简介: 近日,在国际体系架构顶会USENIX ATC2021上,阿里云飞天伏羲团队与香港中文大学合作的一篇论文《Scaling Large Production Clusters with Partitioned Synchronization》不仅成功被大会录取,而且被大会专家组评定为三篇最佳论文之一(Best Paper Award)。

作者 | 冯亦挥、刘智、赵蕴健、金晓月、吴一迪、张杨、郑尚策、李超、关涛
来源 | 阿里技术公众号
引言
近日,在国际体系架构顶会USENIX ATC2021上,阿里云飞天伏羲团队与香港中文大学合作的一篇论文《Scaling Large Production Clusters with Partitioned Synchronization》不仅成功被大会录取,而且被大会专家组评定为三篇最佳论文之一(Best Paper Award)。
ATC在计算机系统领域极具影响力。自1992年至今,ATC已成功举办31届,吸引了普林斯顿、斯坦福、加州大学伯克利分校、康奈尔、中国清华大学、北京大学等顶级名校,以及微软、英特尔、三星等科技巨头发布研究成果。ATC 对论文要求极高,必须满足基础性贡献、前瞻性影响和坚实系统实现的要求,2021 USENIX组委会录用64篇(录取率为18%),全球仅选取3篇最佳论文(其他两篇来自Stanford University和Columbia University)。这也是ATC最佳论文首次出现中国公司的身影。
本次大会上,我们详细介绍了Fuxi 2.0项目的最新成果,超大规模分布式集群去中心化的调度架构,首次向外界披露了阿里云在超大规模集群调度上的实现细节,也是飞天操作系统核心能力的又一次成功展现。
一 论文背景
AI/大数据计算场景,随着计算需求的快速增长,云计算集群突破单集群万台规模(一个集群可能有10万台机器,每天执行数十亿个任务,特别是短时任务),以实现高利用率低成本的附加值,具有重要意义。资源调度器作为大型生产集群的核心组件,它负责将集群内的多维度资源请求与机器资源进行高效匹配,而集群规模的增长,意味着有更高的并发请求,产生”乘积“效应,使调度复杂度急剧增加。因此,如何实现集群规模的可扩展,在保持良好的调度效果的同时,做到高并发、低延时,是业内公认的非常艰巨的任务。传统的中心调度器,受限于单点调度能力,大多数无法处理生产级别的规模,也无法保证稳定性和健壮性,做到升级过程对用户透明。
二 现状分析
1 作业负载
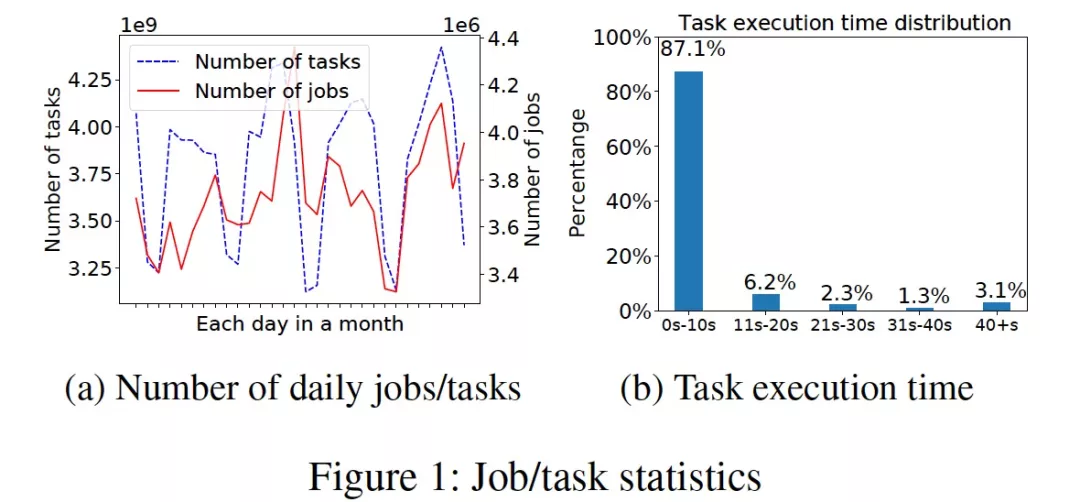
在阿里巴巴,单个计算集群每天运行着数百万的作业。图1a(实心曲线)绘制了一个集群某个月份内每天随机处理的作业数,334万至436万,而一个作业由许多任务组成,图1a(虚线)显示每天的任务数量大概为从31亿到44亿。其中大部分任务都是短时任务,如图1b所示,87%的任务在10秒内完成。大规模集群的调度负载还是非常大的。
2 调度架构升级的必要性
在Fuxi1.0,调度器遵循典型的master-worker架构,FuxiMaster负责管理并调度集群中的所有资源,同时每台机器上有一个agent,Tubo,定期通过心跳消息向FuxiMaster同步状态。用户提交的每个作业都有其所在的quota组的信息,quota组能使用资源的最大最小值由SRE设置。我们的quota机制既能在集群高负载时保证各个quota组之间的公平性,也能在集群相对较闲时,削峰填谷,让集群资源被充分使用。
近年来,计算集群的规模在显著地增长,在可预见的将来,集群规模很可能突破十万台。面对超大规模集群,一种方法是将集群静态切分为几个小集群,但该方法有着明显的局限性。首先,一些超大规模作业的资源需求可能就超过上述单个集群的规模;其次,集群的切分也会带来资源碎片问题,局部视图无法保证全局调度结果的最优;最后是其他非技术的因素,比如project之间存在依赖关系,同一业务部门的不同project需要互相访问数据,将它们部署在同一个集群(而不是拆分成一个个小集群)会大大降低运维和管理的代价。
但单master架构无法处理十万级别的集群规模,主要有两方面原因:1)随着集群规模的扩大,受限于单调度器处理能力的上限,master和worker之间的心跳延时会增加,调度信息不能及时下发,导致集群利用率下降;2)规模的提升意味着更高的任务并发度,使调度复杂度急剧增加,最终超过单调度器的处理能力。
3 调度的目标和挑战
除了规模可扩展性上的挑战,调度器还应在以下多个调度目标间进行权衡,我们关注的目标主要包括:
- 调度效率(或者延时),即一个任务需要在资源上等待多长时间,一个好的调度器应该让资源快速流转。
- 调度质量,资源的约束是否都被满足,比如data locality,更大体积的内存,更快的CPU型号等。
- 公平性和优先级,在多租户共享的生产环境,需要保证租户间资源使用的公平性,同时提供高优先级作业的保障机制。
- 资源利用率,一个极其重要的目标,集群利用率低会面临很多挑战,尤其是财务上的挑战。
但上述几个目标之间通常是互相冲突的,比如,更好的调度效果往往意味更长的调度延时,绝对的公平性有时会导致资源未能被充分使用,从而导致集群利用率下降。
经过十几年的积累,伏羲的资源调度器通过各种策略在上述几大目标间实现了很好的权衡,但考虑资源调度周边还有其他兄弟团队开发的应用组件,我们在设计新的调度器时,也应该做到尽量少改动,以保持系统的健壮性和向前兼容性。调度器架构调整引入的系统升级应该对用户是透明的,不管是内部用户还是外部用户。
三 理论概述
针对调度器的规模可扩展问题,我们对业内现有的调度模型做了广泛的调研(详见论文),并选取了其中一个最适合我们场景的方案(Omega)进行进一步的分析。以Omega为代表的shared-state的多调度器架构能满足我们之前说的那两个约束条件,向后兼容和对用户透明。但是share-state方案不可避免的会带来调度冲突,我们希望能清楚如下几个问题:
- 有哪些因素会影响冲突,它们各自的权重是多少?
- 调度延迟会恶化到什么程度?
- 如何才能够避免或减缓冲突?
我们首先对冲突进行建模,得出冲突(Conflict)的期望为(推导过程详见论文):
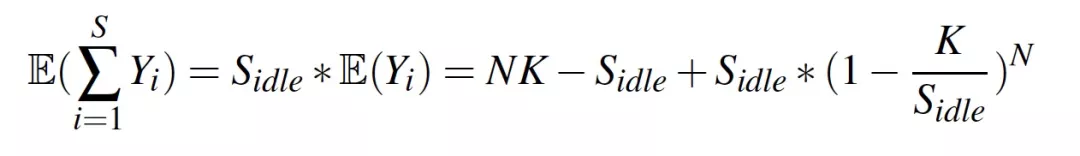
在上述公式中,Yi是多调度器在某个slot上冲突的期望, N是调度器的数量,K是单个调度器的处理能力,S是机器可调度的槽位数。可见,如果想减少冲突的概率,可以通过增加S或者N来实现。增加S是一种很符合直觉的方式,通过额外的资源供给来降低冲突概率。增加N的方式有些反直觉,因为调度器越多,越容易增加冲突,然而虽然在一轮调度过程中冲突变多了,但每个调度器一开始分到的task调度压力也等比例地减小了,所以就有了更多的时间来解决冲突,最终反而起到了降低冲突概率的效果。总结起来,增加N是在整体压力不变的情况下,通过降低每个调度器的调度压力来实现冲突的减少的。
此外我们也通过公式证明了,在调度器数量>1的情况下,无法彻底消除冲突。
下面的实验反映了不同的冲突因素对冲突的影响:
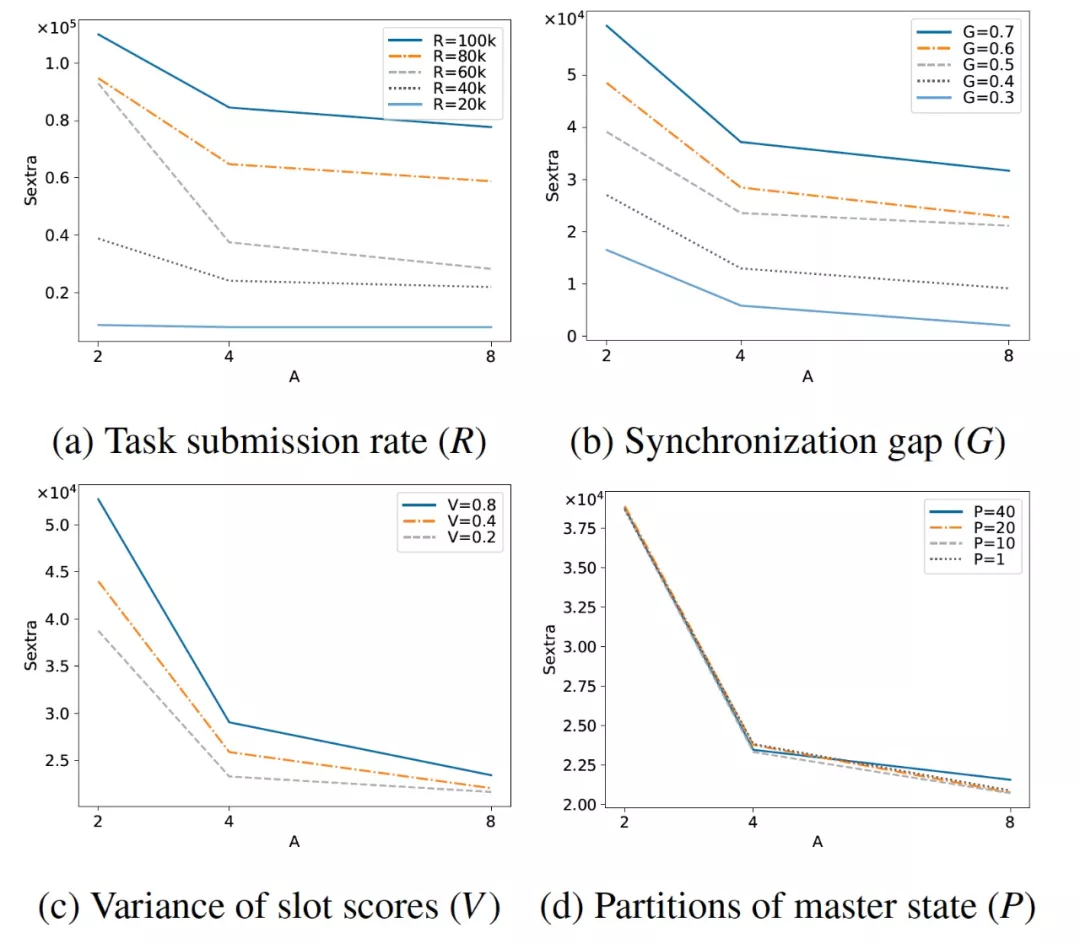
- 图a考量的是任务压力变化对冲突产生的影响。R表示调度器收到的task速率,可以看到在调度器数量相同的情况下,随着R的增大,为了保持冲突数量不发生明显的变化,需要额外补充的slot数目就越多;反过来,在R不变的情况下,随着调度器数量的增加,每个调度器承受的调度压力下降,需要额外补充的slot数目就越少。
- 图b反映的是资源视图同步频率变化对冲突的影响。G表示同步的延迟,可以看到在调度器数量相同的情况下,随着G的增大,为了保持冲突数量不发生明显的变化,需要额外补充的slot数目就越多;反过来,在G不变的情况下,随着调度器数量的增加,每个调度器承受的调度压力下降,需要额外补充的slot数目就越少。
- 图c反映的是机器分数(比如更好的硬件性能)对冲突的影响,V表示机器分数的方差,可以看到在调度器数量相同的情况下,随着V的增大,为了保持冲突不发生明显的变化,需要额外补充的slot数目就越多;反过来,在V不变的情况下,随着调度器数量的增加,每个调度器承受的调度压力下降,需要额外补充的slot数目就越少。
- 图d反映的是机器partition数量对冲突的影响,可以看到这个因素对冲突几乎没有影响。因为不管机器partition的数量是多少,调度器总是以自己内部的视图状态进行调度,即使有些视图的状态已经不够新了,所以partition数量并不会对冲突产生明显的影响。
由以上分析不难发现,在shared-state架构下,如果我们想尽可能的降低冲突,可以采取增加额外资源或者增加调度器数量的方式来降低冲突,但在实际的生产环境中,增加额外资源是不可能的,一方面是集群大小是相对固定的,此外新引入slot也会大幅增加集群的成本;而增加调度器则会显著带来维护\升级的代价。
四 方案实现
由于我们的目标是为了减少冲突,所以我们先简单介绍下一种能够完全消除冲突的策略,悲观锁策略。悲观锁策略是每个调度器能够调度的机器是“静态排他\静态划分”的,这样显然能够消除冲突,但是对利用率是非常不利的,因为会产生资源浪费(其他调度器本来可以调度)。还有一种策略是通过类似于zookeeper等组件实现的基于锁抢占的调度策略,当一批机器被某一个调度器锁住时,其他机器是由于拿不到机器锁从而暂时无法调度,当持锁的调度器放锁时,其他调度器可以通过锁竞争来尝试进行调度,但是在大规模高并发的调度场景下,这种高频的交互会对调度效率产生很大的负作用。
由前面的分析可以知道,降低资源同步的延迟能够有效降低冲突,由此我们提出了一种基于“分区同步”(下称ParSync)的策略:首先将集群的机器分为P个partition,同时要求P>N。通过round robin策略,每个调度器在同一个时刻去同步不同partition的资源视图,这样做能够保证在每个round内每个调度器都能够更新完所有partition的资源,而P>N保证了同一时刻不同的调度器不会同步相同的patition资源。
根据前文所述,在大规模高并发的调度场景下,调度器最优先的目标往往不是locality prefer而是speed prefer,所以调度器会优先在最新同步的partition机器内进行资源调度,在该策略下多调度器间是不会产生资源冲突的。ParSync其实是变相降低了每个patition对其当前同步调度器的同步延迟,因为站在当前更新的调度器的视角,这个partiton的同步延迟其实是低于其他未同步的调度器的,这也是能够有效降低冲突的理论原因。
我们提供三种调度策略:latency-first, quality-first, adaptive。latency-first是在优先在最新的partition上调度资源, quality-first是优先在score最好的机器上调度资源,而adaptvie是先采取quality-first的调度策略,当资源等待时间超过阈值时再采取latency-first的策略。我们通过一组实验来验证3种调度策略的调度效果:我们将调度器分为2类,A\B类调度器在阶段1都收到自身调度能力的2/3调度请求;阶段2,A类调度器收到等同于自身调度能力的调度请求,而B类调度器不变;阶段3,A\B类调度器都收到等同于自身调度能力的调度请求。
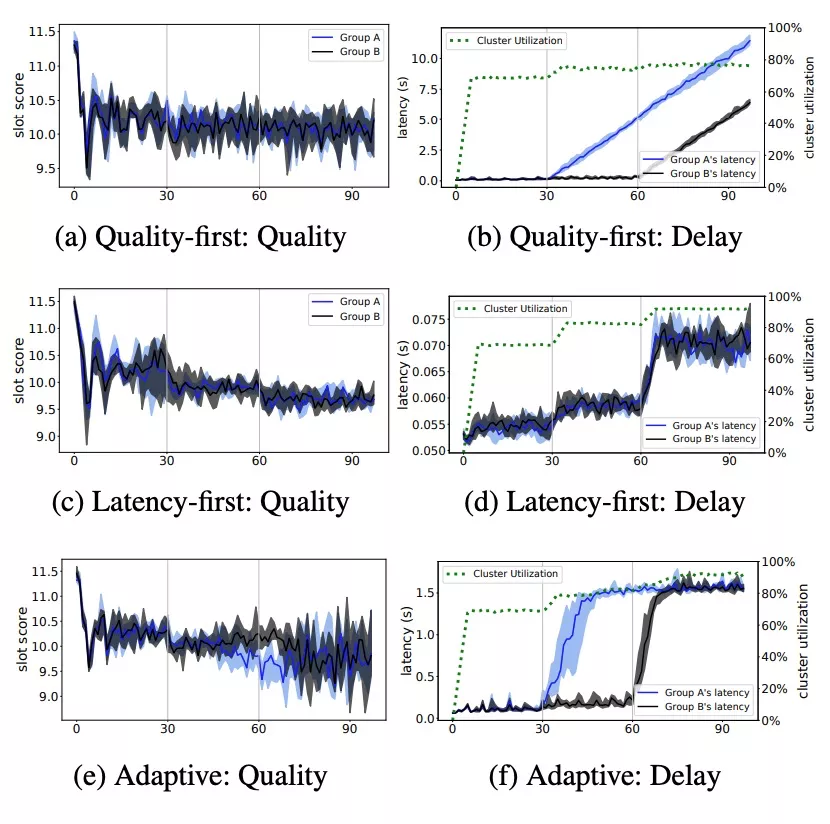
- 从(a)(b)可以看出,在阶段1\2\3, 调度quality的表现都是很好的,但是在阶段2\3随着调度压力的增加,调度latency出现了直线上升的情况,这是符合直觉预期的。
- 从(c)(d)可以看到,在阶段1调度器压力只有2/3的时候,调度latency和quality都是表现比较好的。随着调度压力的增加,quality质量开始出现了下降,但是latency的增加却非常有限,这也符合直觉预期。
- 从(e)(f)可以看到,在阶段2,由于B类调度器的调度压力仍只有2/3,所以还停留在quality-first策略,而A类调度器由于调度latency的增加进入到了latency-first策略。通过仔细观察可以看到在quality的图里B类调度器的quality质量(浅灰色)是优于latency-first策略的。在阶段3,A\B类调度器同时将调度latency约束在了门限值(1.5s),符合设计预期。
五 实验分析
我们通过“风洞”系统来验证整个调度框架。在风洞环境下,除了调度器是真实的,单机节点和am都是程序模拟出来的,它们和调度器进行真实的资源交互,通过sleep来模拟作业的执行,这样在一个node上就可以进行1:500的模拟。
测试环境:
- 20个调度器,2个resource manager
- 集群总共有20w个槽位
- 调度器调度能力为40k task/s
- 调度分为3个阶段,调度压力分别调度器能力的50%,80%, 95%,80%, 50%
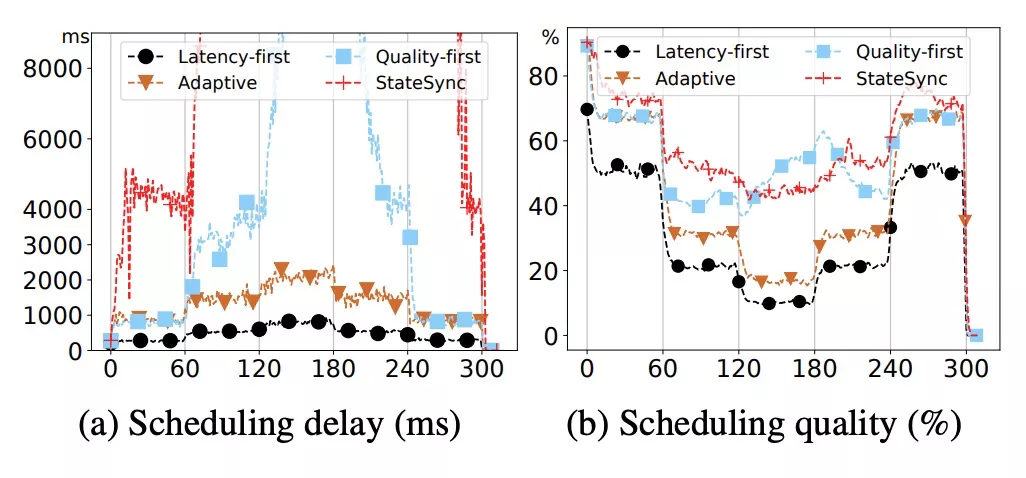
从图(a)可以看出,随着调度压力的变化,latency-first在调度latency上优于adaptive, 而quality-first优于StateSync(以Omega为代表的视图同步策略,调度器每次同步整个视图信息),latency-first策略能够将latency控制在一个非常好的水准,而StateSync的latency已经不受控制了,这也很好地证明了ParSync策略对冲突控制的有效性。对于quality-first策略,其latency也出现了不受控制的情况,这是调度器一直尝试在分数最高的机器上进行调度所带来的副作用。而adaptive策略对latency-first和quality-first进行了一个良好的折中。
从图(b)中可以看出,随着调度压力的变化,latency-first和adaptive策略在quality上表现都有一个明显的下降,这个符合预期。而quality-first的表现基本和StateSync持平。
综上,ParSync在quality与StateSync表现持平的情况下,latency表现远优于StateSync。其他更多的详细的数据分析详见论文。
六 总结
论文首先介绍了分布式调度器领域在解决规模问题时的常见做法:多调度器联合调度,其次介绍了多调度器的一种常见的资源供给模型StateSync。在StateSync模式下,不同调度器间会产生严重的调度冲突,进而影响集群的调度效率和利用率。针对上述问题,论文通过理论分析,给出了缓解冲突方法:增加可调度资源或扩充调度器,但是在实际中这2种方法都是不可接受的。
本文提出了一种新的资源供给模式:ParSync。在ParSync模式下,不同的调度器通过round robin的方式来分时更新机器资源。同时ParSync提供了三种调度策略:latency-first, quality-first, adaptive,用来满足不同场景下调度器对于latency\quality的要求。大规模实验表明,ParSync在调度质量上与其他调度器持平,但在调度延时上远优于其他调度器。
附录
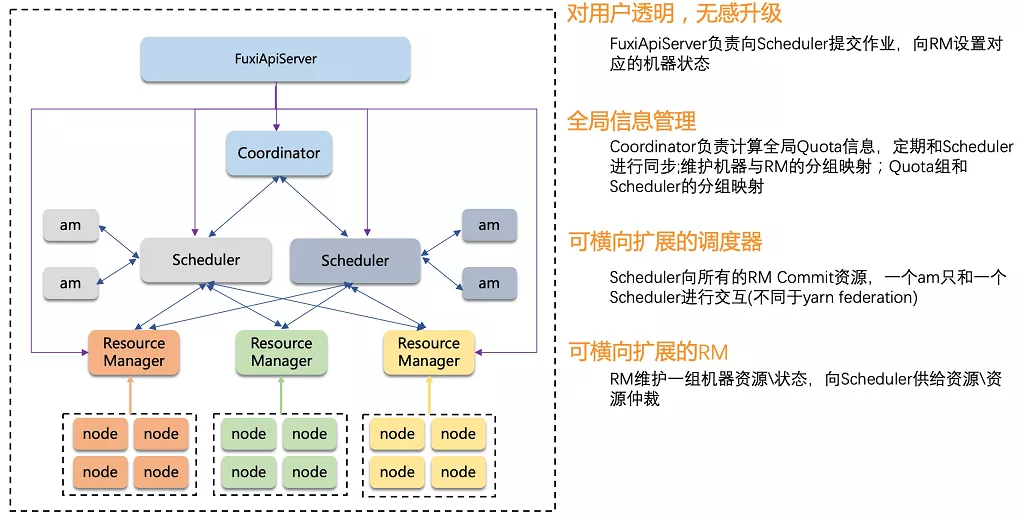
生产集群资源调度架构图
原文链接
本文为阿里云原创内容,未经允许不得转载。



















