作者 | 王申领
供稿 | 浪潮
MLPerf是一套衡量机器学习系统性能的权威标准,将在标准目标下训练或推理机器学习模型的时间,作为一套系统性能的测量标准。MLPerf推理任务包括图像识别(ResNet50)、医学影像分割(3D-UNet)、目标物体检测(SSD-ResNet34)、语音识别(RNN-T)、自然语言理解(BERT)以及智能推荐(DLRM)。在MLPerf V2.0推理竞赛中,浪潮AI服务器基于ImageNet数据集在离线场景中运行Resnet50,达到了449,856 samples/s的计算性能,位居第一。本文将介绍浪潮在MLPerf推理竞赛中使用的卷积合并计算算法。
Resnet是残差网络(Residual Network)的缩写,该系列网络广泛用于目标分类等领域以及作为计算机视觉任务主干经典神经网络的一部分,典型的网络有Resnet50、Resnet101等。在Resnet神经网络中,主要计算算子是卷积计算层。Resnet50神经网络具有4组残差结构,这4组残差结构包含48个卷积算子,通过设计卷积算子的计算算法,提高卷积算子的计算性能,可以减少Resnet50推理过程中的延迟。基于A100 GPU单卡的性能测试显示,在BatchSize=2048的情况下,优化后的卷积合并优化算法相比原算法可带来14.6%的性能提升。
- MLPerf Resnet50推理流程
在MLPerf V2.0推理测试中,Resnet50模型需要在ImageNet2012测试集上达到FP32精度(76.46%)的99%以上。数据中心赛道设置了离线(Offline)与在线(Server)两种模式,其中离线模式会产生一次推理时间大于10分钟的samples请求,可直接反映机器和算法的推理性能。
Resnet50推理流程如下。首先在ImageNet2012测试集中读取数据,并进行数据预处理,随后数据会加载到TensorRT中进行实际的推理测试。测试分为两方面,一是测试模型的精度;二是产生一次推理请求,TensorRT会将请求中的图片全部推理完成得到总时间,根据计算时间得到每秒推理的样本数量,即为最终的成绩。
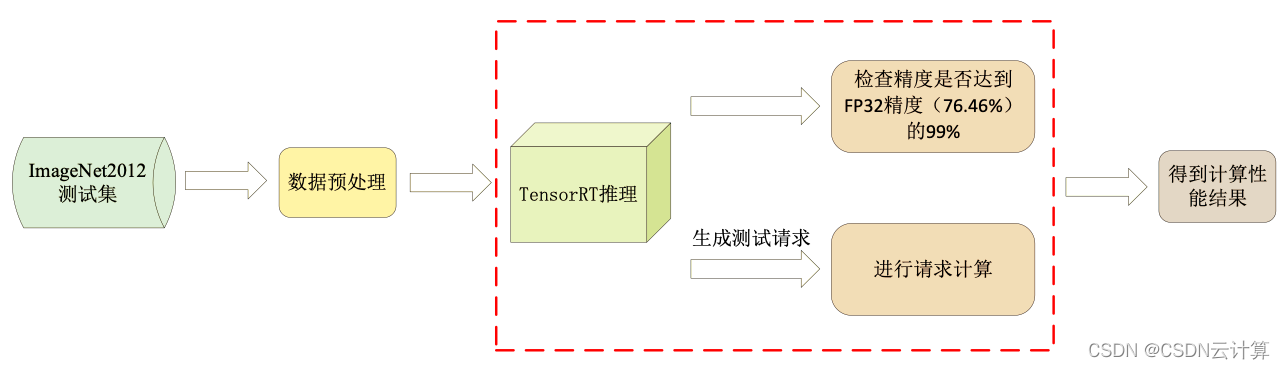
图1 MLPerf Resnet50推理流程
2. 卷积合并计算算法
2.1 算法优化思路
在GPU上运行Resnet50图像推理模型时,需要将每一个算子(卷积、池化、全连接等)放在GPU的Kernel中进行算子计算,由于GPU上运行Kernel时共享内存以及寄存器的资源有限(A100的共享内存为164KB),不可能将所有的计算过程数据放到Kernel中,而GPU的全局内存(A100有40G或者80G全局内存)一般都很大,所以会将比较大的过程数据放在全局内存中。在进行推理时,根据Kernel的计算将数据按需从全局内存读取到Kernel中进行计算,每个算子在计算时会不可避免地产生Kernel与全局内存的数据交换,由于全局内存的读写访问延迟较大,会使算子计算性能下降。
对于每个算子的Kernel计算,会产生两部分的全局内存访问,一部分是最开始的全局内存读取,另一部分是Kernel计算完成后的全局内存写回。为了降低全局内存访问带来的性能影响,有如下两种办法:
一是采用算子合并的方式。默认的程序会将每个算子都放在单独的Kernel中进行计算,每个算子都会产生全局内存读和写两次访问。如果将两个算子放在一个Kernel中进行计算,对于连续的两个卷积计算,可以减少第一个卷积算子的写回以及第二个算子的读取;对于卷积与Shortcut的合并,可以减少一次全局内存的写回操作,通过减少全局内存的访问可以提高程序的计算性能。
二是根据GPU不同架构的计算特性对Kernel的内部计算进行合理的优化设计。当不可避免地需要对全局内存进行访问时,做到全局内存进行连续线程的融合读取,充分利用向量化读取等加速对全局内存的访问,同时优化计算流程,通过Double buffer用计算来隐藏内存的访问延迟,对于需求较晚的全局内存数据,也可以通过A100的新特性-全局内存的异步复制来隐藏数据读取过程。
本文主要针对MLPerf推理中Resnet50卷积神经网络的第二组残差结构中的部分算子进行计算合并,在充分考虑GPU计算特性前提下,进行合理的算法设计,提高Resnet50卷积神经网络的性能。
2.2 Resnet50合并计算算法
在Resnet50神经网络中,第二组残差结构有Res3.1、Res3.2、Res3.3、Res3.4,共四部分的卷积计算,其中Res3.2、Res3.3、Res3.4三部分计算结构一样,如下图所示:
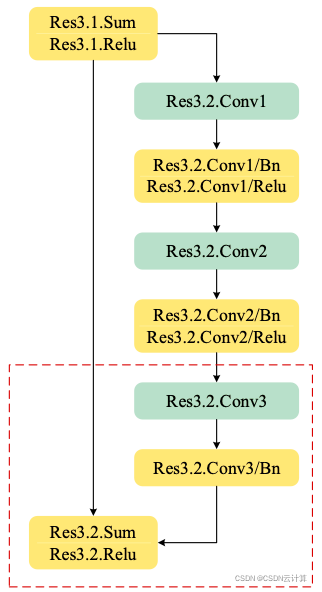
图2 Resnet50中第二组残差结构Res3.2示意图
可以看到,Res3.1的输出(input)作为Res3.2部分的输入,输入后会有两部分分支,在右部分的分支中,会先后计算Conv1,Conv2,Conv3三个卷积,其中Conv1,Conv2两个卷积后面都包含Bn和Relu过程,Conv3后面会有Bn的计算过程;在右边分支计算完成后,会与input进行Shortcut操作,主要进行的是与输入数据Sum和Relu操作,两部分结果经过Shortcut操作后会得到Res3.2的输出完成这部分的计算。
本文介绍的合并算法对图2虚线框中的计算进行合并,主要是对Conv3以及Shortcut的过程进行合并,包含Conv3+Bn+Sum+Relu过程。
3. 卷积合并算法在GPU加速卡上的实现
Res3.2的计算参数主要如下:
| Data | Weight | ||||||
| H | W | Ic | h | w | Ic | Oc | |
| Conv1 | 28 | 28 | 512 | 1 | 1 | 512 | 128 |
| Conv2 | 28 | 28 | 128 | 3 | 3 | 128 | 128 |
| Conv3 | 28 | 28 | 128 | 1 | 1 | 128 | 512 |
通过上表可以看到,Conv3输入Data的H*W为28*28,输入通道Ic为128,输入的权重Weight的h*w为1*1,输入通道Ic为128,输出通道Oc为512;Shortcut的输入同Conv1,其中H*W为28*28,输入通道Ic为512;两部分计算合并之后的输出Output的H*W为28*28,通道Oc为512。(本文所有的算法都围绕A100 GPU进行介绍)
3.1关于data、weight、output的layout变换
本文采用的计算数据类型为int8,因此下文介绍的所有内容都是基于int8开展的优化。
算法对data以及weight进行了提前处理以适应GPU的计算特性,主要处理如下:
对于data,原始layout为[B, H, W, Ic]=[B, 28, 28, 128],算法将Ic=128以32为单位进行拆分为4组,形成[B, 4, H, W, Ic/32]=[B, 4(I1), 28, 28, 32(I2)]的layout,这样做的目的是32个int8可以组成16B共128位数据的联合向量化读写,提高GPU中全局内存的通信速度。
对于weight,由于h*w=1*1,因此本文后续不再表示h*w,默认的weight的layout为[Ic, Oc]=[128, 512],算法将Ic以32为单位进行拆分为4组,将4放在左数第二维,将32放在左数第四维,这样做的目的也是为了程序在访问全局内存时做到16B共128位数据的联合向量化读写;算法将Oc以128为单位进行拆分为4组,将4放在左数第一维,将128放在左数第三维,这样做的目的是将Oc拆成了4组放在了不同的block中进行计算,这样在每个block进行计算的时候可以顺序的由全局内存加载weight,不会产生数据内存位置的跳跃,这部分会在后面block的划分中进行介绍,这样就形成[O1, I1, O2, I2] =[4, 4, 128, 32]的weight的layout。
对于output,原始layout为[B, H, W, Oc]=[B, 28, 28, 512],这部分数据类似于输入data,将Oc以32为单位进行拆分为16组,形成layout为[B, 16, H, W, Oc/32]=[B, 16(O1), 28, 28, 32(O2)]。
3.2关于Grid以及Block的并行划分:
对于Grid的划分,首先是x维度,由上文可知,对于Conv3的Oc为512,本文将Oc划分为4组放到Grid.x维度,每组计算的Oc为128;对于y维度,将H*W=28*28=784分为49组放到Grid.y维度,每组计算的HW为16;对于z维度,将B分为B/4组放到Grid.z维度,每组计算B的数量是4。这样经过划分,Grid的数量为[Grid.x, Grid.y, Grid.z]=[4, 49, B/4],即共有4*49*B/4组计算同时并行进行。A100 GPU上SM数量有108个,当B≥4时,一个kernel共需要启动大于4*49*4/4=196个Block,完全满足Grid维度并行度的要求。
对于Block中的划分,A100 GPU中一个SM的warp schedule为4个,因此一个block中线程数量至少大于或等于128,为了实现更好的并行度,算法选择一个Block中设置8个warp共256个线程。
3.3关于Block内部计算层次划分
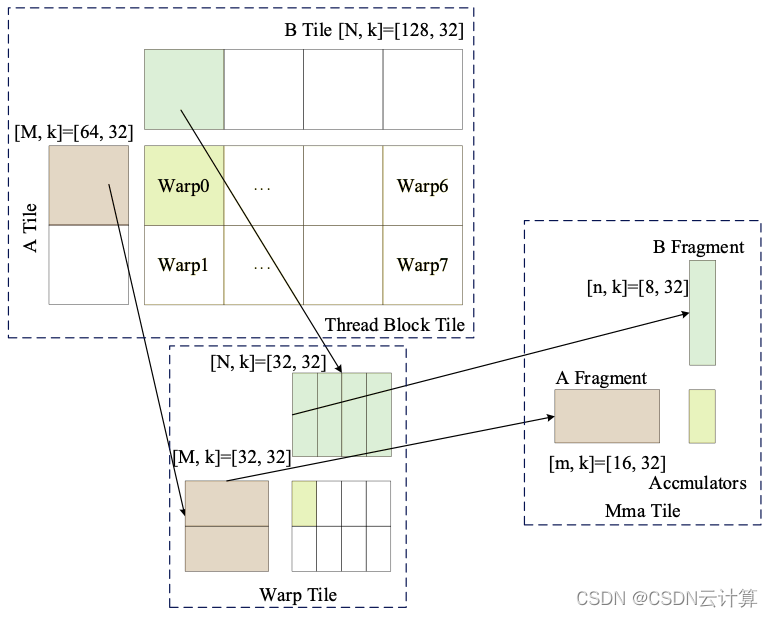
图3 Block内部计算层析划分
由上文可知,一个Block中划分的Output的计算shape为[B, H*W, Oc]=[4, 16, 128],由于在1*1卷积计算中B维度与HW维度具有同等地位,因此将BHW合并为一个维度,此时本文用M表示BHW维度,即M=BHW=4*16=64,用N表示Oc维度,即N=Oc=128,此时一个Block中的计算维度变为[M,N]=[64, 128]。
由前述data的layout的变换可知形成[B, 4, H, W, Ic/32]=[B, 4, 28, 28, 32]的layout,由于Grid.y以及Grid.x对B维度以及HW维度进行了划分,此时一个Block中data的输入数据为[B, I1, HW, I2]=[4, 4, 16, 32],用上段所述BHW合并为1维用M表示,即M=B*HW=4*16=64,K表示I1*I2维度,即K=I1*I2=128,则此时一个Block中data的计算维度变为[M, K]=[64, 128]。
由前述weight的layout的变换可知,weight的layout为[O1, I1, O2, I2]=[4, 4, 128, 32],由于对Oc按照32为单位划分4组在Grid.x维度,因此每个Block中计算的Oc为128,此时一个Block中的weight的计算数据为[I1, O2, I2] =[4, 128, 32],用N表示O2维度,即N=O2=128,用K表示I1*I2维度,即K=I1*I2=128,则此时一个Block中weight的计算维度变为[N, K]=[128, 128]。
一个Block中实际要进行的计算就变为一个矩阵乘data[M, K]点乘weight[N, K]等于output[M, N],即[64, 128]﹒[128,128]=[64, 128],共4*49*B/4个Block并行完成所有整个卷积合并的计算,其中data的实际维度为[B, I1, HW, I2]=[4, 4, 16, 32],weight的实际维度为[I1, O, I2]=[4, 128, 32]。
经过前面的划分,一个Thread Block层次实际计算量为[64, 128]﹒[128,128]=[64, 128]。
为了加速int8矩阵乘的计算,程序采用了CUDA中mma进行加速计算,其中mma的计算形状为[m ,n ,k]=[16, 8, 32],为了配合共享内存,寄存器以及mma形状的匹配,程序将内积方向的K维度128拆分为2组64进行计算,每组64进一步拆分为2组32(k)进行计算,这样最基础的Thread Block层次进行的计算就变为图3中左上角虚线框中所示的[M, k]﹒[N, k]=[M ,N]即[64, 32]﹒[128, 32]=[64 ,128],由于一个Block中设置warp的数量为8,8个warp会对Thread Block中的计算任务进行划分,每个warp计算任务为[32, 32]﹒[32, 32]=[32, 32]的矩阵乘,经过内积方向的4次32的循环,在warp level便可以将内积方向K=128完全计算得[M, N]=[32, 32]的计算结果,则8个warp合并可得[M, N]=[64, 128]的计算结果。
如上文所述,程序将内积方向的K维度128拆分为2组64进行计算,每组64进一步拆分为2组32(k)进行计算。这么做的目的是将data以及weight的全局内存加载变成了Double buffer模式,即首先将第一组的数据由全局内存加载到共享内存,然后在利用第一组的数据进行计算前,便提交第二组数据由全局内存加载到共享内存的过程,这样可以利用第一组数据的计算过程时间来隐藏第二组数据的全局内存加载到共享内存的过程的时间,整体流程示意图如下:
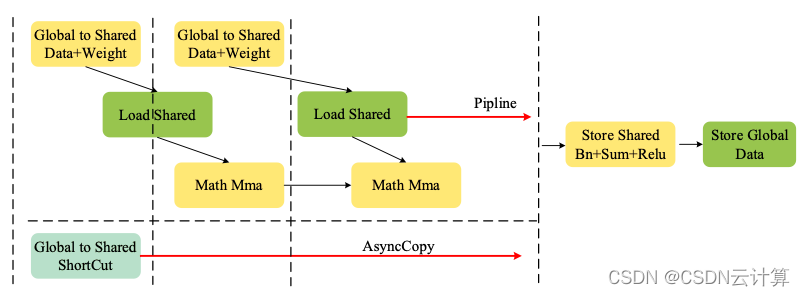
图4 程序整体流程图
如前所述,每个warp计算任务为[32, 32]﹒[32, 32]=[32, 32]的矩阵乘,因此在warp的计算层次配合[m ,n ,k]=[16, 8, 32]的形状,需要进行row=2,col=4,共row*col=8次mma的计算才可以得到warp 层次的计算结果,在计算时配合ldmatrix的使用可以进一步提高程序的计算性能。
对于Mma层次的计算,根据mma的形状,单次计算为[m , k]﹒[n, k]=[16, 32]﹒[8, 32]=[16, 8]。
3.4 Shoutcut的合并计算
经过以上计算,每个Block程序会得到Conv3的[M, N]=[64, 128]的计算结果,由于程序对Bn+Sum+Relu进行了合并,因此需要对Res3.1输出的原始数据进行加载。根据Grid[x , y, z]的划分,可以相应的得到Shortcut的数据偏移,为了隐藏这部分数据在全局内存加载到共享内存时通信延迟,程序利用了A100 GPU异步复制(pipeline_memcpy_async)的新特性,在程序的最开始便提交了这部分数据的加载,这样可以最大程度上利用计算的时间同时进行数据的加载以隐藏Shortcut的通信延迟,如图4所示。完成数据的加载后,会以warp为单位对每一个计算结果进行Bn+Sum+Relu的操作,最后将数据由寄存器写回共享内存,再写回全局内存完成整个卷积合并算法的计算。
4. 性能提升效果
根据上文介绍的卷积合并优化算法,在TensorRT中增加了关于卷积合并算法的plugin以替代原始算法,在A100 GPU单卡进行Conv3+Bn+Sum+Relu性能测试,在BatchSize=2048的情况下,原算法的性能为123TOPS,经过优化后的卷积合并优化算法性能为141TOPS,算子相比较原算法可以带来14.6%的性能提升。通过合并Res3.2、Res3.3、Res3.4三部分Conv3+Bn+Sum+Relu算子合并,可将Resnet50推理性能提升1%-2%。同样该算法合并思路可以用到其他残差结构中,通过合理的算法设计带来整体的程序性能提升。
在MLPerf V2.0推理竞赛中,浪潮通过软件与硬件优化,基于ImageNet数据集Resnet50模型,在Offline场景中达到了449,856 samples/s的计算性能,位居第一。



)



)








...)


