第一类:逻辑型boolean

第二类:文本型char

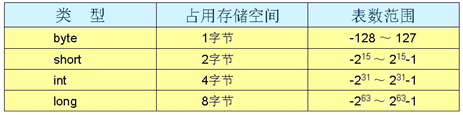
第三类:整数型(byte、short、int、long)
char类型占2个字节
short从-32768到32767
int从-2147483648,到2147483647共10位
long从-9223372036854775808到9223372036854775807共19位

第四类:浮点型(float、double)
在数学中0到1有无数个浮点数;而计算机是离散的,所以表示的时候有误差,计算机用精度(小数点后几位来表示正确),比较浮点数时a==0.1是不合适的,应该a-0.1==0;如果a是0.1,则即使有误差 a-0.1==0因为a和0.1都被表示为一个有误差的计算机二进制


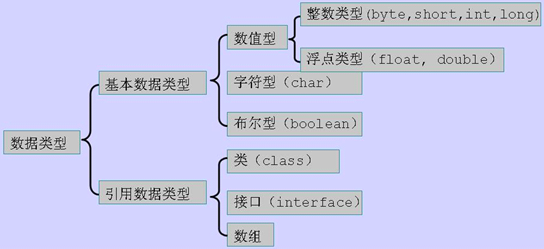
数组
概念
同一种类型数据的集合。其实数组就是一个容器。
数组的好处
可以自动给数组中的元素从0开始编号,方便操作这些元素。
格式1:
元素类型[] 数组名 = new 元素类型[元素个数或数组长度];
示例:int[] arr = new int[5];
格式2:
元素类型[] 数组名 = new 元素类型[]{元素,元素,……};
int[] arr = new int[]{3,5,1,7};
int[] arr = {3,5,1,7};
如果需要存储大量的数据,例如如果需要读取100个数,那么就需要定义100个变量,显然重复写100次代码,是没有太大意义的。如何解决这个问题,Java语言提供了数组(array)的数据结构,是一个容器可以存储相同数据类型的元素,可以将100个数存储到数组中。
1数组的概念
同一种类型数据的集合。其实数组就是一个容器。运算的时候有很多数据参与运算,那么首先需要做的是什么.不是如何运算而是如何保存这些数据以便于后期的运算,那么数组就是一种用于存储数据的方式,能存数据的地方我们称之为容器,容器里装的东西就是数组的元素, 数组可以装任意类型的数据,虽然可以装任意类型的数据,但是定义好的数组只能装一种元素, 也就是数组一旦定义,那么里边存储的数据类型也就确定了。
2 数组的好处
存数据和不存数据有什么区别吗?数组的最大好处就是能都给存储进来的元素自动进行编号. 注意编号是从0开始。方便操作这些数据。
例如 学生的编号,使用学号就可以找到对应的学生。
3数组的格式
元素类型[] 数组名 = new 元素类型[元素个数或数组长度];
示例:int[] arr = new int[5];
案例:
需求: 想定义一个可以存储3个整数的容器
实现:
1声明数组变量
为了使用数组必须在程序中声明数组,并指定数组的元素类型
=左半部分:
先写左边明确了元素类型 是int ,容器使用数组,那么如何来标识数组?.那么用一个特殊的符号[]中括号来表示。想要使用数组是需要给数组起一个名字的,那么我们在这里给这个数组起名字为x .接着跟上等号。
代码体现:
int [] x
注意:int x[] 也是一种创建数组的格式。推荐使用int [] x 的形式声明数组。
2创建数组
=右半部分:
要使用一个新的关键字.叫做new。new 用来在内存中产生一个容器实体,数据要存储是需要有空间的,存储很多数据的空间用new 操作符来开辟,new int[3]; 这个3是元素的个数。右边这部分就是在内存中定义了一个真实存在的数组,能存储3个元素。
new int[3] 做了两件事情,首先使用new int[3] 创建了一个数组,然后把这个数组的引用赋值给数组变量x。
int [] x=new int[3];
x 是什么类型?
任何一个变量都得有自己的数据类型。注意这个x 不是int 类型的 。int 代表的是容器里边元素的类型。那么x 是数组类型的。
数组是一种单独的数据类型。数据类型分为2大派,分为基本数据类型和引用数据类型。 第二大派是引用数据类型。那么大家现在已经接触到了引用数据类型三种当中的一种。就是数组类型 [] 中括号就代表数组。
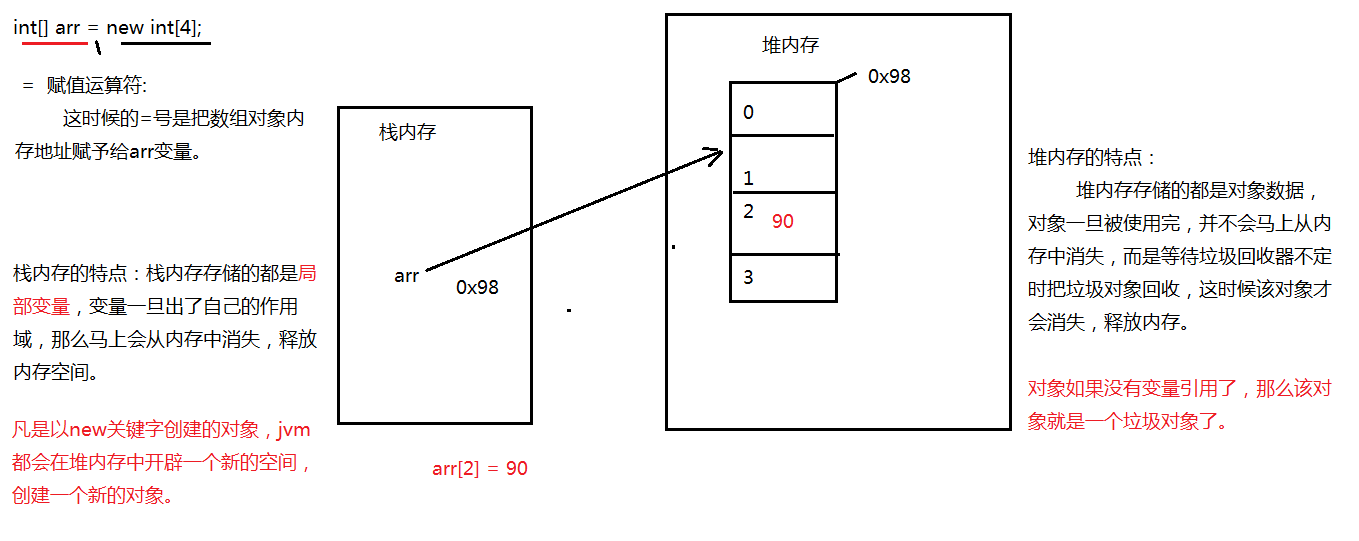
4、int[] arr = new int[5];在内存中发生了什么?
内存任何一个程序,运行的时候都需要在内存中开辟空间.int[] arr = new int[5]; 这个程序在内存中是什么样?这就涉及到了java虚拟机在执行程序时所开辟的空间,那么java开辟启动了多少空间呢?继续学习java的内存结构。
数组的定义
格式1:
元素类型[] 数组名 = new 元素类型[元素个数或数组长度];
示例:int[] arr = new int[5];
格式2:
元素类型[] 数组名 = new 元素类型[]{元素,元素,……};
int[] arr = new int[]{3,5,1,7};
int[] arr = {3,5,1,7};
注意:给数组分配空间时,必须指定数组能够存储的元素个数来确定数组大小。创建数组之后不能修改数组的大小。可以使用length 属性获取数组的大小。
遍历数组
数组初始化
数组的格式
int[] x = new int[3];
x[0] = 1;
x[1] = 2;
另一种定义:该形式可以直接明确数组的长度,以及数组中元素的内容
int[] x = { 1, 2, 3 };
int[] x=new int[]{1,2,3};
初始化方式1:不使用运算符new
int[] arr = { 1, 2, 3, 4, 5 };
int[] arr2 = new int[] { 1, 2, 3, 4, 5 };
初始化方式2:
int[] arr3=new int[3];
arr3[0]=1;
arr3[1]=5;
arr3[2]=6;
如果数组初始化中不使用运算符new。需要注意:下列写法是错误的。
int[] arr;
arr={1,2,3,4,5};
此时初始化数组,必须将声明,创建,初始化都放在一条语句中个,分开会产生语法错误。
所以只能如下写:
int[] arr={1,2,3,4,5};
数组遍历
public static void main(String[] args) {
int[] x = { 1, 2, 3 };
for (int y = 0; y
System.out.println(x[y]);
// System.out.println("x["+y+"]="+x[y]); 打印效果 x[0]=1;
} // 那么这就是数组的第一个常见操作.遍历
}
数组中有一个属性可以获取到数组中元素的个数,也就是数组的长度. 数组名.length
public static void main(String[] args) {
int[] x = { 1, 2, 3 };
for (int y = 0; y
System.out.println(x[y]);
// System.out.println("x["+y+"]="+x[y]); 打印效果 x[0]=1;
} // 那么这就是数组的第一个常见操作.遍历
}
数组的常见异常
数组中最常见的问题:
1. NullPointerException 空指针异常
原因: 引用类型变量没有指向任何对象,而访问了对象的属性或者是调用了对象的方法。\
2. ArrayIndexOutOfBoundsException 索引值越界。
原因:访问了不存在的索引值。
一数组角标越界异常:,注意:数组的角标从0开始。
public static void main(String[] args) {
int[] x = { 1, 2, 3 };
System.out.println(x[3]);
//java.lang.ArrayIndexOutOfBoundsException
}
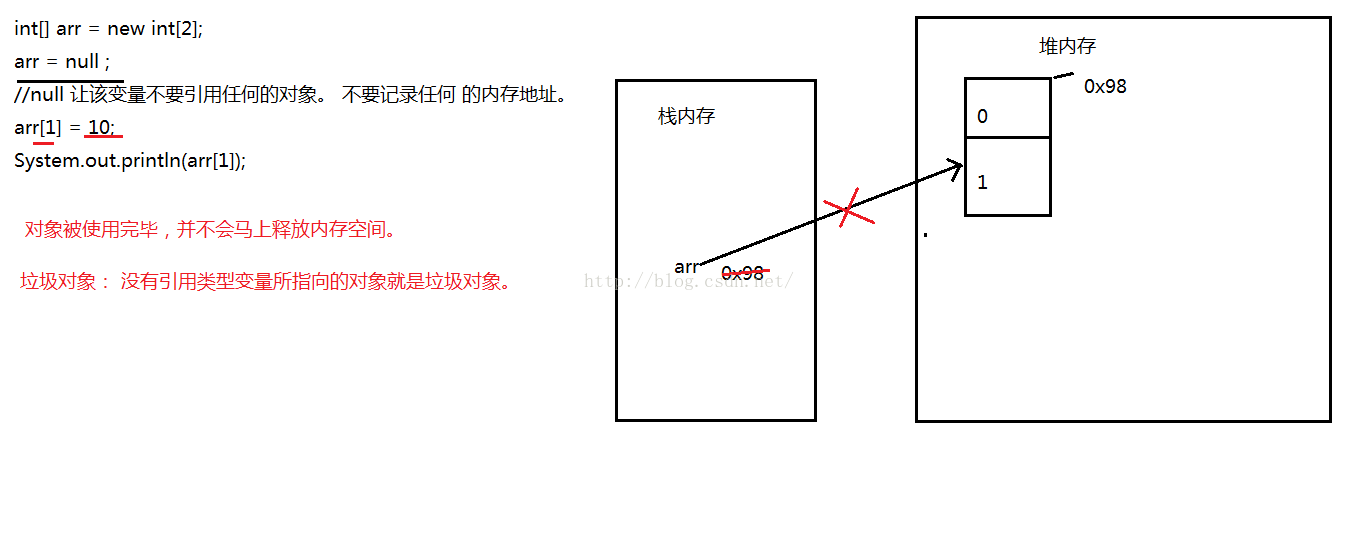
二 空指针异常:
public static void main(String[] args) {
int[] x = { 1, 2, 3 };
x = null;
System.out.println(x[1]);
// java.lang.NullPointerException
}
数组:
什么时候使用数组:当元素较多时为了方便操作这些数组,会先进行来临时存储,所使用的容器就是数组。
特点:
数组长度是固定的。
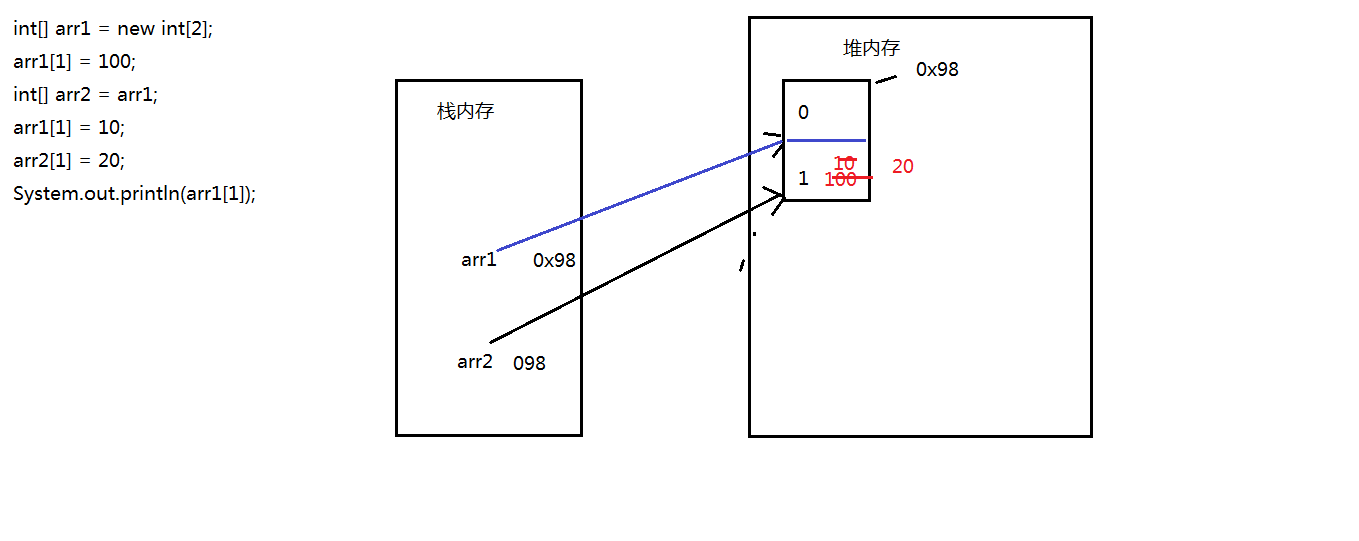
数组的内存分析
二维数组
Arrays的使用
遍历: toString() 将数组的元素以字符串的形式返回
排序: sort() 将数组按照升序排列
查找: binarySearch()在指定数组中查找指定元素,返回元素的索引,如果没有找到返回(-插入点-1) 注意:使用查找的功能的时候,数组一定要先排序。

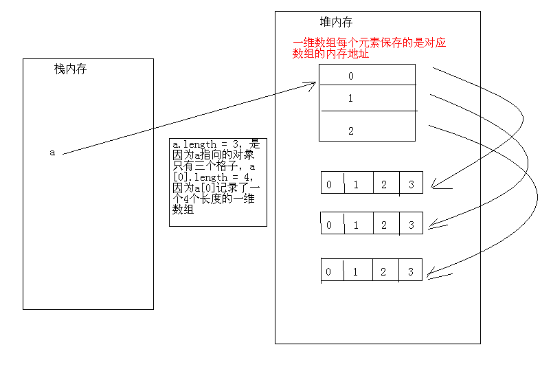
二维数组:实质就是存储是一维数组。
数组定义:
数组类型[][] 数组名 = new 数组类型[一维数组的个数][每一个一维数组中元素的个数];
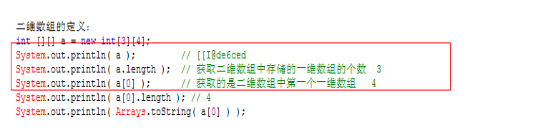
疑问: 为什么a.length = 3, a[0].length = 4?
数组的初始化:
静态初始化:
int [][] a = new int[][]{ {12,34,45,89},{34,56,78,10},{1,3,6,4} };
动态初始化:

文章内容为转载




)



-连接数据库MSSQL(JDBC代码篇))










