作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
Redis的简单介绍
- **作者前言**
- 安装Redis
- Readis的优点
- 安装Redis
- 配置redis
- Reids分区
- Redis数据类型
- Redis操作
- 其他操作
- Python中的Redis操作
安装Redis
Readis的优点
- Reids是非关系型数据的代表,里面储存的数据类型十分多样
- Reids是内存型数据,读写快速
- 应用十分广泛
安装Redis
# 添加EPEL仓库,更新yum源
sudo yum install epel-release
sudo yum update
# 安装Redis数据库
sudo yum -y install redis
# 启动Redis服务
sudo systemctl start redis
# 进入Redis命令行模式操作
redis-cli
# 退出redis
exit
配置redis
# 进入到配置文件
sudo vim /etc/redis.conf
# 一般而言,配置文件会在这个路径下
# 允许被远程连接,注释掉这一行
# bind 127.0.0.1
# 为redis设置密码,取消注释
requirepass foobared
# foobared为密码,可以自己更改
# 保存后重启
sudo systemctl restart redis
# 因为设置了密码,所以有任何操作出现了
(error) NOAUTH Authentication required
# 可以先输入密码,1223456是具体的密码
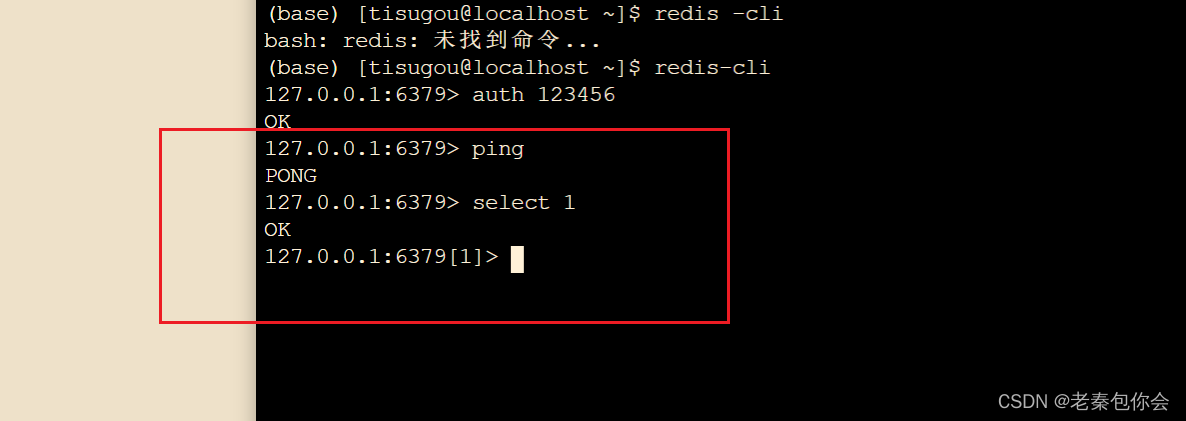
auth 123456
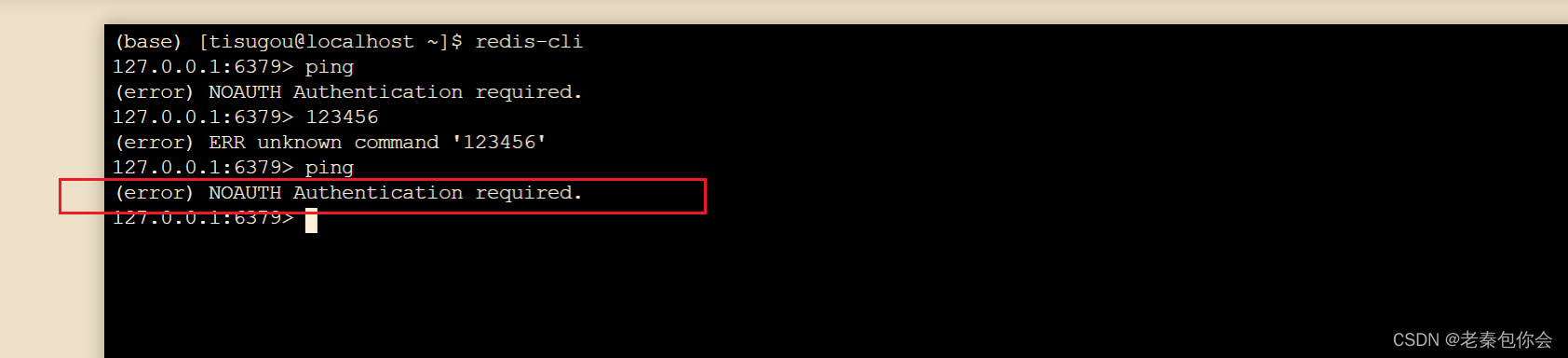
注意一下,进入到redis命令模式后我们要输入auth 123456 后面的操作就不用再输入密码了
判断redis是否正常运行,我们输入ping来看看
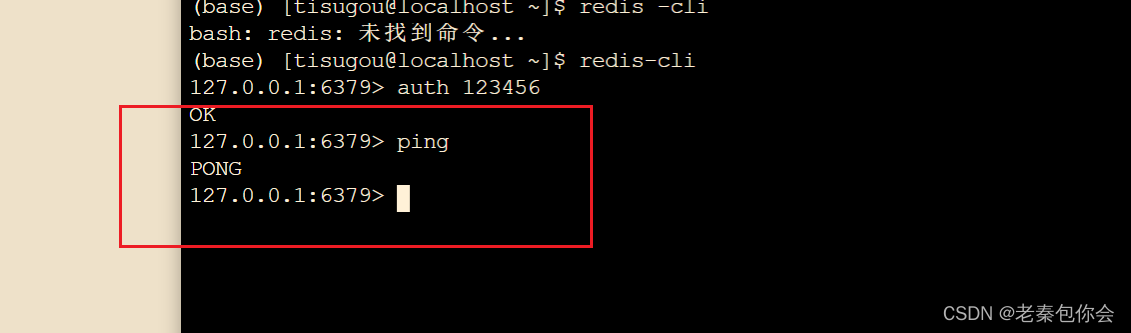
如果回复pong就是运行成功了
Reids分区
如同是MySQL里分库一样,对不同的数据进行分区操作,有利于提高数据库的效率。通过利用多台计算机内存的和值,允许我们构造更大的数据库
# 选择redis的分区
select index
# index是分区的编号,只能是数字,默认从0开始,一般最大编号是255
Redis数据类型

有string(字符串)、 hash(哈希)、 set(集合)、list(链表)、sorted set,
图中的写法是让我们可以理解大概是啥类型
啥是链表
链表包含列表
列表形式(通过索引访问元素)
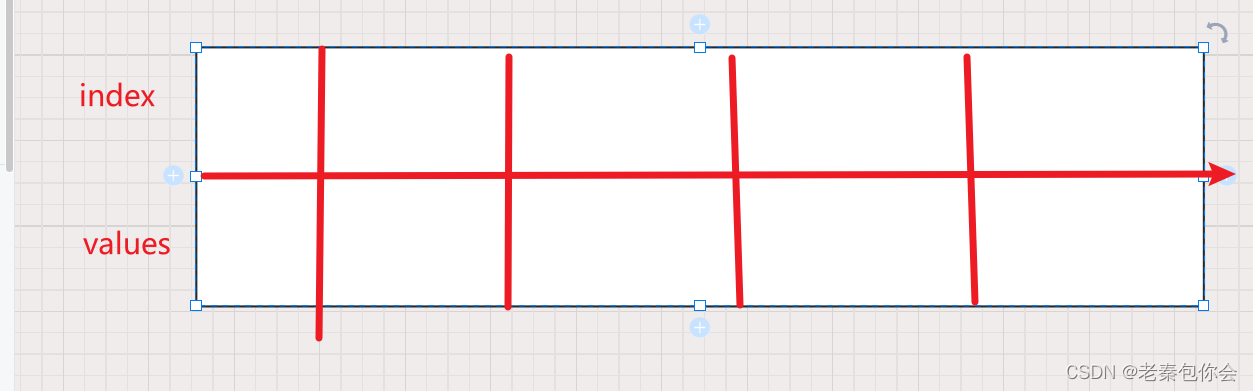
方向是从左往右,而链表是从左往右和从右往左的
Redis操作
string(字符串)
redis中,所有的数据形式都是由键值对组成的,即为 {key: value} ,其中说的数据类型,都是针对值而言
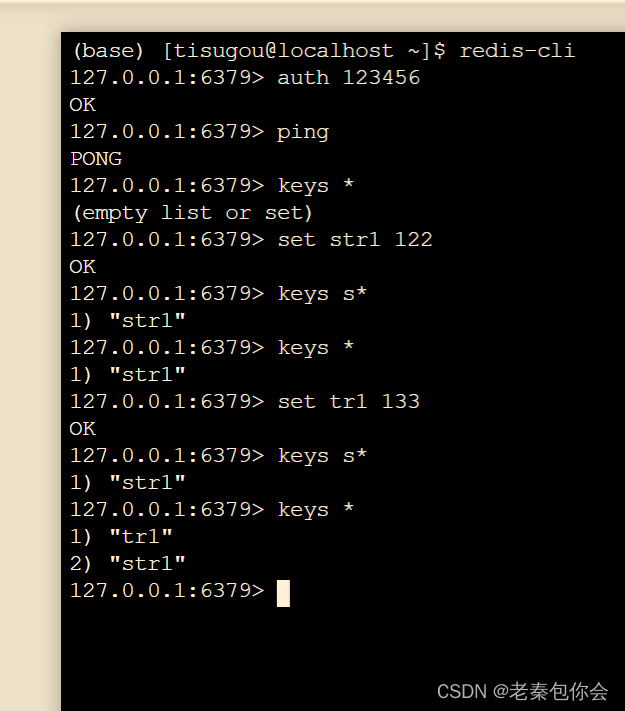
# 获取所有的键,星号* 表示任意匹配
keys *
keys 1*
# 设置值
set key value

# 获取指定的值
get key

# 将给定key的值设为value,并返回key原来的值
getset key value

# 获取一个或多个给定key的值,键之间以空格隔开
mget key1 key2

# 设置值,并将key的过期时间设为n(以秒为单位)
setex key n value

当这个key超过这个时间,就会不存在,为啥会这样呢 ?
原因是redis的全称为内存型数据库,数据本身是保存在硬盘里面的,当启动redis 就会把所有数据写到内存里面去,结束就会保存到硬盘里面
# 当key不存在时,设置值
setnx key value

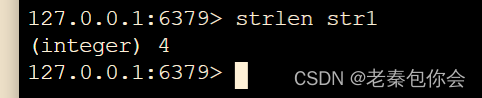
# 返回key所储存的字符串长度
strlen key
# 同时设置一个或多个键值对
mset key1 value1 key2 value2
# 同时设置一个或多个键值对,当且仅当所有给定key都不存在
msetnx key1 value1 key2 value2
需要注意的是使用msetnx要保证所有的可以的key不存在
hash(哈希)
哈希里面包含字典
字典保存的形式是{key : value}
# 将哈希key中的字段field设为value
hset key field value

# 获取存储在哈希中指定字段的值
hget key field

查看h_num1 中的field字段的值,我们可以理解为h_num1={“field”: “100”}
# 获取在哈希中指定key的所有字段和值
hgetall key

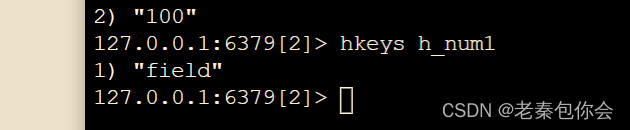
# 获取所有哈希表中的字段
hkeys key
# 查看哈希key中指定的字段是否存在
hexists key field

存在返回1,不存在返回0
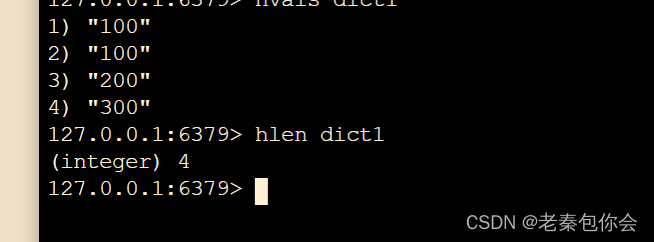
# 取哈希中所有值
hvals key

注意一下key和filed是不一样的,key是哈希的名称,filed是哈希里面的字段名
# 删除一个或多个哈希字段
hdel key field1 field2

# 获取哈希中字段的数量
hlen key
# 获取哈希中字段的数量
hlen key
# 获取所有给定字段的值
hmget key field1 field2
# 只有在字段field不存在时,设置哈希字段的值。
hsetnx key field value
list(链表)
在python中,列表的头部: 列名[0] 尾部:列名[-1] ,而链表是没有头部和尾部 的,两边操作都是可以的,为了更好的区分,会认为链表有头部和尾部
# 将一个或多个值写到列表头部
lpush key value1 value2

需要注意的是这里写入不是和python列表一样的写入,而是推入 比如我们要写入1 2 3
而结果是3 2 1 ,当1写入到第一个位置,2再写入就会把1 推到第二个位置,2占据第一,依次往复,下面的rpush命令也是一样的,还有注意的是如果内存满了,再写入数据就会报错
# 通过索引设置列表元素的值
lset key index value

可以修改和添加
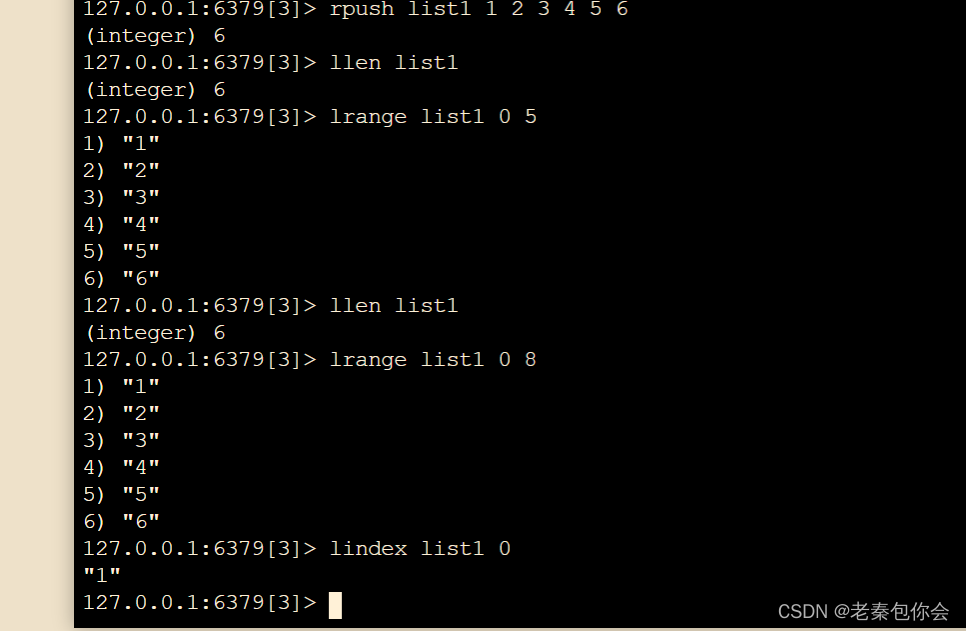
# 在列表尾部中添加一个或多个值
rpush key value1 value2

# 获取列表长度
llen key
# 通过索引获取列表中的元素
lindex key index
# 获取列表指定范围内的元素,从start到end
lrange key start end
# 在列表的元素前或者后插入元素,pivot为目标值,value为需要插入的值
linsert key before|after pivot value
pivot是值,不是索引
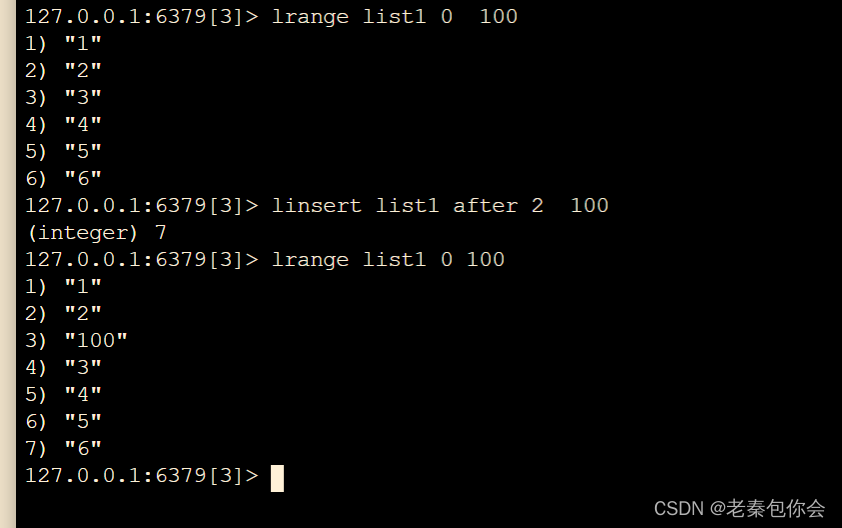
# 移出并获取列表的第一个元素
lpop key
# 移除并获取列表的最后一个元素
rpop key
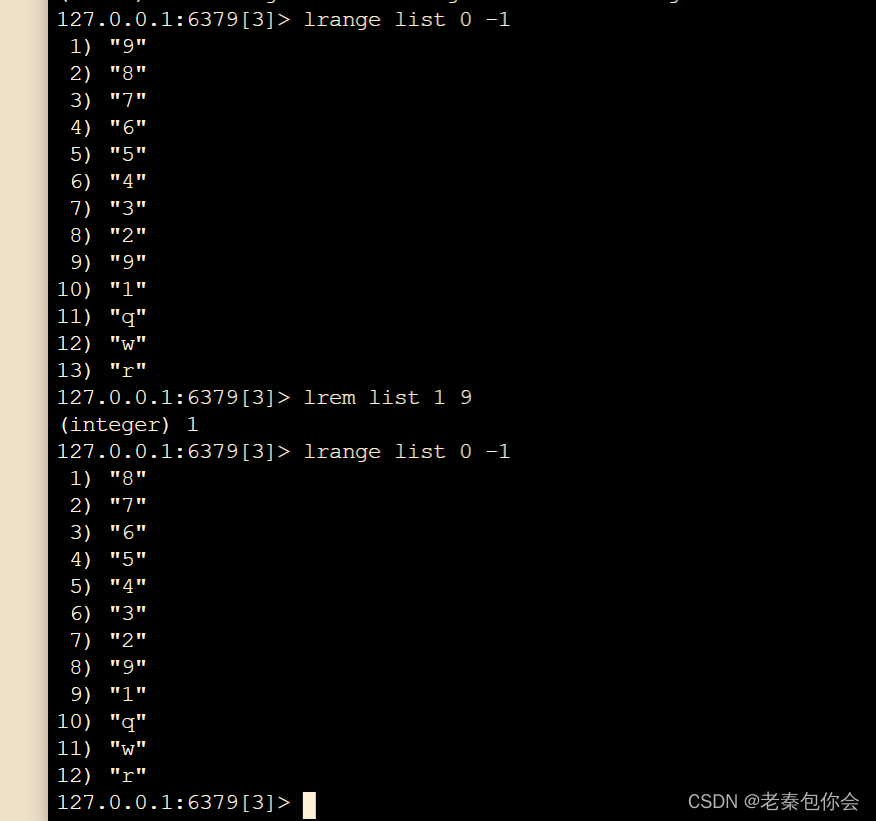
# 移除列表元素,count是数量
lrem key count value
跟python的pop()方法很像,而第三条语句是根据for循环,把找到的第一数删除掉
set(集合)
Redis的集合是 string 类型的无序集合,成员是唯一的,不能出现重复数据
# 查看集合
smembers key

需要注意的是集合是无序的,
# 向集合添加一个或多个成员
sadd key value1 value2

需要注意的是如果里面有相同的元素就不会添加
# 获取集合的成员数
scard key

我们理解为长度也可以
# 返回给定所有集合的交集
sinter key1 key2

# 判断value素是否是集合key的元素
sismember key value

存在返回1,不存在返回0
# 移除集合中一个或多个成员
srem key value1 value2
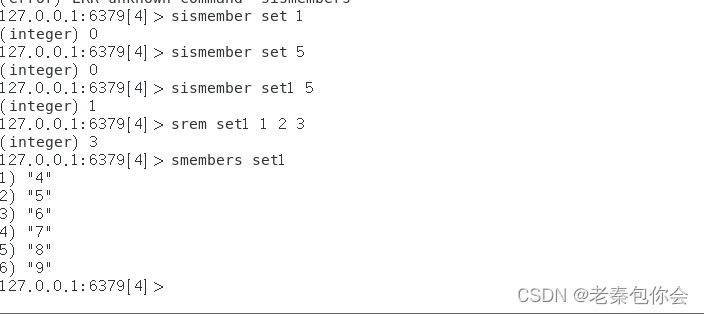
返回所有给定集合的并集
sunion key1 key2

跟mysql数据库的外连接很像
zset(sorted set:有序集合)
Redis有序集合也是string 类型的集合,不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis 是通过分数来为集合中的成员进行从小到大的排序。
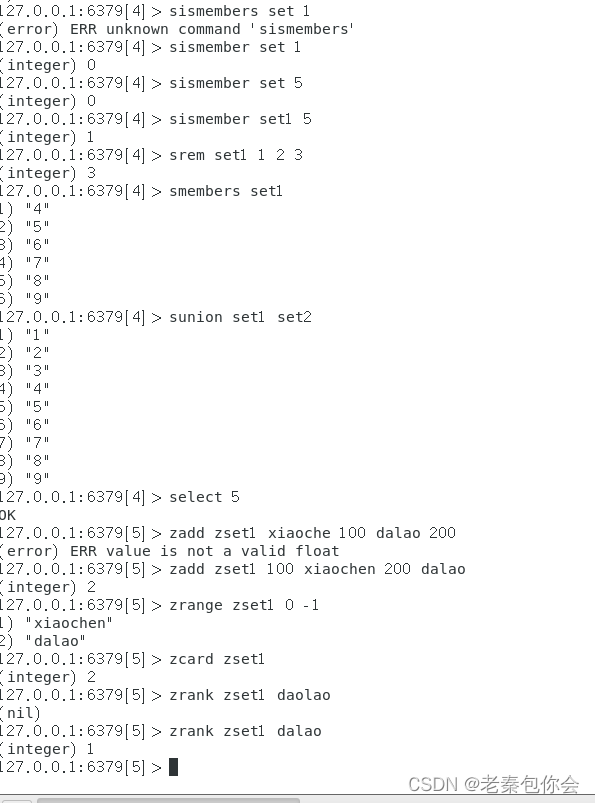
# 向有序集合添加一个或多个成员,或者更新已存在成员的分数
zadd key value1 member1 value2 member2

这样要注意一下,这里的先写值,再写字段,字段是唯一的,值可以相同,但是有序集合里面存储的是字段,不存储值,我们可以理解字段相当于变量,变量里面有值
# 获取有序集合的成员数
zcard key
# 查看有序集合中所有的成员
zrange key 0 -1
# 返回有序集合中指定成员的索引
zrank key member
# 移除有序集合中的一个或多个成员
zrem key member1 member2
需要注意的是,这里value都是字段,不是字段里面的值
其他操作
# 删除当前库中的所有key
flushdb
# 删除数据库中的所有key
flushall
# 查看key的类型
type key

Python中的Redis操作
连接Redis
import redis
# db是分区
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True,
db=0)
r = redis.Redis(connection_pool=pool)
string
# 设置值,ex表示过期时间,可以不设置
r.set('key', 'value', ex=3)
# 获取值
r.get('key')
# 当key不存在时,设置值
r.setnx('key', 'value')
# 批量设置值
r.mget({'key1': 'value1', 'key2': 'value2'})
# 这时的键key1、key2不能有引号
r.mset(key1="value1", key2="value2")
# 批量获取值
r.mget("key1", "key2")
r.mget(['key1', 'key2'])
# 设置新值并获取原来的值
r.getset("key1", "value1")
# 返回key对应值的字节长度(一个汉字3个字节)
r.strlen("key")
hash
# 单个增加或修改,存在就修改,没有就新增
r.hset("hash1", "key1", "value1")
# 取hash1中所有的key
r.hkeys("hash1")
# 单个取hash1的key1对应的值
r.hget("hash1", "key1")
# 取hash1的多个key对应的值
r.hmget("hash1", "key1", "key2")
# 只能新建
r.hsetnx("hash2", "key2", "value2")
# 批量设置
r.hmset("hash1", {"key1": "value1", "key2": "value2"})
# 取出所有的键值对
r.hgetall("hash1")
# 得到所有键值对的hash长度
r.hlen("hash1")
# 得到所有的keys
r.hkeys("hash1")
# 得到所有的value
r.hvals("hash1")
# 判断存在
r.hexists("hash1", "key1")
# 删除键值对
r.hdel("hash1", "key1")
list
# 从左边开始增加值,没有就新建
r.lpush("list1", 11, 22, 33)
# 从右边新增
r.rpush("list1", 11, 22, 33)
# 切片取出值,范围是索引号0到-1(最后一个元素)
r.lrange("list1", 0, -1)
# 向已有的列表左边添加元素,没有的话无法创建
r.lpushx("list2", 10)
r.lpushx("list1", 77)
# 向已有的列表左边添加元素,没有的话无法创建
r.rpushx("list2", 10)
r.rpushx("list1", 77)
# 指定索引号进行修改
r.lset("list1", 2, 'lalala')
# 指定值进行删除
# 将列表中左边第一次出现的"11"删除
r.lrem("list1", "11", 1)
# 删除并返回
# 删除并返回列表最左边的元素
r.lpop("list1")
# 删除并返回列表最右边的元素
r.rpop("list1")
# 根据索引取值
# 取出索引是1的值
r.lindex("list1", 1)
set
# 新增
r.sadd("set1", 1, 2, 3, 4)
# 获取元素个数
r.scard("set1")
# 获取集合中所有的值
r.smembers("set1")
# 交集
r.sinter("set1", "set2")
# 获取多个对应的集合的并集
r.sunion("set1", "set2")
# 判断是否是集合的成员
r.sismember("set1", 33)
# 指定值删除
r.srem("set1", 1)
zset
# 新增
r.zadd("zset1", value1=1, value2=2)
r.zadd("zset1", 'value3', 3, 'value4', 4)
# 获取有序集合的长度
r.zcard("zset1")
# 获取有序集合中所有元素
r.zrange("zset1", 0, -1)
# 获取有序集合中所有元素和分数
r.zrange("zset1", 0, -1, withscores=True)
# 获取值的索引号
r.zrank("zset1", "value1")
# 指定值删除
# 删除有序集合中的元素value1
r.zrem("zset1", "value1")
# 获取值对应的分数
r.zscore("zset1", "value2")
# 删除redis中的任意数据类型(string、hash、list、set、有序set)
# 删除key为gender的键值对
r.delete("gender")
# 检查名字是否存在
r.exists("zset1")
# 获取类型
r.type("set1")
r.type("hash1")
# 查询所有的Key
r.keys()
# 当前redis包含多少条数据
r.dbsize()
在python里的方法和在redis里面是一样的,没有差别