简介: 本文会介绍 Kubernetes 可观测性系统的构建,以及基于阿里云云产品实现 Kubernetes 可观测系统构建的最佳实践。
作者:佳旭 阿里云容器服务技术专家
引言
Kubernetes 在生产环境应用的普及度越来越广、复杂度越来越高,随之而来的稳定性保障挑战也越来越大。
如何构建全面深入的可观测性架构和体系,是提升系统稳定性的关键之因素一。ACK将可观测性最佳实践进行沉淀,以阿里云产品功能的能力对用户透出,可观测性工具和服务成为基础设施,赋能并帮助用户使用产品功能,提升用户 Kubernetes 集群的稳定性保障和使用体验。
本文会介绍 Kubernetes 可观测性系统的构建,以及基于阿里云云产品实现 Kubernetes 可观测系统构建的最佳实践。
Kubernetes 系统的可观测性架构
Kubernetes 系统对于可观测性方面的挑战包括:
- K8s 系统架构的复杂性。系统包括控制面和数据面,各自包含多个相互通信的组件,控制面和数据间之间通过 kube-apiserver 进行桥接聚合。
- 动态性。Pod、Service 等资源动态创建以及分配 IP,Pod 重建后也会分配新的资源和 IP,这就需要基于动态服务发现来获取监测对象。
- 微服务架构。应用按照微服务架构分解成多个组件,每个组件副本数可以根据弹性进行自动或者人工控制。
针对 Kubernetes 系统可观测性的挑战,尤其在集群规模快速增长的情况下,高效可靠的 Kubernetes 系统可观测性能力,是系统稳定性保障的基石。
那么,如何提升建设生产环境下的 Kubernetes 系统可观测性能力呢?
Kubernetes 系统的可观测性方案包括指标、日志、链路追踪、K8s Event 事件、NPD 框架等方式。每种方式可以从不同维度透视 Kubernetes 系统的状态和数据。在生产环境,我们通常需要综合使用各种方式,有时候还要运用多种方式联动观测,形成完善立体的可观测性体系,提高对各种场景的覆盖度,进而提升 Kubernetes 系统的整体稳定性。下面会概述生产环境下对 K8s 系统的可观测性解决方案。
指标(Metrics)
Prometheus 是业界指标类数据采集方案的事实标准,是开源的系统监测和报警框架,灵感源自 Google 的 Borgmon 监测系统。2012 年,SoundCloud 的 Google 前员工创造了 Prometheus,并作为社区开源项目进行开发。2015 年,该项目正式发布。2016 年,Prometheus 加入 CNCF 云原生计算基金会。
Prometheus 具有以下特性:
- 多维的数据模型(基于时间序列的 Key、Value 键值对)
- 灵活的查询和聚合语言 PromQL
- 提供本地存储和分布式存储
- 通过基于 HTTP 的 Pull 模型采集时间序列数据
- 可利用 Pushgateway(Prometheus 的可选中间件)实现 Push 模式
- 可通过动态服务发现或静态配置发现目标机器
- 支持多种图表和数据大盘
Prometheus 可以周期性采集组件暴露在 HTTP(s) 端点的/metrics 下面的指标数据,并存储到 TSDB,实现基于 PromQL 的查询和聚合功能。
对于 Kubernetes 场景下的指标,可以从如下角度分类:
- 容器基础资源指标
采集源为 kubelet 内置的 cAdvisor,提供容器内存、CPU、网络、文件系统等相关的指标,指标样例包括:
容器当前内存使用字节数 container_memory_usage_bytes;
容器网络接收字节数 container_network_receive_bytes_total;
容器网络发送字节数 container_network_transmit_bytes_total,等等。
- Kubernetes 节点资源指标
采集源为 node_exporter,提供节点系统和硬件相关的指标,指标样例包括:节点总内存 node_memory_MemTotal_bytes,节点文件系统空间 node_filesystem_size_bytes,节点网络接口 ID node_network_iface_id,等等。基于该类指标,可以统计节点的 CPU/内存/磁盘使用率等节点级别指标。
- Kubernetes 资源指标
采集源为 kube-state-metrics,基于 Kubernetes API 对象生成指标,提供 K8s 集群资源指标,例如 Node、ConfigMap、Deployment、DaemonSet 等类型。以 Node 类型指标为例,包括节点 Ready 状态指标 kube_node_status_condition、节点信息kube_node_info 等等。
- Kubernetes 组件指标
Kubernetes 系统组件指标。例如 kube-controller-manager, kube-apiserver,kube-scheduler, kubelet,kube-proxy、coredns 等。
Kubernetes 运维组件指标。可观测类包括 blackbox_operator, 实现对用户自定义的探活规则定义;gpu_exporter,实现对 GPU 资源的透出能力。
Kubernetes 业务应用指标。包括具体的业务 Pod在/metrics 路径透出的指标,以便外部进行查询和聚合。
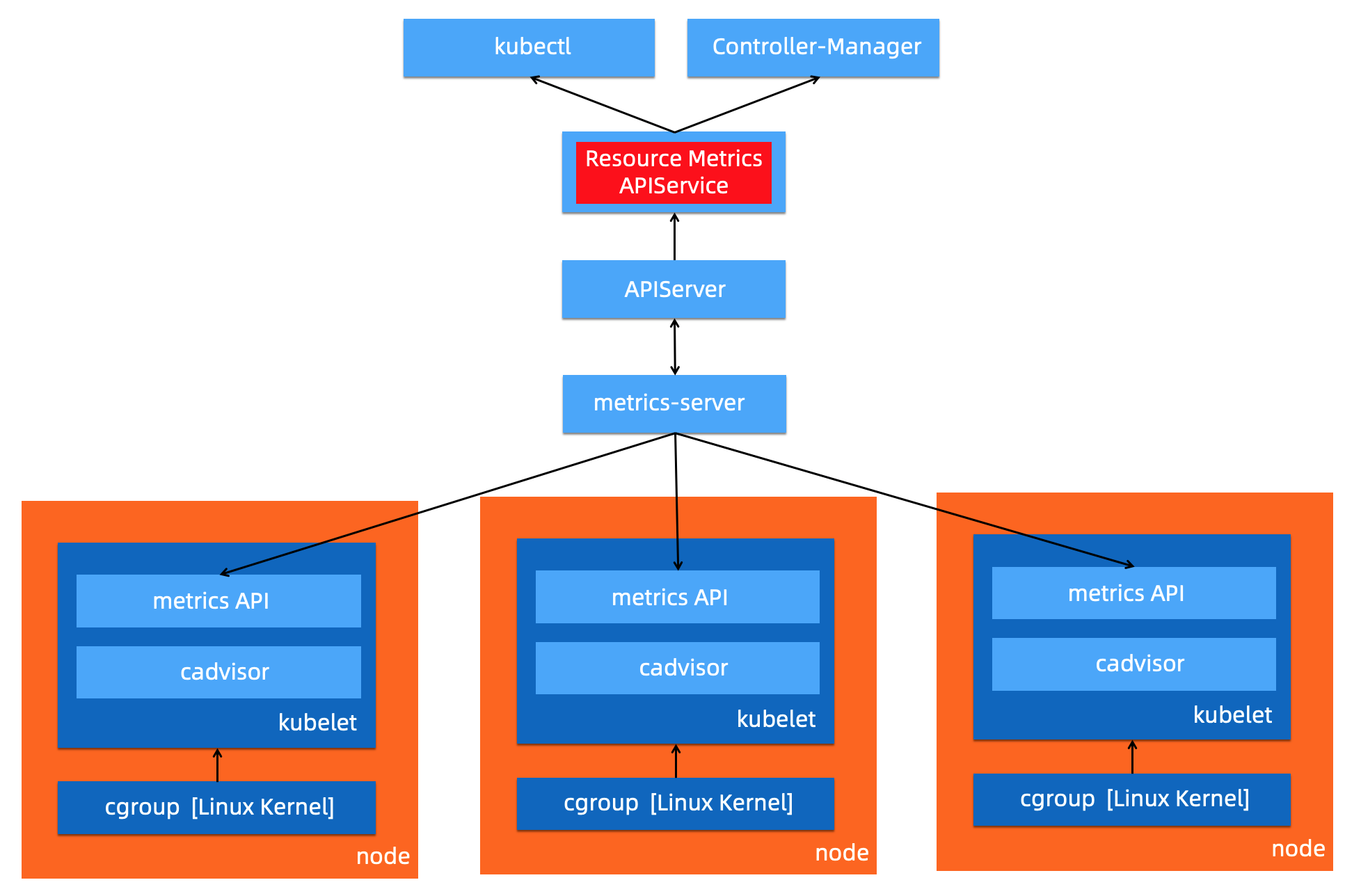
除了上述指标,K8s 提供了通过 API 方式对外透出指标的监测接口标准,具体包括 Resource Metrics,Custom Metrics 和 External Metrics 三类。
| 监测接口标准 | APIService 地址 | 接口使用场景描述 |
| Resource Metrics | metrics.k8s.io http://metrics.k8s.io/ | 主要用于 Kubernetes 内置的消费链路,通常由 Metrcis-Server 提供。 |
| Custom Metrics | custom.metrics.k8s.io http://custom.metrics.k8s.io/ | 主要的实现为 Prometheus,提供资源监测和自定义监测。 |
| External Metrics | external.metrics.k8s.io http://external.metrics.k8s.io/ | 主要的实现为云厂商的 Provider,提供云资源的监测指标。 |
Resource Metrics 类对应接口 metrics.k8s.io,主要的实现就是 metrics-server,它提供资源的监测,比较常见的是节点级别、pod 级别、namespace 级别。这些指标可以通过 kubectl top 直接访问获取,或者通过 K8s controller 获取,例如 HPA(Horizontal Pod Autoscaler)。系统架构以及访问链路如下:
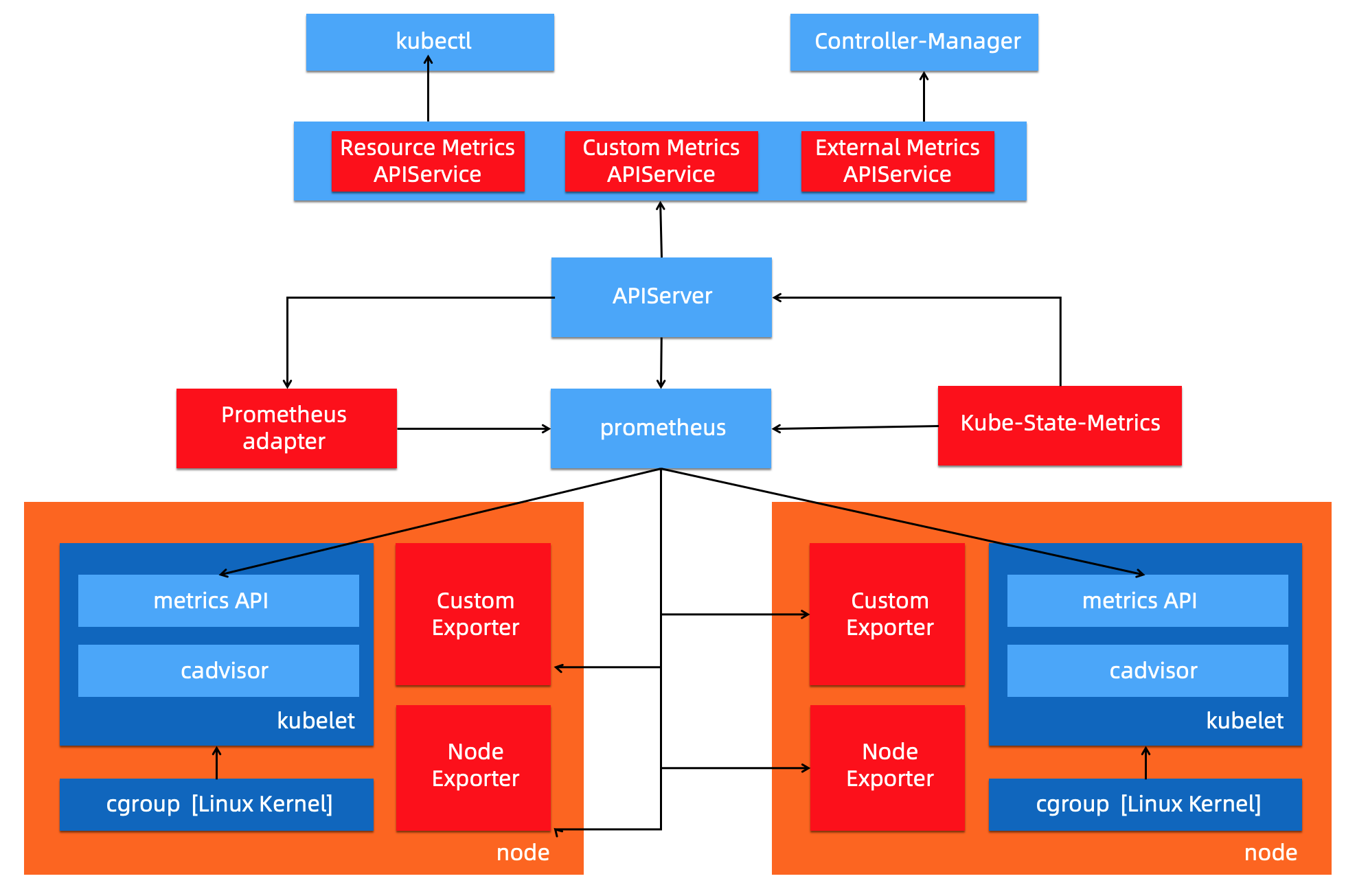
Custom Metrics 对应的 API 是 custom.metrics.k8s.io,主要的实现是 Prometheus。它提供的是资源监测和自定义监测,资源监测和上面的资源监测其实是有覆盖关系的,而这个自定义监测指的是:比如应用上面想暴露一个类似像在线人数,或者说调用后面的这个数据库的 MySQL 的慢查询。这些其实都是可以在应用层做自己的定义的,然后并通过标准的 Prometheus 的 client,暴露出相应的 metrics,然后再被 Prometheus 进行采集。
而这类的接口一旦采集上来也是可以通过类似像 custom.metrics.k8s.io 这样一个接口的标准来进行数据消费的,也就是说现在如果以这种方式接入的 Prometheus,那你就可以通过 custom.metrics.k8s.io 这个接口来进行 HPA,进行数据消费。系统架构以及访问链路如下:
External Metrics 。因为我们知道 K8s 现在已经成为了云原生接口的一个实现标准。很多时候在云上打交道的是云服务,比如说在一个应用里面用到了前面的是消息队列,后面的是 RBS 数据库。那有时在进行数据消费的时候,同时需要去消费一些云产品的监测指标,类似像消息队列中消息的数目,或者是接入层 SLB 的 connection 数目,SLB 上层的 200 个请求数目等等,这些监测指标。
那怎么去消费呢?也是在 K8s 里面实现了一个标准,就是 external.metrics.k8s.io。主要的实现厂商就是各个云厂商的 provider,通过这个 provider 可以通过云资源的监测指标。在阿里云上面也实现了阿里巴巴 cloud metrics adapter 用来提供这个标准的 external.metrics.k8s.io 的一个实现。
日志(Logging)
概要来说包括:
- 主机内核的日志。主机内核日志可以协助开发者诊断例如:网络栈异常,驱动异常,文件系统异常,影响节点(内核)稳定的异常。
- Runtime 日志。最常见的运行时是 Docker,可以通过 Docker 的日志排查例如删除 Pod Hang 等问题。
- K8s 组件日志。APIServer 日志可以用来审计,Scheduler 日志可以诊断调度,etcd 日志可以查看存储状态,Ingress 日志可以分析接入层流量。
- 应用日志。可以通过应用日志分析查看业务层的状态,诊断异常。
日志的采集方式分为被动采集和主动推送两种,在 K8s 中,被动采集一般分为 Sidecar 和 DaemonSet 两种方式,主动推送有 DockerEngine 推送和业务直写两种方式。
- DockerEngine 本身具有 LogDriver 功能,可通过配置不同的 LogDriver 将容器的 stdout 通过 DockerEngine 写入到远端存储,以此达到日志采集的目的。这种方式的可定制化、灵活性、资源隔离性都很低,一般不建议在生产环境中使用;
- 业务直写是在应用中集成日志采集的 SDK,通过 SDK 直接将日志发送到服务端。这种方式省去了落盘采集的逻辑,也不需要额外部署 Agent,对于系统的资源消耗最低,但由于业务和日志 SDK 强绑定,整体灵活性很低,一般只有日志量极大的场景中使用;
- DaemonSet 方式在每个 node 节点上只运行一个日志 agent,采集这个节点上所有的日志。DaemonSet 相对资源占用要小很多,但扩展性、租户隔离性受限,比较适用于功能单一或业务不是很多的集群;
- Sidecar 方式为每个 POD 单独部署日志 agent,这个 agent 只负责一个业务应用的日志采集。Sidecar 相对资源占用较多,但灵活性以及多租户隔离性较强,建议大型的 K8s 集群或作为 PaaS 平台为多个业务方服务的集群使用该方式。
挂载宿主机采集、标准输入输出采集、Sidecar 采集。
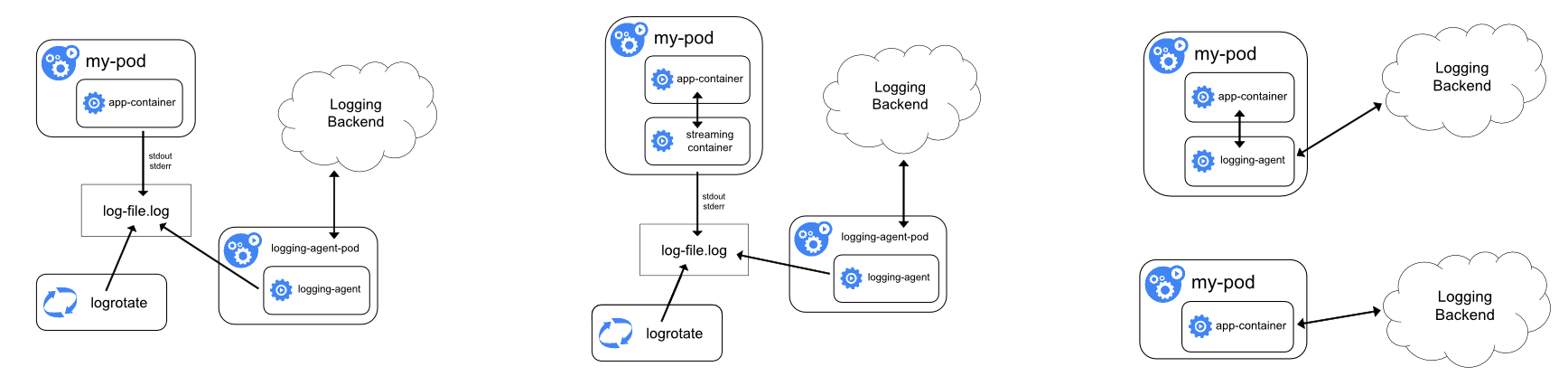
总结下来:
- DockerEngine 直写一般不推荐;
- 业务直写推荐在日志量极大的场景中使用;
- DaemonSet 一般在中小型集群中使用;
- Sidecar 推荐在超大型的集群中使用。
事件(Event)
事件监测是适用于 Kubernetes 场景的一种监测方式。事件包含了发生的时间、组件、等级(Normal、Warning)、类型、详细信息,通过事件我们能够知道应用的部署、调度、运行、停止等整个生命周期,也能通过事件去了解系统中正在发生的一些异常。
K8s 中的一个设计理念,就是基于状态机的一个状态转换。从正常的状态转换成另一个正常的状态的时候,会发生一个 Normal 的事件,而从一个正常状态转换成一个异常状态的时候,会发生一个 Warning 的事件。通常情况下,Warning 的事件是我们比较关心的。事件监测就是把 Normal 的事件或者是 Warning 事件汇聚到数据中心,然后通过数据中心的分析以及报警,把相应的一些异常通过像钉钉、短信、邮件等方式进行暴露,实现与其他监测的补充与完善。
Kubernetes中的事件是存储在 etcd 中,默认情况下只保存 1 个小时,无法实现较长周期范围的分析。将事件进行长期存储以及定制化开发后,可以实现更加丰富多样的分析与告警:
- 对系统中的异常事件做实时告警,例如 Failed、Evicted、FailedMount、FailedScheduling 等。
- 通常问题排查可能要去查找历史数据,因此需要去查询更长时间范围的事件(几天甚至几个月)。
- 事件支持归类统计,例如能够计算事件发生的趋势以及与上一时间段(昨天/上周/发布前)对比,以便基于统计指标进行判断和决策。
- 支持不同的人员按照各种维度去做过滤、筛选。
- 支持自定义的订阅这些事件去做自定义的监测,以便和公司内部的部署运维平台集成。
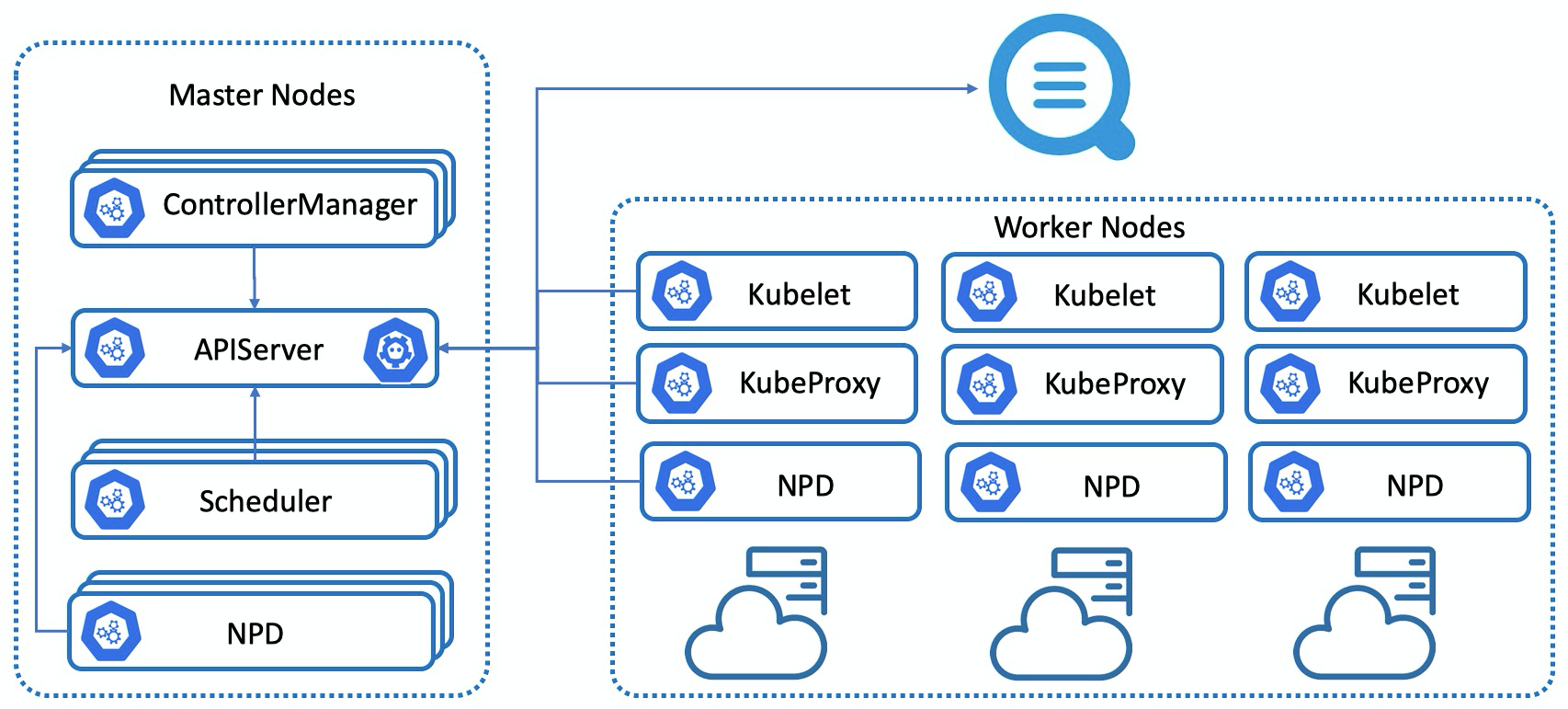
NPD(Node Problem Detector)框架
Kubernetes 集群及其运行容器的稳定性,强依赖于节点的稳定性。Kubernetes 中的相关组件只关注容器管理相关的问题,对于硬件、操作系统、容器运行时、依赖系统(网络、存储等)并不会提供更多的检测能力。NPD(Node Problem Detector)针对节点的稳定性提供了诊断检查框架,在默认检查策略的基础上,可以灵活扩展检查策略,可以将节点的异常转换为 Node 的事件,推送到 APIServer 中,由同一的 APIServer 进行事件管理。
NPD 支持多种异常检查,例如:
- 基础服务问题:NTP 服务未启动
- 硬件问题:CPU、内存、磁盘、网卡损坏
- Kernel 问题:Kernel hang,文件系统损坏
- 容器运行时问题:Docker hang,Docker 无法启动
- 资源问题:OOM 等
综上,本章节总结了常见的 Kubernetes 可观测性方案。在生产环境,我们通常需要综合使用各种方案,形成立体多维度、相互补充的可观测性体系;可观测性方案部署后,需要基于上述方案的输出结果快速诊断异常和错误,有效降低误报率,并有能力保存、回查以及分析历史数据;进一步延伸,数据可以提供给机器学习以及 AI 框架,实现弹性预测、异常诊断分析、智能运维 AIOps 等高级应用场景。
这需要可观测性最佳实践作为基础,包括如何设计、插件化部署、配置、升级上述各种可观测性方案架构,如何基于输出结果快速准确诊断分析跟因等等。阿里云容器服务 ACK 以及相关云产品(监测服务 ARMS、日志服务 SLS 等),将云厂商的最佳实践通过产品化能力实现、赋能用户,提供了完善全面的解决方案,可以让用户快速部署、配置、升级、掌握阿里云的可观测性方案,显著提升了企业上云和云原生化的效率和稳定性、降低技术门槛和综合成本。
下面将以 ACK 最新的产品形态 ACK Pro 为例,结合相关云产品,介绍 ACK 的可观测性解决方案和最佳实践。
ACK可观测性能力
指标(Metrics)可观测性方案
对于指标类可观测性,ACK 可以支持开源 Prometheus 监测和阿里云 Prometheus 监测(阿里云 Prometheus 监测是 ARMS 产品子产品)两种可观测性方案。
开源 Prometheus 监测,以 helm 包形式提供、适配阿里云环境、集成了钉钉告警、存储等功能;部署入口在控制台的应用目录中 ack-prometheus-operator,用户配置后可以在 ACK 控制台一键部署。用户只需要在阿里云 ACK 控制台配置 helm 包参数,就可以定制化部署。
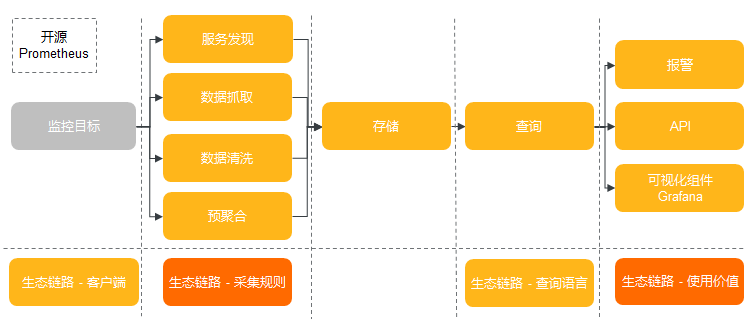
阿里云 Prometheus监测,是 ARMS 产品子产品。应用实时监测服务 (Application Real-Time Monitoring Service, 简称 ARMS) 是一款应用性能管理产品,包含前端监测,应用监测和 Prometheus 监测三大子产品。
在 2021 年的 Gartner 的 APM 魔力象限评测中,阿里云应用实时监测服务(ARMS)作为阿里云 APM 的核心产品,联合云监测以及日志服务共同参与。Gartner 评价阿里云 APM:
- 中国影响力最强:阿里云是中国最大的云服务提供商,阿里云用户可以使用云上监测工具来满足其可观测性需求。
- 开源集成:阿里云非常重视将开源标准和产品(例如 Prometheus)集成到其平台中。
- 成本优势:与在阿里云上使用第三方 APM 产品相比,阿里云 APM 产品具有更高的成本效益。
下图概要对比了开源 Prometheus 和阿里云 Prometheus 的模块划分和数据链路。
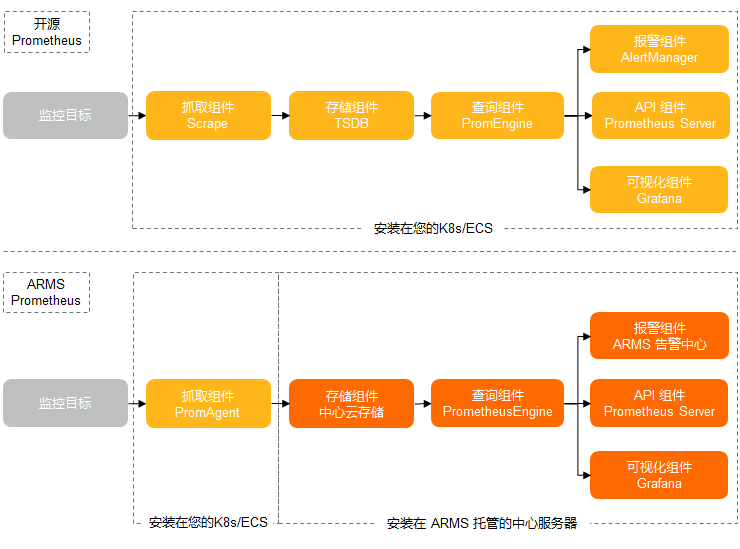
ACK 支持 CoreDNS、集群节点、集群概况等 K8s 可观测性能力;除此之外,ACK Pro 还支持托管的管控组件 Kube API Server、Kube Scheduler 和 Etcd 的可观测性能力,并持续迭代。用户可以通过在阿里云 Prometheus 中丰富的监测大盘,结合告警能力,快速发现 K8s 集群的系统问题以及潜在风险,及时采取相应措施以保障集群稳定性。监测大盘集成了 ACK 最佳实践的经验,可以帮助用户从多维度分析分析、定位问题。下面介绍如何基于最佳实践设计可观测性大盘,并列举使用监测大盘定位问题的具体案例,帮助理解如何使用可观测性能力。
首先来看 ACK Pro 的可观测性能力。监测大盘入口如下:
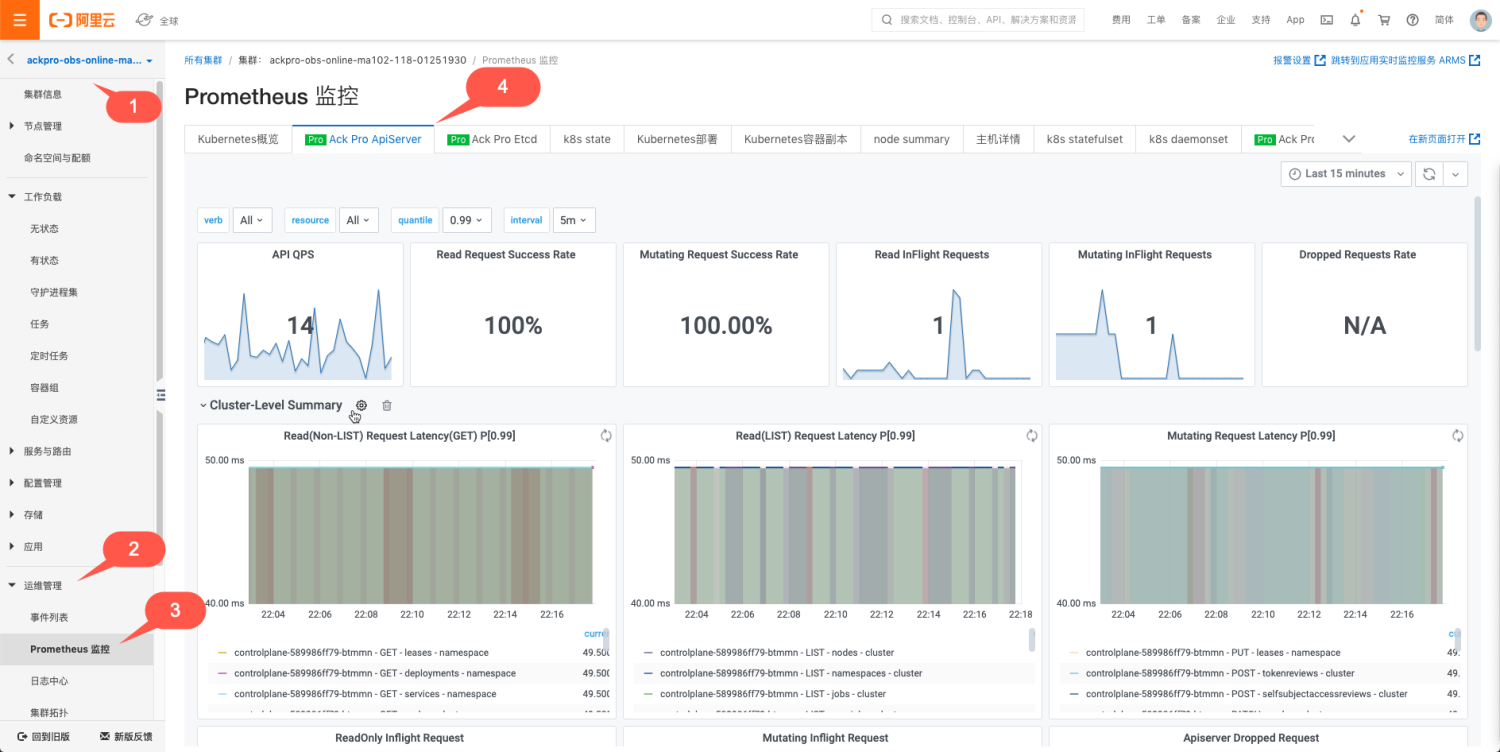
APIServer 是 K8s 核心组件之一,是 K8s 组件进行交互的枢纽,ACK Pro APIServer 的监测大盘设计考虑到用户可以选择需要监测的 APIServer Pod 来分析单一指标、聚合指标以及请求来源等,同时可以下钻到某一种或者多种 API 资源联动观测 APIServer 的指标,这样的优势是既可以全局观测全部 APIServer Pod 的全局视图,又可以下钻观测到具体 APIServer Pod 以及具体 API 资源的监测,监测全部和局部观测能力,对于定位问题非常有效。所以根据 ACK 的最佳实践,实现上包含了如下 5 个模块:
- 提供 APIServer Pod、API 资源(Pods,Nodes,ConfigMaps 等)、分位数(0.99,0.9,0.5)、统计时间间隔的筛选框,用户通过控制筛选框,可以联动控制监测大盘实现联动
- 凸显关键指标以便识别系统关键状态
- 展示 APIServer RT、QPS 等单项指标的监测大盘,实现单一维度指标的观测
- 展示 APIServer RT、QPS 等聚合指标的监测大盘,实现多维度指标的观测
- 展示对 APIServer 访问的客户端来源分析,实现访问源的分析
下面概要介绍模块的实现。
关键指标

显示了核心的指标,包括 APIServer 总 QPS、读请求成功率、写请求成功率、Read Inflight Request、Mutating Inflight Request 以及单位时间丢弃请求数量 Dropped Requests Rate。
这些指标可以概要展示系统状态是否正常,例如如果 Dropped Requests Rate 不为 NA,说明 APIServer 因为处理请求的能力不能满足请求出现丢弃请求,需要立即定位处理。
Cluster-Level Summary
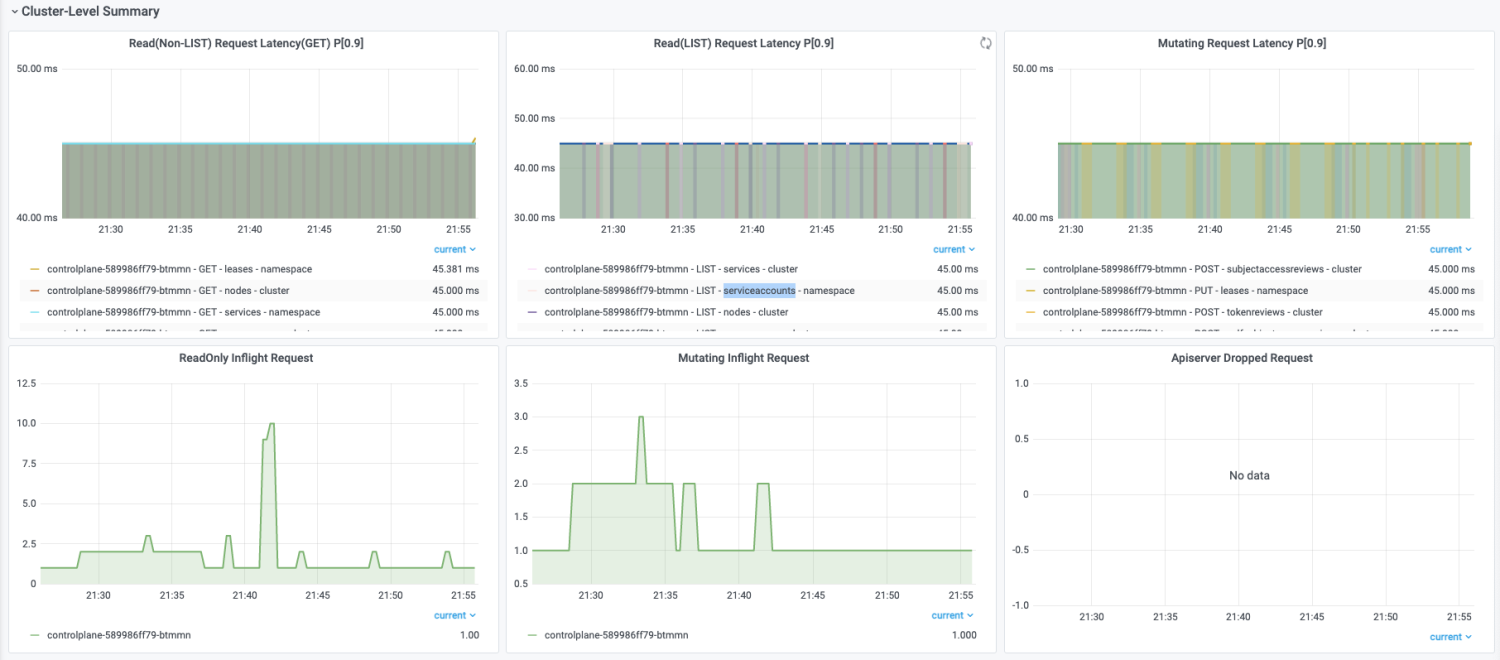
包括读非 LIST 读请求 RT、LIST 读请求 RT、写请求 RT、读请求 Inflight Request、修改请求 Inflight Request 以及单位时间丢弃请求数量,该部分大盘的实现结合了 ACK 最佳实践经验。
对于响应时间的可观测性,可以直观的观察到不同时间点以及区间内,针对不同资源、不同操作、不同范围的响应时间。可以选择不同的分位数,来筛选。有两个比较重要的考察点:
- 曲线是否连续
- RT 时间
先来解释曲线的连续性。通过曲线的连续性,可以很直观的看出请求是持续的请求,还是单一的请求。
下图表示在采样周期内,APIServer 收到 PUT leases 的请求,每个采样期内 P90 RT 是 45ms。
因为图中曲线是连续,说明该请求在全部采样周期都存在,所以是持续的请求。
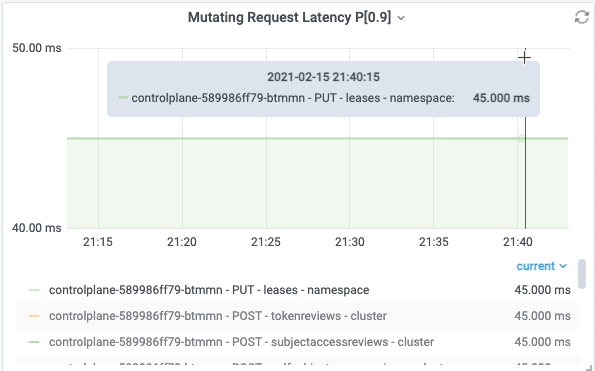
下图表示在采样周期内,APIServer 收到 LIST daemonsets 的请求,有样值的采样周期内 P90 RT 是 45ms。
因为图中只有一次,说明该请求只是在一次采样周期存在。该场景来自于用户执行 kubectl get ds --all-namespaces 产生的请求记录。

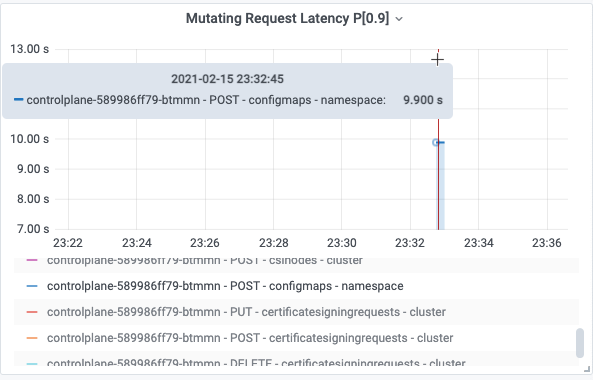
再来解释曲线体现的 RT。
用户执行命令创建 1MB 的 configmap,请求连接到公网 SLBkubectl create configmap cm1MB --from-file=cm1MB=./configmap.file
APIServer 记录的日志中,该次请求 POST configmaps RT 为 9.740961791s,该值可以落入 apiserver_request_duration_seconds_bucket 的(8, 9]区间,所以会在 apiserver_request_duration_seconds_bucket 的 le=9 对应的 bucket 中增加一个样点,可观测性展示中按照 90 分位数,计算得到 9.9s 并图形化展示。这就是日志中记录的请求真实RT与可观测性展示中的展示 RT 的关联关系。
所以监测大盘既可以与日志可观测功能联合使用,又可以直观概要的以全局视图展示日志中的信息,最佳实践建议结合监测大盘和日志可观测性做综合分析。
I0215 23:32:19.226433 1 trace.go:116] Trace[1528486772]: "Create" url:/api/v1/namespaces/default/configmaps,user-agent:kubectl/v1.18.8 (linux/amd64) kubernetes/d2f5a0f,client:39.x.x.10,request_id:a1724f0b-39f1-40da-b36c-e447933ef37e (started: 2021-02-15 23:32:09.485986411 +0800 CST m=+114176.845042584) (total time: 9.740403082s): Trace[1528486772]: [9.647465583s] [9.647465583s] About to convert to expected version Trace[1528486772]: [9.660554709s] [13.089126ms] Conversion done Trace[1528486772]: [9.660561026s] [6.317µs] About to store object in database Trace[1528486772]: [9.687076754s] [26.515728ms] Object stored in database Trace[1528486772]: [9.740403082s] [53.326328ms] END I0215 23:32:19.226568 1 httplog.go:102] requestID=a1724f0b-39f1-40da-b36c-e447933ef37e verb=POST URI=/api/v1/namespaces/default/configmaps latency=9.740961791s resp=201 UserAgent=kubectl/v1.18.8 (linux/amd64) kubernetes/d2f5a0f srcIP="10.x.x.10:59256" ContentType=application/json:
下面解释一下RT与请求的具体内容以及集群规模有直接的关联。
在上述创建 configmap 的例子中,同样是创建 1MB 的 configmap,公网链路受网路带宽和时延影响,达到了 9s;而在内网链路的测试中,只需要 145ms,网络因素的影响是显著的。
所以 RT 与请求操作的资源对象、字节尺寸、网络等有关联关系,网络越慢,字节尺寸越大,RT 越大。
对于大规模 K8s 集群,全量 LIST(例如 pods,nodes 等资源)的数据量有时候会很大,导致传输数据量增加,也会导致 RT 增加。所以对于 RT 指标,没有绝对的健康阈值,一定需要结合具体的请求操作、集群规模、网络带宽来综合评定,如果不影响业务就可以接受。
对于小规模 K8s 集群,平均 RT 45ms 到 100ms 是可以接受的;对于节点规模上 100 的集群,平均 RT 100ms 到 200ms 是可以接受的。
但是如果 RT 持续达到秒级,甚至 RT 达到 60s 导致请求超时,多数情况下出现了异常,需要进一步定位处理是否符合预期。
这两个指标通过 APIServer /metrics 对外透出,可以执行如下命令查看 inflight requests,是衡量 APIServer 处理并发请求能力的指标。如果请求并发请求过多达到 APIServer 参数 max-requests-inflight和 max-mutating-requests-inflight 指定的阈值,就会触发 APIServer 限流。通常这是异常情况,需要快速定位并处理。
QPS & Latency
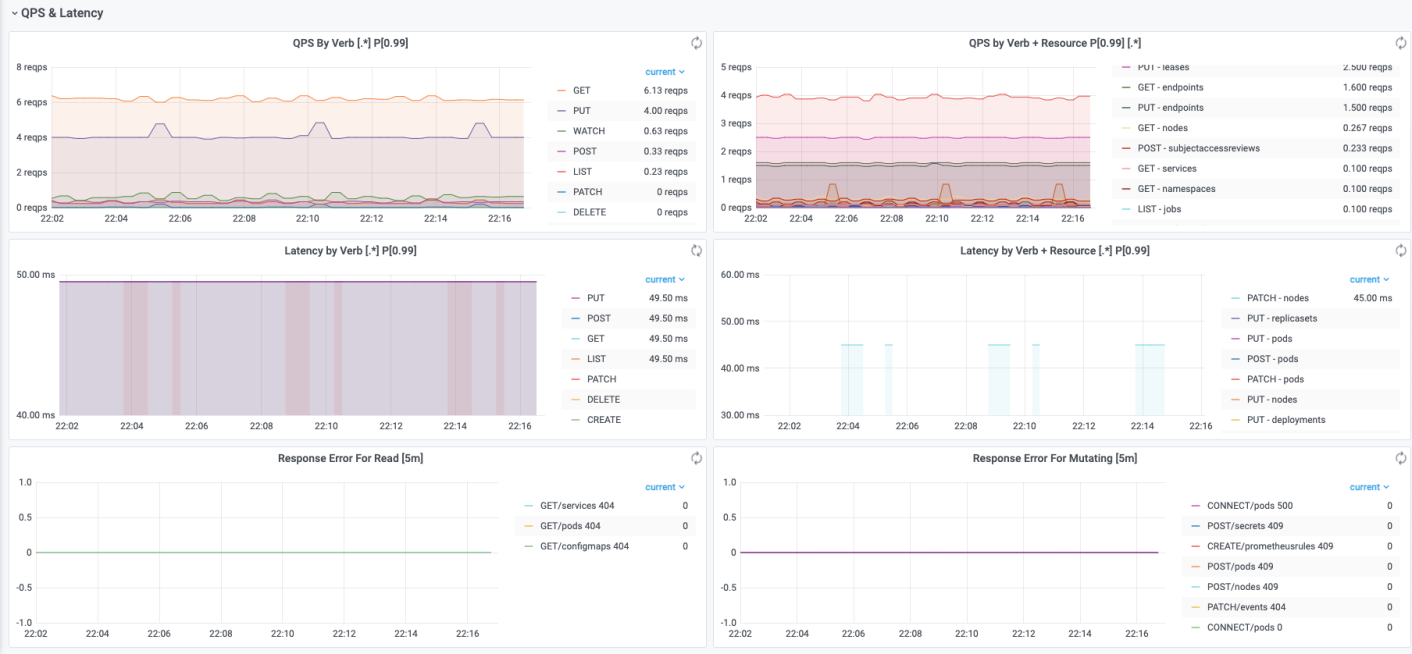
该部分可以直观显示请求 QPS 以及 RT 按照 Verb、API 资源进行分类的情况,以便进行聚合分析。还可以展示读、写请求的错误码分类,可以直观发现不同时间点下请求返回的错误码类型。
Client Summary
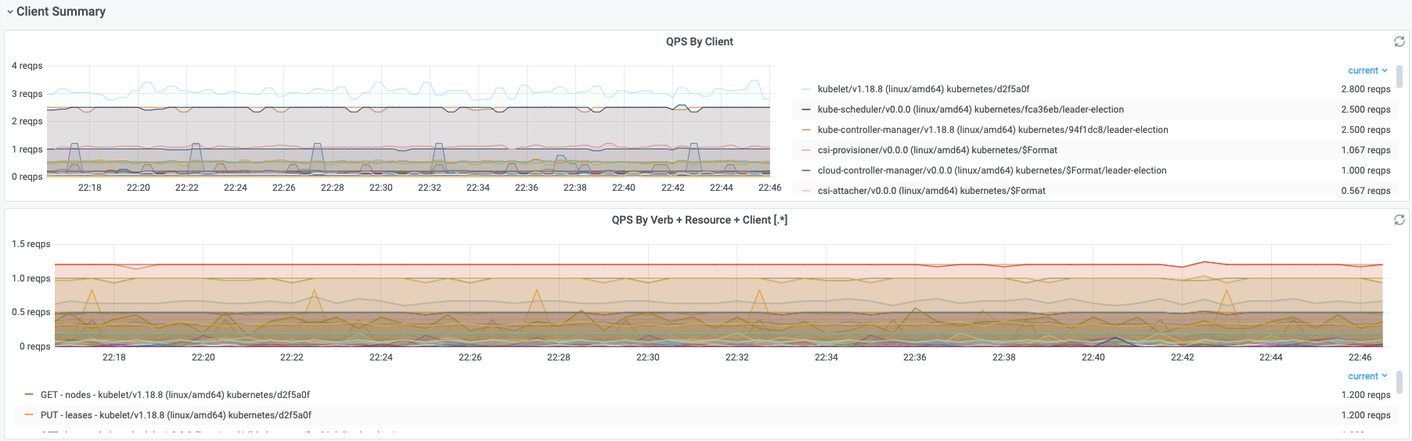
该部分可以直观显示请求的客户端以及操作和资源。
QPS By Client 可以按客户端维度,统计不同客户端的QPS值。
QPS By Verb + Resource + Client 可以按客户端、Verb、Resource 维度,统计单位时间(1s)内的请求分布情况。
基于 ARMS Prometheus,除了 APIServer 大盘,ACK Pro 还提供了 Etcd 和 Kube Scheduler 的监测大盘;ACK 和 ACK Pro 还提供了 CoreDNS、K8s 集群、K8s 节点、Ingress 等大盘,这里不再一一介绍,用户可以查看 ARMS 的大盘。这些大盘结合了 ACK 和 ARMS 的在生产环境的最佳实践,可以帮助用户以最短路径观测系统、发现问题根源、提高运维效率。
日志(Logging)可观测性方案
SLS 阿里云日志服务是阿里云标准的日志方案,对接各种类型的日志存储。
对于托管侧组件的日志,ACK 支持托管集群控制平面组件(kube-apiserver/kube-controller-manager/kube-scheduler)日志透出,将日志从 ACK 控制层采集到到用户 SLS 日志服务的 Log Project 中。
对于用户侧日志,用户可以使用阿里云的 logtail、log-pilot 技术方案将需要的容器、系统、节点日志收集到 SLS 的 logstore,随后就可以在 SLS 中方便的查看日志。
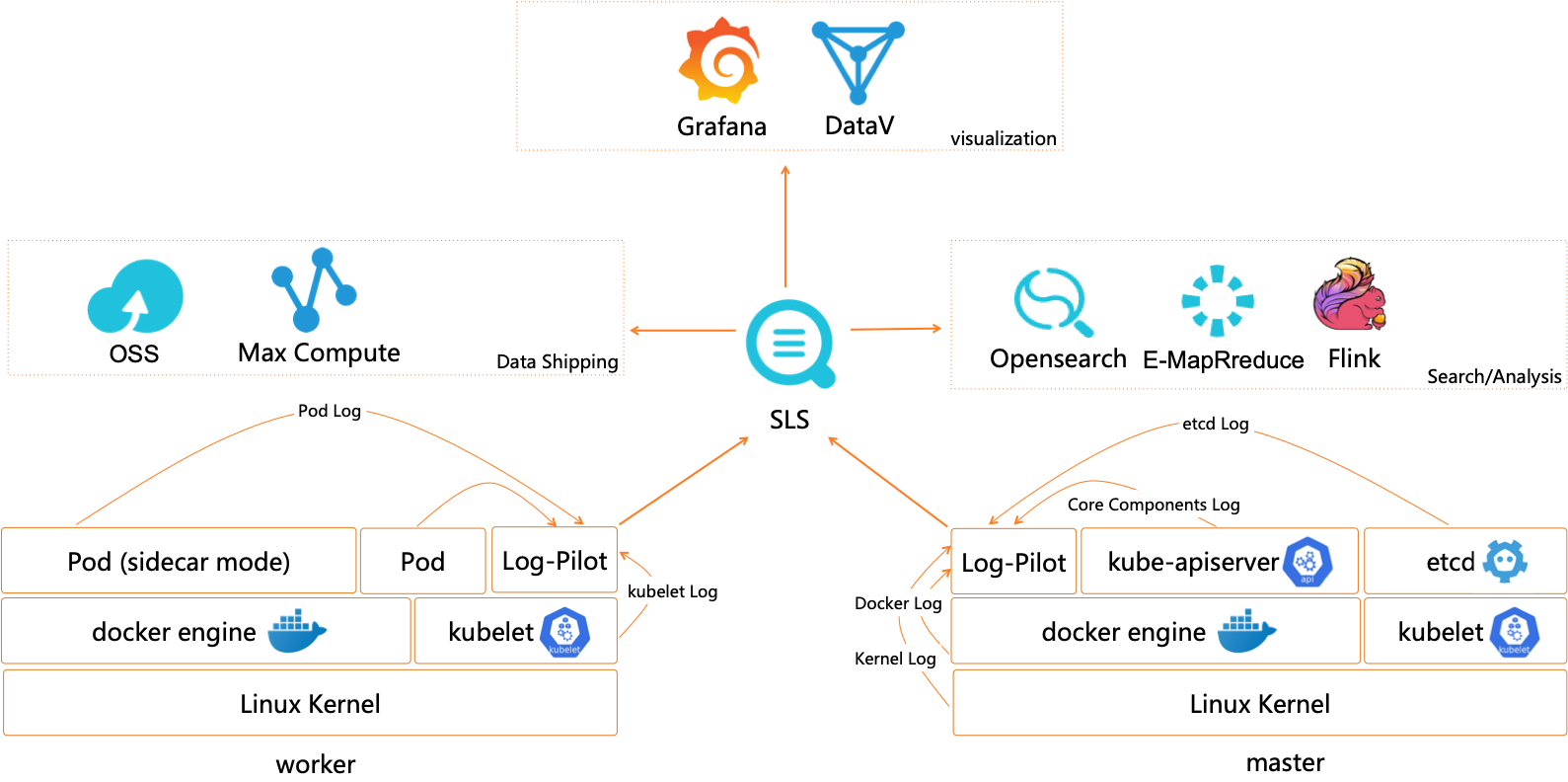
事件(Event)可观测性方案 + NPD 可观测性方案
Kubernetes 的架构设计基于状态机,不同的状态之间进行转换则会生成相应的事件,正常的状态之间转换会生成 Normal 等级的事件,正常状态与异常状态之间的转换会生成 Warning 等级的事件。
ACK 提供开箱即用的容器场景事件监测方案,通过 ACK 维护的 NPD(node-problem-detector)以及包含在 NPD 中的 kube-eventer 提供容器事件监测能力。
- NPD(node-problem-detector)是 Kubernetes 节点诊断的工具,可以将节点的异常,例如 Docker Engine Hang、Linux Kernel Hang、网络出网异常、文件描述符异常转换为 Node 的事件,结合 kube-eventer 可以实现节点事件告警的闭环。
- kube-eventer 是 ACK 维护的开源 Kubernetes 事件离线工具,可以将集群的事件离线到钉钉、SLS、EventBridge 等系统,并提供不同等级的过滤条件,实现事件的实时采集、定向告警、异步归档。
NPD 根据配置与第三方插件检测节点的问题或故障,生成相应的集群事件。而Kubernetes集群自身也会因为集群状态的切换产生各种事件。例如 Pod 驱逐,镜像拉取失败等异常情况。日志服务 SLS(Log Service)的 Kubernetes 事件中心实时汇聚 Kubernetes 中的所有事件并提供存储、查询、分析、可视化、告警等能力。
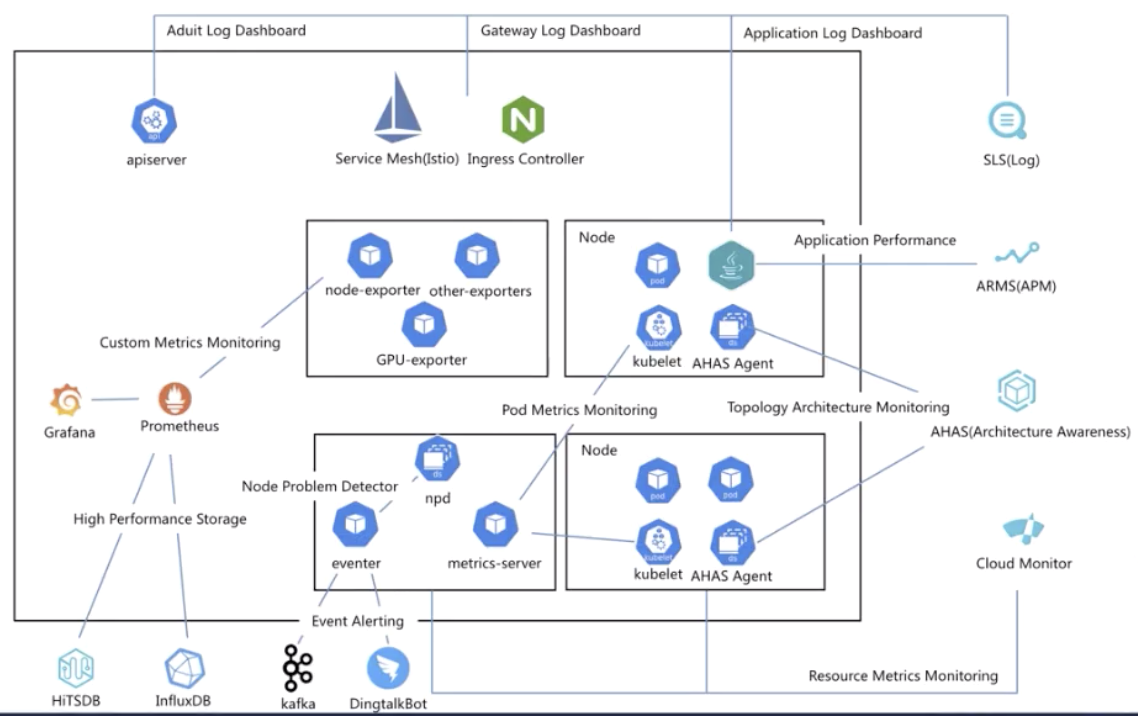
ACK可观测性展望
ACK 以及相关云产品对 Kubernetes 集群已经实现了全面的观测能力,包括指标、日志、链路追踪、事件等。后面发展的方向包括:
- 挖掘更多应用场景,将应用场景与可观测性关联,帮助用户更好的使用K8s。例如监测一段时间内 Pod 中容器的内存/CPU 等资源水位,利用历史数据分析用户的Kubernets 容器资源 requests/limits 是否合理,如果不合理给出推荐的容器资源 requests/limits;监测集群 APIServer RT 过大的请求,自动分析异常请求的原因以及处理建议;
- 联动多种可观测性技术方案,例如K8s事件和指标监测,提供更加丰富和更多维度的可观测性能力。
我们相信 ACK 可观测性未来的发展方向会越来越广阔,给客户带来越来越出色的技术价值和社会价值!
原文链接
本文为阿里云原创内容,未经允许不得转载。




)














