简介:本文讲讲述平安保险为何选择 RocketMQ,以及在确定使用消息中间件后,又是如何去选择哪款消息中间件的。
作者:孙园园|平安人寿资深开发
为什么选用 RocketMQ
首先跟大家聊聊我们为什么会选用 RocketMQ,在做技术选型的过程中,应用场景应该是最先考虑清楚的,只有确定好了应用场景在做技术选型的过程中才有明确的目标和衡量的标准。像异步、解耦、削峰填谷这些消息中间件共有的特性就不一一介绍了,这些特性是决定你的场景需不需要使用消息中间件,这里主要讲述下在确定使用消息中间件后,又是如何去选择哪款消息中间件的。
同步双写,确保业务数据安全可靠不丢失
我们在搭建消息中间件平台时的定位是给业务系统做业务数据的传输使用,对业务数据的很重要的一个要求就是不允许丢数据,所以选用 RocketMQ 的第一点就是他有同步双写机制,数据在主从服务器上都刷盘成功才算发送成功。同步双写条件下,MQ 的写入性能与异步刷盘异步赋值相比肯定会有所下降,与异步条件下大约会有 20% 左右的下降,单主从架构下,1K 的消息写入性能还是能达到 8W+ 的 TPS,对大部分业务场景而言性能是能完全满足要求的,另外对下降的这部分性能可以通过 broker 的横向扩招来弥补,所以在同步双写条件下,性能是能满足业务需求的。
多 topic 应用场景下,性能依旧强悍
第二点,业务系统的使用场景会特别多,使用场景广泛带来的问题就是会创建大量的 topic,所以这时候就得去衡量消息中间件在多 topic 场景下性能是否能满足需求。我自己在测试的时候呢,用 1K 的消息随机往 1 万个 topic 写数据,单 broker 状态下能达到2W左右的 TPS,这一点比 Kafka 要强很多。所以多 topic 应用场景下,性能依旧强悍是我们选用 topic 的第二个原因。这点也是由底层文件存储结构决定的,像 Kafka、RocketMQ 这类消息中间件能做到接近内存的读写能力,主要取决于文件的顺序读写和内存映射。RocketMQ 中的所有 topic 的消息都是写在同一个 commitLog 文件中的,但是 Kafka 中的消息是以 topic 为基本单位组织的,不同的 topic 之间是相互独立的。在多 topic 场景下就造成了大量的小文件,大量的小文件在读写时存在一个寻址的过程,就有点类似随机读写了,影响整体的性能。
支持事务消息、顺序消息、延迟消息、消息消费失败重试等
RocketMQ 支持事务消息、顺序消息、消息消费失败重试、延迟消息等,功能比较丰富,比较适合复杂多变的业务场景使用。
社区建设活跃,阿里开源系统
另外,在选用消息中间件时也要考虑下社区的活跃度和源码所使用的开发语言,RocketMQ 使用 Java 开发,对 Java 开发人员就比较友好,不管是阅读源码排查问题还是在 MQ 的基础上做二次开发都比较容易一点。社区里同学大都是国内的小伙伴,对大家参与 RocketMQ 开源贡献也是比较亲近的,这里呢也是希望更多的小伙伴能参与进来,为国内开源项目多做贡献。
SPI 机制简介及应用
介绍完为什么选用 RocketMQ 后,接下来给大家介绍下我们是如何基于 SPI 机制应用 RocketMQ 的。SPI 全称为 (Service Provider Interface) ,是 JDK 内置的一种服务提供发现机制,我个人简单理解就是面向接口编程,留给使用者一个扩展的点,像 springBoot 中的 spring.factories 也是 SPI 机制的一个应用。如图给大家展示的是 RocketMQ 中 SPI 的一个应用。我们基于 SPI 机制的 RocketMQ 客户端的应用的灵感也是来自于 MQ 中 SPI 机制的应用。RocketMQ 在实现 ACL 权限校验的时候,是通过实现 AccessValidator 接口,PlainAccessValidator 是 MQ 中的默认实现。权限校验这一块,可能因为组织架构的不一样会有不同的实现方式,通过 SPI 机制提供一个接口,为开发者定制化开发提供扩展点。在有定制化需求时只需要重新实现 AccessValidator 接口,不需要对源码大动干戈。


接下来先给大家介绍下我们配置文件的一个简单模型,在这个配置文件中除了 sendMsgService、consumeMsgConcurrently、consumeMsgOrderly 这三个配置项外其余的都是 RocketMQ 原生的配置文件,发送消息和消费消息这三个配置项呢就是 SPI 机制的应用,是为具体实现提供的接口。可能有的同学会有疑问,SPI 的配置文件不是应该放在 META-INF.service 路径下么?这里呢我们是为了方便配置文件的管理,索性就跟 MQ 配置文件放在了一起。前面也提到了,META-INF.service 只是一个默认的路径而已,为了方便管理做相应的修改也没有违背SPI机制的思想。
我们再看下这个配置文件模型,这里的配置项呢囊括了使用 MQ 时所要配置的所有选项,proConfigs 支持所有的 MQ 原生配置,这样呢也就实现了配置与应用实现的解耦,应用端只需呀关注的具体的业务逻辑即可,生产者消费者的实现和消费者消费的 topic 都可以通过配置文件来指定。另外该配置文件也支持多 nameserver 的多环境使用,在较复杂的应用中支持往多套 RocketMQ 环境发送消息和消费多套不同环境下的消息。消费者提供了两个接口主要是为了支持 RocketMQ 的并发消费和顺序消费。接下来呢给大家分享下如何根据这个配置文件来初始化生产者消费者。首先给大家先介绍下我们抽象出来的客户端加载的一个核心流程。
客户端核心流程详情

图中大家可以看到,客户端的核心流程我们抽象成了三部分,分别是启动期、运行期和终止期。首先加载配置文件呢就是加载刚刚介绍的那个配置文件模型,在配置与应用完全解耦的状态下,必须先加载完配置文件才能初始化后续的流程。在初始化生产者和消费者之前应当先创建好应用实现的生产者和消费者的业务逻辑对象 供生产者和消费者使用。在运行期监听配置文件的变化,根据变化动态的调整生产者和消费者实例。这里还是要再强调下配置与应用的解耦为动态调整提供了可能。终止期就比较简单了,就是关闭生产者和消费者,并从容器中移除。这里的终止期指的生产者和消费者的终止,并不是整个应用的终止,生产者和消费者的终止可能出现在动态调整的过程中,所以终止了的实例一定要从容器中移除,方便初始化后续的生产者和消费者。介绍完基本流程后,接下来给大家介绍下配置文件的加载过程。
如何加载配置文件

配置文件加载这一块的话,流程是比较简单的。这里主要讲的是如何去兼容比较老的项目。RocketMQ 客户端支持的 JDK 最低版本是 1.6,所以在封装客户端时应该要考虑到新老项目兼容的问题。在这里呢我们客户端的核心包是支持 JDK1.6 的,spring 早期的项目配置文件一般都是放在在 resources 路径下,我们是自己实现了一套读取配置文件的和监听配置文件的方法,具体的大家可以参考 acl 中配置文件的读取和监听。在核心包的基础上用 springBoot 又封装了一套自动加载配置文件的包供微服务项目使用,配置文件的读取和监听都用的 spring 的那一套。配置文件加载完之后, 配置文件中应用实现的生产者和消费者是如何与 RocketMQ 的生产者和消费者相关联的呢?接下来给大家分享下这方面的内容。
如何将生产消费者与业务实现关联
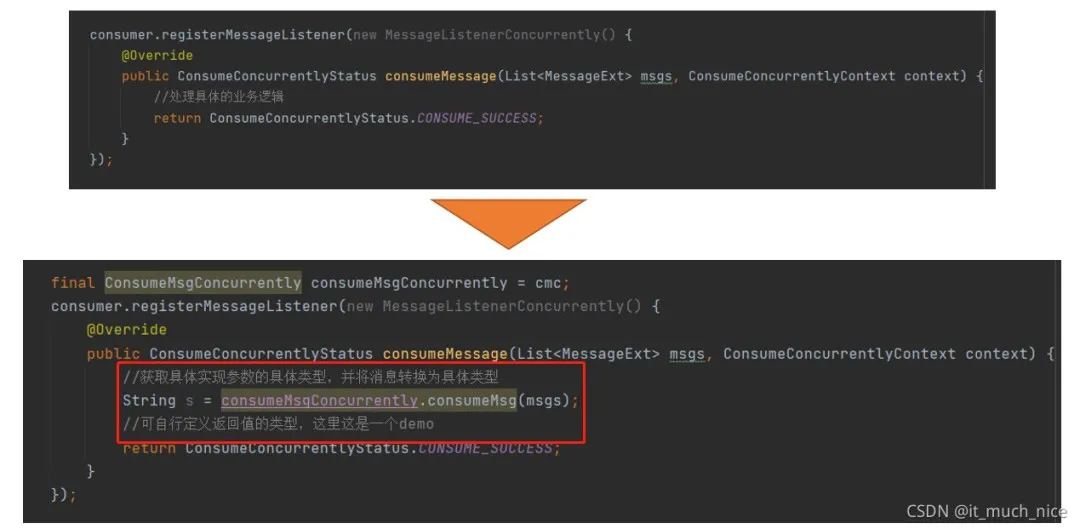
首先先看下消费者是如何实现关联的,上图是 MQ 消费者的消息监听器,需要我们去实现具体的业务逻辑处理。通过将配置文件中实现的消费逻辑关联到这里就能实现配置文件中的消费者与 RocketMQ 消费者的关联。消费者的接口定义也是很简单,就是去消费消息。消费消息的类型可以通过泛型指定,在初始化消费者的时候获取具体实现的参数类型,并将MQ 接受到的消息转换为具体的业务类型数据。由客户端统一封装好消息类型的转换。对消费消息的返回值大家可以根据需要与 MQ 提供的 status 做一个映射,这里的 demo 只是简单显示了下。在获取具体的应用消费者实例的时候,如果你的消费逻辑里使用了 spring 管理的对象,那么你实现的消费逻辑对象也要交给 spring 管理,通过 spring 上下文获取初始化好的对象;如果你的消费逻辑里没有使用 spring 进行管理,可以通过反射的方式自己创建具体的应用实例。
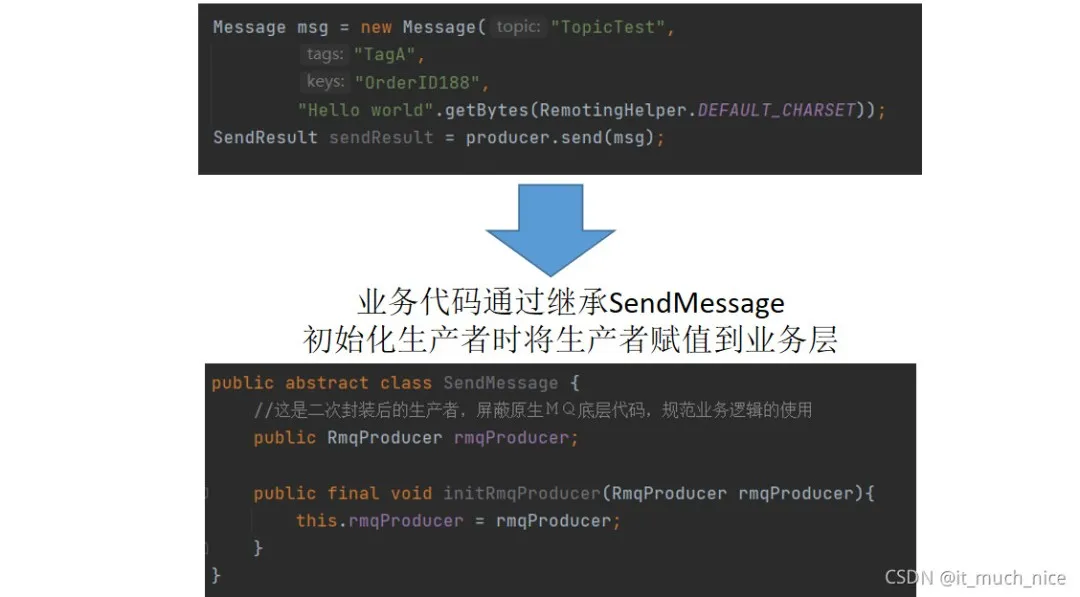
与消费者不一样的是生产者需要将初始化好的 producer 对象传递到应用代码中去,而消费者是去获取应用中实现的逻辑对象,那如何将 producer 传递到业务应用中去呢?
业务代码中实现的生产者需要继承 SendMessage,这样业务代码就获得了 RmqProducer 对象,这是一个被封装后的生产者对象,该对象对发送消息的方法进行的规范化定义,使之符合公司的相应规范制度,该对象中的方法也会对 topic 的命名规范进行检查,规范 topic 有一个统一的命名规范。
如何动态调整生产消费者

首先谈到动态调整就需要谈一下动态调整发生的场景,如果没有合适的使用场景的话实现动态调整就有点华而不实了。这里我列举了四个配置文件发生变化的场景:
nameserver发生变化的时候,需要重新初始化所有的生产者和消费者,这个一般是在 MQ 做迁移或者当前 MQ 集群不可用是需要紧急切换 MQ;
增减实例的场景只要启动或关闭相应的实例即可,增加应用实例的场景一般是在需要增加一个消费者来消费新的 topic 的,减少消费者一般是在某个消费者发生异常时需要紧急关闭这个消费者,及时止损。
调整消费者线程的场景中我们对源码进行了一点修改,让应用端能获取到消费者的线程池对象,以便对线程池的核心线程数进行动态调整。这个的应用场景一般是在当某个消费者消费的数据比较多,占用过多的 CPU 资源时,导致优先级更高的消息得不到及时处理,可以先将该消费者的线程调小一些。
应用的优点

原文链接
本文为阿里云原创内容,未经允许不得转载。





中实现超时)









移动端:让数据在更多业务场景中流通)

发布中心:生产和开发隔离模式下的保护伞)

)