
导读:年初的一个晨会上,用户增长负责人湘翁问我说:一个周内上线50个增长策略,技术兄弟们能做到么?
在闲鱼用户增长业务上的实验
闲鱼的用户增长业务具有如下现状:
闲鱼的卖家都是普通小卖家,而非专业的 B 类商家。因此无法统一组织起来参加营销活动带来买家活跃。这一点是与淘宝/天猫的差别。
我们目前 DAU 已经突破到 2000W ,如何承接好这么大体量的用户,对运营同学是个很大的考验。
为了能更好地做好用户增长,在今年年初时,我们在用户增长下做了多个实验,希望提高用户停留时长。用户浏览时间越长,就越有可能发现闲鱼上还有很多有趣的内容,无论是商品宝贝还是鱼塘内的帖子。从而达到吸引用户下一次还能再回来的目的,最终带来用户增长。其中两个实验如下:
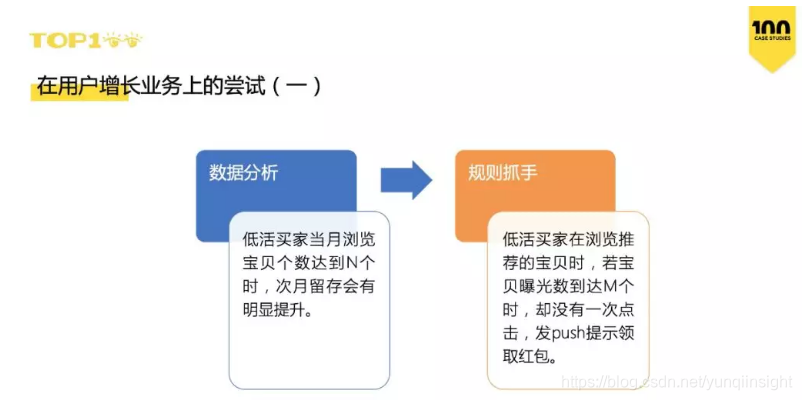

我们做的实验上线后大部分都取得了不错的业务效果,但是在过程中也暴露了两个问题:
研发周期长 一开始,我们先用最快的实现方案来做,主要是为了快速验证规则策略的有效性,并没有做大而全的设计,每个需求都是case by case地写代码来实现。那么从开始开发真正能到上线,很可能就是三周,主要因为客户端发版是有窗口的。
运营效率慢 因为上线慢,导致获取业务数据后再分析效果就很晚了,然后还要根据数据再去做调整那就更晚了。这样算下来,一年也上不了几个规则策略。
工程化解法——基于事件流的规则引擎
针对上述问题,我们先做了一层业务抽象。运营先通过对用户的各种行为进行一个分析和归类,得出一个共同的具体的规则,再将这个规则实时地作用到用户身上进行干预。

针对这层业务抽象,我们再做了工程化,目的就是为了提升研发效率和运营效率。这样就有了第一个方案——基于事件流的规则引擎,我们认为用户的行为是一串顺序的行为事件流,使用一段简单的事件描述 DSL ,再结合输入和输出的定义,就可以完整地定义一个规则。

以上述用户增长的第二个实验为例,如下图所示的 DSL 即可简单表达出来:


规则引擎的局限性
该规则引擎可以很好地解决之前用户增长业务下的几个策略,随后我们进行了内部推广,准备在闲鱼 C2C 安全业务下也落地。在 C2C 安全业务上有如下描述:

在 C2C 安全业务上,也有一个看似是一个针对一系列行为作出的规则抽象,如下图所示:

但是将上述规则套上规则引擎后,就会发现无法将安全的规则套上规则引擎。假设我们的详细规则是1分钟内被拉黑2次,就对该用户打上高危标记。那么我们想一想,当来了第一个拉黑事件后,匹配上了。然后紧接着来了第二个拉黑事件,也匹配上了。此时按照规则引擎的视角,条件已经满足了,可以进行下一步操作了。但是再仔细看一看规则,我们的规则是要被不同的用户拉黑,因为有可能是同一个用户操作了多次拉黑(同时多开设备)。而规则引擎上只知道匹配到了2次拉黑事件,对规则引擎来说已经满足了。却无法知道是否是不同人操作的。其根本原因是因为在规则引擎里,事件都是无状态的,无法回溯去做聚合计算。

新的解决方案
针对规则引擎的局限性,重新分析和梳理了我们的实际业务场景。并结合了业界知名的通用的解决方案后,设计出了新的方案,定义了新的 DSL 。可以看到,我们的语法是类 SQL 的,主要有以下几个考虑:
- SQL已经是语义完备的编程语言,不用再去做额外的语法设计。
- SQL是一门很简单的语言,不需要花太多时间就可以掌握。
- 我们闲鱼的运营同学会写SQL,这样会让上线效率更快。


新的 DSL 方案与之前的规则引擎相比主要有以下几个增强:
- 增加了条件表达式。可以支持更丰富更复杂的事件描述,也就能支撑更多的业务场景。
- 增加了时间表达式。通过 WITHIN 关键字,定义了一个时间窗口。通过 HAVING 之后跟的DISTINCT等关键字,就可以针对时间窗口内的事件进行聚合计算。使用新的方案,就可以很好地解决上述 C2C 业务上的规则描述问题。
- 扩展性强。遵循了业界标准,与具体业务的输入和输出无关,便于推广。
针对之前的 C2C 业务上的规则描述问题,使用新方案的例子如下:


▶ 整体分层架构
基于这套用EPL(Event Programming Language)写出的DSL,为了做好工程化,我们做了如下的整体分层架构。为了快速实现最小闭环验证效果,我们选择先基于Blink(Blink是阿里对Flink的内部优化和升级)做云上的解析和计算引擎。
在这个分层架构里,至上而下分别是:
- 业务应用 在这里是我们整个系统的业务方,已经在多个业务场景下做了落地。
- 任务投放 这里是对业务应用层提供DSL声明和投放的能力,能可以做简单的圈人,以及与用户触达模块的关联。
- 用户触达 这个模块用于接收来EPL引擎计算的结果,根据关联的Action来实施动作。同时这个模块也可以独立对业务应用提供服务,即各个业务方可以拥有自己的逻辑,通过用户触达模块来触达用户。
- EPL引擎 目前已经实现了云上的解析和结算。用于接收来自任务投放里声明的DSL,再去解析和运行在Blink上。
- 事件采集 负责通过服务端日志和行为打点里采集行为事件,并归一化地输出给EPL引擎。

▶ 事件采集
通过切面的方式拦截所有的网络请求和行为打点,再记录到服务端日志流里。同时通过一个事实任务对事件流进行清洗,按前面定义的格式清洗出我们想要的事件。再将清洗后的日志输出到另一个日志流里,供 EPL 引擎来读取。

▶ EPL 实现
由于我们采取了类 SQL 语法,而 Calcite 是业界通用的解析 SQL 的工具,因此我们采用 Calcite 并通过自定义其中的 parser 来解析。如果是单一事件的 DSL ,则会解析成 Flink SQL 。如果是多事件的 DSL ,则会解析后通过直接调用 Blink 的 API 接口的方式来实现。

▶ 用户触达
当 EPL 引擎计算出结果之后,会输出给用户触达模块。首先会进行一个 Action 路由,最终决策出需要由具体哪一个 Action 来响应,最后通过与客户端之间的长连接将 Action 下发到端上。端上收到具体的 Action 后,会先判断当前用户的行为是否允许展示该 Action。如果可以的话,就直接执行 Action 的具体内容,曝光给用户。用户看到这次响应后会有相应的行为,那么这部分的行为会影响到 Action 路由,对这次的路由的做出一个反馈。

应用落地
新方案上线后,我们就在越来越多的业务场景里进行了落地。这里列举2个例子:



在上述鱼塘的例子里,可以看出来,我们这套方案已经有了一点算法推荐的影子了。在上述租房的例子里,由于规则过于复杂,用DSL表达起来很麻烦,所以就做成只采集4次浏览不同租房宝贝的规则,即触发后,就将这里的数据都给到租房的具体开发的业务方,这也是我们在落地过程中摸到的边界。
结论
使用这一套完整方案,研发效率上有了很大的提升。原先通过写代码 case by case 的方式一般要4个工作日完成整个研发流程,极端情况下需要跟客户端版本则需要 2-3 周的时间。现在通过写 SQL 的方式一般要0.5个工作日即可上线。
此外,这套方案还有如下几个优势:
- 高性能 整条链路计算完毕平均耗时5秒。
- 高可靠 依托于 Blink 的高可靠性,承载了双十一上亿的流量。
通过在多个业务的落地实践,我们也摸索出来这套方案的适用边界:
- 对实时性要求高
- 强运营主导规则
- 能够用 SQL 表达
原文链接
本文为云栖社区原创内容,未经允许不得转载。









)








)
