简介: 企业上云多账号架构中,如何做到从上到下管理的同时,处理好员工的权限边界问题?
由多账号上云模式说起
多账号上云模式的产生
我们的企业客户上云,一般都是从尝试部署少量业务开始,然后逐步将更多业务采用云上架构。随着企业上云的进一步深入,越来越多的企业业务被放在了云端,这使得企业采购的云资源迅速增多,资源、项目、人员、权限的管理变得极其复杂,仅仅使用一个账号,使得问题被放大,很难得到有效解决。单账号负载过重已无力支撑,许多企业开始创建更多账号以分散业务压力。于是,许多企业选择使用了更多账号,对应其不同的业务。因此,从账号的使用方面看,企业使用的账号数量逐步增多,多账号上云模式逐渐成为多业务上云的重要选项。

多账号模式的优势
诸多企业选择采用多账号模式上云,也是由于多账号相对单账号而言,有着不可替代的优势。
- 使用多账号的逻辑强隔离,实现企业不同业务应用间的相互独立
账号与账号之间默认是隔离的。这将避免不同业务间发生依赖项冲突或资源争用,甚至可以支持为每个业务设置明确的资源限制。
- 利用多账号分散风险,最大程度提升资源安全边界,尽可能将危害降到最低
消除安全“核按钮”。当非法用户窃取到一个高权限时,“爆炸半径”被限定到单个账号内,而不影响企业所有业务。
- 轻松应对大型企业多分公司关系,支持多种法律实体、多种结算模式共存
每个账号都可对应唯一一个法律主体,多账号环境天然支持集团企业的多分公司主体、以及不同业务的不同结算模式。
- 多账号易于结构化管理,业务的拆分和融合变得简单
业务过多导致“臃肿”不利于管理,业务间也非扁平形态,存在业务关联的“组织性”要求,单个账号很难解决,多账号却易于实现;同时,借助账号的独立性,它们可轻松地拆分或融合于不同的管控域,与企业业务适配联动。
多账号架构的挑战
多账号的采用,如果不去有序的管理它,也会有很多麻烦。
比如,账号散落没有集中、没有结构化,就无法做到组织化管理。再比如,上层管理者如何能够一眼全局、如何能够集中管控,都是影响企业业务效率的问题,需要解决。

无序管理的多账号一盘散沙,有序管理是企业多账号模式促进生产效率的第一要务。
从多账号组织化问题看,阿里云的资源目录产品,可以很好地解决多账号有序管理问题。这是资源目录的基础能力之一。
资源目录是阿里云面向企业客户,提供的基于多账号的管理与治理服务。详细了解资源目录
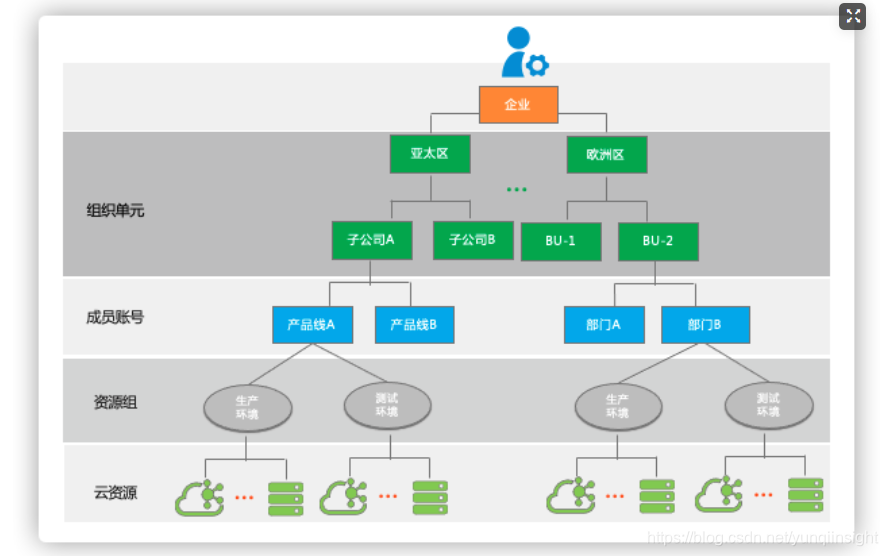
大家可以看到,上图中,利用资源目录的组织能力,企业可以很快的构建属于自己的业务架构,将企业多账号按照业务关系聚合,形成结构化易管理的形态,并提供闭环的企业云资源管理服务,以此来适配业务的管理需要。
多账号模式下的权限管控问题
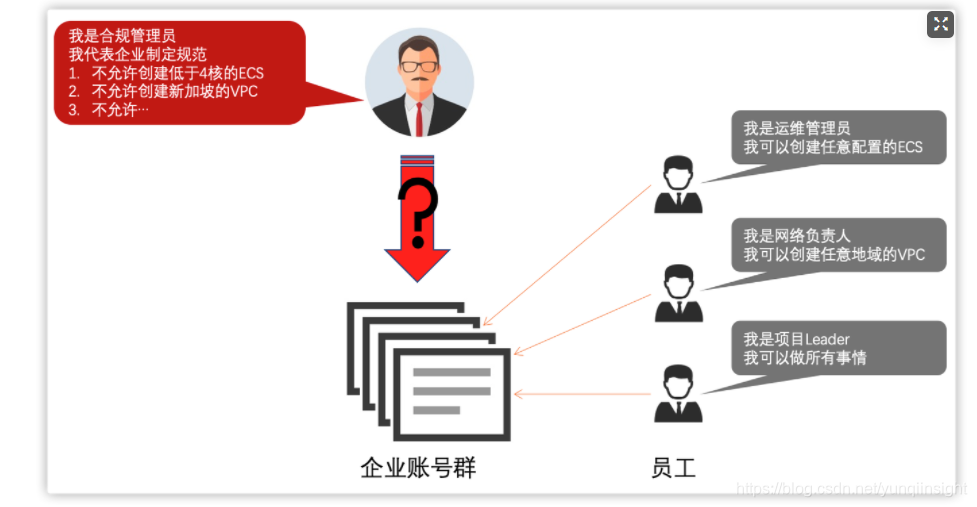
阿里云诸多大客户对于企业TopDown管控越来越重视。
随着客户业务的大量上云,员工(user)被密集且复杂的授予各种资源、服务的权限以运作这些业务,企业管理端很难非常细致地考量每个业务的具体授权,但希望能够从顶层做出企业的全局管控,即制定企业“大规范”以限定用户权限边界,以免超出公司的合规范围。
如何能够简单高效的解决这个问题?以下是资源目录管控策略产品设计的初衷。
管控策略产品定义与实现
管控策略(Control Policy,下文简称CP) 是一种基于资源结构(资源目录中的组织单元或成员账号)的访问控制策略,可以统一管理资源目录各层级内资源访问的权限边界,建立企业整体访问控制原则或局部专用原则。管控策略只定义权限边界,并不真正授予权限,您还需要在某个成员账号中使用访问控制(RAM)设置权限后,相应身份才具备对资源的访问权限。
从企业上云的角度看,管控策略的实施对象是企业用户对所需云资源的操作行为。从企业用户订购云资源、配置和使用云资源、最后到销毁云资源,管控策略可以对企业用户操作云资源的整个生命周期行为作出预设的前置校验,阻止不符合预设规则的操作发生,最终达到规范企业用户对云资源使用行为的目的。
管控策略的实现机制
在鉴权引擎中增加管控策略校验
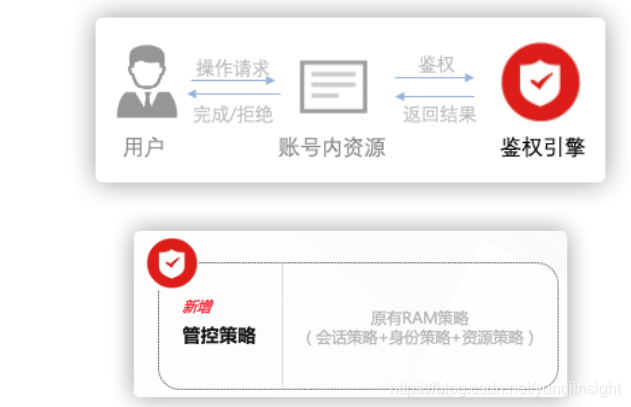
管控策略(CP)是如何实现权限管控效果的呢?
上图所示为用户访问资源请求的鉴权流程。管控策略在鉴权引擎中增加前置校验逻辑,在正式鉴权之前就对操作发生的边界进行判定:对于Explicit Deny(显式拒绝)或Implicit Deny(隐式拒绝),将直接做出「拒绝」结果,仅当管控策略的判定结果是Allow(允许)时,鉴权引擎才会进行下一步判定。
基于资源目录实现从上至下的管控
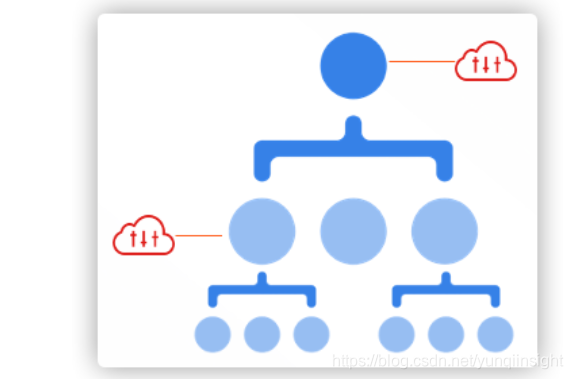
当企业创建了一个资源目录,并为每个部门创建了成员账号后,如果对各成员账号的行为不加以管控,就会破坏运维规则,带来安全风险和成本浪费。利用资源目录-管控策略功能,企业可以通过企业管理账号集中制定管理规则,并将这些管理规则应用于资源目录的各级组织结构(资源夹、成员账号)上,管控各成员账号内资源的访问规则,确保安全合规和成本可控。例如:禁止成员账号申请域名,禁止成员账号删除日志记录等。
当成员账号中的RAM用户或角色访问阿里云服务时,阿里云将会先进行管控策略检查,再进行账号内的RAM权限检查。具体如下:
- 管控策略鉴权从被访问资源所在账号开始,沿着资源目录层级逐级向上进行。
- 在任一层级进行管控策略鉴权时,命中拒绝(Deny)策略时都可以直接判定结果为拒绝(Explicit Deny),结束整个管控策略鉴权流程,并且不再进行账号内基于RAM权限策略的鉴权,直接拒绝请求。
- 在任一层级进行管控策略鉴权时,如果既未命中拒绝(Deny)策略,也未命中允许(Allow)策略,同样直接判定结果为拒绝(Explicit Deny),不再进入下一个层级鉴权,结束整个管控策略鉴权流程,并且不再进行账号内基于RAM权限策略的鉴权,直接拒绝请求。
- 在某一层级鉴权中,如果未命中拒绝(Deny)策略,而命中了允许(Allow)策略,则本层级鉴权通过,继续在父节点上进行管控策略鉴权,直至Root资源夹为止。如果Root资源夹鉴权结果也为通过,则整个管控策略鉴权通过,接下来进入账号内基于RAM权限策略的鉴权,详情请参见权限策略判定流程。
管控策略的用法说明
管控策略的语言
CP使用与RAM基本相同的语法结构。
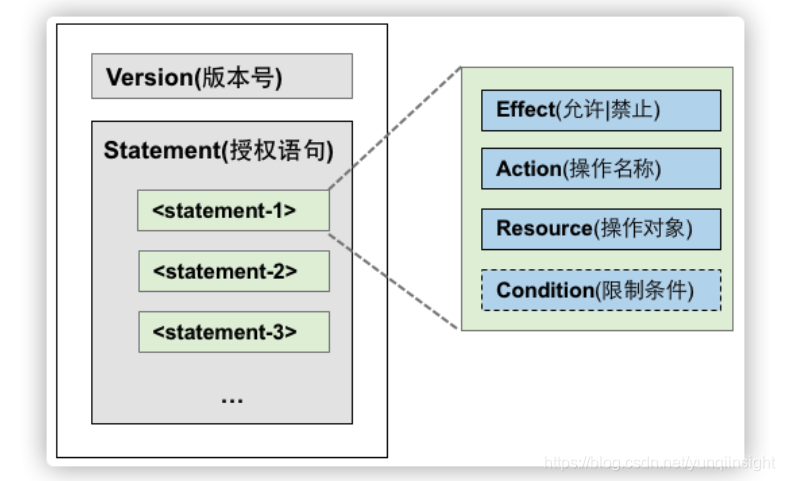
CP语法结构中包含版本号和授权语句列表,每条授权语句包括授权效力(Effect)、操作(Action)、资源(Resource)以及限制条件(Condition,可选项)。其中CP较RAM的Condition支持上,多了一种条件Key:acs:PrincipalARN,实现对执行者身份(目前支持Role)的条件检查,主要应用场景为下文中提到的「避免指定云服务访问被管控」。您可以了解更多CP语言的使用方法
管控策略的影响效果
您可以将自定义CP绑定到资源目录的任意节点,包含任何一个资源夹或成员账号。CP具备基于资源目录树形结构从上向下继承的特点,例如:为父资源夹设置管控策略A,为子资源夹设置管控策略B,则管控策略A和管控策略B都会在子资源夹及其下的成员账号中生效。
- CP仅影响资源目录内的成员账号下的资源访问。它对资源目录企业管理账号(MA)下的资源访问不会产生影响,因为MA并不属于RD;
- CP仅影响成员账号内的RAM用户和角色访问,不能管控账号的根用户(Root user)访问。我们建议您在资源目录内使用资源账号类型成员,这一成员类型禁用了根用户;关于资源目录成员类型,请参见文档
- CP基于资源的访问生效。无论是资源目录内的用户,还是外部用户,访问资源目录内的资源时,都会受到CP的管控;例如,您对资源目录内的A账号绑定了一个CP,同样适用于在资源目录外部的B账号内的用户访问A账号内的资源时的管控
- CP同样影响基于资源的授权策略。例如,在资源目录内的A账号中OSS bucket上授予资源目录外部的B账号内的用户访问,此访问行为同样受到绑定在A账号的CP影响
- CP对服务关联角色(Service Linked Role)不生效。关于服务关联角色的详情,请参见服务关联角色
避免指定云服务访问被管控
管控策略将对被管控成员账号中的资源访问权限限定边界,边界之外的权限将不允许生效,此限定同样影响阿里云服务对该成员账号访问的有效性。
阿里云服务可能使用服务角色(Service Role)访问您账号中的资源,以实现云服务的某些功能。当一个服务角色的权限超过管控策略的边界时,此权限会受到管控策略的约束,这可能导致云服务的某些功能不能正常使用。如果这正是您配置管控策略期望的结果,则无需进行其他额外操作,但是,如果您不希望这些云服务被管控,您可以采用以下方法进行处理:
- 确认您不希望被管控的云服务所使用的服务角色名称。您可以登录RAM控制台,查看账号下的所有服务角色。
- 在造成管控效果的管控策略中增加Condition key: "acs:PrincipalArn"的条件,将受影响的云服务所使用的服务角色名称写入到PrincipalArn字段,以避免该服务角色被误管控。示例如下:
{"Statement": [{"Action": ["ram:UpdateUser"],"Resource": "*","Effect": "Deny", "Condition": {"StringNotLike": {"acs:PrincipalARN":"acs:ram:*:*:role/<服务角色名称>"}}}],"Version": "1"
}
管控策略使用限制与参考
阿里云资源目录-管控策略目前已支持对152款云产品,您可以查看支持管控策略的云服务
管控策略的使用限制如下:
- 资源目录内最多允许创建自定义管控策略的数量为1500个;
- 每个节点(资源夹、成员账号)最多允许绑定自定义管控策略的数量为10个;
- 每个自定义策略的最大长度2048个字符。
我们建议您先进行局部小范围测试,确保策略的有效性与预期一致,然后再绑定到全部目标节点(资源夹、成员账号)。
原文链接
本文为阿里云原创内容,未经允许不得转载。



















