简介: 作者:长别
1. 前言
随着IT基础设施的发展,现代的数据处理系统需要处理更多的数据、支持更为复杂的算法。数据量的增长和算法的复杂化,为数据分析系统带来了严峻的性能挑战。近年来,我们可以在数据库、大数据系统和AI平台等领域看到很多性能优化的技术,技术涵盖体系结构、编译技术和高性能计算等领域。作为编译优化技术的代表,本文主要介绍基于LLVM的代码生成技术(简称Codeden)。
LLVM是一款非常流行的开源编译器框架,支持多种语言和底层硬件。开发者可以基于LLVM搭建自己的编译框架并进行二次开发,将不同的语言或者逻辑编译成运行在多种硬件上的可执行文件。对于Codegen技术来说,我们主要关注LLVM IR的格式以及生成LLVM IR的API。在本文的如下部分,我们首先对LLVM IR进行介绍,然后介绍Codegen技术的原理和使用场景,最后我们介绍在阿里云自研的云原生数据仓库产品AnalyticDB PostgreSQL中,Codegen的典型应用场景。
2. LLVM IR简介及上手教程
在编译器理论与实践中,IR是非常重要的一环。IR的全称叫做Intermediate Representation,翻译过来叫“中间表示”。 对于一个编译器来说,从上层抽象的高级语言到底层的汇编语言,要经历很多个环节(pass),经历不同的表现形式。而编译优化技术有很多种,每种技术作用的编译环节不同。但是IR是一个明显的分水岭。IR以上的编译优化,不需要关心底层硬件的细节,比如硬件的指令集、寄存器文件大小等。IR以下的编译优化,需要和硬件打交道。LLVM最为著名是它的IR的设计。得益于巧妙地IR设计,LLVM向上可以支持不同的语言,向下可以支持不同的硬件,而且不同的语言可以复用IR层的优化算法。
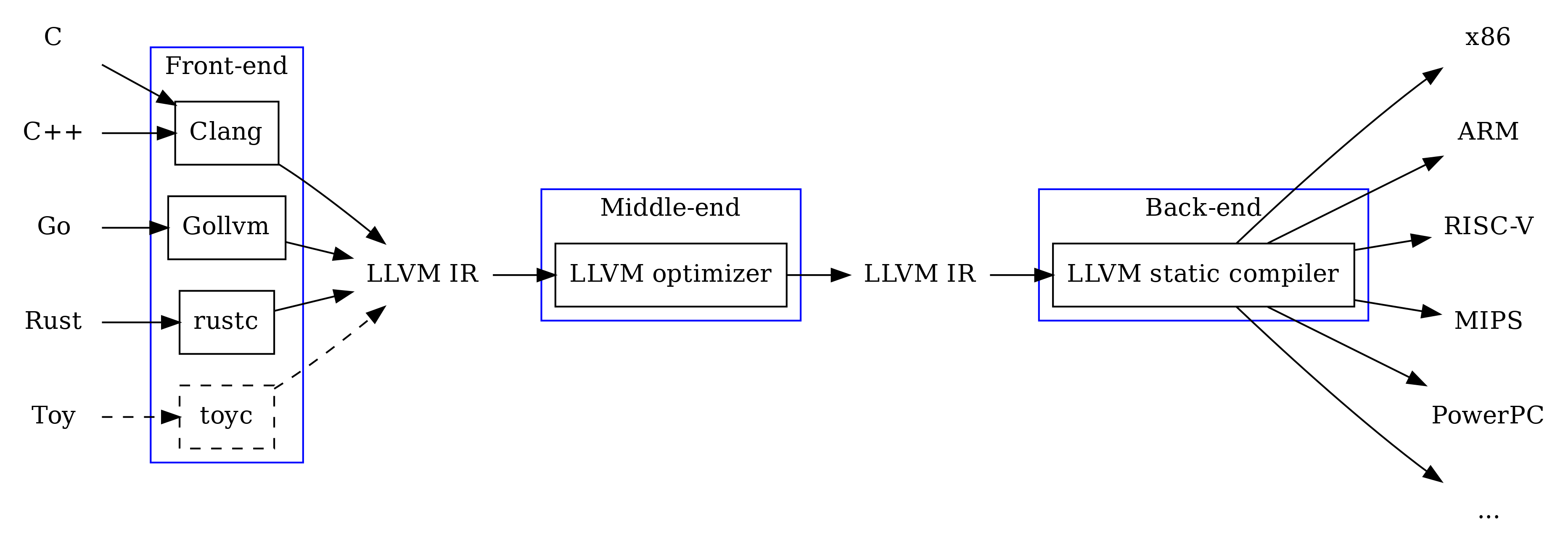
上图展示了LLVM的一个框架图。LLVM把整个编译过程分为三步:(1)前端,把高级语言转换为IR。(2)中端,在IR层做优化。(3) 后端,把IR转化为对应的硬件平台的汇编语言。因此LLVM的扩展性很好。比如你要实现一个名为toyc的语言、希望运行在ARM平台上,你只需要实现一个toyc->LLVM IR的前端,其他部分调LLVM的模块就可以了。或者你要搞一个新的硬件平台,那么只需要搞定LLVM IR->新硬件这一阶段,然后该硬件就可以支持很多种现存的语言。因此,IR是LLVM最有竞争力的地方,同时也是学习使用LLVM Codegen的最核心的地方。
2.1 LLVM IR基本知识
LLVM的IR格式非常像汇编,对于学习过汇编语言的同学来说,学会使用LLVM IR进行编程非常容易。对于没学过汇编语言的同学,也不用担心,汇编其实并不难。汇编难的不是学会,而是工程实现。因为汇编语言的开发难度,会随着工程复杂度的提升呈指数级上升。接下来我们需要了解IR中最重要的三部分,指令格式、Basic Block & CFG,还有SSA。完整的LLVM IR信息请参考https://llvm.org/docs/LangRef.html。
指令格式。LLVM IR提供了一种类似于汇编语言的三地址码式的指令格式。下面的代码片段是一个非常简单的用LLVM IR实现的函数,该函数的输入是5个i32类型(int32)的整数,函数的功能是计算这5个数的和并返回。LLVM IR是支持一些基本的数据类型的,比如i8、i32、浮点数等。LLVM IR中得变量的命名是以 "%"开头,默认%0是函数的第一个参数、%1是第二个参数,依次类推。机器生成的变量一般是以数字进行命名,如果是手写的话,可以根据自己的喜好选择合适的命名方法。LLVM IR的指令格式包括操作符、类型、输入、返回值。例如 "%6 = add i32 %0, %1"的操作符号是"add"、类型是"i32"、输入是"%0"和“%1”、返回值是"%6"。总的来说,IR支持一些基本的指令,然后编译器通过这些基本指令的来完成一些复杂的运算。例如,我们在C中写一个形如“A * B + C”的表达式在LLVM IR中是通过一条乘法和一条加法指令来完成的,另外可能也包括一些类型转换指令。
define i32 @ir_add(i32, i32, i32, i32, i32){%6 = add i32 %0, %1%7 = add i32 %6, %2%8 = add i32 %7, %3%9 = add i32 %8, %4ret i32 %9
}
Basic Block & CFG。了解了IR的指令格式以后,接下来我们需要了解两个概念:Basic Block(基本块,简称BB)和Control Flow Graph(控制流图,CFG)。下图(左)展示了一个简单的C语言函数,下图(中)是使用clang编译出来的对应的LLVM IR,下图(右)是使用graphviz画出来的CFG。结合这张图,我们解释下Basic Block和CFG的概念。
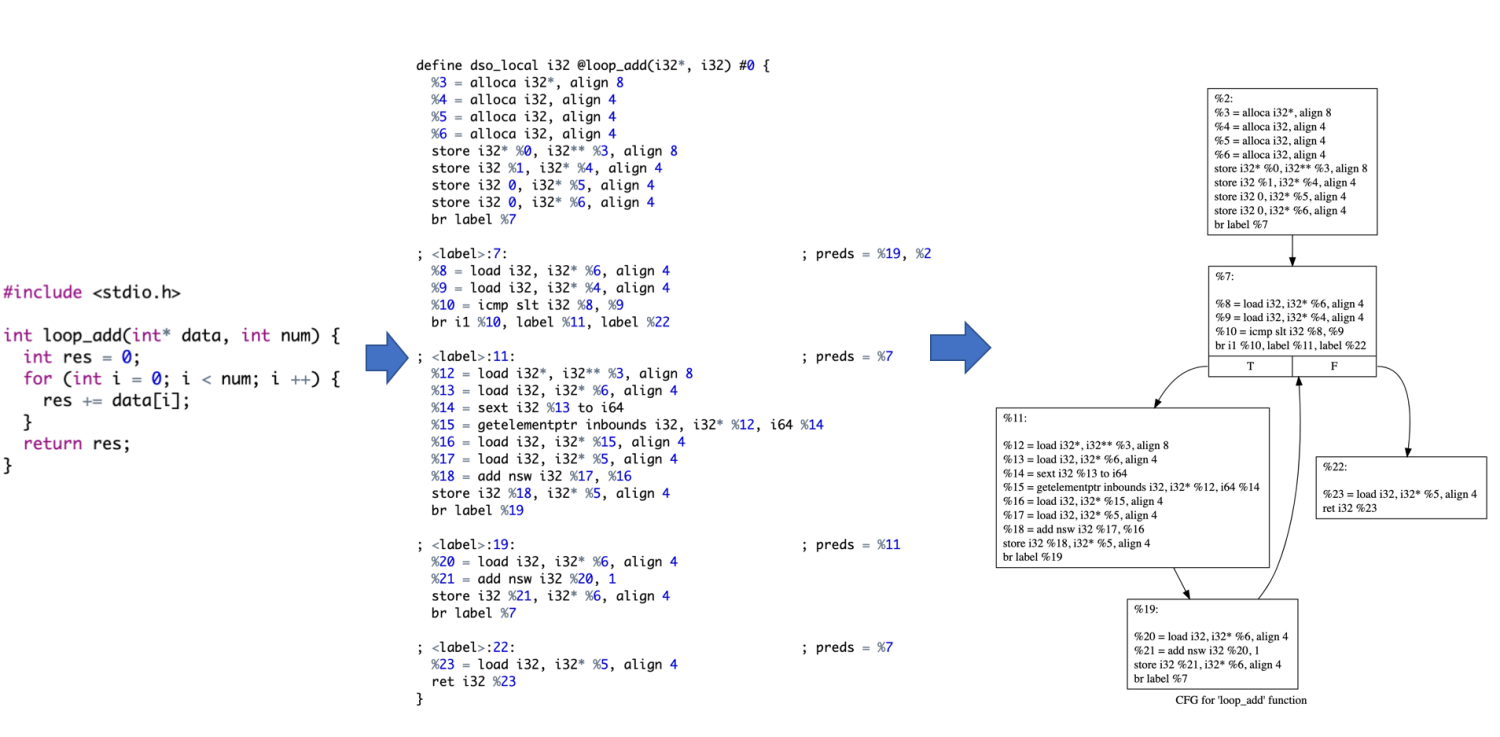
在我们平时接触到的高级语言中,每种语言都会有很多分支跳转语句,比如C语言中有for, while, if等关键字,这些关键字都代表着分支跳转。开发者通过分支跳转来实现不同的逻辑运算。汇编语言通常通过有条件跳转和无条件跳转两种跳转指令来实现逻辑运算,LLVM IR同理。比如在LLVM IR中"br label %7"意味着无论如何都跳转到名为%7的label那里,这是一条无条件跳转指令。"br i1 %10, label %11, label %22"是有条件跳转,意味着这如果%10是true则跳转到名为%11的label,否则跳转到名为%22的label。
在了解了跳转指令这个概念后,我们介绍Basic Block的概念。一个Basic Block是指一段串行执行的指令流,除了最后一句之外不会有跳转指令,Basic Block入口的第一条指令叫做“Leading instruction”。除了第一个Basic Block之外,每个Basic Block都会有一个名字(label)。第一个Basic Block也可以有,只是有时候没必要。例如在这段代码当中一共有5个Basic Block。Basic Block的概念,解决了控制逻辑的问题。通过Basic Block, 我们可以把代码划分成不同的代码块,在编译优化中,有的优化是针对单个Basic Block的,有些是针对多个Basic Block的。
CFG(Control Flow Graph, 控制流图)其实就是由Basic Block以及Basic Block之间的跳转关系组成的一个图。例如上图所示的代码,一共有5个Basic Block,箭头列出了Basic Block之间的跳转关系,共同组成了一个CFG。如果一个Basic Block只有一个箭头指向别的Block,那么这个跳转就是无条件跳转,否则是有条件跳转。CFG是编译理论中一个比较简单而且很基础的概念,CFG更进一步是DFG(Data Flow Graph,数据流图),很多进阶的编译优化算法都是基于DFG的。对于使用LLVM进行Codegen开发的同学,理解CFG的概念即可。
SSA。SSA的全称是Static Single Assignment(静态单赋值),这是编译技术中非常基础的一个理念。SSA是学习LLVM IR必须熟悉的概念,同时也是最难理解的一个概念。细心的读者在观察上面列出的IR代码时会发现,每个“变量”只会被赋值一次,这就是SSA的核心思想。因为从编译器的角度来看,编译器不关心“变量”,编译器是以“数据”为中心进行设计的。每个“变量”的每次写入,都生成了一个新的数据版本,编译器的优化是围绕数据版本展开的。接下来我们用如下的C语言代码来解释这一思想。

上图(左)展示了一段简单的C代码,上图(右)是这短代码的SSA版本,也就是“编译器眼中的代码”。在C语言中,我们知道数据都是用变量来存储的,因此数据操作的核心是变量,开发者需要关心变量的生存时间、何时被赋值、何时被使用。但是编译器只关心数据的流向,因此每次赋值操作都会生成一个新的左值。例如左边代码只有一个a, 但是在右边的代码有4个变量,因为a里面的数据一共有4个版本。除了每次赋值操作会生成一个新的变量,最后的一个phi节点会生成一个新的变量。在SSA中,每个变量都代表数据的一个版本。也就是说,高级语言以变量为核心,而SSA格式以数据为核心。SSA中每次赋值操作都会生成一个版本的数据,因此在写IR的时候,时刻牢记IR的变量和高层语言不同,一个IR的变量代表数据的一个版本。Phi节点是SSA中的一个重要概念。在这个例子当中,a_4的取值取决于之前执行了哪个分支,如果执行了第一个分支,那么a_4 = a_1, 依次类推。Phi节点通过判断这段代码是从哪个Basic Block跳转而来,选择合适的数据版本。LLVM IR自然也是需要开发者写Phi节点的,在循环、条件分支跳转的地方,往往需要手写很多phi节点,这是写LLVM IR时逻辑上比较难处理的地方。
2.2 学会使用LLVM IR写程序
熟悉LLVM IR最好的办法就是使用IR写几个程序。在开始写之前,建议先花30分钟-1个小时再粗略阅读下官方手册(https://llvm.org/docs/LangRef.html),熟悉下都有哪些指令的类型。接下来我们通过两个简单的case熟悉下LLVM IR编程的全部流程。
下面是一个循环加法的函数片段。这个函数一共包含三个Basic Block,loop、loop_body和final。其中loop是整个函数的开始,loop_body是函数的循环体,final是函数的结尾。在第5行和第6行,我们使用phi节点来实现结果和循环变量。
define i32 @ir_loopadd_phi(i32*, i32){br label %looploop:%i = phi i32 [0,%2], [%newi,%loop_body]%res = phi i32[0,%2], [%new_res, %loop_body]%break_flag = icmp sge i32 %i, %1br i1 %break_flag, label %final, label %loop_body loop_body:%addr = getelementptr inbounds i32, i32* %0, i32 %i%val = load i32, i32* %addr, align 4%new_res = add i32 %res, %val%newi = add i32 %i, 1br label %loopfinal:ret i32 %res;
}
下面是一个数组冒泡排序的函数片段。这个函数包含两个循环体。LLVM IR实现循环本身就比较复杂,两个循环嵌套会更加复杂。如果能够用LLVM IR实现一个冒泡算法,基本上就理解了LLVM的整个逻辑了。
define void @ir_bubble(i32*, i32) {%r_flag_addr = alloca i32, align 4%j = alloca i32, align 4%r_flag_ini = add i32 %1, -1store i32 %r_flag_ini, i32* %r_flag_addr, align 4br label %out_loop_head
out_loop_head:;check breakstore i32 0, i32* %j, align 4%tmp_r_flag = load i32, i32* %r_flag_addr, align 4%out_break_flag = icmp sle i32 %tmp_r_flag, 0br i1 %out_break_flag, label %final, label %in_loop_headin_loop_head:;check break%tmpj_1 = load i32, i32* %j, align 4%in_break_flag = icmp sge i32 %tmpj_1, %tmp_r_flagbr i1 %in_break_flag, label %out_loop_tail, label %in_loop_bodyin_loop_body:;read & swap%tmpj_left = load i32, i32* %j, align 4%tmpj_right = add i32 %tmpj_left, 1%left_addr = getelementptr inbounds i32, i32* %0, i32 %tmpj_left%right_addr = getelementptr inbounds i32, i32* %0, i32 %tmpj_right%left_val = load i32, i32* %left_addr, align 4%right_val = load i32, i32* %right_addr, align 4;swap check%swap_flag = icmp sge i32 %left_val, %right_val%left_res = select i1 %swap_flag, i32 %right_val, i32 %left_val %right_res = select i1 %swap_flag, i32 %left_val, i32 %right_valstore i32 %left_res, i32* %left_addr, align 4store i32 %right_res, i32* %right_addr, align 4br label %in_loop_endin_loop_end:;update j%tmpj_2 = load i32, i32* %j, align 4%newj = add i32 %tmpj_2, 1store i32 %newj, i32* %j, align 4br label %in_loop_head
out_loop_tail:;update r_flag %tmp_r_flag_1 = load i32, i32* %r_flag_addr, align 4%new_r_flag = sub i32 %tmp_r_flag_1, 1store i32 %new_r_flag, i32* %r_flag_addr, align 4br label %out_loop_head
final:ret void
}
我们把如上的LLVM IR用clang编译器编译成object文件,然后和C语言写的程序链接到一起,即可正常调用。在上面提到的case中,我们只使用了i32、i64等基本数据类型,LLVM IR中支持struct等高级数据类型,可以实现更为复杂的功能。
2.3 使用LLVM API实现Codegen
编译器本质上就是调用各种各样的API,根据输入去生成对应的代码,LLVM Codegen也不例外。在LLVM内部,一个函数是一个class,一个Basic Block试一个class, 一条指令、一个变量都是一个class。用LLVM API实现codegen就是根据需求,用LLVM内部的数据结构去实现相应的IR。
Value *constant = Builder.getInt32(16);Value *Arg1 = fooFunc->arg_begin();Value *val = createArith(Builder, Arg1, constant);Value *val2 = Builder.getInt32(100);Value *Compare = Builder.CreateICmpULT(val, val2, "cmptmp");Value *Condition = Builder.CreateICmpNE(Compare, Builder.getInt1(0), "ifcond");ValList VL;VL.push_back(Condition);VL.push_back(Arg1);BasicBlock *ThenBB = createBB(fooFunc, "then");BasicBlock *ElseBB = createBB(fooFunc, "else");BasicBlock *MergeBB = createBB(fooFunc, "ifcont");BBList List;List.push_back(ThenBB);List.push_back(ElseBB);List.push_back(MergeBB);Value *v = createIfElse(Builder, List, VL);
如上是一个用LLVM API实现codegen的例子。其实这就是个用C++写IR的过程,如果知道如何写IR的话,只需要熟悉下这套API就可以了。这套API提供了一些基本的数据结构,比如指令、函数、基本块、llvm builder等,然后我们只需要调用相应的函数去生成这些对象即可。一般来说,首先我们先生成函数的原型,包括函数名字、参数列表、返回类型等。然后我们在根据函数的功能,确定都需要有哪些Basic Block以及Basic Block之间的跳转关系,然后生成相应的Basic。最后我们再按照一定的顺序去给每个Basic Block填充指令。逻辑是,这个流程和用LLVM IR写代码是相仿的。
3. Codegen技术分析
如果我们用上文所描述的方法,生成一些简单的函数,并且用C写出对应的版本进行性能对比,我们就会发现,LLVM IR的性能并不会比C快。一方面,计算机底层执行的是汇编,C语言本身和汇编是非常接近的,了解底层的程序员往往能够从C代码中推测出大概会生成什么样的汇编。另一方面,现代编译器往往做了很多优化,一些大大减轻了程序员的优化负担。因此,使用LLVM IR进行Codegen并不会获得比手写C更好的性能,而且使用LLVM Codegen有一些明显的缺点。想要真正用好LLVM,我们还需要熟悉LLVM的特点。
3.1 缺点分析
缺点1:开发难。实际开发中几乎不会有工程使用汇编作为主要开发语言,因为开发难度太大了,有兴趣的小伙伴可以试着写个快排感受一下。即使是数据库、操作系统这样的基础软件,往往也只是在少数的地方会用到汇编。使用LLVM IR开发会有类似的问题。比如上文展示的最复杂例子是冒泡算法。开发者用C写个冒泡只需要几分钟,但是用LLVM IR写个冒泡可能要一个小时。另外,LLVM IR很难处理复杂的数据结构,比如结构体、类。除了LLVM IR中的那些基本数据结构外,新增一个复杂的数据结构非常难。因此在实际的开发当中,采用Codegen会导致开发难度指数级上升。
缺点2:调试难。开发者通常通过单步跟踪的方式去调试代码,但是LLVM IR是不支持的。一旦代码出问题,只能是人肉一遍一遍看LLVM IR。如果懂汇编的话,可以通过单步跟踪生成的汇编进行调试,但是汇编语言和IR之间并不是简单的映射关系,因此只能一定程度上降低调试难度,并不完全解决调试的问题。
缺点3: 运行成本。生成LLVM IR往往很快,但是生成的IR需要调用LLVM 中的工具进行优化、以及编译成二进制文件,这个过程是需要时间的(请联想一下GCC编译的速度)。在数据库的开发过程中,我们的经验值是每个函数大约需要10ms-100ms的codegen成本。大部分的时间花在了优化IR和IR到汇编这两步。
3.2 适用场景
了解了LLVM Codegen的缺点,我们才能去分析其优点、选择合适场景。下面这部分是团队在开发过程中总结的适合使用LLVM Codegen的场景。
场景1:Java/python等语言。上文中提到过LLVM IR并不会比C快,但是会比Java/python等语言快啊。例如在Java中,有时候为了提升性能,会通过JNI调用一些C的函数提升性能。同理,Java也可以调用LLVM IR生成的函数提升性能。
场景2:硬件和语言不兼容。LLVM支持多种后端,比如X86、ARM和GPU。对于一些硬件与语言不兼容的场景,可以利用LLVM实现兼容。例如如果我们的系统是用Java语言开发、想要调用GPU,可以考虑用LLVM IR生成GPU代码,然后通过JNI的方法进行调用。这套方案不仅支持NVIDIA的GPU,也支持AMD的GPU,而且对应生成的IR也可以在CPU上执行。
场景3:逻辑简化。以数据库为例,数据库执行引擎在执行过程中需要做大量的数据类型、算法逻辑相关的判断。这主要是由于SQL中的数据类型和逻辑,很多是在数据库开发时无法确定的,只能在运行时决定。这一部分过程,也被称为“解释执行”。我们可以利用LLVM在运行时生成代码,由于这个时候数据类型和逻辑已经确定,我们可以在LLVM IR中删除那些不必要的判断操作,从而实现性能的提升。
4. LLVM在数据库中的应用
在数据库当中,团队是用LLVM来进行表达式的处理,接下来我们以PostgreSQL数据库和云原生数据仓库AnalyticDB PostgreSQL为对比,解释LLVM的应用方法。
PostgreSQL为了实现表达式的解释执行,采用了一套“拼函数”的方案。PostgreSQL中实现了大量C函数,比如加减法、大小比较等,不同类型的都有。SQL在生成执行计划阶段会根据表达式符号的类型和数据类型选择相应的函数、把指针存下来,等执行的时候再调用。因此对于 "a > 10 and b < 5"这样的过滤条件,假设a和b都是int32,PostgreSQL实际上调用了“Int8AndOp(Int32GT(a, 10), Int32LT(b, 5))”这样一个函数组合,就像搭积木一样。这样的方案有两个明显的性能问题。一方面这种方案会带来比较多次数的函数调用,函数调用本身是有成本的。另一方面,这种方案必须要实现一个统一的函数接口,函数内部和外部都需要做一些类型转换,这也是额外的性能开销。Odyssey使用LLVM 进行codegen,可以实现最小化的代码。因为在SQL下发以后,数据库是知道表达式的符号和输入数据的类型的,因此只需要根据需求选取相应的IR指令就可以了。因此只需要三条IR指令,就可以实现这个表达式,然后我们把表达式封装成一个函数,就可以在执行的时候调用了。这次操作,把多次函数调用简化成了一次函数调用,大大减少了指令的总数量。
// 样例SQL select count(*) from table where a > 10 and b < 5;// PostgreSQL解释执行方案:多次函数调用 result = Int8AndOp(Int32GT(a, 10), Int32LT(b, 5));// AnalyticDB PostgreSQL方案:使用LLVM codegen生成最小化底层代码 %res1 = icmp ugt i32 %a, 10; %res2 = icmp ult i32 %b, 5; %res = and i8 %res1, %res2;
在数据库中,表达式主要出现在几个场景。一类是过滤条件,通常出现在where条件中。一类是输出列表,一般跟在select之后。有些算子,比如join、agg等,它的判断条件中也可能会出现一些比较复杂的表达式。因此表达式的处理是会出现在数据库执行引擎的各个模块的。在AnalyticDB PostgreSQL版中,开发团队抽象出了一个表达式处理框架,通过LLVM Codegen来处理这些表达式,从而提高了执行引擎的整体性能。

5. 总结
LLVM作为一个流行的开源编译框架,近年来被用于数据库、AI等系统的性能加速。由于编译器理论本身门槛较高,因此LLVM的学习有一定的难度。而且从工程上,还需要对LLVM的工程特点和性能特征有比较准确的理解,才能找到合适的加速场景。阿里云数据库团队的云原生数据仓库产品AnalyticDB PostgreSQL版基于LLVM实现了一套运行时的表达式处理框架,能够有效地提高系统在进行复杂数据分析时地性能。
原文链接
本文为阿里云原创内容,未经允许不得转载。

...)

















