简介: 数据湖的架构中,CDC 数据实时读写的方案和原理
本文由李劲松、胡争分享,社区志愿者杨伟海、李培殿整理。主要介绍在数据湖的架构中,CDC 数据实时读写的方案和原理。文章主要分为 4 个部分内容:
- 常见的 CDC 分析方案
- 为何选择 Flink + Iceberg
- 如何实时写入读取
- 未来规划
一、常见的 CDC 分析方案
我们先看一下今天的 topic 需要设计的是什么?输入是一个 CDC 或者 upsert 的数据,输出是 Database 或者是用于大数据 OLAP 分析的存储。
我们常见的输入主要有两种数据,第一种数据是数据库的 CDC 数据,不断的产生 changeLog;另一种场景是流计算产生的 upsert 数据,在最新的 Flink 1.12 版本已经支持了 upsert 数据。
1.1 离线 HBase 集群分析 CDC 数据
我们通常想到的第一个方案,就是把 CDC upsert 的数据通过 Flink 进行一些处理之后,实时的写到 HBase 当中。HBase 是一个在线的、能提供在线点查能力的一种数据库,具有非常高的实时性,对写入操作是非常友好的,也可以支持一些小范围的查询,而且集群可扩展。
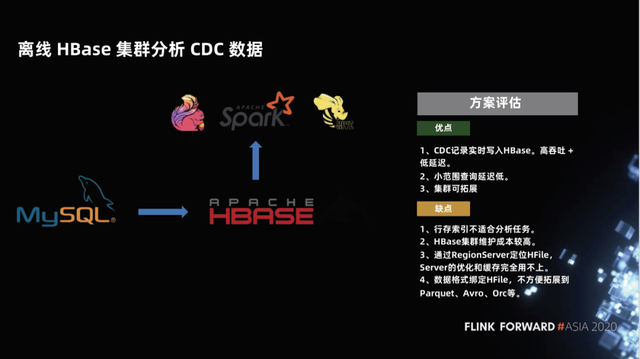
这种方案其实跟普通的点查实时链路是同一套,那么用 HBase 来做大数据的 OLAP 的查询分析有什么问题呢?
首先,HBase 是一个面向点查设计的一种数据库,是一种在线服务,它的行存的索引不适合分析任务。典型的数仓设计肯定是要列存的,这样压缩效率和查询效率才会高。第二,HBase 的集群维护成本比较高。最后,HBase 的数据是 HFile,不方便与大数据里数仓当中典型的 Parquet、Avro、Orc 等结合。
1.2 Apache Kudu 维护 CDC 数据集
针对 HBase 分析能力比较弱的情况,社区前几年出现了一个新的项目,这就是 Apache Kudu 项目。Kudu 项目拥有 HBase 的点查能力的同时,采用列存,这样列存加速非常适合 OLAP 分析。
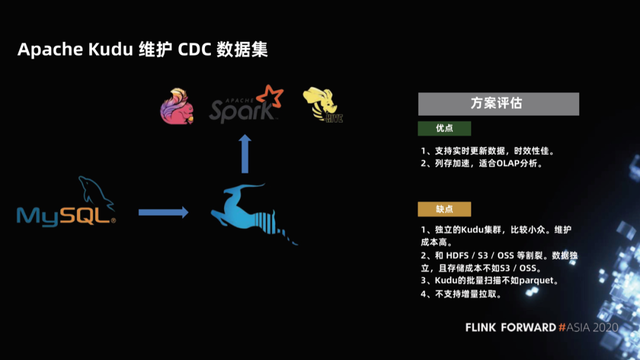
这种方案会有什么问题呢?
首先 Kudu 是比较小众的、独立的集群,维护成本也比较高,跟 HDFS、S3、OSS 比较割裂。其次由于 Kudu 在设计上保留了点查能力,所以它的批量扫描性能不如 parquet,另外 Kudu 对于 delete 的支持也比较弱,最后它也不支持增量拉取。
1.3 直接导入 CDC 到 Hive 分析
第三种方案,也是大家在数仓中比较常用的方案,就是把 MySQL 的数据写到 Hive,流程是:维护一个全量的分区,然后每天做一个增量的分区,最后把增量分区写好之后进行一次 Merge ,写入一个新的分区,流程上这样是走得通的。Hive 之前的全量分区是不受增量的影响的,只有当增量 Merge 成功之后,分区才可查,才是一个全新的数据。这种纯列存的 append 的数据对于分析是非常友好的。
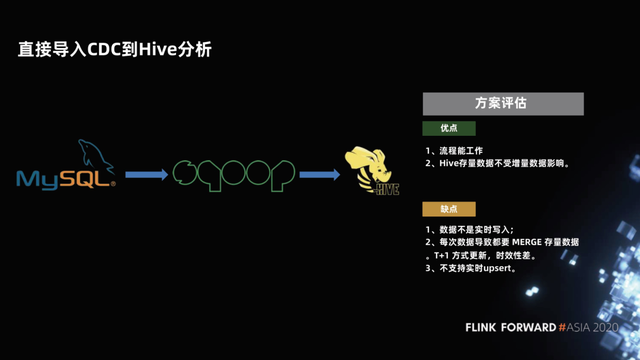
这种方案会有什么问题呢?
增量数据和全量数据的 Merge 是有延时的,数据不是实时写入的,典型的是一天进行一次 Merge,这就是 T+1 的数据了。所以,时效性很差,不支持实时 upsert。每次 Merge 都需要把所有数据全部重读重写一遍,效率比较差、比较浪费资源。
1.4 Spark + Delta 分析 CDC 数据
针对这个问题,Spark + Delta 在分析 CDC 数据的时候提供了 MERGE INTO 的语法。这并不仅仅是对 Hive 数仓的语法简化,Spark + Delta 作为新型数据湖的架构(例如 Iceberg、Hudi),它对数据的管理不是分区,而是文件,因此 Delta 优化 MERGE INTO 语法,仅扫描和重写发生变化的文件即可,因此高效很多。
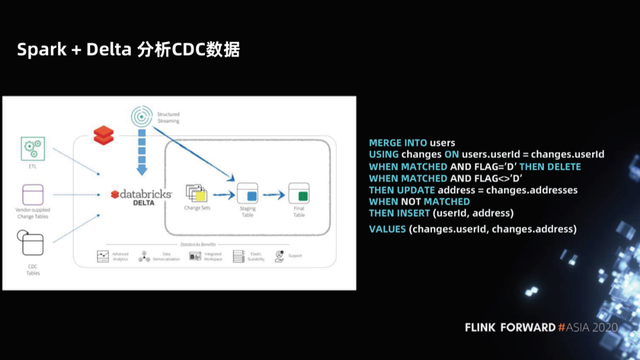
我们评估一下这个方案,他的优点是仅依赖 Spark + Delta 架构简洁、没有在线服务、列存,分析速度非常快。优化之后的 MERGE INTO 语法速度也够快。
这个方案,业务上是一个 Copy On Write 的一个方案,它只需要 copy 少量的文件,可以让延迟做的相对低。理论上,在更新的数据跟现有的存量没有很大重叠的话,可以把天级别的延迟做到小时级别的延迟,性能也是可以跟得上的。
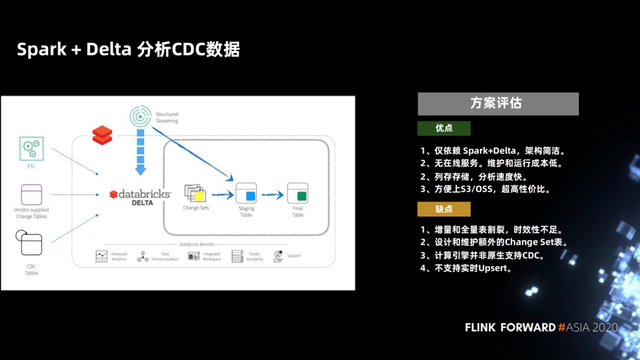
这个方案在 Hive 仓库处理 upsert 数据的路上已经前进了一小步了。但小时级别的延迟毕竟不如实时更有效,因此这个方案最大的缺点在 Copy On Write 的 Merge 有一定的开销,延迟不能做的太低。
第一部分大概现有的方案就是这么多,同时还需要再强调一下,upsert 之所以如此重要,是因为在数据湖的方案中,upsert 是实现数据库准实时、实时入湖的一个关键技术点。
二、为何选择 Flink + Iceberg
2.1 Flink 对 CDC 数据消费的支持
第一,Flink 原生支持 CDC 数据消费。在前文 Spark + Delta 的方案中,MARGE INTO 的语法,用户需要感知 CDC 的属性概念,然后写到 merge 的语法上来。但是 Flink 是原生支持 CDC 数据的。用户只要声明一个 Debezium 或者其他 CDC 的 format,Flink 上面的 SQL 是不需要感知任何 CDC 或者 upsert 的属性的。Flink 中内置了 hidden column 来标识它 CDC 的类型数据,所以对用户而言比较简洁。
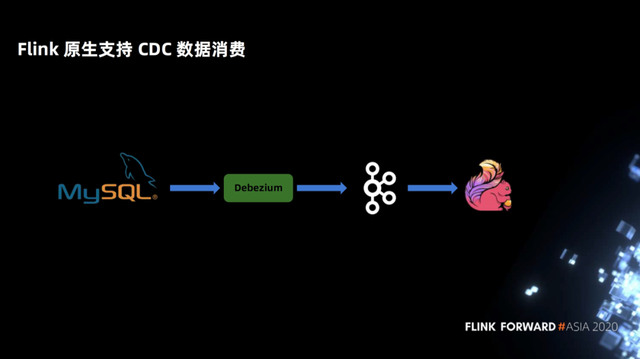
如下图示例,在 CDC 的处理当中,Flink 在只用声明一个 MySQL Binlog 的 DDL 语句,后面的 select 都不用感知 CDC 属性。
2.2 Flink 对 Change Log Stream 的支持
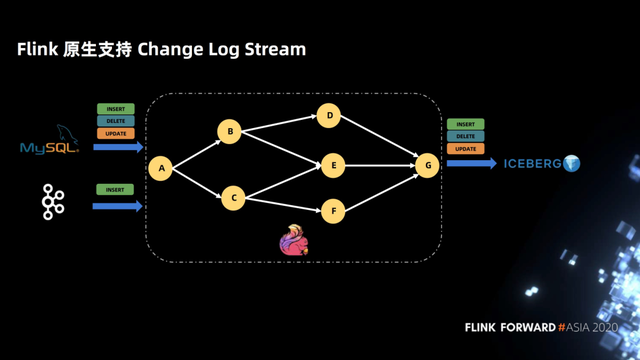
下图介绍的是 Flink 原生支持 Change Log Stream,Flink 在接入一个 Change Log Stream 之后,拓扑是不用关心 Change Log flag 的 SQL。拓扑完全是按照自己业务逻辑来定义,并且一直到最后写入 Iceberg,中间不用感知 Change Log 的 flag。
2.3 Flink + Iceberg CDC 导入方案评估
最后,Flink + Iceberg 的 CDC 导入方案的优点是什么?
对比之前的方案,Copy On Write 跟 Merge On Read 都有适用的场景,侧重点不同。Copy On Write 在更新部分文件的场景中,当只需要重写其中的一部分文件时是很高效的,产生的数据是纯 append 的全量数据集,在用于数据分析的时候也是最快的,这是 Copy On Write 的优势。
另外一个是 Merge On Read,即将数据连同 CDC flag 直接 append 到 Iceberg 当中,在 merge 的时候,把这些增量的数据按照一定的组织格式、一定高效的计算方式与全量的上一次数据进行一次 merge。这样的好处是支持近实时的导入和实时数据读取;这套计算方案的 Flink SQL 原生支持 CDC 的摄入,不需要额外的业务字段设计。
Iceberg 是统一的数据湖存储,支持多样化的计算模型,也支持各种引擎(包括 Spark、Presto、hive)来进行分析;产生的 file 都是纯列存的,对于后面的分析是非常快的;Iceberg 作为数据湖基于 snapshot 的设计,支持增量读取;Iceberg 架构足够简洁,没有在线服务节点,纯 table format 的,这给了上游平台方足够的能力来定制自己的逻辑和服务化。

三、如何实时写入读取
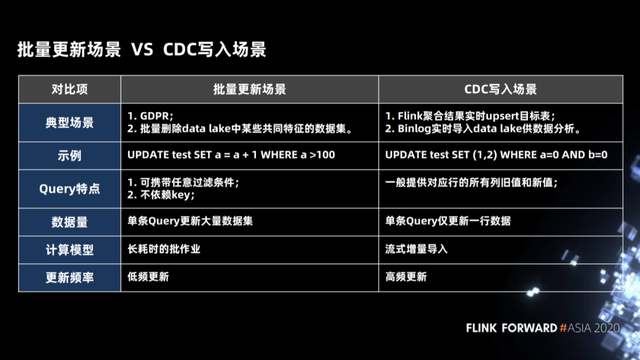
3.1 批量更新场景和 CDC 写入场景
首先我们来了解一下在整个数据湖里面批量更新的两个场景。
- 第一批量更新的这种场景,在这个场景中我们使用一个 SQL 更新了成千上万行的数据,比如欧洲的 GDPR 策略,当一个用户注销掉自己的账户之后,后台的系统是必须将这个用户所有相关的数据全部物理删除。
- 第二个场景是我们需要将 date lake 中一些拥有共同特性的数据删除掉,这个场景也是属于批量更新的一个场景,在这个场景中删除的条件可能是任意的条件,跟主键(Primary key)没有任何关系,同时这个待更新的数据集是非常大,这种作业是一个长耗时低频次的作业。
另外是 CDC 写入的场景,对于对 Flink 来说,一般常用的有两种场景,第一种场景是上游的 Binlog 能够很快速的写到 data lake 中,然后供不同的分析引擎做分析使用; 第二种场景是使用 Flink 做一些聚合操作,输出的流是 upsert 类型的数据流,也需要能够实时的写到数据湖或者是下游系统中去做分析。如下图示例中 CDC 写入场景中的 SQL 语句,我们使用单条 SQL 更新一行数据,这种计算模式是一种流式增量的导入,而且属于高频的更新。
3.2 Apache Iceberg 设计 CDC 写入方案需要考虑的问题
接下来我们看下 iceberg 对于 CDC 写入这种场景在方案设计时需要考虑哪些问题。
- 第一是正确性,即需要保证语义及数据的正确性,如上游数据 upsert 到 iceberg 中,当上游 upsert 停止后, iceberg 中的数据需要和上游系统中的数据保持一致。
- 第二是高效写入,由于 upsert 的写入频率非常高,我们需要保持高吞吐、高并发的写入。
- 第三是快速读取,当数据写入后我们需要对数据进行分析,这其中涉及到两个问题,第一个问题是需要支持细粒度的并发,当作业使用多个 task 来读取时可以保证为各个 task 进行均衡的分配以此来加速数据的计算;第二个问题是我们要充分发挥列式存储的优势来加速读取。
- 第四是支持增量读,例如一些传统数仓中的 ETL,通过增量读取来进行进一步数据转换。

3.3 Apache Iceberg Basic
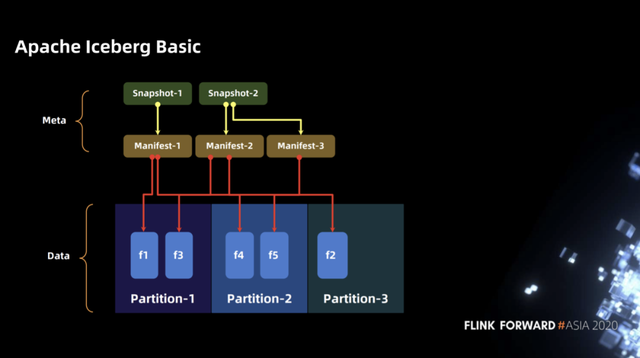
在介绍具体的方案细节之前,我们先了解一下 Iceberg 在文件系统中的布局,总体来讲 Iceberg 分为两部分数据,第一部分是数据文件,如下图中的 parquet 文件,每个数据文件对应一个校验文件(.crc文件)。第二部分是表元数据文件(Metadata 文件),包含 Snapshot 文件(snap-.avro)、Manifest 文件(.avro)、TableMetadata 文件(*.json)等。

下图展示了在 iceberg 中 snapshot、manifest 及 partition 中的文件的对应关系。下图中包含了三个 partition,第一个 partition 中有两个文件 f1、f3,第二个 partition 有两个文件f4、f5,第三个 partition 有一个文件f2。对于每一次写入都会生成一个 manifest 文件,该文件记录本次写入的文件与 partition 的对应关系。再向上层有 snapshot 的概念,snapshot 能够帮助快速访问到整张表的全量数据,snapshot 记录多个 manifest,如第二个 snapshot 包含 manifest2 和 manifest3。
3.4 INSERT、UPDATE、DELETE 写入
在了解了基本的概念,下面介绍 iceberg 中 insert、update、delete 操作的设计。
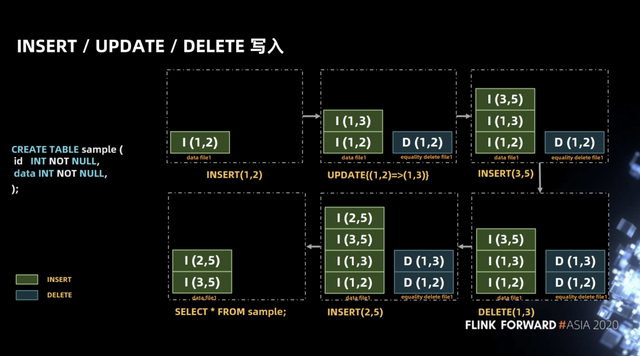
下图示例的 SQL 中展示的表包含两个字段即 id、data,两个字段都是 int 类型。在一个 transaction 中我们进行了图示中的数据流操作,首先插入了(1,2)一条记录,接下来将这条记录更新为(1,3),在 iceberg 中 update 操作将会拆为 delete 和 insert 两个操作。
这么做的原因是考虑到 iceberg 作为流批统一的存储层,将 update 操作拆解为 delete 和 insert 操作可以保证流批场景做更新时读取路径的统一,如在批量删除的场景下以 Hive 为例,Hive 会将待删除的行的文件 offset 写入到 delta 文件中,然后做一次 merge on read,因为这样会比较快,在 merge 时通过 position 将原文件和 delta 进行映射,将会很快得到所有未删除的记录。
接下来又插入记录(3,5),删除了记录(1,3),插入记录(2,5),最终查询是我们得到记录(3,5)(2,5)。
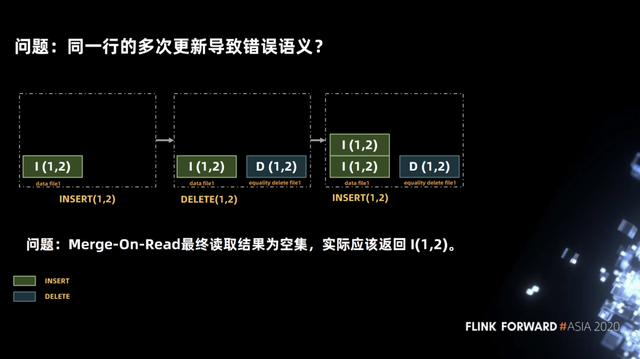
上面操作看上去非常简单,但在实现中是存在一些语义上的问题。如下图中,在一个 transaction 中首先执行插入记录(1,2)的操作,该操作会在 data file1 文件中写入 INSERT(1,2),然后执行删除记录(1,2)操作,该操作会在 equalify delete file1 中写入 DELETE(1,2),接着又执行插入记录(1,2)操作,该操作会在 data file1 文件中再写入INSERT(1,2),然后执行查询操作。
在正常情况下查询结果应该返回记录 INSERT(1,2),但在实现中,DELETE(1,2)操作无法得知删除的是 data file1 文件中的哪一行,因此两行 INSERT(1,2)记录都将被删除。
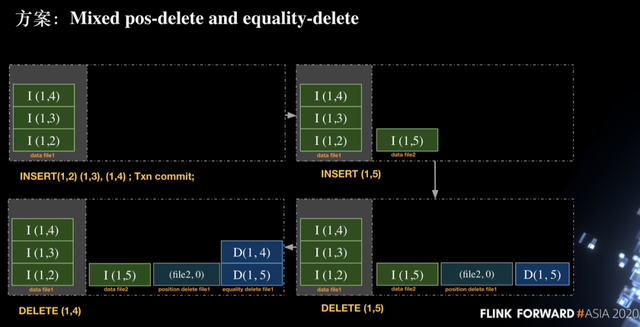
那么如何来解决这个问题呢,社区当前的方式是采用了 Mixed position-delete and equality-delete。Equality-delete 即通过指定一列或多列来进行删除操作,position-delete 是根据文件路径和行号来进行删除操作,通过将这两种方法结合起来以保证删除操作的正确性。
如下图我们在第一个 transaction 中插入了三行记录,即 INSERT(1,2)、INSERT(1,3)、INSERT(1,4),然后执行 commit 操作进行提交。接下来我们开启一个新的 transaction 并执行插入一行数据(1,5),由于是新的 transaction,因此新建了一个 data file2 并写入 INSERT(1,5)记录,接下来执行删除记录(1,5),实际写入 delete 时是:
在 position delete file1 文件写入(file2, 0),表示删除 data file2 中第 0 行的记录,这是为了解决同一个 transaction 内同一行数据反复插入删除的语义的问题。
在 equality delete file1 文件中写入 DELETE (1,5),之所以写入这个 delete 是为了确保本次 txn 之前写入的 (1,5) 能被正确删除。
然后执行删除(1,4)操作,由于(1,4)在当前 transaction 中未曾插入过,因此该操作会使用 equality-delete 操作,即在 equality delete file1 中写入(1,4)记录。在上述流程中可以看出在当前方案中存在 data file、position delete file、equality delete file 三类文件。
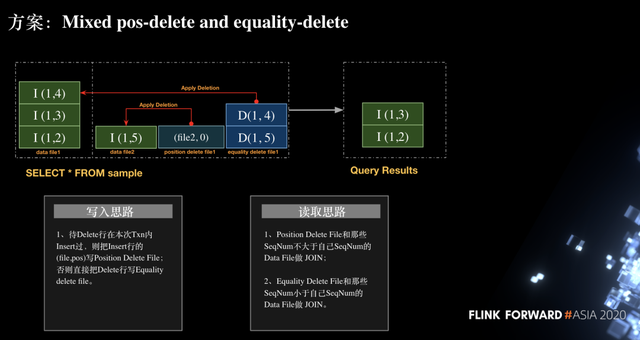
在了解了写入流程后,如何来读取呢。如下图所示,对于 position delete file 中的记录(file2, 0)只需和当前 transaction 的 data file 进行 join 操作,对于 equality delete file 记录(1,4)和之前的 transaction 中的 data file 进行 join 操作。最终得到记录 INSERT(1,3)、INSERT(1,2)保证了流程的正确性。
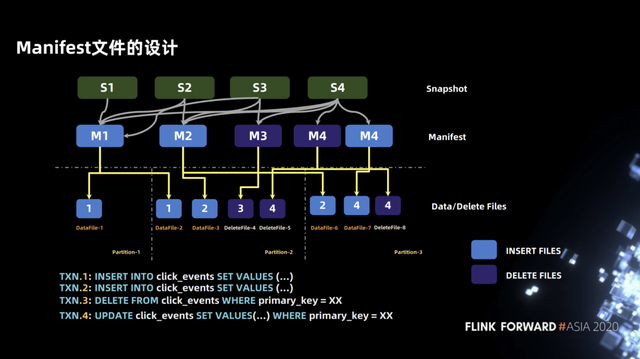
3.5 Manifest 文件的设计
上面介绍了 insert、update 及 delete,但在设计 task 的执行计划时我们对 manifest 进行了一些设计,目的是通过 manifest 能够快速到找到 data file,并按照数据大小进行分割,保证每个 task 处理的数据尽可能的均匀分布。
如下图示例,包含四个 transaction,前两个 transaction 是 INSERT 操作,对应 M1、M2,第三个 transaction 是 DELETE 操作,对应 M3,第四个 transaction 是 UPDATE 操作,包含两个 manifest 文件即 data manifest 和 delete manifest。
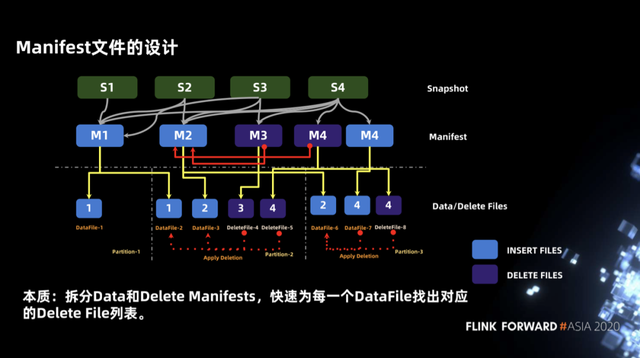
对于为什么要对 manifest 文件拆分为 data manifest 和 delete manifest 呢,本质上是为了快速为每个 data file 找到对应的 delete file 列表。可以看下图示例,当我们在 partition-2 做读取时,需要将 deletefile-4 与datafile-2、datafile-3 做一个 join 操作,同样也需要将 deletefile-5 与 datafile-2、datafile-3 做一个 join 操作。
以 datafile-3 为例,deletefile 列表包含 deletefile-4 和 deletefile-5 两个文件,如何快速找到对应的 deletefIle 列表呢,我们可以根据上层的 manifest 来进行查询,当我们将 manifest 文件拆分为 data manifest 和 delete manifest 后,可以将 M2(data manifest)与 M3、M4(delete manifest)先进行一次 join 操作,这样便可以快速的得到 data file 所对应的 delete file 列表。
3.6 文件级别的并发
另一个问题是我们需要保证足够高的并发读取,在 iceberg 中这点做得非常出色。在 iceberg 中可以做到文件级别的并发读取,甚至文件中更细粒度的分段的并发读取,比如文件有 256MB,可以分为两个 128MB 进行并发读取。这里举例说明,假设 insert 文件跟 delete 文件在两个 Bucket 中的布局方式如下图所示。

我们通过 manifest 对比发现,datafile-2 的 delete file 列表只有 deletefile-4,这样可以将这两个文件作为一个单独的 task(图示中Task-2)进行执行,其他的文件也是类似,这样可以保证每个 task 数据较为均衡的进行 merge 操作。
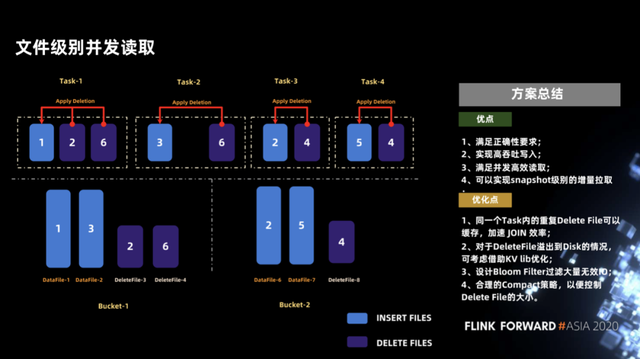
对于这个方案我们做了简单的总结,如下图所示。首先这个方案的优点可以满足正确性,并且可以实现高吞吐写入和并发高效的读取,另外可以实现 snapshot 级别的增量的拉取。
当前该方案还是比较粗糙,下面也有一些可以优化的点。
- 第一点,如果同一个 task 内的 delete file 有重复可以做缓存处理,这样可以提高 join 的效率。
- 第二点,当 delete file 比较大需要溢写到磁盘时可以使用 kv lib 来做优化,但这不依赖外部服务或其他繁重的索引。
- 第三点,可以设计 Bloom filter(布隆过滤器)来过滤无效的 IO,因为对于 Flink 中常用的 upsert 操作会产生一个 delete 操作和一个 insert 操作,这会导致在 iceberg 中 data file 和 delete file 大小相差不大,这样 join 的效率不会很高。如果采用 Bloom Filter,当 upsert 数据到来时,拆分为 insert 和 delete 操作,如果通过 bloom filter 过滤掉那些之前没有 insert 过数据的 delete 操作(即如果这条数据之前没有插入过,则不需要将 delete 记录写入到 delete file 中),这将极大的提高 upsert 的效率。
- 第四点,是需要一些后台的 compaction 策略来控制 delete file 文件大小,当 delete file 越少,分析的效率越高,当然这些策略并不会影响正常的读写。

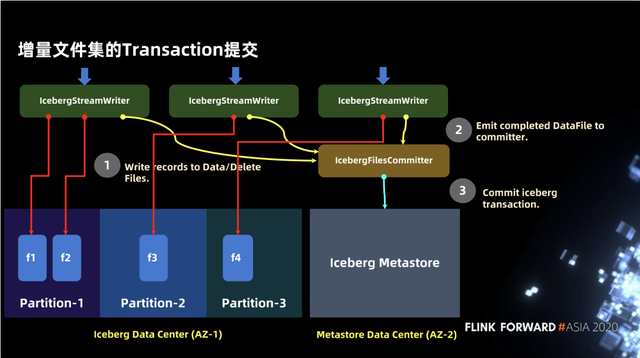
3.7 增量文件集的 Transaction 提交
前面介绍了文件的写入,下图我们介绍如何按照 iceberg 的语义进行写入并且供用户读取。主要分为数据和 metastore 两部分,首先会有 IcebergStreamWriter 进行数据的写入,但此时写入数据的元数据信息并没有写入到 metastore,因此对外不可见。第二个算子是 IcebergFileCommitter,该算子会将数据文件进行收集, 最终通过 commit transaction 来完成写入。
在 Iceberg 中并没有其他任何其他第三方服务的依赖,而 Hudi 在某些方面做了一些 service 的抽象,如将 metastore 抽象为独立的 Timeline,这可能会依赖一些独立的索引甚至是其他的外部服务来完成。
四、未来规划
下面是我们未来的一些规划,首先是 Iceberg 内核的一些优化,包括方案中涉及到的全链路稳定性测试及性能的优化, 并提供一些 CDC 增量拉取的相关 Table API 接口。
在 Flink 集成上,会实现 CDC 数据的自动和手动合并数据文件的能力,并提供 Flink 增量拉取 CDC 数据的能力。
在其他生态集成上,我们会对 Spark、Presto 等引擎进行集成,并借助 Alluxio 加速数据查询。

作者:阿里云实时计算Flink
原文链接
本文为阿里云原创内容,未经允许不得转载















)



