的page的id。例如之前上图页面里f.ids=[42,44,47,48,49,51]
当请求n个连续页面时,这种方法通过线性扫描的方式进行查找。当遇到内部存在大量碎片时,例如freelist内部存在的页面大多是小的页面,比如大小为1或者2,但是当需要一个size为4的页面时候,这个算法会花很长时间去查找,另外查找后还需调用copy移动数组的元素,当数组元素很多,即内部存储了大量数据时,这个操作是非常慢的。
优化方案
由上面的分析, 我们知道线性扫描查找空页面的方法确实比较naive, 在大数据量场景下很慢。前yahoo的chief scientist Udi Manber曾说过在yahoo内最重要的三大算法是 hashing, hashing and hashing!(From algorithm design manual)
因此我们的优化方案中将相同大小的连续页面用set组织起来,然后在用hash算法做不同页面大小的映射。如下面新版freelist结构体中的freemaps数据结构。
type freelist struct {...freemaps map[uint64]pidSet // key is the size of continuous pages(span), value is a set which contains the starting pgids of same sizeforwardMap map[pgid]uint64 // key is start pgid, value is its span sizebackwardMap map[pgid]uint64 // key is end pgid, value is its span size...
}
除此之外,当页面被释放,我们需要尽可能的去合并成一个大的连续页面,之前的算法这里也比较简单,是个是耗时的操作O(nlgn).我们通过hash算法,新增了另外两个数据结构forwardMap和backwardMap, 他们的具体含义如下面注释所说。
当一个页面被释放时,他通过查询backwardMap尝试与前面的页面合并,通过查询forwardMap尝试与后面的页面合并。具体算法见下面mergeWithExistingSpan函数。
// mergeWithExistingSpan merges pid to the existing free spans, try to merge it backward and forward
func (f *freelist) mergeWithExistingSpan(pid pgid) {prev := pid - 1next := pid + 1preSize, mergeWithPrev := f.backwardMap[prev]nextSize, mergeWithNext := f.forwardMap[next]newStart := pidnewSize := uint64(1)if mergeWithPrev {//merge with previous spanstart := prev + 1 - pgid(preSize)f.delSpan(start, preSize)newStart -= pgid(preSize)newSize += preSize}if mergeWithNext {// merge with next spanf.delSpan(next, nextSize)newSize += nextSize}f.addSpan(newStart, newSize)
}
新的算法借鉴了内存管理中的segregated freelist的算法,它也使用在tcmalloc中。它将page分配时间复杂度由O(n)降为O(1), 释放从O(nlgn)降为O(1),优化效果非常明显。
实际优化效果
以下测试为了排除网络等其他原因,就测试一台etcd节点集群,唯一的不同就是新旧算法不同, 还对老的tair作为后端存储的方案进行了对比测试. 模拟测试为接近真实场景,模拟100个客户端同时向etcd put 1百万的kv对,kv内容随机,控制最高5000qps,总计大约20~30GB数据。测试工具是基于官方代码的benchmark工具,各种情况下客户端延时如下
旧的算法时间
有一些超时没有完成测试,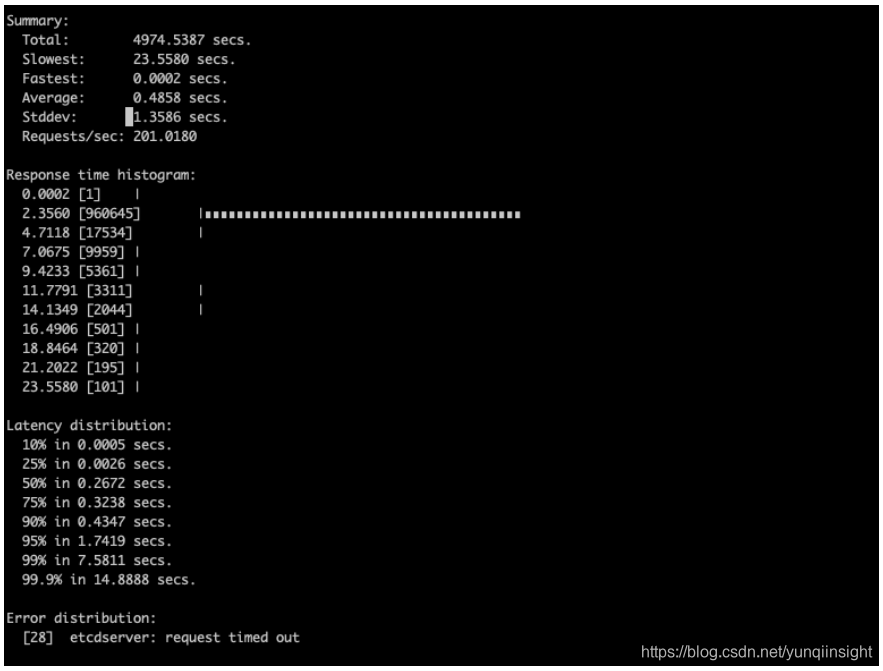
新的segregated hashmap
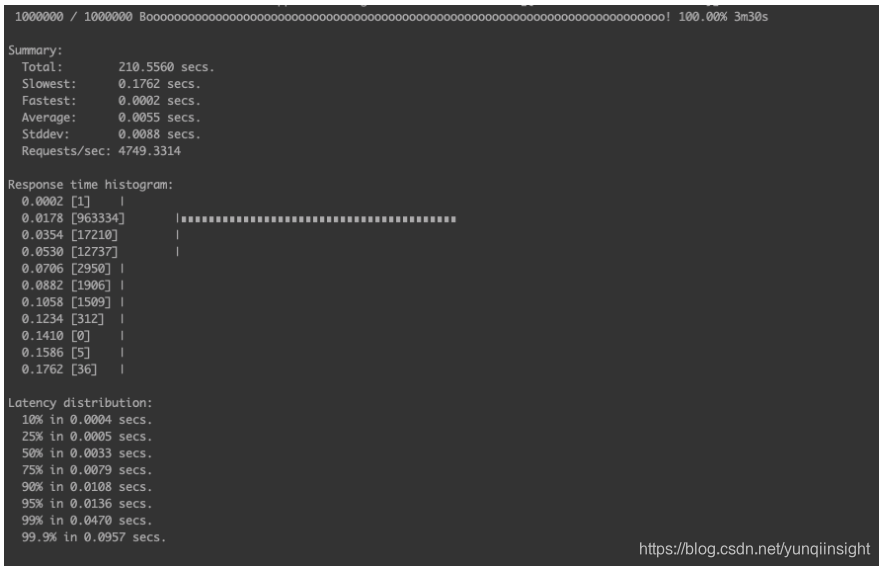
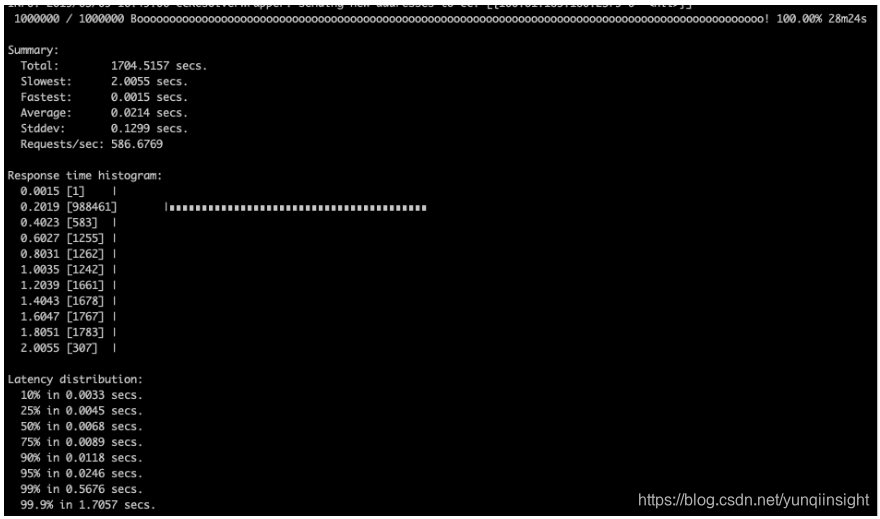
etcd over tail 时间
| 方案 | 完成耗时 | 性能提升倍数 |
|---|---|---|
| 新的hashmap算法 | 210s | 1x |
| 旧array算法 | 4974s | 24x |
| etcd over tair | 1705 | 8x |
在数据量更大的场景下,并发度更高的情况下新算法提升倍数会更多。
总结
这次优化将boltdb中freelist分配的内部算法由O(n)降为O(1), 释放部分从O(nlgn)降为O(1), 解决了在超大数据规模下etcd内部存储的性能问题,使etcd存储100GB数据时的读写操作也像存储2GB一样流畅。并且这次的新算法完全向后兼容,无需做数据迁移或是数据格式变化即可使用新技术带来的福利!
目前该优化经过2个多月的反复测试, 上线使用效果稳定,并且已经贡献到了开源社区link,在新版本的boltdb和etcd中,供更多人使用。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















