简介: 本文由 Bigo 计算平台负责人徐帅分享,主要介绍 Bigo 实时计算平台建设实践的介绍
本文由 Bigo 计算平台负责人徐帅分享,主要介绍 Bigo 实时计算平台建设实践的介绍。内容包括:
- Bigo 实时计算平台的发展历程
- 特色与改进
- 业务场景
- 效率提升
- 总结展望
一、Bigo 实时计算平台的发展历程
今天主要跟大家分享 Bigo 实时计算平台的建设历程,我们在建设过程中解决的一些问题,以及所做的一些优化和改进。首先进入第一个部分,Bigo 实时计算平台的发展历程。
先简单介绍一下 Bigo 的业务。它主要有三大 APP,分别是 Live, Likee 和 Imo。其中,Live 为全球用户提供直播服务。Likee 是短视频的创作与分享的 App,跟快手和抖音都非常相似。Imo 是一个全球免费的通讯工具。这几个主要的产品都是跟用户相关的,所以我们的业务要围绕着如何提高用户的转化率和留存率。而实时计算平台作为基础的平台,主要是为以上业务服务的,Bigo 平台的建设也要围绕上述业务场景做一些端到端的解决方案。

Bigo 实时计算的发展历程大概分为三个阶段。
- 在 2018 年之前,实时作业还非常少,我们使用 Spark Streaming 来做一些实时的业务场景。
- 从 18 年到 19 年,随着 Flink 的兴起,大家普遍认为 Flink 是最好的实时计算引擎,我们开始使用 Flink,离散发展。各个业务线自己搭一个 Flink 来简单使用。
- 从 2019 年开始,我们把所有使用 Flink 的业务统一到 Bigo 实时计算平台上。通过两年的建设,目前所有实时计算的场景都运行在 Bigo 平台上。

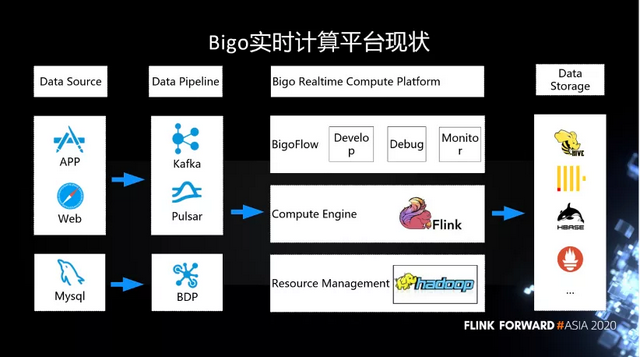
如下图所示,这是 Bigo 实时计算平台的现状。在 Data Source 端,我们的数据都是用户的行为日志,主要来自于 APP 和客户端。还有一部分用户的信息存在 MySQL 中。
这些信息都会经过消息队列,最终采集到我们的平台里。消息队列主要用的是 Kafka,现在也在逐渐的采用 Pulsar。而 MySQL 的日志主要是通过 BDP 进入实时计算平台。在实时计算平台这块,底层也是基于比较常用的 Hadoop 生态圈来做动态资源的管理。在上面的引擎层,已经统一到 Flink,我们在上面做一些自己的开发与优化。在这种一站式的开发、运维与监控的平台上,我们内部做了一个 BigoFlow 的管理平台。用户可以在 BigoFlow 上开发、调试和监控。最终在数据存储上,我们也是对接了 Hive、ClickHouse、HBase 等等。
二、Bigo 实时计算平台的特色与改进
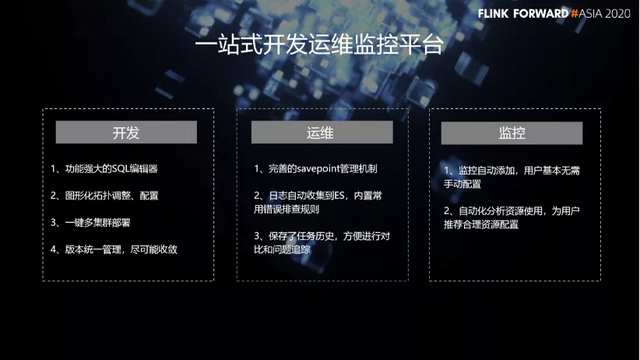
接下来我们看一下 Bigo 计算平台的特色,以及我们做的改进。作为一个发展中的公司,我们平台建设的重点还是尽可能的让业务人员易于使用。从而促进业务的发展,扩大规模。我们希望建设一个一站式的开发、运维、监控平台。
首先,在 BigoFlow 上面,用户可以非常方便的开发。我们在开发这一块的特色与改进包括:
- 功能强大的 SQL 编辑器。
- 图形化拓扑调整、配置。
- 一键多集群部署。
- 版本统一管理,尽可能收敛。
另外,在运维这一块,我们也做了许多改进:
- 完善的 savepoint 管理机制。
- 日志自动收集到 ES,内置常 用错误排查规则。
- 保存了任务历史,方便进行对比和问题追踪。
最后是监控这一块,我们的特色有:
- 监控自动添加,用户基本无需手动配置。
- 自动化分析资源使用,为用户推荐合理资源配置。
我们元数据的存储主要有三个地方。分别是 Kafka、Hive 和 ClickHouse。目前我们能够把所有的存储系统的元数据全面打通。这会极大的方便用户,同时降低使用成本。
- Kafka 的元数据打通之后,就可以一次导入,无限使用,无需 DDL。
- Flink 与 Hive 也做到了完全打通,用户在使用 Hive 表的时候,无需 DDL,直接使用即可。
- ClickHouse 也类似,可自动追踪到 Kafka 的 topic。

其实,我们今天提供的不仅仅是一个平台,还包括在通用场景提供了端到端的解决方案。在 ETL 场景,我们的解决方案包括:
- 通用打点完全自动化接入。
- 用户无需开发任何代码。
- 数据进入 hive。
- 自动更新 meta。
在监控这一块,我们的特色有:
- 数据源自动切换。
- 监控规则不变。
- 结果自动存入 prometheus。
第三个场景是 ABTest 场景,传统的 ABTest 都是通过离线的方式,隔一天之后才能产出结果。那么我们今天将 ABTest 转为实时的方式去输出,通过流批一体的方式大大提高了 ABTest 的效率。

对 Flink 的改进主要体现在这几个方面:
- 第一,在 connector 层面,我们自定义了很多的 connector,对接了公司用到的所有系统。
- 第二,在数据格式化层面,我们对 Json,Protobuf,Baina 三种格式做了非常完整的支持。用户无需自己做解析,直接使用就可以。
- 第三,公司所有的数据都直接落到 Hive 里面,在 Hive 的使用上是领先于社区的。包括流式的读取,EventTime 支持,维表分区过滤,Parquet 复杂类型支持,等等。
- 第四,在 State 层面我们也做了一些优化。包括 SSD 支持,以及 RocksDB 优化。

三、Bigo 典型的业务场景
传统的打点入库,都是通过 Kafka 到 Flume,然后进入到 Hive,最后到 ClickHouse。当然 ClickHouse 里面大部分是从 Hive 导进去的,还有一部分是通过 Kafka 直接写进去的。
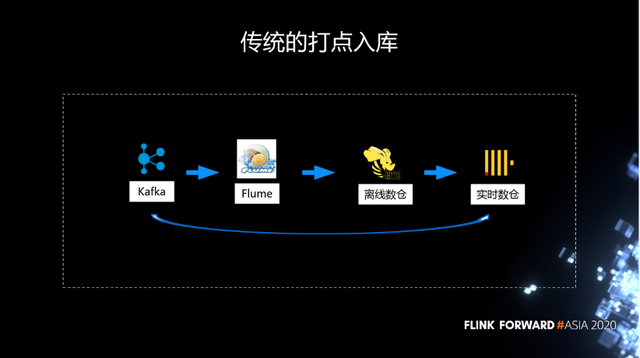
这个链路是一个非常老的链路,它存在以下问题:
- 第一,不稳定,flume 一旦有异常,经常会出现数据丢失和重复。
- 第二,扩展能力差。面对突然到来的流量高峰,很难去扩展。
- 第三,业务逻辑不易调整。

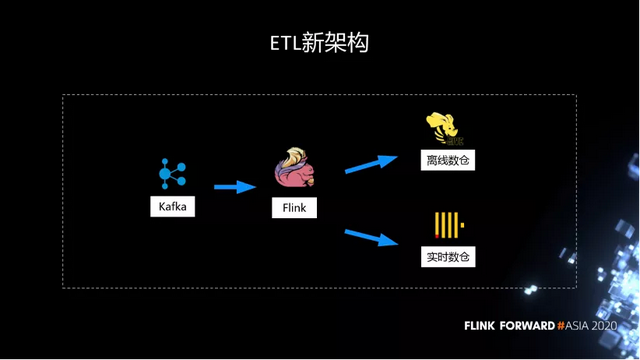
所以我们在建设 Flink 之后,做了非常多的工作。把原先 Flume 到 Hive 的流程替换掉,今天所有的 ETL 都是通过 Kafka,再经过 Flink,所有的打点都会进入到 Hive 离线数仓,作为历史的保存,使数据不丢失。同时,因为很多作业需要实时的分析,我们在另外一个链路,从 Flink 直接进入 ClickHouse 实时数仓来分析。
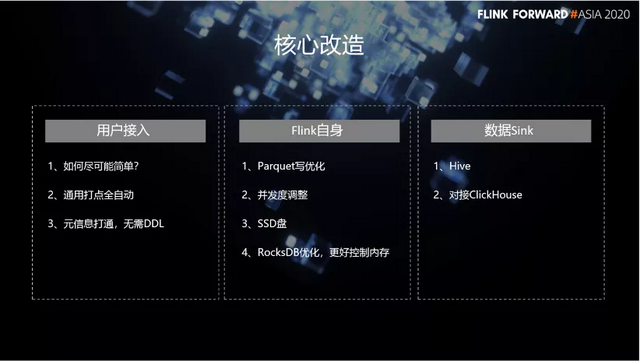
在这个过程中,我们做了一些核心改造,分为三大块。首先,在用户接入这一块,我们的改造包括:
- 尽可能简单。
- 通用打点全自动。
- 元信息打通,无需 DDL。
另外,在 Flink 自身这一块,我们的改造有:
- Parquet 写优化。
- 并发度调整。
- 通过 SSD 盘,支持大状态的作业。
- RocksDB 优化,更好控制内存。
最后,在数据 Sink 这一块,我们做了非常多的定制化的开发,不仅支持 Hive,也对接了 ClickHouse。
四、Flink 为业务带来的效率提升
下面主要介绍 ABTest 场景下,我们做的一些改造。比如说,数据全部落到 Hive 之后,就开始启动离线的计算,可能经过无数个工作流之后,最终产出了一张大宽表。表上可能有很多个维度,记录了分组实验的结果。数据分析师拿到结果之后,去分析哪些实验比较好。
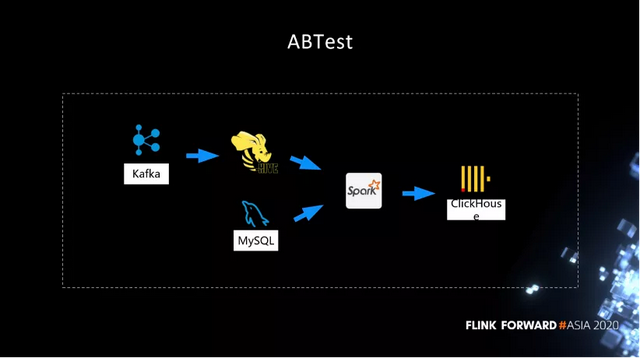
虽然这个结构很简单,但是流程太长,出结果晚,并且不易增加维度。主要问题其实在 Spark 这块,这个作业有无数个工作流去执行,一个工作流要等到另外一个执行完才能去调度。而且离线资源没有非常好的保证。我们之前最大的问题是 ABTest 上一天的结果要等到下一天的下午才能输出,数据分析师经常反馈上午没法干活,只能下午快下班的时候才能开始分析。

所以我们就开始利用 Flink 实时计算能力去解决时效性的问题。不同于 Spark 任务要等上一个结果才能输出,Flink 直接从 Kafka 消费。基本上可以在上午出结果。但是当时因为它最终产出的结果维度非常多,可能有几百个维度,这个时候 State 就非常大,经常会遇到 OOM。
因此我们在第一步的改造过程中取了一个折中,没有直接利用 Flink 在一个作业里面把所有的维度 join 起来,而是把它拆分成了几个作业。每个作业计算一部分维度,然后把这些结果先利用 HBase 做了一个 join,再把 join 的结果导入到 ClickHouse 里面。
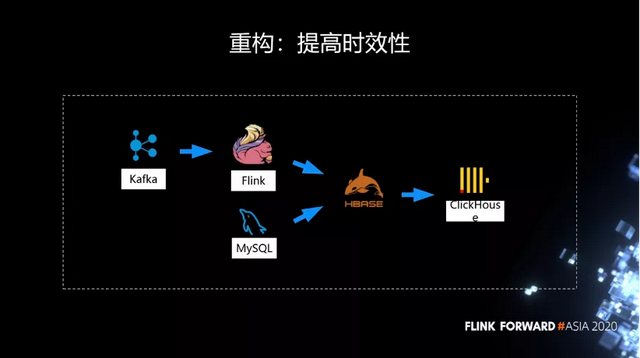
在改造的过程中,我们发现了一个问题。可能作业需要经常的调整逻辑,调完后要去看结果对不对,那么这需要 1 天的时间窗口。如果直接读历史数据,Kafka 就要保存很久的数据,读历史数据的时候,要到磁盘上去读,对 Kafka 的压力就非常大。如果不读历史数据,因为只有零点才能触发,那么今天改了逻辑,要等到一天之后才能够去看结果,会导致调试迭代非常慢。

前面提到我们的所有数据在 Hive 里面,当时还是 1.9 的版本,我们就支持了从 Hive 里面流式的去读取数据。因为这些数据都是用 EventTime 去触发,我们在 Hive 上支持了用 EventTime 去触发。为了流批统一,这里没有用 Spark,因为如果用 Spark 去做作业验证,需要维护两套逻辑。
我们在 Flink 上面用流批一体的方式去做离线的补数据,或者离线的作业验证。而实时的这条用于日常作业的产生。

刚才说了这其实是一个折中的方案,因为对 HBase 有依赖,也没有充分发挥 Flink 的能力。所以我们进行了第二轮的改造,彻底去除对 HBase 的依赖。
经过第二轮迭代之后,我们今天在 Flink 上已经能够扛住大表的天级别的窗口交易。这个流批统一的方案已经上线了,我们直接通过 Flink 去计算完整个大宽表,在每天的窗口触发之后,将结果直接写到 ClickHouse 里面,基本上凌晨就可以产出结果。
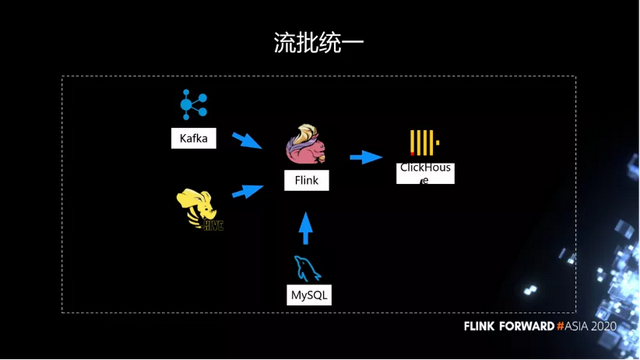
在整个过程中间,我们对 Flink 的优化包括:
- State 支持 SSD 盘。
- 流式读取 Hive,支持 EventTime。
- Hive 维表 join,支持 partition 分区 load。
- 完善的 ClickHouse Sinker。
优化之后,我们的小时级任务再也不延迟了,天级别完成时间由下午提早到上班前,大大加速了迭代效率。

五、总结与展望
总结一下实时计算在 Bigo 的现状。首先,非常贴近业务。其次,跟公司里用到的所有生态无缝对接,基本上让用户不需要做任何的开发。另外,实时数仓已现雏形。最后,我们的场景跟大厂相比还不够丰富。一些比较典型的实时场景,由于业务需求没有那么高,很多业务还没有真正的切换到实时场景上来。

我们的发展规划有两大块。
- 第一块是拓展更多的业务场景。包括实时机器学习,广告,风控和实时报表。在这些领域,要更多的去推广实时计算的概念,去跟业务对接好。
- 另外一块就是在 Flink 自身上面,我们内部有很多场景要做。比如说,支持大 Hive 维表 join,自动化资源配置,CGroup 隔离,等等。以上就是我们在未来要做的一些工作。

作者:徐帅
原文链接
本文为阿里云原创内容,未经允许不得转载









)









