为什么要做这个工具?
由于阿里云上的容器服务 ACK 在使用成本、运维成本、方便性、长期稳定性上大大超过公司自建自维护 Kubernets 集群,有不少公司纷纷想把之前自己维护 Kubernetes 负载迁移到阿里云 ACK 服务上。在迁移过程中,往往会碰到一个不大不小的坑:那就是怎么把已有的容器镜像平滑的迁移到阿里云镜像服务 ACR 上。这个问题看起来非常简单,如果只有三五个镜像,只要做一次 docker pull/docker push 就能完成,但实际生产中涉及到成千上百个镜像,几 T 的镜像仓库数据时,迁移过程就变的耗时非常漫长,甚至丢失数据。
阿里云云原生应用平台的工程师——也就是我们,发现这是一个通用的需求,用户会在各种容器镜像仓库之间做迁移,或者进一步,期望有同步复制的能力,所以我们研发了 image-syncer 这个项目来支持迁云,并同时开源给业界大众,用来解决通用的容器镜像批量迁移/同步的问题。
这个工具在实际生产中,已经帮助了多家客户进行镜像迁移,其中最大镜像仓库的总量达到 3T 以上,同步时能跑满机器带宽,进行同步任务的机器磁盘容量没有要求。
image-syncer 简介
如上所述,在 k8s 集群迁移场景中,镜像仓库之间进行镜像迁移/同步是基本需求,而使用 docker pull/push 结合脚本的传统方式进行镜像同步,有如下几个局限性:
- 依赖磁盘存储,需要及时进行本地镜像的清理,并且落盘造成多余的时间开销,难以胜任生产场景中大量镜像的迁移
- 依赖 docker 程序,docker daemon 对 pull/push 的并发数进行了严格的限制,无法进行高并发同步
- 一些功能只能通过 HTTP api 进行操作,单纯使用 docker cli 无法做到,使脚本变得复杂
image-syncer 的定位是一个简单、易用的批量镜像迁移/同步工具,支持几乎所有目前主流的基于 docker registry V2 搭建的镜像存储服务,比如 ACR、Docker
Hub、Quay、自建 Harbor 等,目前已经初步经过了 TB 级别的生产环境镜像迁移验证,并开源于 https://github.com/AliyunContainerService/image-syncer ,欢迎大家下载使用以及提供宝贵的建议~
工具特性
image-syncer 的特性如下:
1.支持多对多镜像仓库同步
2.支持基于 Docker Registry V2 搭建的 docker 镜像仓库服务 (如 Docker Hub、 Quay、 阿里云镜像服务 ACR、 Harbor等)
3.同步只经过内存和网络,不依赖磁盘存储,同步速度快
4.增量同步, 通过对同步过的镜像 blob 信息落盘,不重复同步已同步的镜像
5.并发同步,可以通过配置文件调整并发数
6.自动重试失败的同步任务,可以解决大部分镜像同步中的网络抖动问题
7.不依赖 docker 以及其他程序
借助 image-syncer,只需要保证 image-syncer 的运行环境与需要同步的 registry 网络连通,你可以快速地完成从镜像仓库的迁移、拷贝以及增量同步,并且对硬件资源几乎没有要求(因为 image-syncer 严格控制网络连接数目=并发数,所以只有在当单个镜像层过大的情况下,并发数目过大可能会打满内存,内存占用 <= 并发数 x 最大镜像层大小);除了使用重传机制规避同步过程中可能出现的偶发问题之外, image-syncer 会在运行结束时统计最后同步失败的镜像个数,并且打印出详细的日志,帮助使用者定位同步过程中出现的问题。
使用指南
image-syncer 运行,只需要用户提供一个配置文件,内容如下:
{"auth": { // 认证字段,其中每个对象为一个registry的一个账号和// 密码;通常,同步源需要具有pull以及访问tags权限,// 同步目标需要拥有push以及创建仓库权限,如果没有提供,则默认匿名访问"quay.io": { // registry的url,需要和下面images中对应registry的url相同"username": "xxx", // 用户名,可选"password": "xxxxxxxxx", // 密码,可选"insecure": true // registry是否是http服务,如果是,insecure 字段需要为true,默认是false,可选,支持这个选项需要image-syncer版本 > v1.0.1},"registry.cn-beijing.aliyuncs.com": {"username": "xxx","password": "xxxxxxxxx"},"registry.hub.docker.com": {"username": "xxx","password": "xxxxxxxxxx"}},"images": {// 同步镜像规则字段,其中条规则包括一个源仓库(键)和一个目标仓库(值)// 同步的最大单位是仓库(repo),不支持通过一条规则同步整个namespace以及registry// 源仓库和目标仓库的格式与docker pull/push命令使用的镜像url类似(registry/namespace/repository:tag)// 源仓库和目标仓库(如果目标仓库不为空字符串)都至少包含registry/namespace/repository// 源仓库字段不能为空,如果需要将一个源仓库同步到多个目标仓库需要配置多条规则// 目标仓库名可以和源仓库名不同(tag也可以不同),此时同步功能类似于:docker pull + docker tag + docker push"quay.io/coreos/kube-rbac-proxy": "quay.io/ruohe/kube-rbac-proxy","xxxx":"xxxxx","xxx/xxx/xx:tag1,tag2,tag3":"xxx/xxx/xx"// 当源仓库字段中不包含tag时,表示将该仓库所有tag同步到目标仓库,此时目标仓库不能包含tag// 当源仓库字段中包含tag时,表示只同步源仓库中的一个tag到目标仓库,如果目标仓库中不包含tag,则默认使用源tag// 源仓库字段中的tag可以同时包含多个(比如"a/b/c:1,2,3"),tag之间通过","隔开,此时目标仓库不能包含tag,并且默认使用原来的tag// 当目标仓库为空字符串时,会将源镜像同步到默认registry的默认namespace下,并且repo以及tag与源仓库相同,默认registry和默认namespace可以通过命令行参数以及环境变量配置,参考下面的描述}
}用户可以根据配置不同的镜像同步规则组合,以匹配不同的迁移/同步需求,如将单个镜像 repo 同步到多个不同的镜像 repo、将多个源镜像同步到单个镜像 repo 中(以 tag 区分)、在同一个 registry 中以不同的名字拷贝一个镜像 repo 等等。
使用时需要注意,如果匿名访问作为同步源的 registry 地址,可能存在权限问题无法 pull 镜像以及无法获取 tags,这种情况下需要在" auth "中加入有对应权限的账号密码;而如果匿名访问作为同步目标的 registry 地址,可能存在权限问题无法 push 镜像,同样也可能需要用户提供有对应权限的账号密码。
image-syncer 同时支持 insecure 的 registry(类比 docker 的-- insecure - registry 参数,在" auth "的相应条目中添加 " insecure ": true ),可以同时在 http 和 https 两种类型的镜像服务之间迁移。
image-syncer 还提供了一些简单的参数来控制程序的运行,包括并发数目控制、重传次数设置等等:
-h --help 使用说明,会打印出一些启动参数的当前默认值--config 设置用户提供的配置文件所在路径,使用之前需要创建配置文件,默认为当前工作目录下的image-syncer.json文件--log 打印出来的log文件路径,默认打印到标准错误输出,如果将日志打印到文件将不会有命令行输出,此时需要通过cat对应的日志文件查看--namespace 设置默认的目标namespace,当配置文件内一条images规则的目标仓库为空,并且默认registry也不为空时有效,可以通过环境变量DEFAULT_NAMESPACE设置,同时传入命令行参数会优先使用命令行参数值--registry 设置默认的目标registry,当配置文件内一条images规则的目标仓库为空,并且默认namespace也不为空时有效,可以通过环境变量DEFAULT_REGISTRY设置,同时传入命令行参数会优先使用命令行参数值--proc 并发数,进行镜像同步的并发goroutine数量,默认为5--records 指定传输过程中保存已传输完成镜像信息(blob)的文件输出/读取路径,默认输出到当前工作目录,一个records记录了对应目标仓库的已迁移信息,可以用来进行连续的多次迁移(会节约大量时间,但不要把之前自己没执行过的records文件拿来用),如果有unknown blob之类的错误,可以删除该文件重新尝试--retries 失败同步任务的重试次数,默认为2,重试会在所有任务都被执行一遍之后开始,并且也会重新尝试对应次数生成失败任务的生成。一些偶尔出现的网络错误比如io timeout、TLS handshake timeout,都可以通过设置重试次数来减少失败的任务数量在同步结束之后,image-syncer
会统计成功和失败的同步任务数目(每个同步任务代表一个镜像),并在标准输出和日志中打印 "Finished, FAILED TASKS> sync tasks failed, TASKS> tasks generate failed" 的字样,从而可以获得同步的结果。更多FAQ参见 FAQs.md
使用示例
ACR(Alibaba Cloud Container Registry)是阿里云提供的容器镜像托管服务,支持全球20个地域的镜像全生命周期管理,联合容器服务等云产品,打造云原生应用的一站式体验。这里通过将自建 harbor 上的镜像同步到 ACR,提供 image-syncer 的基本使用示例
从自建 harbor 同步镜像到 ACR
1.在阿里云控制台上开通容器镜像服务,并进入 ACR 控制台
2.创建命名空间,默认仓库类型决定了当仓库不存在时,docker push 自动创建的仓库类型是公有的还是私有的;如果部分需要同步的目标仓库不存在,需要打开自动创建仓库按钮,让类似" docker push "的操作能自动创建仓库
3.创建访问凭证,对应的账号即为 docker login 的账号,如下图:
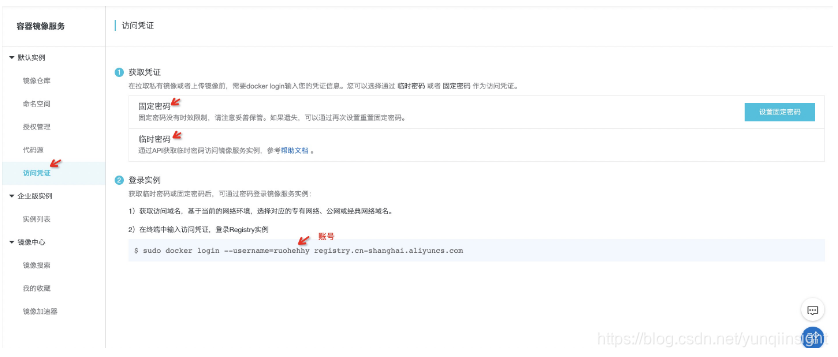
4.上面的操作使用的是主账号,默认拥有全部权限;为了进行权限管理,我们也可以通过创建 RAM 子账号,并配置对应权限,这里的场景中我们只使用到了创建、更新镜像仓库相关权限,最小权限设置如下,访问控制的资源粒度为 image-syncer 命名空间:
{"Statement": [{"Effect": "Allow","Action": ["cr:CreateRepository","cr:UpdateRepository","cr:PushRepository","cr:PullRepository"],"Resource": ["acs:cr:*:*:repository/image-syncer/*"]}],"Version": "1"
}5.同样,RAM 账号需要通过 RAM 用户登陆入口登陆阿里云控制台,并进入 ACR 控制台创建访问凭证(同3.)
6.然后我们可以通过访问凭证中创建的密码,完成如下 image-syncer 的同步配置(配置中使用 RAM 子账号的访问凭证);这里我们将本地搭建的 harbor( http 服务,要设置 insecure,通过 harbor.myk8s.paas.com:32080 访问)中的 library/nginx 仓库同步到华北2(通过为 registry.cn-beijing.aliyuncs.com 访问)中的 image-syncer 命名空间下,并且保持仓库名称为 nginx,config.json 如下:
{"auth": {"harbor.myk8s.paas.com:32080": {"username": "admin","password": "xxxxxxxxx","insecure": true},"registry.cn-beijing.aliyuncs.com": {"username": "acr_pusher@1938562138124787","password": "xxxxxxxx"}},"images": {"harbor.myk8s.paas.com:32080/library/nginx": ""}
}7.下载最新的 image-syncer 可执行文件(目前只支持 linux amd64 版本,可以自行编译),解压,并运行工具
执行命令:
# 设置默认目标registry为registry.cn-beijing.aliyuncs.com,默认目标namespace为image-syncer
# 并发数为10,重试次数为10
# 日志输出到./log文件下,不存在会自动创建,不指定的话默认会将日志打印到Stderr
# 指定配置文件为harbor-to-acr.json,内容如上所述
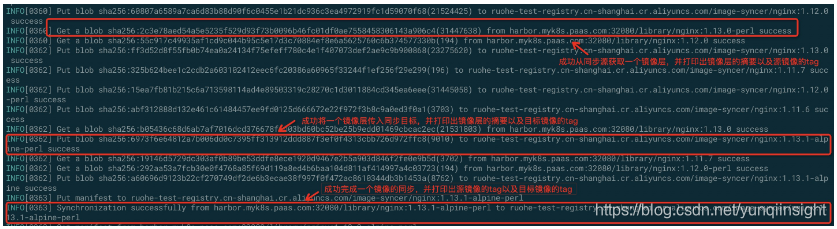
./image-syncer --proc=10 --config=./harbor-to-acr.json --registry=registry.cn-beijing.aliyuncs.com --namespace=image-syncer --retries=10 --log=./log一次同步会经历三个阶段:生成同步任务、执行同步任务以及重试失败任务;其中,每个同步任务都代表了一个需要同步的 tag (镜像),如果配置文件中某条规则没有指定 tag,在“生成同步任务”阶段会自动 list 源仓库所有 tag,并生成对应的同步任务,如果生成同步任务失败,也会在重试阶段进行重试,(故意配错账号密码时)执行输出如下:

正常运行的输出:

在运行时,image-syncer 会打印出如下的日志信息:
从自建 harbor 同步镜像到 ACR 企业版
ACR 企业版提供企业级容器镜像、Helm Chart 安全托管能力,拥有企业级安全独享特性,具备千节点镜像分发、全球多地域同步能力。提供云原生应用交付链,实现一次应用变更,全球化多场景自动交付。强烈推荐安全需求高、业务多地域部署、拥有大规模集群节点的企业级客户使用。
同步到 ACR 企业版和 ACR 普通版所需的操作基本相同:
1.创建 ACR 企业版实例
2.创建命名空间,并对默认仓库类型进行设置,并打开自动创建仓库的功能
3.配置公网的访问控制,需要打开 ACR 企业版的访问入口,并添加公网白名单,使外部能访问镜像服务
4.配置访问凭证,这部分和 ACR 普通版相同
5.使用访问凭证中创建的密码,完成如下 image-syncer 的同步配置;与之前同步到ACR共享版不同的是,每个ACR企业版实例有自己单独的域名(一个公网可见,一个仅专有网络可见,如果镜像同步工具运行在个人环境上需要使用公网域名;如果要使用仅专有网络可见的域名,则将镜像同步工具运行在阿里云ECS实例上,并且通过配置使域名对该ECS所在的专有网络可见;这里使用的是公网域名
ruohe-test-registry.cn-shanghai.cr.aliyuncs.com),并且namespace对于每个不同企业版实例之间来说都是隔离的。我们同样将本地搭建的 harbor(http 服务,要设置i nsecure,通过 harbor.myk8s.paas.com:32080 访问)中的 library/nginx 仓库同步到 ACR 企业版实例中 image-syncer 命名空间下,并且保持仓库名称为 nginx,config.json 如下:
{"auth": {"harbor.myk8s.paas.com:32080": {"username": "admin","password": "xxxxxxxxx","insecure": true},"ruohe-test-registry.cn-shanghai.cr.aliyuncs.com": {"username": "ruohehhy","password": "xxxxxxxx"}},"images": {"harbor.myk8s.paas.com:32080/library/nginx": ""}
}6.运行工具
执行命令
# 设置默认目标registry为ruohe-test-registry.cn-shanghai.cr.aliyuncs.com,默认目标namespace为image-syncer
# 并发数为10,重试次数为10
# 日志输出到./log文件下,不存在会自动创建,不指定的话默认会将日志打印到Stderr
# 指定配置文件为harbor-to-acr.json,内容如上所述
./image-syncer --proc=10 --config=./harbor-to-acr.json --registry=ruohe-test-registry.cn-shanghai.cr.aliyuncs.com --namespace=image-syncer --retries=10输出与前述相同
更多能力
开源不易,长期的维护项目更不容易,大家觉得好就请给这个项目点个 star,公司内的老板会看这个项目的 star 数量来决定后续能不能投更多的研发资源来维护这个项目,万分感谢:)
One More Thing
那么,镜像仓库能顺利迁移,是否迁云就能顺利进行呢?答案是——并没有那么简单,仓库只是迁云过程中碰到的问题之一,还需要解决其他痛点。
对于已经在私有云/公有云上已经把业务应用跑在 k8s 上的用户来说,如何让业务在迁云过程中不受影响是头等大事。阿里云云原生应用平台的解决方案架构师对此已经有了完善的考虑,力助用户应用高效稳定的迁移到 ACK 服务上。在帮助这些用户落实迁云方案的同时,我们也在不断思考如何把这些案例中共性的东西做一些沉淀,总结出一些优秀的解决方案、最佳实践以及开发一些工具来帮助用户快速完成迁云的这件事情,这是我们迁移过程中为用户考虑到的点
原文链接
本文为云栖社区原创内容,未经允许不得转载。





![RuoYi-Cloud [网关异常处理]请求路径:/code,异常信息:null](http://pic.xiahunao.cn/RuoYi-Cloud [网关异常处理]请求路径:/code,异常信息:null)






)




)

