文章目录
- 数据同步ElasticSearch
- 单表基本配置
- 适配器映射文件详细介绍(单表、多表映射介绍)
- 单表映射索引示例sql
- 单表映射索引示例sql带函数或运算操作
- 多表映射(一对一, 多对一)索引示例sql
- 多表映射(一对多)索引示例sql
- 其它类型的sql示例
- 注意事项
本文详细介绍Canal 配置保存 ElasticSearch
Canal从零配置使用参考:https://blog.csdn.net/zhangshenghang/article/details/120361721
数据同步ElasticSearch
我们接着在之前配置Hbase基础上直接修改配置,实现同时同步ElasticSearch
单表基本配置
- 1.修改启动器配置 {canal-apapter}/conf/application.yml
server:port: 8081
logging:level:com.alibaba.otter.canal.client.adapter: DEBUGcom.alibaba.otter.canal.client.adapter.hbase: DEBUG
spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8default-property-inclusion: non_null
canal.conf:# tcp kafka rocketMQ rabbitMQ canal-server运行的模式,TCP模式就是直连客户端,不经过中间件。kafka和mq是消息队列的模式mode: tcp
# flatMessage: truezookeeperHosts: syncBatchSize: 1retries: 0timeout: 1000accessKey:secretKey:consumerProperties:# canal tcp consumer 指定canal-server的地址和端口canal.tcp.server.host: 127.0.0.1:11111canal.tcp.zookeeper.hosts: 127.0.0.1:2181canal.tcp.batch.size: 1canal.tcp.username:canal.tcp.password:srcDataSources: # 数据源配置,从哪里获取数据defaultDS: # 指定一个名字,在ES的配置中会用到,唯一url: jdbc:mysql://127.0.0.1:3306/test2?useUnicode=trueusername: rootpassword: *****canalAdapters:- instance: example # canal instance Name or mq topic name 指定在canal配置的实例名称groups:- groupId: g1 outerAdapters:- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000- name: hbaseproperties:hbase.zookeeper.quorum: sangfor.abdi.node3,sangfor.abdi.node2,sangfor.abdi.node1hbase.zookeeper.property.clientPort: 2181zookeeper.znode.parent: /hbase-unsecure- name: es7 # config目录下的子目录名称hosts: 192.168.168.2:9300 # 127.0.0.1:9200 for rest modeproperties:mode: transport # or rest
# # security.auth: test:123456 # only used for rest modecluster.name: my_application
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address- 2.ElasticSearch 表映射文件
# 指定数据源,这个值和adapter的application.yml文件中配置的srcDataSources值对应。
dataSourceKey: defaultDS
# 指定canal-server中配置的某个实例的名字,不同实例对应不同业务
destination: example
# 组ID ,tcp方式这里填写空,不要填写值,不然可能会接收不到数据
groupId:
# ES的mapping(映射)
esMapping:# ES索引名称_index: testsync2# ES标示文档的唯一标示,通常对应数据表中的主键ID字段_id: _id
# upsert: true
# pk: id
# 数据表每个字段映射到表中的具体名称,不能重复sql: "select a.id as _id, a.name,a.age,a.age_2,a.message,a.insert_time from testsync as a"
# objFields:
# _labels: array:;
# etlCondition: "where a.c_time>={}"commitBatch: 10
- 3 重启服务
bin/restart.sh
写入数据
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
查看adapter日志
2021-09-20 13:53:07.279 [pool-1-thread-1] INFO c.a.o.canal.client.adapter.logger.LoggerAdapterExample - DML: {"data":[{"id":"05fabf89-19d7-11ec-bbe0-708cb6f5eaa6","name":"05fabfb4-19d7-11ec-bbe0-708cb6f5eaa6","age":2,"age_2":null,"message":null,"insert_time":1632117185000}],"database":"test2","destination":"example","es":1632117185000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"testsync","ts":1632117187278,"type":"INSERT"}
2021-09-20 13:53:07.286 [pool-1-thread-1] DEBUG c.a.o.c.client.adapter.hbase.service.HbaseSyncService - DML: {"data":[{"id":"05fabf89-19d7-11ec-bbe0-708cb6f5eaa6","name":"05fabfb4-19d7-11ec-bbe0-708cb6f5eaa6","age":2,"age_2":null,"message":null,"insert_time":1632117185000}],"database":"test2","destination":"example","es":1632117185000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"testsync","ts":1632117187278,"type":"INSERT"}
2021-09-20 13:53:07.287 [pool-1-thread-1] DEBUG c.a.o.canal.client.adapter.es.core.service.ESSyncService - DML: {"data":[{"id":"05fabf89-19d7-11ec-bbe0-708cb6f5eaa6","name":"05fabfb4-19d7-11ec-bbe0-708cb6f5eaa6","age":2,"age_2":null,"message":null,"insert_time":1632117185000}],"database":"test2","destination":"example","es":1632117185000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"testsync","ts":1632117187278,"type":"INSERT"}
Affected indexes: testsync2
查看ElasticSearch数据
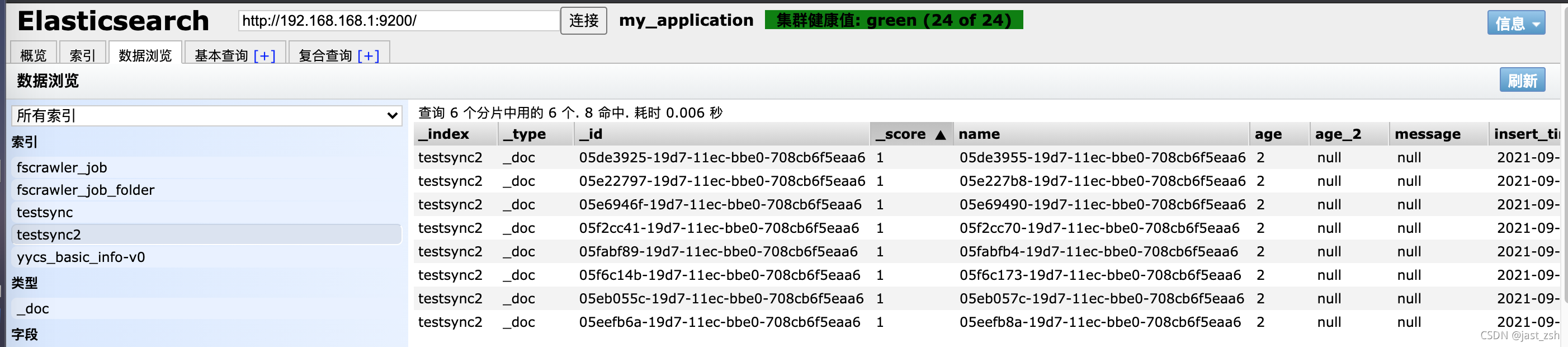
至此写入ElasticSearch、Hbase成功
适配器映射文件详细介绍(单表、多表映射介绍)
${adapter}/conf/es7/xxx.yml
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
outerAdapterKey: exampleKey # 对应application.yml中es配置的key
destination: example # cannal的instance或者MQ的topic
groupId: # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:_index: mytest_user # es 的索引名称_type: _doc # es 的type名称, es7下无需配置此项_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
# pk: id # 如果不需要_id, 则需要指定一个属性为主键属性# sql映射sql: "select a.id as _id, a.name as _name, a.role_id as _role_id, b.role_name as _role_name,a.c_time as _c_time, c.labels as _labels from user aleft join role b on b.id=a.role_idleft join (select user_id, group_concat(label order by id desc separator ';') as labels from labelgroup by user_id) c on c.user_id=a.id"
# objFields:
# _labels: array:; # 数组或者对象属性, array:; 代表以;字段里面是以;分隔的
# _obj: object # json对象etlCondition: "where a.c_time>='{0}'" # etl 的条件参数commitBatch: 3000 # 提交批大小
sql映射说明:
sql支持多表关联自由组合, 但是有一定的限制:
- 主表不能为子查询语句
- 只能使用left outer join即最左表一定要是主表
- 关联从表如果是子查询不能有多张表
- 主sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的不一致, 比如修改了where条件中的字段内容)
- 关联条件只允许主外键的’='操作不能出现其他常量判断比如: on a.role_id=b.id and b.statues=1
- 关联条件必须要有一个字段出现在主查询语句中比如: on a.role_id=b.id 其中的 a.role_id 或者 b.id 必须出现在主select语句中
Elastic Search的mapping 属性与sql的查询值将一一对应(不支持 select *), 比如: select a.id as _id, a.name, a.email as _email from user, 其中name将映射到es mapping的name field, _email将 映射到mapping的_email field, 这里以别名(如果有别名)作为最终的映射字段. 这里的_id可以填写到配置文件的 _id: _id映射.
单表映射索引示例sql
select a.id as _id, a.name, a.role_id, a.c_time from user a
该sql对应的es mapping示例:
{"mytest_user": {"mappings": {"_doc": {"properties": {"name": {"type": "text"},"role_id": {"type": "long"},"c_time": {"type": "date"}}}}}
}
单表映射索引示例sql带函数或运算操作
select a.id as _id, concat(a.name,'_test') as name, a.role_id+10000 as role_id, a.c_time from user a
函数字段后必须跟上别名, 该sql对应的es mapping示例:
{"mytest_user": {"mappings": {"_doc": {"properties": {"name": {"type": "text"},"role_id": {"type": "long"},"c_time": {"type": "date"}}}}}
}
多表映射(一对一, 多对一)索引示例sql
select a.id as _id, a.name, a.role_id, b.role_name, a.c_time from user a
left join role b on b.id = a.role_id
注:这里join操作只能是left outer join, 第一张表必须为主表!!
该sql对应的es mapping示例:
{"mytest_user": {"mappings": {"_doc": {"properties": {"name": {"type": "text"},"role_id": {"type": "long"},"role_name": {"type": "text"},"c_time": {"type": "date"}}}}}
}
多表映射(一对多)索引示例sql
select a.id as _id, a.name, a.role_id, c.labels, a.c_time from user a
left join (select user_id, group_concat(label order by id desc separator ';') as labels from labelgroup by user_id) c on c.user_id=a.id
注:left join 后的子查询只允许一张表, 即子查询中不能再包含子查询或者关联!!
该sql对应的es mapping示例:
{"mytest_user": {"mappings": {"_doc": {"properties": {"name": {"type": "text"},"role_id": {"type": "long"},"c_time": {"type": "date"},"labels": {"type": "text"}}}}}
}
其它类型的sql示例
- geo type
select ... concat(IFNULL(a.latitude, 0), ',', IFNULL(a.longitude, 0)) AS location, ...
- 复合主键
select concat(a.id,'_',b.type) as _id, ... from user a left join role b on b.id=a.role_id
- 数组字段
select a.id as _id, a.name, a.role_id, c.labels, a.c_time from user a
left join (select user_id, group_concat(label order by id desc separator ';') as labels from labelgroup by user_id) c on c.user_id=a.id
配置中使用:
objFields:labels: array:;
- 对象字段
select a.id as _id, a.name, a.role_id, c.labels, a.c_time, a.description from user a
配置中使用:
objFields:description: object
其中a.description字段内容为json字符串
- 父子文档索引
es/customer.yml
......
esMapping:_index: customer_type: _doc_id: idrelations:customer_order:name: customersql: "select t.id, t.name, t.email from customer t"
es/order.yml
esMapping:_index: customer_type: _doc_id: _idrelations:customer_order:name: orderparent: customer_idsql: "select concat('oid_', t.id) as _id,t.customer_id,t.id as order_id,t.serial_code as order_serial,t.c_time as order_timefrom biz_order t"skips:- customer_id
mapping示例:
{"mappings":{"_doc":{"properties":{"id": {"type": "long"},"name": {"type": "text"},"email": {"type": "text"},"order_id": {"type": "long"},"order_serial": {"type": "text"},"order_time": {"type": "date"},"customer_order":{"type":"join","relations":{"customer":"order"}}}}}
}
注意事项
- 多表映射时,主表数据必须插入,如果只插入子表不插入主表,数据无法同步到ElasticSearch;相反只插入主表,子表不进行插入,数据是可以同步到ElasticSearch的
- 多表映射时,如果主表关联id写入后,子表再进行修改之前的关联的id为我们主表写入的id,数据是无法同步到ElasticSearch中的。
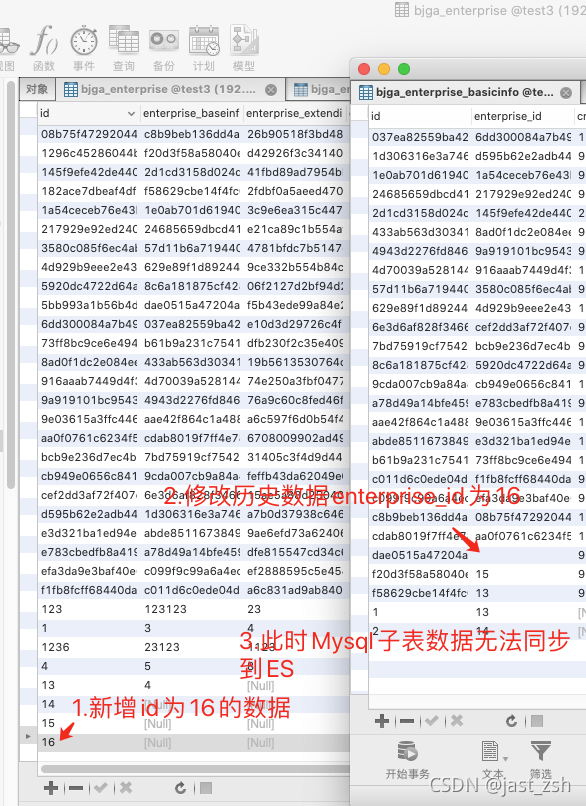


)



)












