文章目录
- 基础
- 语言
- 数据结构与算法
- 工程方面
- 搜索相关
- 搜索主要模块
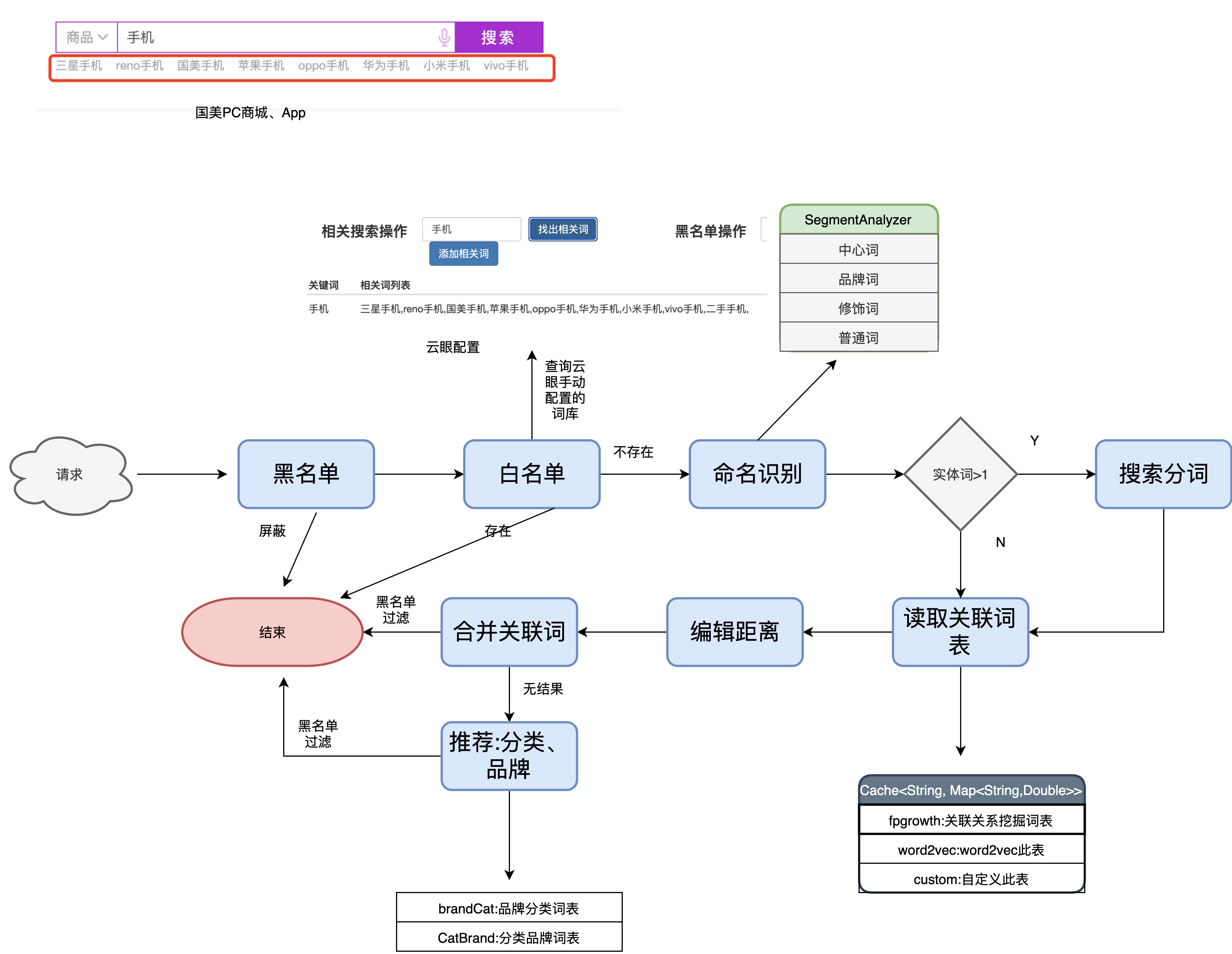
- 电商搜索流程
- 分词相关
- 搜索召回
- 相似度算法
- 相关词推荐
- 排序相关
- 国美搜索
- 搜索算法工程师需要掌握的技能
基础
语言
- 大部分公司用的是Solr、ElasticSearch,都是基于Java实现的,因此熟悉掌握Java语言并灵活使用很重要
- 360公司他们的分词、搜索引擎都是基于C、C++去写,因此C、C++也很重要,但是我工作当中主要用Java,其实我也忘了差不多了
- 其实Python也很重要,Python提供了很多优秀的库可以解决很多应用场景,读写Excel、Word文档如果用Java库去调太麻烦了,还有Python提供了很多机器学习库,当然我是做工程更多这方面很多也不懂
数据结构与算法
- 我觉得所有软件的底层都是数据结构,掌握数据结构尤其重要,例如你用mysql底层用的B+树、用Hbase底层也是B+树、HashMap底层是红黑树、定时任务底层是优先队列、Lucene底层用FST、跳跃表,其实到了汇编指令用栈协助计算等等,这些都离不开数据结构,当然面试肯定也会被问到,去年面国美、京东被问
写二叉树等前序遍历代码、两个链表去重,最近面试Boss直聘、京东到家被问到BitMap、BitSet、链表、FST、跳跃表 - 基础的算法基础也很重要,额,反正面试肯定会被问到,最近面了网易就被问到
如何用DFS构建一个迷宫,再用BFS去解迷宫,Boss直聘被问到LCS原理时间复杂度去年面滴滴问到二分查找,之前去360企业安全实习被问到快速排序
工程方面
- 应用框架:SpringBoot
- RPC框架:Dubbo、Thrift
- 缓存:SSDB、Redis、Guava Cache、EvCache、Caffeine等
- 数据库:Hbase、Mongodb、Mysql
- 搜索相关:Lucene、Solr、ElasticSearch
- 实时计算:Flink
- 监控相关:Cat、Prometheus
- 其他的后续遇到再补充,我现在也还是小白上面的很多还没时间去学
搜索相关
搜索主要模块
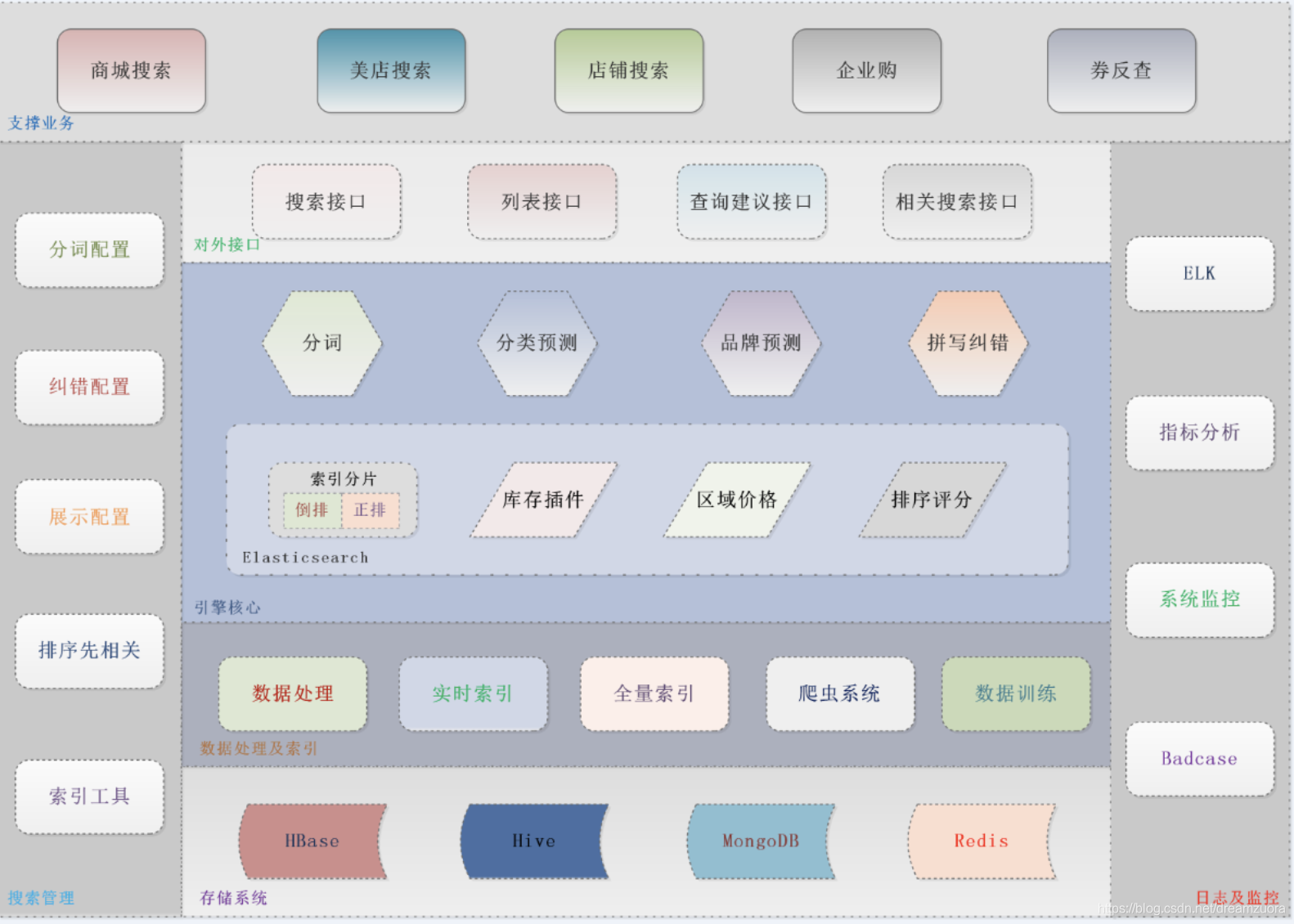
电商搜索流程
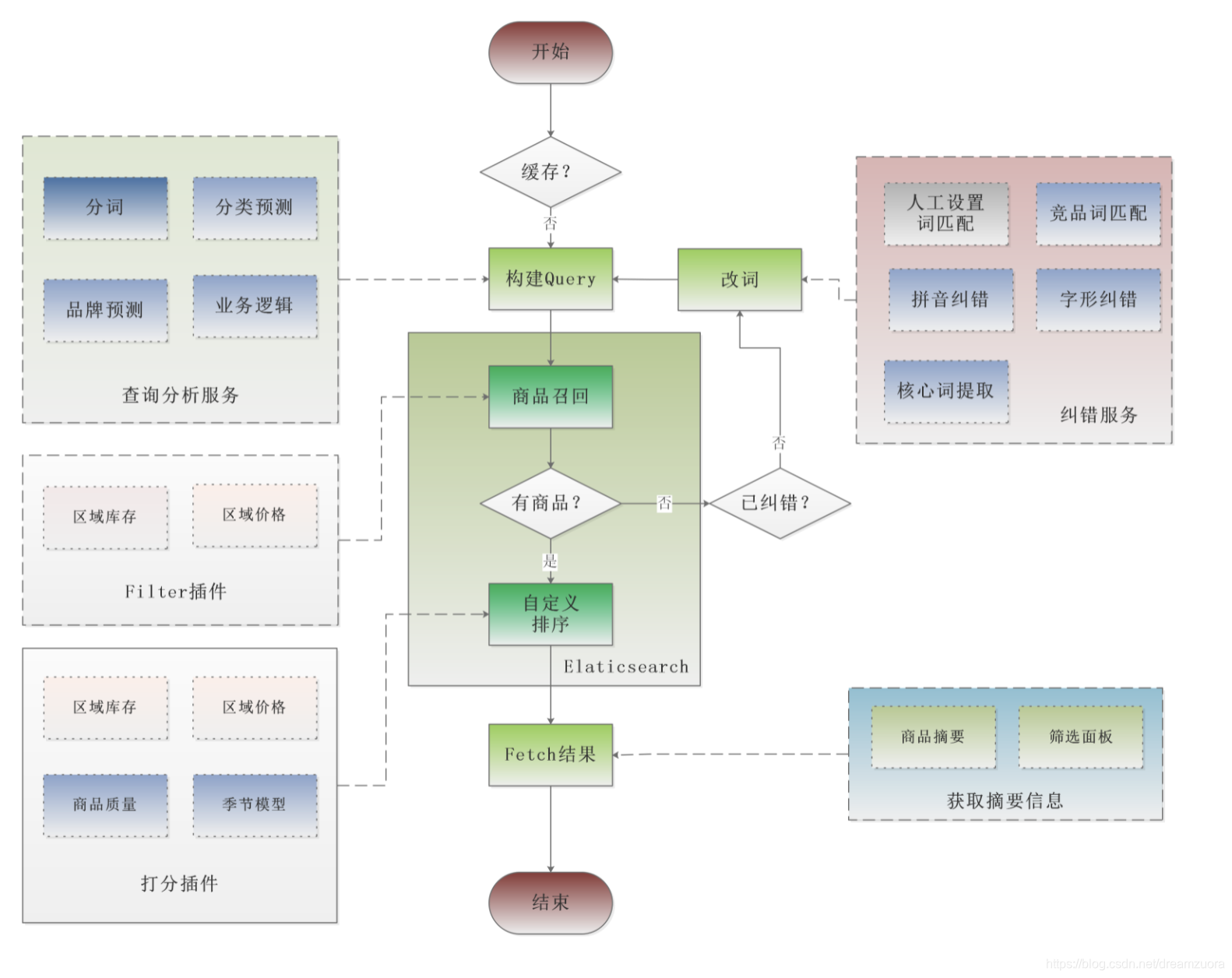
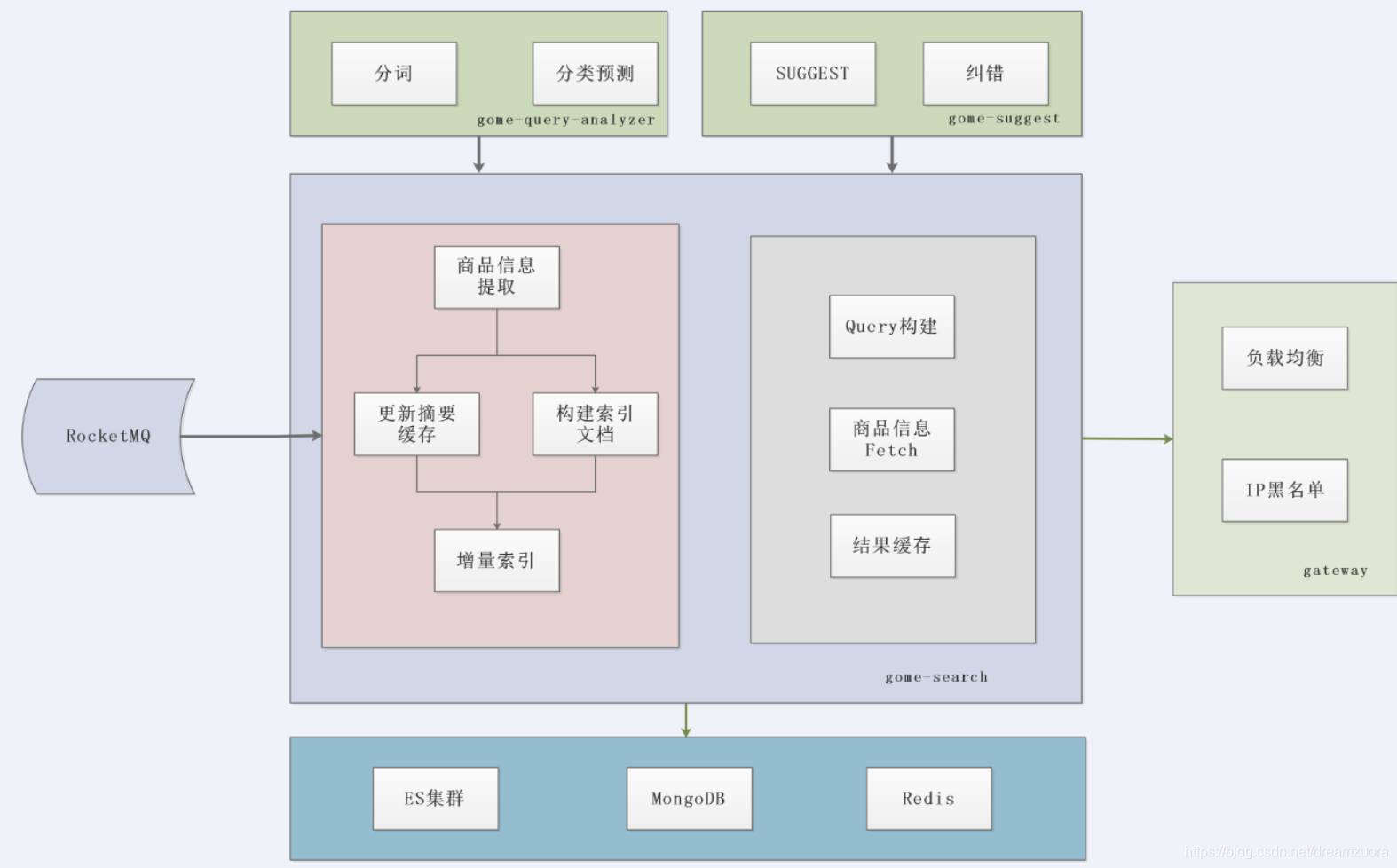
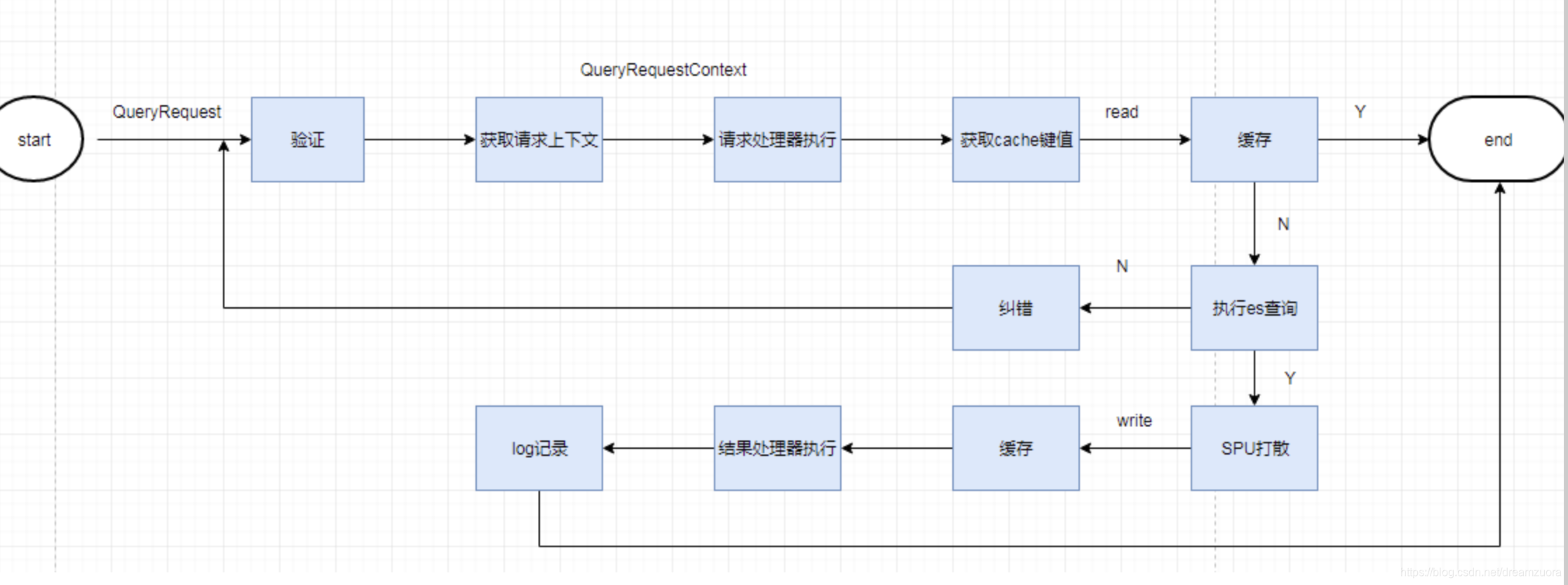
分词相关
- 分词
- 新词发现
- 词权重计算
- 核心词识别
- 同义词
- 紧密度分析
- 意图识别
- 改写
- 纠错
搜索召回
- TFIDF
- BM25
相似度算法
- 欧几里得距离
- 曼哈顿距离
- 余弦相似度
- accard相似度
相关词推荐
Fpgrow:你可以理解为统计词的共现次数,只是fpgrowth统计起来效率更高
word2vec:word2vec是语义层面的相关
排序相关
- Learning To Rank(LTR): pointwise 、 pairwise 、 listwis
国美搜索
1.分词:基于词典和机器学习相结合的,其中机器学习部分用的CFR,条件随机场来做的分词
2.搜索分词用的是最大后向匹配,用最大后向匹配主要是考虑人的正常输入习惯,比如玻璃水杯,要是前向最大切分就是玻璃水 杯,后向就是玻璃 水杯
索引分词:
全切分:最小正向切分又叫全切分
分类预测:fasttext + 分词命名实体识别 + 型号词库结合的
精排:
pointwise:就是看成ctr(点击率预估)来给出每个商品点击的概率值,按照概率值的大小对候选的商品排序
pairwise 更关注同一搜索词下面不同商品的是否和搜索词相关,样本构造起来比pointwise麻烦
召回:bm25
关键词提取:tfidf、textrank
意图识别:
对query做分类预测,预测商品所在分类
搜索算法工程师需要掌握的技能
以下内容摘选自知乎
说说我对搜索算法工程师能力要求的理解。这个能力要求,与求职者应聘面试时的能力要求可能不一样。毕竟,“面试造火箭,入职拧螺丝”是很常见的。
搜索算法的掌握,分两个方面,一个是掌握的深度,另一个是掌握的范围。
深度可以分几个等级:
- 只知道名字,或完全没听过;
- 大概知道原理并未使用过;或调包使用过,但具体原理不太清楚,没做过优化;
- 在实际项目中,深度使用过,有丰富的调优经验;对算法理论有充分的理解,可以推导公式等。
搜索算法的范围其实非常广。在整个搜索系统中,与算法最强相关的,我理解是查询理解/query分析和排序。 - 查询理解
主要是NLU相关的技术,包括:分词、新词发现、词权重计算、核心词识别、改写、同义词、紧密度分析、意图识别、纠错等。这里面多数都依赖机器学习算法,也有少量是依赖词典、规则。 - 召回
从倒排索引中,召回相关的网页。包括相关性计算,在相关性基础上的粗排序。 相关性计算,至少知道tf-idf,bm25及各种变种等,知道每种算法的优劣。 - 排序
使用机器学习模型对召回结果做精细化的排序,Learning To Rank(LTR)。这是搜索系统中最关键的算法,几乎决定了最终的排序效果。常见的算法包括LambdaMart, RankNet, LambdaRank等,至少知道PointWise, PairWise, ListWise等几种算法的分类。深入使用过其中某几个算法。
在排序中,还涉及语义匹配和点击调权等算法,使用过DSSM, DBN等常规的算法。
除了上述3个,其它的像倒排索引构建、网页搜索中的爬虫、网页分析、摘要计算等,也会涉及一些算法。
我个人感受,搜索算法工程师是对经验要求特别高的一个岗位。不太像有些搞机器学习的岗位,知道几个机器学习模型,一直在调优这几个模型来改善效果就行。搜索的效果是由非常多的因素共同影响决定的,整个系统比较庞大。
从普通的搜索算法工程师角度,一般不太可能对上述所有算法都非常熟悉,所以如果能对某一两个模块的算法非常熟悉,或者说经验很丰富,个人觉得已经不错了。如果是对这些都很熟悉,那就是算法的总负责人之类的了。



















