蚂蚁金服过去十五年,重塑支付改变生活,为全球超过十二亿人提供服务,这些背后离不开技术的支撑。在2019杭州云栖大会上,蚂蚁金服将十五年来的技术沉淀,以及面向未来的金融技术创新和参会者分享。我们将其中的优秀演讲整理成文并将陆续发布在“蚂蚁金服科技”公众号上,本文为其中一篇。

自从今年4月份开源以来,SQLFlow受到了业界和社区的广泛关注。SQLFlow项目以社区主导,与外部开发者进行合作与共建的形式运营。滴滴出行作为蚂蚁金服当前共建回馈开源社区的重要合作伙伴之一,从自己的场景实际应用出发将SQLFlow进行了落地应用。
9月27日,滴滴数据科学部首席数据科学家谢梁和蚂蚁金服研究员王益在云栖大会上就SQLFlow的产品形态、产品使命愿景、在滴滴的落地应用、未来前景展望等几个部分给大家进行了详细的介绍。
从SQLFlow的愿景说起
如果你还对SQLFlow还不了解,可以阅读我们之前的介绍文章,或者查看项目官网:
https://sqlflow.org
简单理解的话,SQLFlow = SQL + AI,你可以把SQLFlow看做一个编译器,它可以把经过扩展的SQL语句翻译成AI引擎能够运行的代码。
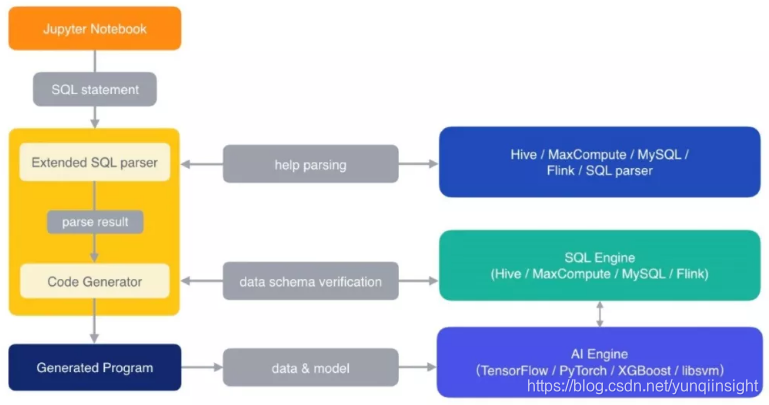
SQLFlow的愿景是:推进人工智能大众化、普及化,也就是只要懂商业逻辑就能用上人工智能, 让最懂业务的人也能够自由地使用人工智能。
传统建模流程中,通常由业务专家(分析师、运营专家、产品专家等)提出具体需求,通过产品、数据科学、算法、开发、测试等多个角色配合完成具体建模任务。很多情况下,由于大家的专业背景不同,如业务专家不懂AI的原理细节、算法工程师也很难理解业务逻辑的巧妙之处,就会导致沟通成本过高。而即使是基于上述条件完成的模型,往往也不能抽象成应用更广泛的通用模型。
如果要让SQLFlow解决前面的问题,就涉及到三个核心要素,第一是数据描述商业逻辑,这个在SQLFlow语句上已经得到了比较好的实现;第二,用AI来赋能深度的数据分析。当前数据分析师的大量工作是获取原始数据,然后把它们整理加工成为可以对业务现状进行描述和评估的指标,但是数据分析师的核心工作绝不仅仅只是数据的简单汇总和加工,他们需要花更多的时间或者发展更好的能力去建立预测模型,进而解读数据并研究数据的内在关系,SQLFlow赋予了他们极强的能力,帮助他们对这些数据进行深度的挖掘,从而正确地解读数据背后用户的行为以及更好抽象出合理的行为规律或商业逻辑;最后,它必须是一个非常易用的工具,让使用者的学习成本或者学习门槛降到最低。
SQLFlow的潜在用户包括了运营专家、商业分析师和数据分析师,他们非常了解业务,只需要直接去调用对应的AI解决方案,一句话、一段SQL的代码就完成一次建模任务,这样的流程只需要业务专家通过SQL同SQLFlow打交道,降低了沟通成本、沟通损耗。建模成本降低,业务专家也可以进行更加激进的探索和更富想象力的尝试;同时高价值的代码和抽象出的智慧会以模型的具象形式沉淀在SQLFlow模型池里面。例如,一个西宁的运营专家看到北京的分析师频繁地调用这个模型,他也可以去调用这个模型进行迁移学习解决本地区的类似问题,因此他的建模成本和经验成本都会进一步降低,知识的传播在SQLFlow的帮助下很容易就能打破地域和行业的限制。
SQLFlow都用在了哪里?

SQLFlow已经在蚂蚁金服和滴滴得到了大规模的落地并得到了较好的反馈。在滴滴,它被用在商业智能业务场景,在蚂蚁金服,SQLFlow则被用在精准营销场景,这些场景都符合业务专家需求灵活多变的情况。SQLFlow也会探索更丰富的使用场景。
滴滴是如何用SQLFlow的
在应用SQLFlow的时候,滴滴首先需要解决的问题就是与数据的整合。
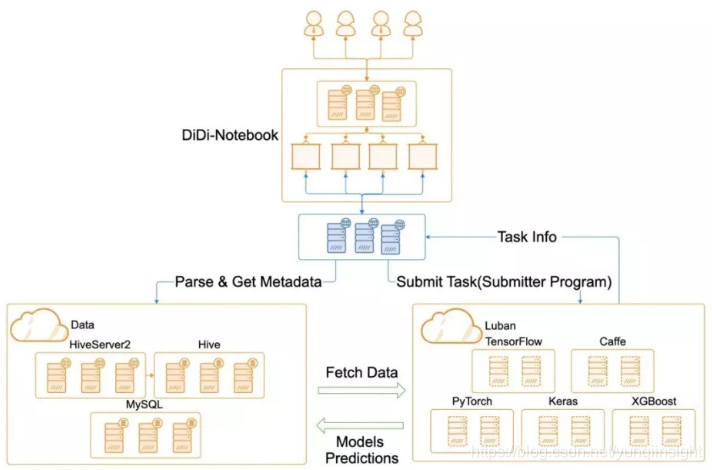
滴滴的大数据平台基于Hive进行打造,SQLFlow主要与Hive集群进行对接。图上蓝色的部分就是SQLFlow服务器,围绕服务器有三个部分,第一部分在上面是滴滴的Notebook,所有的数据分析师和运营专家都在Notebook上操作和编写SQL代码,然后通过SQLFlow服务器连接数据服务器。
下面SQLFlow的服务器会和两个部分产生交集,左下角是数据服务器,它会把SQL代码解析为一系列的Parse代码,并验证其中的数据部分。右下角是神经网络库,比如说支持的有keras、XGBoost等等模型库,这些模型库拿到Parse代码之后会根据解析出来的Date到数据库里面取相应的数据。
数据服务器和神经网络库之间是双向互通的,也就说模型会去取数据进行训练或预测,那预测后的结果以及训练得到的模型,会返回到这个数据服务器里存储,供下一次使用,或者供运营专家做精准营销的时候筛选。最后任务的信息也会通过模型库返回到SQLFlow的服务器里面,在滴滴的Notebook里进行交互。
滴滴首席数据科学家谢梁从滴滴和蚂蚁合作开源的模型出发,阐述了在滴滴的业务场景中如何应用SQLFlow来帮助业务提升效能,其中包括:
- 利用DNN神经网络分类模型在精细化补贴券发放中的应用;
- 通过SHAP+XGBoost可解释模型洞悉用户行为影响因素及影响力度,从而帮助运营人员定位运营点;
- 使用带聚类分析的自编码器分析司机运力的时间分布,挖掘司机行为模式。
下面分别进行介绍。
用SQLFlow进行有监督分类建模
分类模型是快捷的分类器,是机器学习的一个重要方向。这里介绍滴滴的一个优惠券目标乘客识别预测的案例。

滴滴的优惠券是怎么选出来的呢?后台运营的专家会根据乘客历史打车的行为信息看来发券,比如说要对吃喝玩乐的场景进行促销,就会看什么样的用户在什么样的场景下更有可能去进行吃喝玩乐相关的消费,这时候定向给乘客发送优惠券,最大可能地转换出行需求,从而创造用户价值和收益。
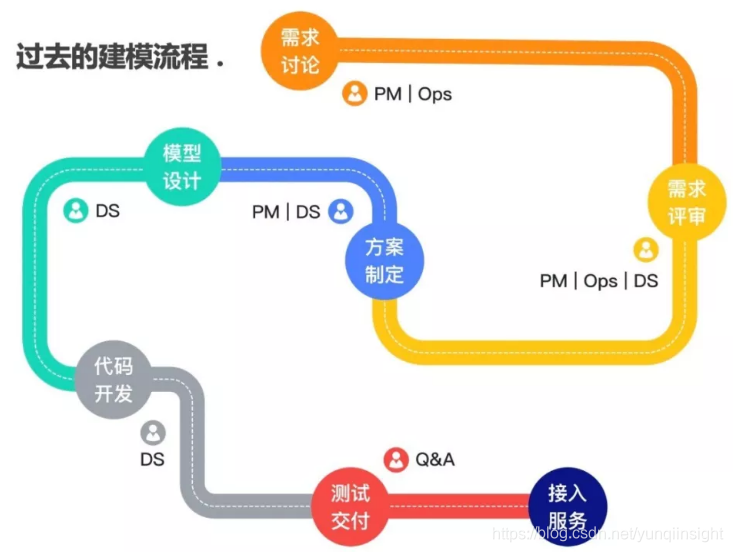
在以前,完成以上整个建模的过程非常繁琐的,既需要有大量的跨团队配合,又需要有不同领域专家的时间投入,当整个建模全流程走完并花费很长时间训练好模型后,投放的最佳时机已经错过,所以业务的高速增长和发展对于公司数据和业务部门的相互合作以及模型的研发上线速度和流程都提出了更高的要求。
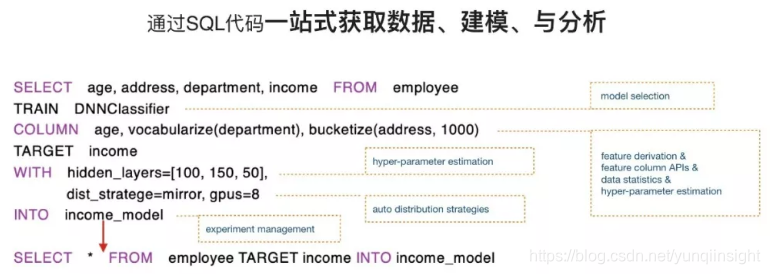
用SQLFlow刚好可以满足这一需求。分析师只需要把待分类的用户数据告诉SQLFlow,就可以去做一个很有效的分类选择器,中间特征的筛选以及特征的组合都可以通过bucketize或者vocabularize做一个处理,最后把训练得到的模型输出到一个叫做income_model的数据集里面。上图的一些方框所表示的代码甚至进一步简化,只用最后一行的代码就可以完成整个模型的训练过程。这样一来,对分析师来讲几乎不存在学习曲线。
用SQLFlow做黑盒模型解释
更多的时候,对于数据分析师和运营专家来讲,只知道what是不够的,更需要知道why和how。例如,当滴滴的分析师进行乘客活跃度影响因素分析的时候,我们需要针对乘客过去的打车行为来建立预测乘客活跃度的模型,以分析影响他们打车的因素有哪些,从而把这些因素都嵌入到整个营销方案的定制,实现更好的用户留存。
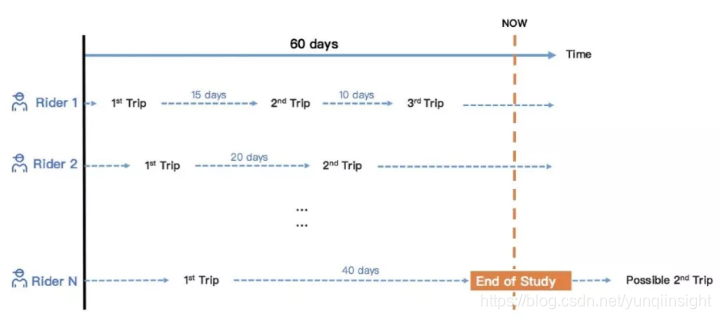
在这个案例中,我们需要确定用户当前处在生命周期的阶段,包括注册天数、等级、行为分等等;从用户对于出行需求性上,我们需要知道这个用户历史上打车时所接受的预估里程以及平台累积里程;此外,用户的乘车体验也是我们必须要了解的,包括用户需求次数、接驾距离、应答时长、是否有排队等等。由于这些数据量纲和业务含义的差异化,导致运营同学很难通过简单的数据汇总和前后比分析去决定哪个因素在哪些业务场景下更能影响用户的发单和留存,因此我们必须借助模型的方式对这些信息进行抽象后再将信息的重要程度排序后显现出来。
在滴滴,我们使用SQLFlow中的SQL语言提取出用户过去一段时间内的出行数据,通过可解释的扩展让SQL调用DNN,然后采用SHAP + XGBoost解读模型洞悉用户行为影响因素并量化影响力度。经过一系列的模型建模之后,可以看到对于前面所列的各种信息,在每一个用户身上都打了一个点,纵轴是每一个维度,横轴是feature value值。通过这张图可以找到对于每个人在每个维度上的影响力是什么样的。所有的信息可以输出一个大的Hive表,运营专家可以根据这些表格来找到运营场景,提升运营效率。无论是生成SHAP value还是查询Hive表,利用SQLFlow,运营专家用简单的SQL语句就可以实现通常一个高度专业化的AI算法工程师才能处理的复杂建模任务。
用SQLFlow进行无监督聚类
第三个例子是无监督聚类,这里的实际场景是司机出车的偏好分层,也就是根据司机一段时间内的出车时长特征,对司机群体进行聚类,识别出不同类别的司机,为后续策略投放和管理提供信息。
滴滴需要根据司机出车习惯来合理安排运力,平台的活跃司机数以万计,如何对这些司机进行打分或者区别呢?这是比较难的问题。
以前滴滴根据历史的经验和常识认知,主观地对司机群体进行分类 – 即每天工作8小时以上的司机叫做高运力司机,8小时以下就叫中等运力司机。亦或是用基于规则来进行划分,比如根据过去30天在线时长多少,是否有指派等一系列非常复杂的规则,把司机分成了五类,变成高运力司机、活跃中等运力司机、低频中等运力司机、活跃低运力司机、偶发出车司机等等。但这样做有很多问题。因为同是高运力中等运力司机,但他们在不同时空的出车习惯,出车时间分布都是具有很大差异的,这也意味着我们需要在不同时段对运力的刻画做到更细的颗粒度。
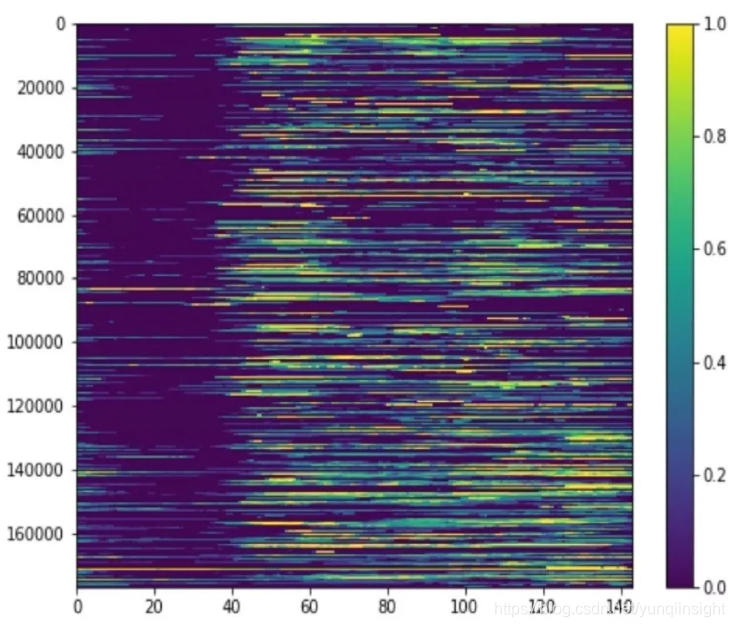
上图代表了一天中一个区域内16万司机的出车时长分布,横轴是一天24小时的144个10分钟,颜色表示该时段经过标准化的出车时长,颜色越鲜艳代表出车时长越长。也许你也发现了,上图光谱比较杂乱,我们很难看出司机出车的规律。
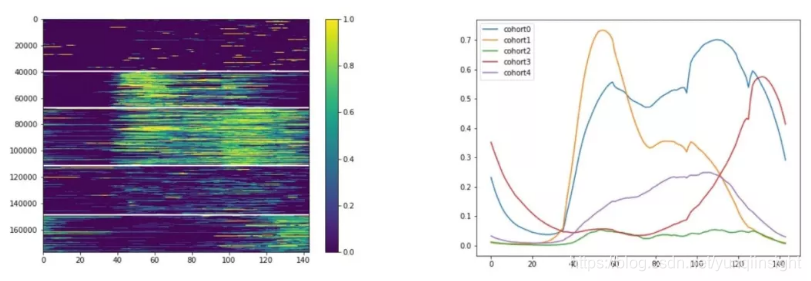
在SQLFlow中通过AutoEncoder-based Clustering实现聚类
为了解决这个难题,滴滴的数据科学家们利用SQLFlow中的Deep Learning Technique中的AutoEncoder将司机的出车时长进行了非监督聚类,在这个模型中自动的把16万的司机出车模式分成了五大类,经过聚类后,具有相同行为模式的司机被很好划分在了一组,组与组之间具有非常明显的区分。
可以看出,大约有4万个司机就是真正的偶发出车司机,基本上不出车,出车以后基本上也是做一单就不做的司机;第二类司机是编号总4万到6万左右的,他们是典型的高峰出车司机,有一部分则是偏向于在晚高峰出车;第三类司机就是真正的所谓高运力司机,因为他们从早上做单到晚上,所以这些司机更有可能是把滴滴作为了一个职业;第四类司机是低频中等司机,他们偶尔做一单,虽然比第一类司机接单更多一些,但出车也没有固定的规律;最后一类就是夜猫子司机,他们从半夜出车凌晨回家睡觉,这群司机是夜间运力的有力补充。
通过数据挖掘出来的这些不同出车习惯偏好的司机群体, 怎么样设计合理的激励和运营策略去合理地部署运力满足乘客需求,就是司机运营同学平时最重要的工作。从前非常复杂和繁琐的工作,现在只需要通过简单的SQL代码就能够有效地帮助运营专家把运力的特征和全天的运力结构分解开来,从而大大提高运营策略的成功率和业务人员工作效率。
从前面这三个例子可以看出,SQLFlow是真正的数智驱动产品,能够以最简单的逻辑赋能业务同学解决最复杂的业务问题。
SQLFlow的价值与未来
我们知道,在计算机科学里,计算单元越接近数据单元,效率越高。SQLFlow的意义就在于它也想要实现同样的目的,让人工智能计算单元与业务主体合体,实现生产力提升。
这个方向的终点,就是所想即所得。

钢铁侠在构建自己的新反应堆时,他只需要去抓取这些影像,抓出来放到系统里看看合不合适,不适合就放回去换另外一个,其实SQLFlow已经无限接近于这种状态了,这也是我们认为SQLFlow所需要达到的终态。
运营专家不需要花时间精力去学习AI模型的搭建,而是应该更大得利用自己的业务专长明确预测标的以及数据输入,尝试不同模型,通过SQLFlow探索解决方案,实现了所想即所得。
最后,SQLFlow是连接业务分析人员和AI的鹊桥,更是链接数据与洞察的鹊桥,未来,我们期待无数的分析师能够走过这个鹊桥,与科学和智慧相遇。
iPhone 11 Pro、卫衣、T恤等你来抽,马上来试试手气 https://www.aliyun.com/1111/2019/m-lottery?utm_content=g_1000083877
原文链接
本文为云栖社区原创内容,未经允许不得转载。






)







)




