简介:随着深度学习的不断发展,AI模型结构在快速演化,底层计算硬件技术更是层出不穷,对于广大开发者来说不仅要考虑如何在复杂多变的场景下有效的将算力发挥出来,还要应对计算框架的持续迭代。深度编译器就成了应对以上问题广受关注的技术方向,让用户仅需专注于上层模型开发,降低手工优化性能的人力开发成本,进一步压榨硬件性能空间。阿里云机器学习PAI开源了业内较早投入实际业务应用的动态shape深度学习编译器 BladeDISC,本文将详解 BladeDISC的设计原理和应用。

作者 | 姜来
来源 | 阿里技术公众号
一 导读
随着深度学习的不断发展,AI模型结构在快速演化,底层计算硬件技术更是层出不穷,对于广大开发者来说不仅要考虑如何在复杂多变的场景下有效的将算力发挥出来,还要应对计算框架的持续迭代。深度编译器就成了应对以上问题广受关注的技术方向,让用户仅需专注于上层模型开发,降低手工优化性能的人力开发成本,进一步压榨硬件性能空间。阿里云机器学习PAI开源了业内较早投入实际业务应用的动态shape深度学习编译器 BladeDISC,本文将详解 BladeDISC的设计原理和应用。
二 BladeDISC是什么
BladeDISC是阿里最新开源的基于MLIR的动态shape深度学习编译器。
1 主要特性
- 多款前端框架支持:TensorFlow,PyTorch
- 多后端硬件支持:CUDA,ROCM,x86
- 完备支持动态shape语义编译
- 支持推理及训练
- 轻量化API,对用户通用透明
- 支持插件模式嵌入宿主框架运行,以及独立部署模式
三 深度学习编译器的背景
近几年来,深度学习编译器作为一个较新的技术方向异常地活跃,包括老牌一些的TensorFlow XLA、TVM、Tensor Comprehension、Glow,到后来呼声很高的MLIR以及其不同领域的延伸项目IREE、mlir-hlo等等。能够看到不同的公司、社区在这个领域进行着大量的探索和推进。
1 AI浪潮与芯片浪潮共同催生——从萌芽之初到蓬勃发展
深度学习编译器近年来之所以能够受到持续的关注,主要来自于几个方面的原因:
框架性能优化在模型泛化性方面的需求
深度学习还在日新月异的发展之中,创新的应用领域不断涌现,复杂多变的场景下如何有效的将硬件的算力充分发挥出来成为了整个AI应用链路中非常重要的一环。在早期,神经网络部署的侧重点在于框架和算子库,这部分职责很大程度上由深度学习框架、硬件厂商提供的算子库、以及业务团队的手工优化工作来承担。
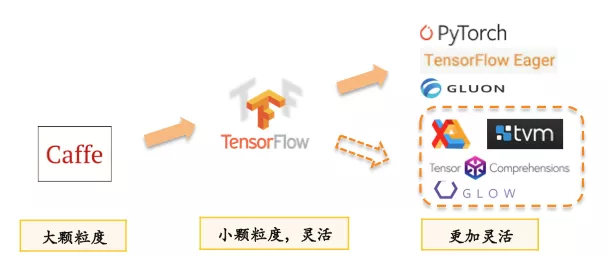
上图将近年的深度学习框架粗略分为三代。一个趋势是在上层的用户API层面,这些框架在变得越来越灵活,灵活性变强的同时也为底层性能问题提出了更大的挑战。初代深度学习框架类似 Caffe 用 sequence of layer 的方式描述神经网络结构,第二代类似 TensorFlow 用更细粒度的 graph of operators 描述计算图,到第三代类似 PyTorch,TensorFlow Eager Mode 的动态图。我们可以看到框架越来越灵活,描述能力越来越强,带来的问题是优化底层性能变得越来越困难。业务团队也经常需要补充完成所需要的手工优化,这些工作依赖于特定业务和对底层硬件的理解,耗费人力且难以泛化。而深度学习编译器则是结合编译时图层的优化以及自动或者半自动的代码生成,将手工优化的原理做泛化性的沉淀,以替代纯手工优化带来的各种问题,去解决深度学习框架的灵活性和性能之间的矛盾。
AI框架在硬件泛化性方面的需求
表面上看近些年AI发展的有目共睹、方兴未艾,而后台的硬件算力数十年的发展才是催化AI繁荣的核心动力。随着晶体管微缩面临的各种物理挑战越来越大,芯片算力的增加越来越难,摩尔定律面临失效,创新体系结构的各种DSA芯片迎来了一波热潮,传统的x86、ARM等都在不同的领域强化着自己的竞争力。硬件的百花齐放也为AI框架的发展带来了新的挑战。
而硬件的创新是一个问题,如何能把硬件的算力在真实的业务场景中发挥出来则是另外一个问题。新的AI硬件厂商不得不面临除了要在硬件上创新,还要在软件栈上做重度人力投入的问题。向下如何兼容硬件,成为了如今深度学习框架的核心难点之一,而兼容硬件这件事,则需要由编译器来解决。
AI系统平台对前端AI框架泛化性方面的需求
当今主流的深度学习框架包括Tensoflow、Pytorch、Keras、JAX等等,几个框架都有各自的优缺点,在上层对用户的接口方面风格各异,却同样面临硬件适配以及充分发挥硬件算力的问题。不同的团队常根据自己的建模场景和使用习惯来选择不同的框架,而云厂商或者平台方的性能优化工具和硬件适配方案则需要同时考虑不同的前端框架,甚至未来框架演进的需求。Google利用XLA同时支持TensorFlow和JAX,同时其它开源社区还演进出了Torch_XLA,Torch-MLIR这样的接入方案,这些接入方案目前虽然在易用性和成熟程度等方面还存在一些问题,却反应出AI系统层的工作对前端AI框架泛化性方面的需求和技术趋势。
2 什么是深度学习编译器
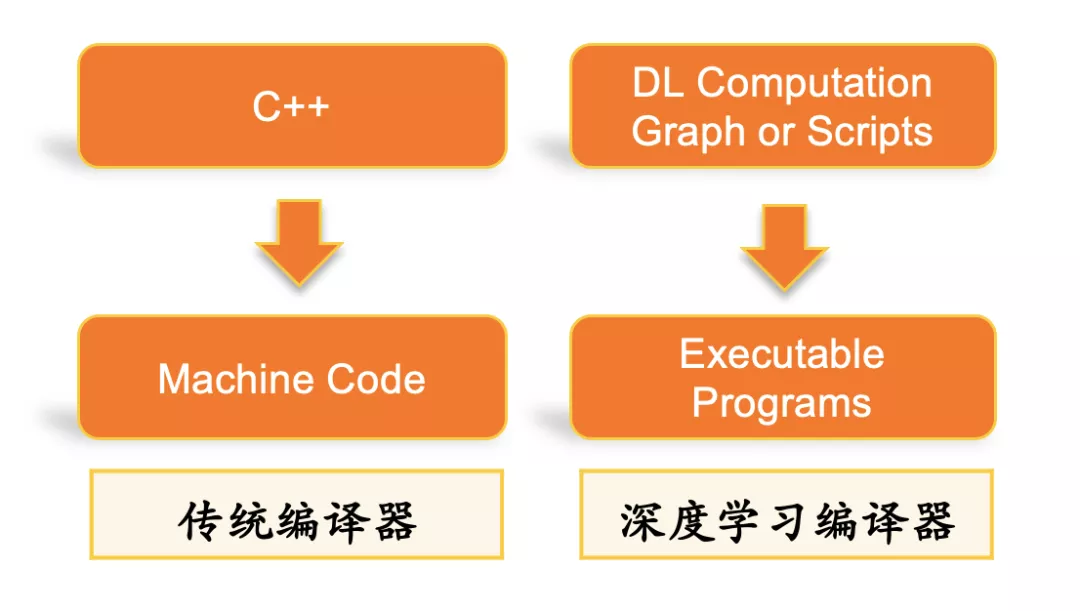
传统编译器是以高层语言作为输入,避免用户直接去写机器码,而用相对灵活高效的语言来工作,并在编译的过程中引入优化来解决高层语言引入的性能问题,平衡开发效率与性能之间的矛盾。而深度学习编译器的作用相仿,其输入是比较灵活的,具备较高抽象度的计算图描述,输出包括CPU、GPU及其他异构硬件平台上的底层机器码及执行引擎。
传统编译器的使命之一是减轻编程者的压力。作为编译器的输入的高级语言往往更多地是描述一个逻辑,为了便利编程者,高级语言的描述会更加抽象和灵活,至于这个逻辑在机器上是否能够高效的执行,往往是考验编译器的一个重要指标。深度学习作为一个近几年发展异常快速的应用领域,它的性能优化至关重要,并且同样存在高层描述的灵活性和抽象性与底层计算性能之间的矛盾,因此专门针对深度学习的编译器出现了。而传统编译器的另外一个重要使命是,需要保证编程者输入的高层语言能够执行在不同体系结构和指令集的硬件计算单元上,这一点也同样反应在深度学习编译器上。面对一个新的硬件设备,人工的话不太可能有精力对那么多目标硬件重新手写一个框架所需要的全部算子实现,深度学习编译器提供中间层的IR,将顶层框架的模型流图转化成中间层表示IR,在中间层IR上进行通用的图层优化,而在后端将优化后的IR通用性的生成各个目标平台的机器码。
深度学习编译器的目标是针对AI计算任务,以通用编译器的方式完成性能优化和硬件适配。让用户可以专注于上层模型开发,降低用户手工优化性能的人力开发成本,进一步压榨硬件性能空间。
3 距离大规模应用面临的瓶颈问题
深度学习编译器发展到今天,虽然在目标和技术架构方面与传统编译器有颇多相似之处,且在技术方向上表现出了良好的潜力,然而目前的实际应用范围却仍然距离传统编译器有一定的差距,主要难点包括:
易用性
深度学习编译器的初衷是希望简化手工优化性能和适配硬件的人力成本。然而在现阶段,大规模部署应用深度学习编译器的挑战仍然较大,能够将编译器用好的门槛较高,造成这个现象的主要原因包括:
- 与前端框架对接的问题。不同框架对深度学习任务的抽象描述和API接口各有不同,语义和机制上有各自的特点,且作为编译器输入的前端框架的算子类型数量呈开放性状态。如何在不保证所有算子被完整支持的情况下透明化的支持用户的计算图描述,是深度学习编译器能够易于为用户所广泛使用的重要因素之一。
- 动态shape问题和动态计算图问题。现阶段主流的深度学习编译器主要针对特定的静态shape输入完成编译,此外对包含control flow语义的动态计算图只能提供有限的支持或者完全不能够支持。而AI的应用场景却恰恰存在大量这一类的任务需求。这时只能人工将计算图改写为静态或者半静态的计算图,或者想办法将适合编译器的部分子图提取出来交给编译器。这无疑加重了应用深度学习编译器时的工程负担。更严重的问题是,很多任务类型并不能通过人工的改写来静态化,这导致这些情况下编译器完全无法实际应用。
- 编译开销问题。作为性能优化工具的深度学习编译器只有在其编译开销对比带来的性能收益有足够优势的情况下才真正具有实用价值。部分应用场景下对于编译开销的要求较高,例如普通规模的需要几天时间完成训练任务有可能无法接受几个小时的编译开销。对于应用工程师而言,使用编译器的情况下不能快速的完成模型的调试,也增加了开发和部署的难度和负担。
- 对用户透明性问题。部分AI编译器并非完全自动的编译工具,其性能表现比较依赖于用户提供的高层抽象的实现模版。主要是为算子开发工程师提供效率工具,降低用户人工调优各种算子实现的人力成本。但这也对使用者的算子开发经验和对硬件体系结构的熟悉程度提出了比较高的要求。此外,对于新硬件的软件开发者来说,现有的抽象却又常常无法足够描述创新的硬件体系结构上所需要的算子实现。需要对编译器架构足够熟悉的情况下对其进行二次开发甚至架构上的重构,门槛及开发负担仍然很高。
鲁棒性
目前主流的几个AI编译器项目大多数都还处于偏实验性质的产品,但产品的成熟度距离工业级应用有较大的差距。这里的鲁棒性包含是否能够顺利完成输入计算图的编译,计算结果的正确性,以及性能上避免coner case下的极端badcase等。
性能问题
编译器的优化本质上是将人工的优化方法,或者人力不易探究到的优化方法通过泛化性的沉淀和抽象,以有限的编译开销来替代手工优化的人力成本。然而如何沉淀和抽象的方法学是整个链路内最为本质也是最难的问题。深度学习编译器只有在性能上真正能够代替或者超过人工优化,或者真正能够起到大幅度降低人力成本作用的情况下才能真正发挥它的价值。
然而达到这一目标却并非易事,深度学习任务大都是tensor级别的计算,对于并行任务的拆分方式有很高的要求,但如何将手工的优化泛化性的沉淀在编译器技术内,避免编译开销爆炸以及分层之后不同层级之间优化的联动,仍然有更多的未知需要去探索和挖掘。这也成为以MLIR框架为代表的下一代深度学习编译器需要着重思考和解决的问题。
四 BladeDISC的主要技术特点
项目最早启动的初衷是为了解决XLA和TVM当前版本的静态shape限制,内部命名为 DISC (DynamIc Shape Compiler),希望打造一款能够在实际业务中使用的完备支持动态shape语义的深度学习编译器。
从团队四年前启动深度学习编译器方向的工作以来,动态shape问题一直是阻碍实际业务落地的严重问题之一。彼时,包括XLA在内的主流深度学习框架,都是基于静态shape语义的编译器框架。典型的方案是需要用户指定输入的shape,或是由编译器在运行时捕捉待编译子图的实际输入shape组合,并且为每一个输入shape组合生成一份编译结果。
静态shape编译器的优势显而易见,编译期完全已知静态shape信息的情况下,Compiler可以作出更好的优化决策并得到更好的CodeGen性能,同时也能够得到更好的显存/内存优化plan和调度执行plan。然而,其缺点也十分明显,具体包括:
- 大幅增加编译开销。引入离线编译预热过程,大幅增加推理任务部署过程复杂性;训练迭代速度不稳定甚至整体训练时间负优化。
- 部分业务场景shape变化范围趋于无穷的,导致编译缓存永远无法收敛,方案不可用。
- 内存显存占用的增加。编译缓存额外占用的内存显存,经常导致实际部署环境下的内存/显存OOM,直接阻碍业务的实际落地。
- 人工padding为静态shape等缓解性方案对用户不友好,大幅降低应用的通用性和透明性,影响迭代效率。
在2020年夏天,DISC完成了仅支持TensorFlow前端以及Nvidia GPU后端的初版,并且正式在阿里内部上线投入实际应用。最早在几个受困于动态shape问题已久的业务场景上投入使用,并且得到了预期中的效果。即在一次编译且不需要用户对计算图做特殊处理的情况下,完备支持动态shape语义,且性能几乎与静态shape编译器持平。对比TensorRT等基于手工算子库为主的优化框架,DISC基于编译器自动codegen的技术架构在经常为非标准开源模型的实际业务上获得了明显的性能和易用性优势。
从2020年第二季度开始至今,DISC持续投入研发力量,针对前文提到的从云端平台方视角看到的深度学习编译器距离大规模部署和应用的几个瓶颈问题,在性能、算子覆盖率和鲁棒性、CPU及新硬件支持、前端框架支持等方面逐渐完善。目前在场景覆盖能力和性能等方面,已经逐渐替换掉团队过往基于XLA和TVM等静态shape框架上的工作,成为PAI-Blade支持阿里内部及阿里云外部业务的主要优化手段。2021年后,DISC在CPU及GPGPU体系结构的后端硬件上的性能有了显著的提升,同时在新硬件的支持上面投入了更多的技术力量。2021年底,为了吸引更多的技术交流和合作共建需要,以及更大范围的用户反馈,正式更名为BladeDISC并完成了初版开源。
五 关键技术
BladeDISC的整体架构,及其在阿里云相关产品中的上下文关系如下图所示:
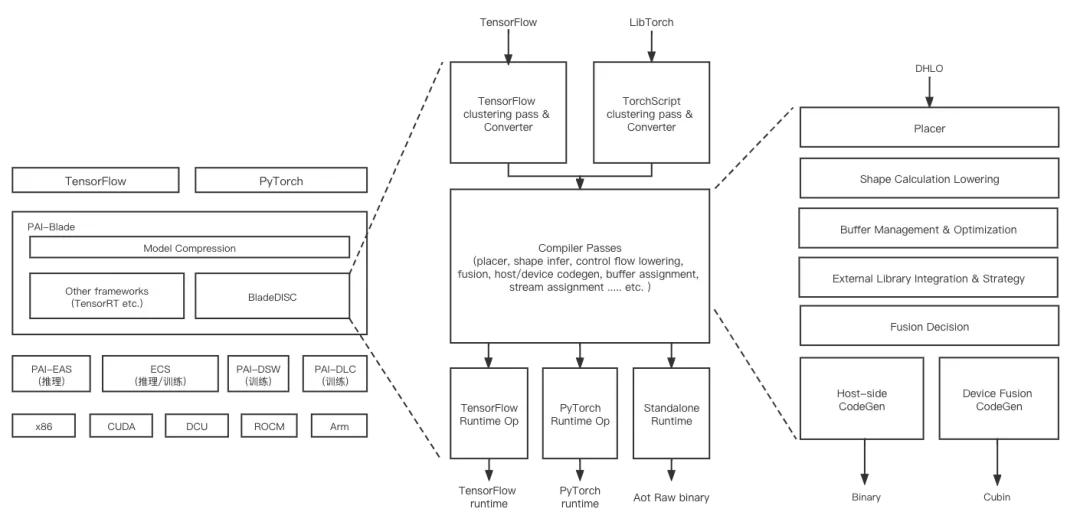
1 MLIR基础架构
MLIR是由Google在2019年发起的项目,MLIR 的核心是一套灵活的多层IR基础设施和编译器实用工具库,深受 LLVM 的影响,并重用其许多优秀理念。这里我们选择基于MLIR的主要原因包括其比较丰富的基础设施支持,方便扩展的模块化设计架构以及MLIR较强的胶水能力。
2 动态shape编译
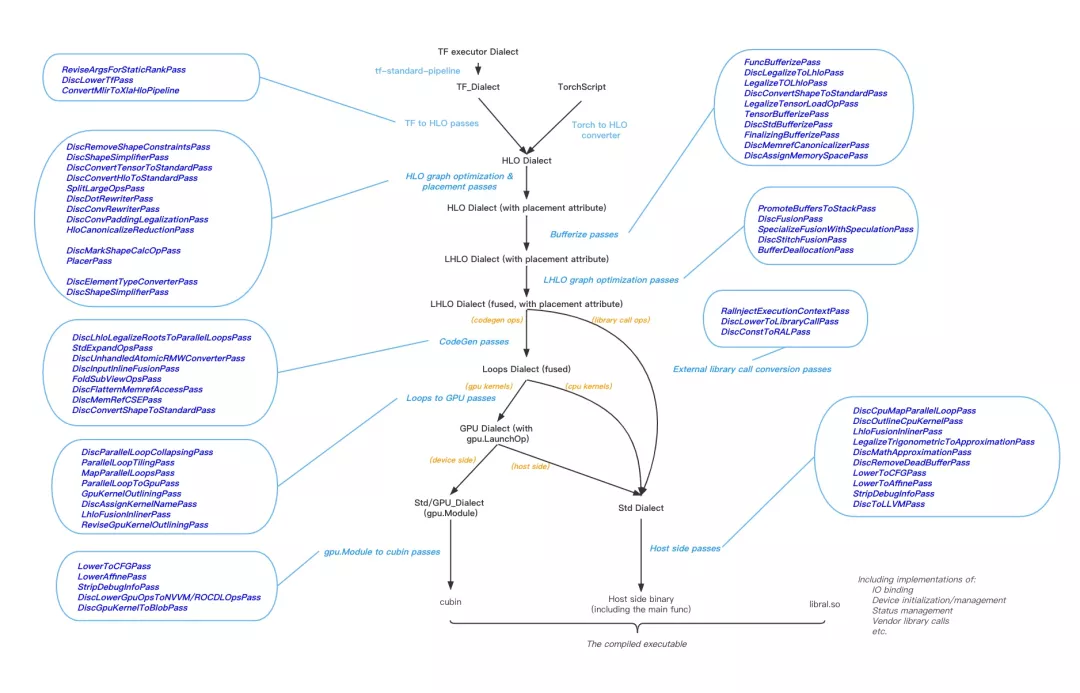
上图为BladeDISC的主体Pass Pipeline设计。对比目前主流的深度学习编译器项目,主要技术特点如下:
图层IR设计
BladeDISC选择基于HLO作为核心图层IR来接入不同的前端框架,但是HLO是原本为XLA设计的纯静态shape语义的IR。静态场景下,HLO IR中的shape表达会被静态化,所有的shape计算会被固化为编译时常量保留在编译结果中;而在动态shape场景下,IR本身需要有足够的能力表达shape计算和动态shape信息的传递。BladeDISC从项目建立开始一直与MHLO社区保持紧密的合作,在XLA的HLO IR基础上,扩展了一套具有完备动态shape表达能力的IR,并增加了相应的基础设施以及前端框架的算子转换逻辑。这部分实现目前已经完整upstream至MHLO社区,确保后续其它MHLO相关项目中IR的一致性。
运行时Shape计算、存储管理和Kernel调度
动态shape编译的主要挑战来自于需要在静态的编译过程中能够处理动态的计算图语义。为完备支持动态shape,编译结果需要能够在运行时做实时的shape推导计算,不仅要为数据计算,同时也需要为shape计算做代码生成。计算后的shape信息用于做内存/显存管理,以及kernel调度时的参数选择等等。BladeDISC的pass pipeline的设计充分考虑了上述动态shape语义支持的需求,采用了host-device联合codegen的方案。以GPU Backend为例,包括shape计算、内存/显存申请释放、硬件管理、kernel launch运行时流程全部为自动代码生成,以期得到完备的动态shape端到端支持方案和更为极致的整体性能。
动态shape下的性能问题
在shape未知或者部分未知的情况下,深度学习编译器在性能上面临的挑战被进一步放大。在大多数主流硬件backend上,BladeDISC采用区分计算密集型部分和访存密集型部分的策略,以期在性能与复杂性和编译开销之间获取更好的平衡。
对于计算密集型部分,不同的shape要求更加精细的schedule实现来获得更好的性能,pass pipeline在设计上的主要考虑是需要支持在运行时根据不同的具体shape选择合适的算子库实现,以及处理动态shape语义下的layout问题。
而访存密集型部分的自动算子融合作为深度学习编译器主要的性能收益来源之一,同样面临shape未知情况下在性能上的挑战。许多静态shape语义下比较确定性的问题,例如指令层的向量化,codegen模版选择,是否需要implicit broadcast等等在动态shape场景下都会面临更大的复杂性。针对这些方面的问题,BladeDISC选择将部分的优化决策从编译时下沉到运行时。即在编译期根据一定的规则生成多个版本的kernel实现,在运行时根据实际shape自动选择最优的实现。这一机制被称作speculation,在BladeDISC内基于host-device的联合代码生成来实现。此外,在编译期没有具体shape数值的情况下,会很容易在各个层级丢失掉大量的优化机会,从图层的线性代数简化、fusion决策到指令层级的CSE、常数折叠等。BladeDISC在IR及pass pipeline的设计过程中着重设计了shape constraint在IR中的抽象和在pass pipeline中的使用,例如编译期未知的不同dimension size之间的约束关系等。在优化整体性能方面起到了比较明显的作用,保证能够足够接近甚至超过静态shape编译器的性能结果。
大颗粒度算子融合
团队在开启BladeDISC项目之前,曾经基于静态shape编译器在大颗粒度算子融合及自动代码生成方面有过若干探索3,其基本思想可以概括为借助于GPU硬件中低访存开销的shared memory或CPU中低访存开销的Memory Cache,将不同schedule的计算子图缝合进同一个kernel内,实现多个parallel loop复合,这种codegen方法称之为fusion-stitching。这种访存密集型子图的自动代码生成打破了常规的loop fusion,input/output fusion对fusion颗粒度的限制。在保证代码生成质量的同时,大幅增加fusion颗粒度,同时避免复杂性及编译开销爆炸。且整个过程完全对用户透明,无需人工指定schedule描述。
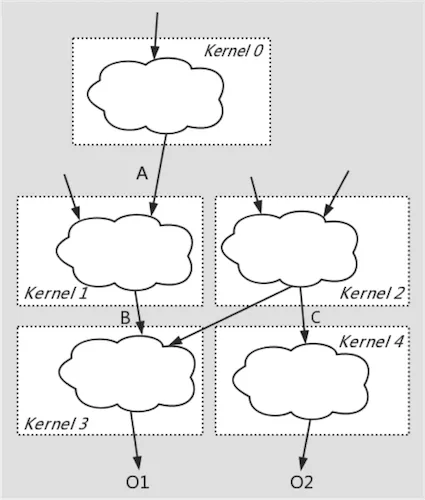
在动态shape语义下实现fusion-stitching对比静态shape语义下同样需要处理更大的复杂性,动态shape语义下的shape constraint抽象一定程度上简化了这一复杂性,使整体性能进一步接近甚至超过手工算子实现。
3 多前端框架支持
AICompiler框架在设计时也包含了扩展支持不同前端框架的考虑。PyTorch侧通过实现一个轻量的Converter将TorchScript转换为DHLO IR实现了对PyTorch推理作业的覆盖。MLIR相对完备的IR基础设施也为Converter的实现提供了便利。BladeDISC包含Compiler以及适配不同前端框架的Bridge侧两部分。其中Bridge进一步分为宿主框架内的图层pass以及运行时Op两部分,以插件的方式接入宿主框架。这种工作方式使BladeDISC可以透明化的支持前端计算图,可以适配用户各种版本的宿主框架。
4 运行时环境适配
为将编译的结果能够配合TensorFlow/PyTorch等宿主在各自的运行环境中执行起来,以及管理运行时IR层不易表达的状态信息等等,我们为不同的运行时环境实现了一套统一的Compiler架构,并引入了运行时抽象层,即RAL(Runtime Abstraction Layer)层。
RAL实现了多种运行环境的适配支持,用户可以根据需要进行选择,具体包括:
- 全图编译,独立运行。当整个计算图都支持编译时,RAL提供了一套简易的runtime以及在此之上RAL Driver的实现,使得compiler编译出来结果可以脱离框架直接运行,减少框架overhead。
- TF中子图编译运行。
- Pytorch中子图编译运行。
以上环境中在诸如资源管理,API语义等上存在差异,RAL通过抽象出一套最小集合的API ,并清晰的定义出它们的语义,将编译器与运行时隔离开来,来达到在不同的环境中都能够执行编译出来的结果的目的。此外RAL层实现了无状态编译,解决了计算图的编译之后,编译的结果可能被多次执行时的状态信息处理问题。一方面简化了代码生成的复杂度,另一方面也更容易支持多线程并发执行(比如推理)的场景,同时在错误处理,回滚方面也更加容易支持。
六 应用场景
BladeDISC的典型应用场景可以不太严格的分为两类:其一是在主流的硬件平台上(包括Nvidia GPU,x86 CPU等)上作为通用、透明的性能优化工具,降低用户部署AI作业的人力负担,提高模型迭代效率;另一个重要的应用场景是帮助新硬件做AI场景的适配和接入支持。
目前BladeDISC已经广泛应用在阿里内部和阿里云上外部用户的多个不同应用场景下,覆盖模型类型涉及NLP、机器翻译、语音类ASR、语音TTS、图像检测、识别、AI for science等等多种典型AI应用;覆盖行业包括互联网、电商、自动驾驶、安全行业、在线娱乐、医疗和生物等等。
在推理场景下,BladeDISC与TensorRT等厂商提供的推理优化工具形成良好的技术互补,其主要差异性优势包括:
- 应对动态shape业务完备的动态shape语义支持
- 基于compiler based的技术路径的模型泛化性在非标准模型上的性能优势
- 更为灵活的部署模式选择,以插件形式支持前端框架的透明性优势
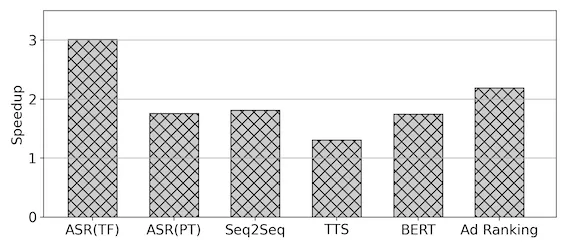
下图为Nvidia T4硬件上几个真实的业务例子的性能收益数字:
在新硬件支持方面,目前普遍的情况是除了积累比较深厚的Nvidia等头部厂商之外,包括ROCM等其它GPGPU硬件普遍存在的情况是硬件的指标已经具备相当的竞争力,但厂商受制于AI软件栈上的积累相对较少,普遍存在硬件算力无法发挥出来导致硬件落地应用困难的问题。如前文所述,基于编译器的技术路径下天然对于硬件的后端具备一定的泛化能力,且与硬件厂商的技术储备形成比较强的互补。BladeDISC目前在GPGPU和通用CPU体系结构上的储备相对比较成熟。以GPGPU为例,在Nvidia GPU上的绝大部分技术栈可以迁移至海光DCU和AMD GPU等体系结构相近的硬件上。BladeDISC较强的硬件泛化能力配合硬件本身较强的通用性,很好的解决了新硬件适配的性能和可用性问题。
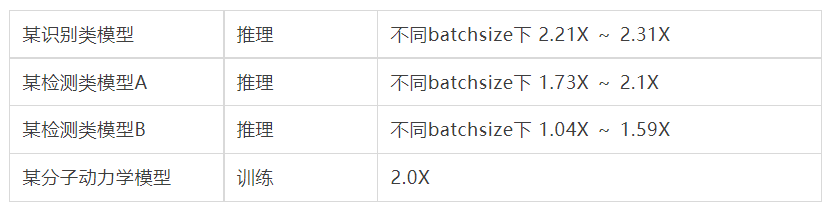
下图为海光DCU上几个真实业务例子上的性能数字:
七 开源生态——构想和未来
我们决定建设开源生态主要有如下的考虑:
- BladeDISC发源于阿里云计算平台团队的业务需求,在开发过程中与MLIR/MHLO/IREE等社区同行之间的讨论和交流给了我们很好的输入和借鉴。在我们自身随着业务需求的迭代逐渐完善的同时,也希望能够开源给社区,在目前整个AI编译器领域实验性项目居多,偏实用性强的产品偏少,且不同技术栈之间的工作相对碎片化的情况下,希望能够将自身的经验和理解也同样回馈给社区,希望和深度学习编译器的开发者和AI System的从业者之间有更多更好的交流和共建,为这个行业贡献我们的技术力量。
- 我们希望能够借助开源的工作,收到更多真实业务场景下的用户反馈,以帮助我们持续完善和迭代,并为后续的工作投入方向提供输入。
后续我们计划以两个月为单位定期发布Release版本。BladeDISC近期的Roadmap如下:
- 持续的鲁棒性及性能改进
- x86后端补齐计算密集型算子的支持,端到端完整开源x86后端的支持
- GPGPU上基于Stitching的大颗粒度自动代码生成
- AMD rocm GPU后端的支持
- PyTorch训练场景的支持
此外,在中长期,我们在下面几个探索性的方向上会持续投入精力,也欢迎各种维度的反馈和改进建议以及技术讨论,同时我们十分欢迎和期待对开源社区建设感兴趣的同行一起参与共建。
- 更多新硬件体系结构的支持和适配,以及新硬件体系结构下软硬件协同方法学的沉淀
- 计算密集型算子自动代码生成和动态shape语义下全局layout优化的探索
- 稀疏子图的优化探索
- 动态shape语义下运行时调度策略、内存/显存优化等方面的探索
- 模型压缩与编译优化联合的技术探索
- 图神经网络等更多AI作业类型的支持和优化等
原文链接
本文为阿里云原创内容,未经允许不得转载。


移动端:让数据在更多业务场景中流通)

发布中心:生产和开发隔离模式下的保护伞)

)



 | 完整小项目看透静态链接过程 | 百篇博客分析HarmonyOS源码 | v54.02...)








