简介: 为什么线下环境的不稳定是必然的?我们怎么办?怎么让它尽量稳定一点?

这篇文章想讲两件事:
- 为什么线下环境[1]的不稳定是必然的?
- 我们怎么办?怎么让它尽量稳定一点?
此外,还会谈一谈如何理解线下环境和线上环境的区别。
如果没有时间读完全文的话,这里是本文的主要观点:
- 线下环境不稳定是必然的,在没有实现TiP之前,当前我们能做的是尽量让它稳定一点。
- 避免过多的笼统使用”环境问题“的说法。
- 业务应用线下环境的基础设施必须按照生产环境标准运维。一个实现手段就是直接使用生产环境的基础设施。
- stable层首先要把单应用可用率提升上去。单应用如果无法做到99.999%或100% 都是能调通的,链路的稳定性就是缘木求鱼、根本无从谈起。
-
减少dev环境的问题,主要有四个重点:
- 做好联调集成前的自测;
- 架构上的投入(契约化、可测性);
- 通过多环境、数据库隔离等手段减少相互打扰;
- 通过持续集成尽早暴露问题,降低问题的影响和修复成本。
- IaC(Infrastructure-as-Code)是解题的一个关键点。
- 线下环境是一个场景。要深刻理解线下环境和线上环境这两个不同场景的差异。
以下是正文:
一 线下环境不稳定的必然性
说起线下环境为什么不稳定,经常会听到大家给出这些原因:
- 为了成本,线下环境的机器不好,是过保机;
- 为了成本,线下环境的硬件资源是超卖的;
- 工具配套不完善,线下环境的配置和生产环境没保持同步;
- 线下环境的监控告警、自愈等没有和生产环境对齐;
- 投入不够,不重视,对问题的响应不及时,流程机制等没建立起来;
- 测试活动会产生脏数据;
- …
其实这些原因中大部分都不是本质问题。换句话说,即便狠狠的砸钱、砸人、上KPI,即使机器不用过保机、硬件不超卖、工具建设好把配置监控自愈等和生产环境保持对齐、问题响应机制建立起来,线下环境也还是会不稳定的。因为线下环境不稳定的根源在于:
- 线下环境里面有不稳定的代码
- 线下环境不稳定带来的影响小
这两个原因是相互有关系的:我们需要有一个地方运行不稳定的代码,但我们怕不稳定的代码引起很大的问题,所以我们需要这个地方是低利害关系的(low-stakes);因为这个地方是低利害关系的,所以对它的问题我们必然是低优先级处理的。
所以,线下环境必然是不稳定的。
之所以Testing-in-Production(TiP)是一条出路,就是因为TiP把这两个根源中的一个(即第二点)给消除了:production不稳定带来的影响是很大的。但TiP注定是一条很漫长且艰难的道路,因为我们怕不稳定的代码引起很大的问题。我们需要首先在技术上有充分的能力充分确保不稳定的代码也不会引起很大的问题。这是很有难度的,今天我们还没有100%的信心做到能充分确保稳定的代码不会引起很大的问题。
既然TiP一时半会儿还用不上、发挥不了很大的作用,那么接下去的问题就是:怎么办?既然线下环境的不稳定是必然的,那我们怎么用不太夸张的投入让它尽量稳定一点?
对策还是要有的。否则,线下环境太不稳定了,大家就都放弃了,不用了,直接跳过,直接把还不太稳定的代码部署到预发环境(pre-production)去了。把预发环境当线下环境用,结果就是预发环境也被搞得像线下环境那样不稳定了。这样再发展下去,预发环境越来越不稳定了,我们还有地方可以去吗?所以,还是要有一整套对策让线下环境尽量稳定一点。
二 怎么让线下环境尽量稳定一点
1 避免过多的笼统使用“环境问题”的说法
- 很多同学习惯用“环境问题”、“环境不稳定”来指代线下环境里除了他自己的那个应用之外的所有的问题:
- 物理机和网络的问题是“环境问题”
- 中间件的问题是“环境问题”
- 数据库本身的问题是“环境问题”
- 数据库里的“脏”数据[2]是“环境问题”
- 我的数据被别人的应用消费掉了是“环境问题”
- 其他应用的配置配错了是“环境问题”
- 其他应用重启了导致我的调用失败是“环境问题”
- 其他应用里的代码bug也是“环境问题”
- ...
“环境问题”这个说法太笼统了,过多的笼统使用这个说法是很有害的,因为它会掩盖很多真正的问题。其中的一些问题也是有可能造成生产环境的稳定性和资金安全风险的。过多的笼统使用“环境问题”这个说法的另一个坏处是:会造成在大家的意识里“环境问题”是必然存在的、是无法避免的,导致大家一听到“环境问题”第一反应就是放弃,放弃排查、放弃抗争、放弃探究、放弃改进优化。
要提升线下环境稳定性,首先要正本清源,尽量避免笼统的使用“环境问题”这个说法。要尽量用具体一点的说法,比如,“网关配置问题”、“某某应用启动超时”、“数据库查询超时“。这些表象/症状背后的原因有很多种可能,是需要我们去排查清楚的,不能“刷墙”。所谓的“刷墙”的意思是:看到墙上有条裂缝,就找一桶乳胶漆刷一道,把裂缝遮盖掉。“刷墙”的行为的一个例子:某个应用启动失败,就换台服务器再试一试,成功了就继续干下面的事情,不去探究之前启动失败背后的原因了。
有些时候的确是项目时间太紧了,没时间排查每一个问题。可以现实一点,如果同样的问题出现第二次或第三次(例如,同一个应用、同一个项目分支,这周遇到两三次启动失败),就要追究一下了。
2 问题拆解
“环境问题”,归根到底,无外乎来自于三个地方:
- 基础设施(中间件、数据库、等等)的问题
- stable环境的问题
- dev环境的问题
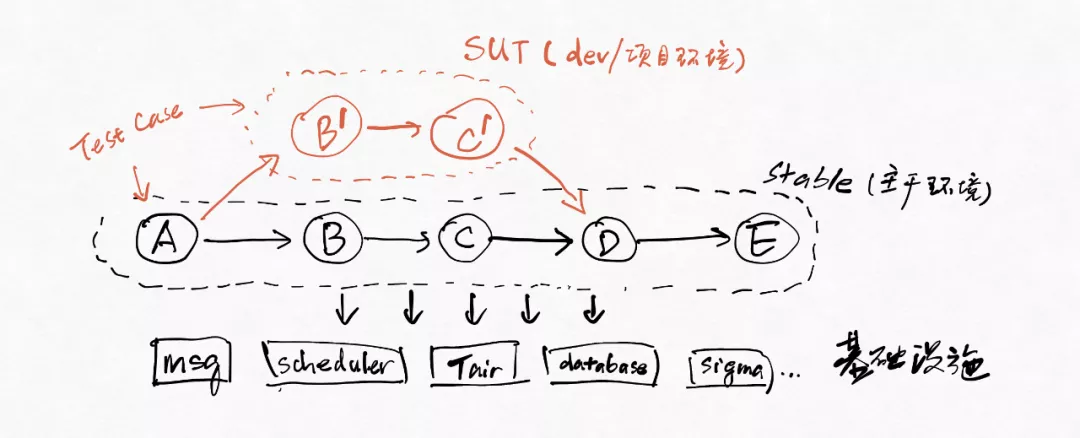
这里要解释一下什么是stable和dev。线下环境的结构在蚂蚁集团和阿里集团的做法一般是这样的:
- 基础设施之上,首先有一个stable环境。
- stable环境跑的是和生产环境的版本相同的代码,每次生产环境发布后,stable也会同步更新。
- dev环境就是项目环境,是SUT(System Under Test)。每个项目有自己的dev环境,部署的是这个项目的代码,这个项目上的同学就在这个项目环境里做测试、联调、集成。
- dev环境不是一个全量的环境,它是“挂”在stable上的一个子集。某系统一共有一百个左右的应用,它的stable环境是全量的,但dev环境只包含这个项目涉及的应用,测试发起的流量里面包含一个标签,测试流量就会被某种路由机制(例如,在蚂蚁用的是sofarouter)从stable环境的应用路由到dev环境的应用:
虽然这三趴对“环境问题”会因人而异,但都不可忽视。要提升线下环境稳定性,必须对基础设施、stable、dev这三趴三管齐下。
3 对策:基础设施
基础设施的稳定是非常关键的一环。如果基础设施不稳定,就会出现“排查疲劳”:每次遇到一些奇怪的问题(启动超时、调不通、等等),如果排查下来10次有9次是基础设施的问题,大家渐渐就不愿意排查了(因为不是代码的问题),一些真正的代码问题也会被漏过。
基础设施层要遵循的原则是:(业务应用的)线下环境的基础设施必须按照生产标准运维 。如果一个系统是运行在公有云上的,那么这个原则就很容易实现,因为线下环境也可以直接运行在公有云上。但有些公司、有些系统,是运行在自建机房、私有云上的,那最好的做法是撤销“线下机房”,直接把业务应用的线下环境放在基础设施的生产机房去跑(同时做好必要的访问控制和业务数据隔离)。线下环境直接放在基础设施的生产机房跑之后,基础设施团队直接按照运维其他生产机房那样去运维,中间件、数据库、缓存、物理机、网络、机房等所有的监控告警、巡检、发布和变更管控、应急、自愈能力、容量管理、等等都能做到位,稳定性可用率有明确的metrics和SLA。慢慢的,就能形成这样的心智:例如,当线下环境的某个业务应用出现数据库查询timeout的时候,我们首先怀疑的是应用自己的SQL查询语句有问题,而不是怀疑数据库有问题。
4 对策:stable环境
线下环境不稳定性的时候,工程师的心智是:当我在dev环境跑测试遇到错误的时候,我的第一反应是“一定是‘环境问题’”。也就是说,我的第一反应是“别人的问题”,只有当“别人的问题”都排出后我才会认真的去看是不是我自己的问题(包括项目的问题)。
当基础设施层稳定保障好以后,就能形成这样的心智:当某个应用出现数据库查询timeout的时候,我们首先怀疑的是应用(可能是stable的、可能是dev的)的SQL有问题,而不是怀疑数据库有问题。
当stable和基础设施这两趴的稳定性都治理好以后,就能形成这样的心智:当我在dev环境跑测试遇到错误的时候,我的第一反应是“一定是我们的项目有问题”。其实今天在生产环境大家就是这样的心智。一次变更、一次发布后,如果出现问题,做发布做变更的同学的第一反应都是怀疑是不是这个变更/发布有问题,而不是怀疑是不是(生产)环境本身不稳定。做stable和基础设施的稳定性治理也要达成这样的心智。
stable的稳定性治理,最终就是在做一道证明题:拿出数据来,证明stable是稳定的(所以,如果有问题,请先排查你的项目)。证明stable是稳定的数据分两类:
- 单应用
- 链路
单应用就是检查应用是否起来了、是否或者、RPC调用是否调通(不管业务结果是成功还是失败,但至少RPC调用没有system error)。它验证的是单个应用是可用的,不管业务逻辑对不对,不管配置对不对,不管签约绑卡能不能work,至少这个应用、这个服务、这个微服务是up and running的。单应用稳定性必须达到100%,或者至少应该是“五个9”。这个要求是合理的,因为单应用的稳定性是链路稳定性的基础。如果单应用都没有up and running,链路功能的可用和正确性就根本无从谈起。
单应用的稳定性度量是很通用的,不需要理解业务场景就可以度量。我们需要做的事情就是:对目标形成共识,把度量跑起来,然后根据度量数据投入人力,一个个问题的排查解决,把稳定性一点点提升上来;后续再出现问题,第一时间排查解决,让稳定性维持在很高的水平。
链路的稳定性,说白了就是跑脚本、跑测试用例。频率是分钟级也可以,小时级也可以。验证链路的脚本是需要不断的补充丰富的,当发生了一个stable的问题但是验证脚本没有发现,就要把这个问题的场景补充到链路验证脚本(测试用例)里面去。也可以借用测试用例充分度的度量手段(例如,行覆盖率、业务覆盖率、等等),主动的补充链路验证脚本。很多其他测试用例自动生成的技术也可以用上来。
最后,达到的效果就是:用数据说话。用很有说服力的数据说话:stable的单应用都是好的,链路也都是通的,这时候出现了问题,就应该先怀疑是项目(dev环境)的问题。
顺便说一句:stable能不能像基础设施那样也直接用生产环境呢?可以的,stable用生产就是Testing-in-Production了。蚂蚁的影子链路压测就是这种做法的一个例子。只不过如果要把这个做法推广到更大面积的日常功能测试、支持更多链路和场景,复杂度和难度会比影子链路压测更高。
5 对策:dev环境
严格来说,dev环境的问题不能算是“环境问题”,也不能算是“线下环境稳定性问题”。因为dev环境就是被测对象(SUT),既然是还在写代码、联调集成和测试,那我们的预期就是它是不稳定的,是会有问题的。只不过实际工作中,dev环境本身的问题也构成了大家对线下环境不稳定的体感。
根据我们对一些项目进行的具体数据分析来分类,在dev环境遇到的问题的几个头部类型是:
- 自测没做好。单应用本身就有bug,而且这些bug是在单应用的unit test和接口测试中是可以发现的,但是由于各种原因,单应用的自测没做好,这些bug留到了在dev环境中进行联调集成的时候才发现。
- 架构方面的原因。例如,接口契约问题。一个项目里,系分做好以后,上下游两个应用各自按照系分去编码实现,但由于系分做的不够好,或者上下游对系分的理解有差异,两个应用到了dev环境放在一起一跑才发现跑不通。这类问题是无法通过自测来发现的(因为本身的理解就有差异)。另一个比较常见的架构原因是可测性。
- 干扰。同一个项目中几个同学各自在做联调集成时候的相互干扰,以及几个项目之间的相互干扰。配置被别人改掉了,数据被别人改掉了,这些情况都很常见。
自测没做好,解法就是要做好自测:
- 单应用的测试要达到一定的覆盖率和有效性。例如,我之前团队的要求是A级系统的单应用测试(unit test和接口测试)要达到90%以上的行覆盖率、以及变更行的覆盖率100%,用例的有效性也要达到90%。
- 单应用的测试要达到很好的稳定性。根据过去在很多地方的时间和观察,我建议的标准是”90%成功率“,这是在“能做得到的”和“够好了”之间的一个比较好的平衡。比这个高,虽然更好,但难度太高,不适合大部分的团队;比这个低,稳定性就不够了,就会感受到测试噪音带来的各种问题。“90%成功率”是一个“甜蜜点”。“90%成功率”的意思是:一个单应用的所有unit test和接口测试的整体通过率,跑一百遍,有至少90遍是100%通过的。
- 单应用的测试也要足够快,一个单应用的所有unit test和接口测试要能在10分钟内跑完。
- 代码门禁是必须的,是标配。很多其他东西是可以根据具体团队的具体情况有不同的做法的,例如,大库、主干开发。有些团队可以举出一些合理的理由说“大库模式不适合我”、“主干开发不适合我”。但我不相信哪个团队能举出合理的理由说“代码门禁不适合我”。
接口契约在软件行业已经有比较多的实践了,例如OpenAPI、ProtoBuf、Pact等。应用间的接口(包括RPC调用和消息),如果只是在一个文档里面用中文或者英文来描述的,上下游之间就比较容易出现gap。也经常出现接口改动只是通过钉钉说了一下,连文档都没有更新。应用间的接口应该以某种DSL来规范的描述,并且在单应用层面根据这个DSL描述进行契约测试,这样能大大减少两个应用到了dev环境放在一起一跑才发现跑不通的情况。
6 dev环境:隔离
上面讲到,dev环境问题的第三个主要来源是相互干扰。既有同一个项目中几个同学各自在做联调集成时候的相互干扰,也有几个项目之间的相互干扰。项目之间的相互干扰的根源是共享数据库:
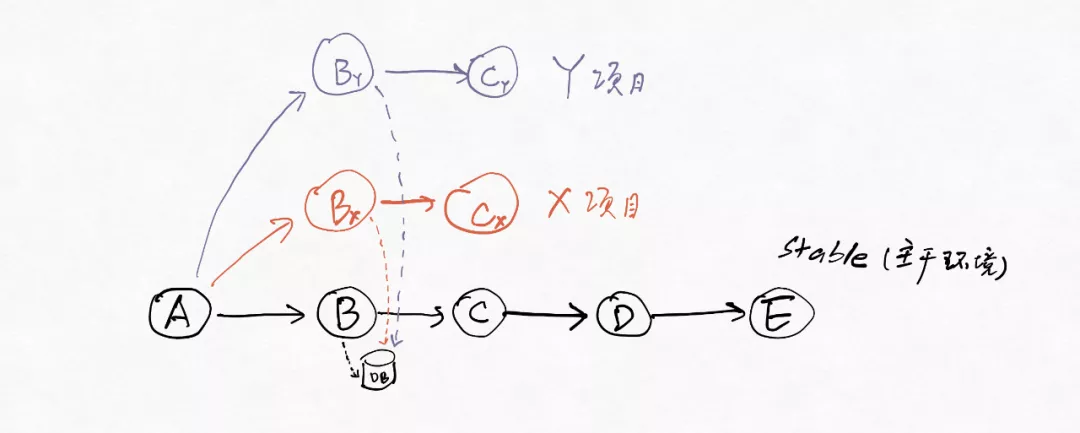
过去,stable环境以及多个项目的dev环境的代码都是访问同一个库的,相互影响就是不可避免的。数据的逻辑隔离和物理隔离都可以解决多项目间的干扰:
- 逻辑隔离:多个项目的dev环境仍然和stable一起共享同一套库表,但是在表的数据层面增加一些标识列,并且在应用的代码逻辑里面根据这种标识来读写数据。
- 物理隔离:每个dev环境分别有自己的库或者表,各自的数据在库或表的层面就是隔离的。相比逻辑隔离,物理隔离有两个优点:1)对应用代码的入侵很小,需要的应用改造工作量很小;2)不同的项目能够有不同的数据库表结构。
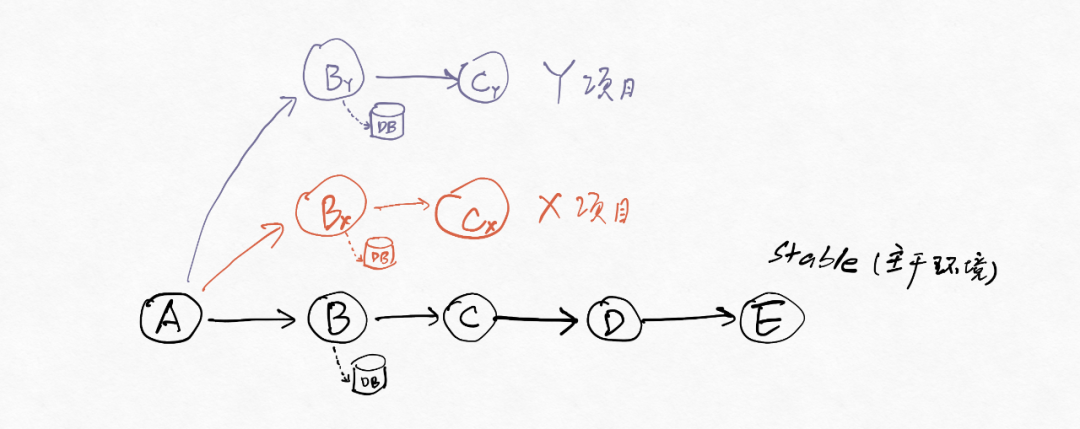
除了数据库,缓存、DRM等也需要进行隔离,减少多个项目之间的相互干扰。做好隔离对提升稳定性有很大的帮助。而且,数据库和缓存等的隔离也能大大降低“脏”数据引起的问题。
7 dev环境:多环境
除了多个项目之间的干扰以外,同一个项目中几个同学各自在做联调集成时候,由于大家都在同一套dev环境(项目环境)上工作,也会出现相互干扰。
解决项目内相互干扰的出路是多环境:
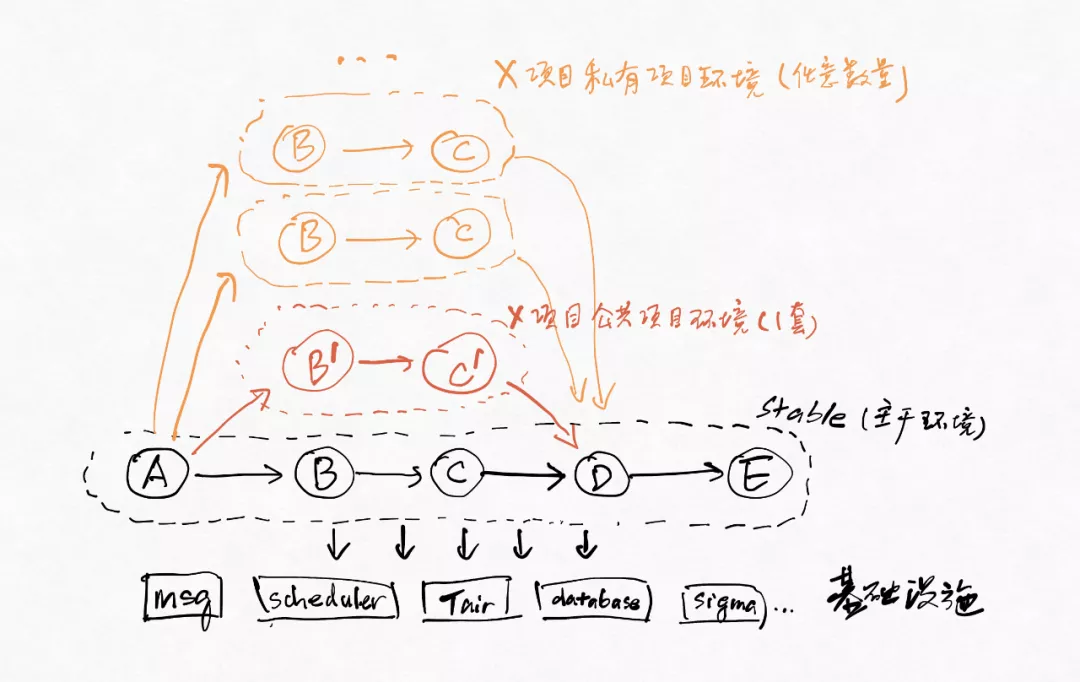
IaC(Infrastructure-as-Code)和GitOps是实现多环境能力的关键。有了GitOps能力(包括Configuration-as-Code和Database-as-Code),能反复快速创建出一套套新的项目环境,并且保证新创建的项目环境中的配置都是对的(IaC也能更好更有效的确保stable的配置、二方包版本、CE版本等和生产环境是一致的)。
8 dev环境:持续集成
单应用的持续集成已经是比较普遍了:在master分支和项目分支上,每次有代码提交都会触发一次单应用的编译构建和测试(包括unit test和接口测试),或者以某个固定周期(例如每15分钟或者每小时)定时触发一次,确保该应用的编译构建和测试一直是好的。
多应用的持续集成就是:在项目分支上,每次有代码提交、或者每隔一定时间,把本项目各个应用的项目分支最新代码部署到dev环境上,并且跑一遍链路级别的用例,确保本项目的这些应用的项目分支代码还是好的。
在很多团队,今天开发同学的很多受挫感和时间的浪费都与缺乏项目级别的多应用持续集成有关,例如:
- 小李跟我说收单支付已经跑通了,让我可以开始测结算了。但我今天到项目环境里一跑,发现收单有问题。我又去找小李,小李看了一下承认是他的问题,他当时只看了行业层的resultCode是Success,没有check下游单据的状态是否正确。
- 我两天前已经把正向流程(例如:支付)跑通了,但今天我要调逆向流程(例如:退款)的时候发现项目环境里正向流程又不work了。逆向流程的调试被block了,我要先花时间排查正向流程的问题。
- 项目环境里正向流程两天前是work的,今天不work了,从两天前到现在,这个中间正向流程是从什么时间开始不work的?两天时间,如茫茫大海捞针啊。
- 我是负责下游应用的。上游的同学今天一次次来找我check数据,每次他在项目环境里发起一笔新的调用,都要来找我让我做数据check。这事儿我躲也躲不掉,因为上游的同学不理解我的应用的内部实现,要他们理解每个下游应用的数据逻辑也不现实。
- 我是负责上游行业层的,我在项目环境里每次发起一笔新的测试交易的时候,我都要挨个儿找下游各域的同学去做数据check,找人找的好辛苦啊。我也理解他们的难处,那么多项目,那么多项目环境,那么多人都去找他们做数据check。
- 我是负责上游行业层的,下游的同学经常来找我,让我帮他们发起一笔交易,因为他们的应用改了代码,他们先知道新的代码work不work。后来我实在觉得这种要求太多了,写了一个发起交易的小工具,让他们自己去跑。但有些会自己去学着用这个小工具,有些还是会来找我。
- 我是负责下游应用的,我经常要去找上游同学帮我发起一笔。他们被我骚扰的很烦,但我也没办法。他们虽然给了我一个小工具,但很难用,很多参数不知道怎么填。
- …
做好了多应用的持续集成,这些问题就都解决了:
- 由于用例都自动化了,发起交易和做check都不需要再求爷爷告奶奶的刷脸找人了。
- 由于用例都自动化了,发起一笔新的交易和验证各域的数据是否正确 都已经都自动化在用例的代码里了,无论是上游还是下游的同学,都只要跑这些用例就可以了,不需要了解小工具的参数怎么填,也不会因为疏漏少check了数据。
- 由于用例都自动化了,所以可以高频的跑,可以每个小时都跑一次,或者可以每15分钟就跑一次。这样,一旦前两天已经跑通的功能被break了,我马上就知道了。
- 由于用例高频的跑了,一旦前两天已经跑通的功能被break了,我马上就知道了,而且问题排查也很容易聚焦。比如,如果这个功能一直到上午9:30还是好的,但是从9:45开始就开始失败了,那我就可以聚焦看9:30-9:45这段时间前后总共几十分钟时间里发生了什么、谁提交了新代码、谁改了数据或配置。
…
做好了多应用的持续集成,其他的好处还有:
- 由于用例高频的跑了,一个用例一天要跑几十次,就很容易暴露出用例本身或者应用代码的一些稳定性问题。比如,有一个链路,从昨天到今天在本项目的多应用持续集成里面跑了几十次,其中有几次失败了。但从昨天到今天,这个链路没有相关代码和配置改动。所以虽然失败的比例小于10%,我还是要排查一下,排查结果发现了一个代码的bug。如果放在过去,没有这种多应用的持续集成,一个链路跑了一次失败了,第二次通过了,我很难判断第一次失败到底是“环境问题”,还是真的代码有bug。
- 由于用例在项目分支里高频的跑了,我就有一个参考物。如果一个用例在项目分支里是一只稳定pass的,但今天在我的个人分支代码上失败了,有了持续集成的结果作为参照物,我就很快能判断出来这很有可能是我的个人分支的代码有问题。
- …
三 线下环境和线上环境的区别
线下环境和线上环境的区别是什么,不同的人有不同的回答。有的说线下的容量没有线上大,有的说线下没有真实用户,有的说线下缺少生产的真实数据,等等,各种答案都有。线下环境和线上环境还有一个很本质的区别是:它们是两个不同的场景。
线下环境是一个场景。
我们做业务架构,先要搞明白业务场景,然后才能正确的设计业务架构和技术实现。数据的读和写是高频的还是低频的,数据块是大而少的还是小而多的,读取数据的时间段上有没有明显的峰谷,数据写入后是否会修改(mutable vs. immutable)等等,这些都会影响我们的架构和技术实现方案。
线下环境也是一个场景,一个和生产环境有不少差异的场景[3]:
1 基础设施层面
中间件
一个配置值、一个开关值,在线上的改动是低频的,大部分情况下一天可能也就推个一两次,但在线下可能每天会有几十次、几百次,因为推送一个配置一个开关可能是测试的一部分。这个差异就是场景的差异。
服务器
服务器重启,在生产环境里是一个低频事件,很多应用只会在发布的时候重启一次,两次重启间的间隔一般都是数天。但在线下环境,重启的频率可能会高很多。
数据库
在生产环境,库的创建和销毁是一个低频事件,但是在线下,如果搞了持续回归和一键拉环境,线下环境数据库就会有比生产高的多得多的库创建销毁操作。
数据丢失
生产环境,我们是不允许数据丢失的。所以,数据库(例如蚂蚁的OceanBase)和DBA团队花了大量的心血在数据丢失场景上。但在线下,数据丢失是完全可以接受的。这个差异,对数据层的架构和技术实现意味着什么?例如,数据库在生产环境是三副本、五副本的,在线下不能支持单副本,能不能很容易的在单服务器、单库级别配置成单副本。
代码版本
生产环境,一个系统,最多同时会有几个不同的代码版本在运行?线下环境呢?这个差异,意味着什么?
抖动
“抖动”是很难避免的,业务应用一般都有一些专门的设计能够容忍线上的基础设施层的一些”抖动“。因此,在生产环境场景里,基础设施层面每天抖N次、每次抖10-20秒,不是一个太大的问题。但这样的抖动在线下环境就是个比较大的问题:每次抖动,都会造成测试用例的失败。这并不是因为这些用例写的不够“健壮”,而是有很多时候测试用例就是不能有防抖逻辑的。例如,如果测试用例有某种retry逻辑,或者测试平台会自动重跑失败的案例[4],那么就会miss掉一些偶发的的bug[5]。在线下环境里,我们宁可接受每周有一次30分钟的outage(不可用),也不愿意接受每周几十次的10-20秒抖动。一次30分钟的outage,大不了就直接忽略掉那段时间的所有测试结果。而每周几十次的10-20秒抖动意味着大量的测试噪音[6],意味着要么是大量的额外的排查成本,要么是漏过一些问题的可能。
2 业务应用层面
业务数据
线下的数据模式和生产是不一样的。由于执行测试用例,线下的营销系统里的当前营销活动的数量可能比生产要高一个数量级。所以营销应用要在技术层面处理好线下这个场景,如果一个营销应用会在启动的时候就加载所有的当前活动,可能就会在线下出现很长的启动时间。
数据的生命周期
我一直倡导的一个原则是“Test environment is ephemeral”,也就是说,线下环境的存在时间是很短的。存在时间短,要求create的成功率高、时间短,但对数据清理要求比较低。存在时间长的,就要求upgrade的成功率高,对create的要求很低,对数据完整性和测试数据清理的要求非常高。继续推演下去,要做好测试数据清理,需要什么?基建层有什么技术方案?业务层需要做什么?业务层是否需要对数据进行打标?测试数据清理这件事,是放在业务层做(基建层提供原子能力),还是在基础设施层做(业务层按照规范打标)?这就是一个架构设计问题。这样的问题,要有顶层设计、架构设计,要针对场景进行设计,不能有啥用啥、凑合将就。
业务流程
生产环境入驻一个商户,会经过一个人工审批流程,这个流程也许会走两三天,有六七个审批步骤。这在线上是OK的,因为线上的商户入驻是相对低频且能够接受较长的处理周期的。但在线下,由于要执行自动化的测试用例,而且要确保测试用例是“自包含”的,商户的创建就会是高频,而且必须快速处理的。所以在技术层面,针对线下环境的场景,要能够“短路”掉审批流程(除非本身要测试的就是审批流程)。类似的流程还有网关的映射配置,线上的网关配置是低频的,但线下的网关配置是高频动作,而且会反反复复。
3 其他
问题排查
线上环境是有比较清楚的基线的,比较容易把失败的交易的链路数据和成功的交易的链路做比较。这个做法在线下环境同样有效吗?如果不是,为什么?是什么具体的线下环境的场景差异导致的?又比如说,对日志的需求,线上线下有差异吗?
权限模型
线下数据库的权限,如果读和写的权限是绑定的、申请权限就是同时申请了读和写,就会很难受。因为工程师为了更好的做问题排查,希望申请上下游应用的数据库读权限,但他们只需要读权限,不需要写权限。如果读写权限是绑定的,即便他们只需要读权限,也要经过繁琐的申请审批,因为涉及了写权限,写权限如果缺乏管控,容易出现数据经常被改乱掉的情况。读写权限申请的时候是绑定的,这在线上环境的场景下也许是OK的,因为生产环境要跑DML本身是有工单流程的,不容易出现数据被改乱掉的情况。但读写权限绑定在线下就不合适了。从架构和设计层面说,读写权限绑定是因为ACL的模型本身没有支持到那个颗粒度。
我们一直说,做技术的要理解业务。比如,做支付系统的,要深刻理解不同的支付场景的差异(比如,代扣、协议支付、收银台、…),才能有效的进行架构设计和技术风险保障。例如,代扣场景,没有uid。这意味着什么?没有uid,意味着灰度引流的做法会不一样,精准灰度的做法可能会不一样,新建机房的切流方案也会不一样。
线下环境也是类似的道理。线下环境也是一个场景。这个场景和生产是不同的场景。每一层(SaaS、PaaS、IaaS)都要深刻的理解不同场景的差异,才能有效的把不同场景都保障好。如果一个应用、一个平台,它的设计和实现只考虑了X场景、没有考虑Y场景,那么它在Y场景下就会遇到这样那样的不舒服,也会使得Y场景下的客户不满意。
充分理解“线下环境”这个场景,把这个场景纳入到架构和技术实现的考虑中,有助于让线下环境尽量保持稳定。
四 结语
总结一下上面所说的一些关键点:
- 线下环境不稳定是必然的,在没有实现TiP之前,当前我们能做的是尽量让它稳定一点。
- 避免过多的笼统使用“环境问题”的说法。
- 业务应用线下环境的基础设施必须按照生产环境标准运维。一个实现手段就是直接使用生产环境的基础设施。
- stable层首先要把单应用可用率提升上去。单应用如果无法做到99.999%或100%都是能调通的,链路的稳定性就是缘木求鱼、根本无从谈起。
- 减少dev环境的问题,主要有四个重点:a)做好联调集成前的自测;b)架构上的投入(契约化、可测性);c)通过多环境、数据库隔离等手段减少相互打扰;d)通过持续集成尽早暴露问题,降低问题的影响和修复成本。
- IaC(Infrastructure-as-Code)是解题的一个关键点。
- 线下环境是一个场景。要深刻理解线下环境和线上环境这两个不同场景的差异。
Note
[1] 线下环境:这里主要讲的是互联网应用的分布式系统的线下环境。也就是通常说的“服务端”的线下环境。这是阿里集团和蚂蚁集团里面涉及技术人员最多的一类线下环境。
[2] 其实,很多”脏“数据一点都不”脏“。很多时候,”脏“数据只不过是之前其他人测试和调试代码留下的数据,但这些数据的存在使得后面的执行结果不符合我们的预期。例如,我要测试的是一个文件打批功能,这个功能会把数据库里面尚未清算的支付都捞出来、写到一个文件里。我创建了一笔未清算的支付,然后运行打批,我预期结果是文件里面只有一条记录,但打出来实际有两条记录,不符合我的预期。这种情况其实是我的预期有问题,是我的测试用例里面的assert写的有问题,或者是我的测试用例的设计、我的测试架构的设计有问题,也有可能是被测代码的可测性(testability)有问题。
[3] 这些场景的差异,也许有人会把它们都归结为“可测性”。这样说也不是没有道理,因为测试就是线下环境最大的一个作用。但我们还是不建议把线下环境这个场景就直接说成“可测性”,因为“可测性”是一种能力,能力是用来支撑场景的,这就好像“可监控”是一种能力,“可监控”这种能力是用来支撑线上环境这个场景的。
[4] 我们是坚决反对测试平台提供自动重跑失败用例能力的,因为自动重跑对质量是有害的。自动重跑会掩盖一些bug和设计不合理的地方,久而久之这些问题就会积累起来。
[5] 偶发bug也可以是很严重的bug。曾经有过一个bug,这个bug会以1/16的几率出现。最后排查发现,原因是这段业务应用代码在处理GUID的时候代码逻辑有问题(而GUID是16进制编码的)。当时的test case只要rerun一下,大概率就会通过(有15/16的通过几率)。
[6] 有噪音的测试,比没有测试 还要糟糕。没有测试,是零资产。有噪音的测试,是负资产。有噪音的测试,要额外搭进去很多排查的时间,而且还会损害大家对测试的信心(类似“狼来了”)。
作者:开发者小助手_LS
原文链接
本文为阿里云原创内容,未经允许不得转载



















