主成分分析法 (Principal Component Analysis, PCA) 是一种数据压缩法,可以从数据中提取重要的部分并排除不重要的部分,是奇异值分解 (Singular Value Decomposition, SVD) 的重要应用。
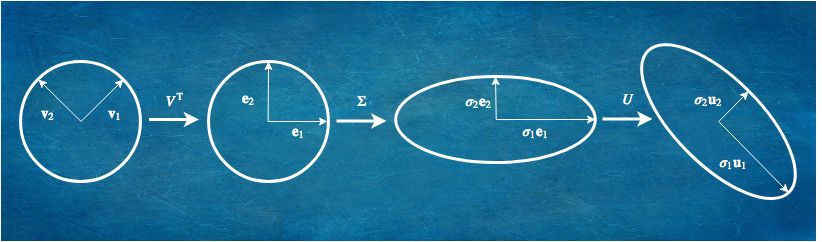
SVD 是线性代数的一个亮点。

SVD 不但找出正交基,还把
SVD 是
现在我们要把数据带到实数空间,所以只能有数字,不能有分类数据。(其实我觉得不应该叫“数据”,因为“分类数据”根本就没有数字。)表格中,一行代表一条记录,一列代表一个特征。
表格里行比列多,每一列都减掉平均值,转换成矩阵,
重要的是右奇异向量,
用 python 来实践一下吧,用 iris 数据,中心化,做 svd() ,奇异值除以
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from itertools import combinations# 准备数据
iris = datasets.load_iris()# 四维数据分六个二维图表显示
fig, axes = plt.subplots(2, 3)
axes = axes.ravel()
for i, (x, y) in enumerate(combinations(range(4), 2)):axes[i].scatter(iris.data[:50, x], iris.data[:50, y],label=iris.target_names[0])axes[i].scatter(iris.data[50:100, x], iris.data[50:100, y],label=iris.target_names[1])axes[i].scatter(iris.data[100:, x], iris.data[100:, y],label=iris.target_names[2])axes[i].legend()axes[i].set_xlabel(iris.feature_names[x])axes[i].set_ylabel(iris.feature_names[y])
plt.show()# 做 SVD
A = iris.data - iris.data.mean(axis=0)
U, S, VT = np.linalg.svd(A, full_matrices=False)
S /= np.sqrt(A.shape[1] - 1)
print('如果从四维降到二维,会保留总方差的 {:.2%}。'.format((S**2)[:2].sum() / (S**2).sum()))# 从四维降到二维后图表显示
A_t = (A @ VT.T)[:, :2]
plt.scatter(A_t[:50, 0], A_t[:50, 1], label=iris.target_names[0])
plt.scatter(A_t[50:100, 0], A_t[50:100, 1], label=iris.target_names[1])
plt.scatter(A_t[100:, 0], A_t[100:, 1], label=iris.target_names[2])
plt.legend()
plt.xlabel(r'$vec v_1$')
plt.ylabel(r'$vec v_2$')
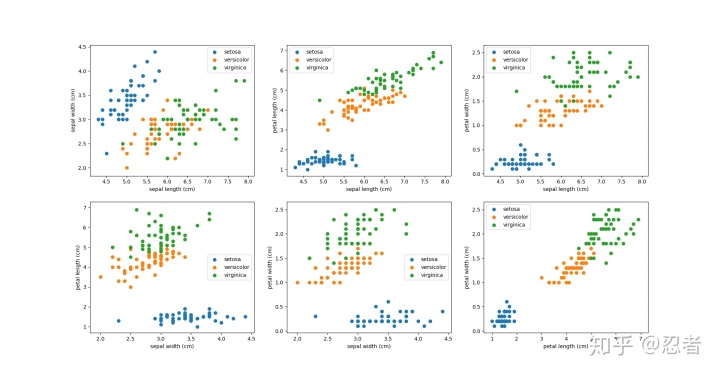
plt.show()四维数据,需要用六个二维图表来看,但这些都是截面,仍然不能想象四维空间里的样子。
从四维降到二维后,保留 97.77% 的信息。
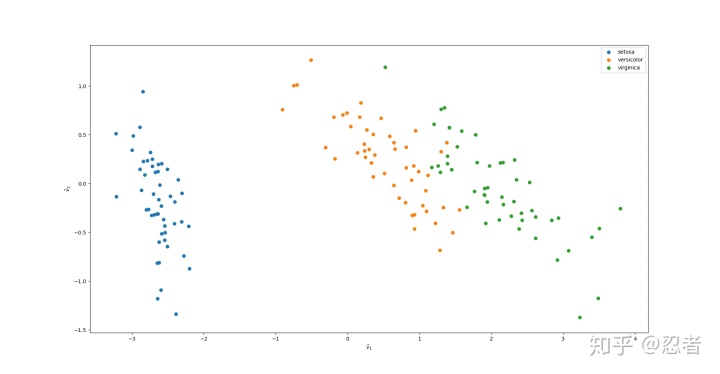
PCA 的功能就是压缩数据,同时保留最重要的信息。在数据分析的领域里,我们可以用它来降维。高维不仅对我们的想象力造成劳损,对建模也是一种诅咒,在这里主成分分析法是一个很有用的降维技巧。



















