来源:专知
摘要:”当研究问题或数据集包括多个这样的模态时,其特征在于多模态。
【导读】人工智能领域最顶级国际期刊IEEE Transactions on Pattern Analysis and Machine Intelligence(IEEE TPAMI,影响因子为 9.455),2019年1月最新一期发表了关于多模态机器学习综述论文。我们周围的世界涉及多种形式 - 我们看到物体,听到声音,感觉质地,闻到异味等等。 一般而言,模态指的是事物发生或经历的方式。 大多数人将形态与感觉方式联系起来,这些感觉方式代表了我们主要的交流和感觉渠道,例如视觉或触觉。 因此,当研究问题或数据集包括多个这样的模态时,其特征在于多模态。 本文主要关注但不仅仅关注三种形式:自然语言既可以是书面的,也可以是口头的; 视觉信号,通常用图像或视频表示; 和声音信号,编码声音和口头信息,如韵律和声音表达。

我们对世界的体验是多模式的 - 我们看到物体,听到声音,感觉质地,闻到异味和味道。情态是指某种事物发生或经历的方式,并且当研究问题包括多种这样的形式时,研究问题被描述为多模式。为了使人工智能在理解我们周围的世界方面取得进展,它需要能够将这种多模态信号一起解释。多模式机器学习旨在构建可以处理和关联来自多种模态的信息的模型。这是一个充满活力的多学科领域,具有越来越重要的意义和非凡的潜力。本文不是关注特定的多模态应用,而是研究多模态机器学习本身的最新进展。我们超越了典型的早期和晚期融合分类,并确定了多模式机器学习所面临的更广泛的挑战,即:表示,翻译,对齐,融合和共同学习。这种新的分类法将使研究人员能够更好地了解该领域的状况,并确定未来研究的方向。
论文地址:
http://www.zhuanzhi.ai/paper/2236c08ef0cd1bc87cae0f14cfbb9915
https://ieeexplore.ieee.org/document/8269806

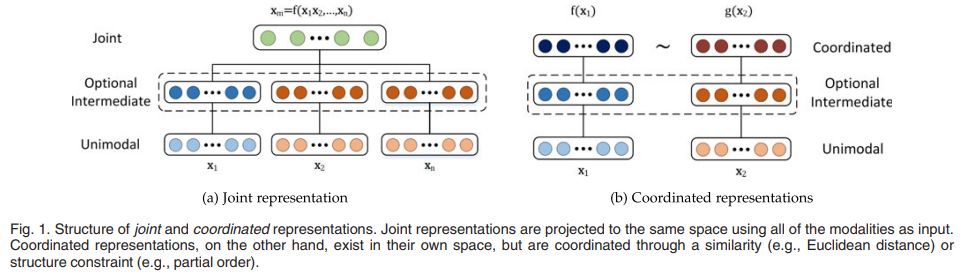
模态特征表示
多模态的表示方法有两类:
联合表示将不同模态的特征映射到同一个空间,代表方法有神经网络的方法、图模型方法与序列模型方法。
协调方法特征仍在原空间,但是通过相似度或者结构特征协调。
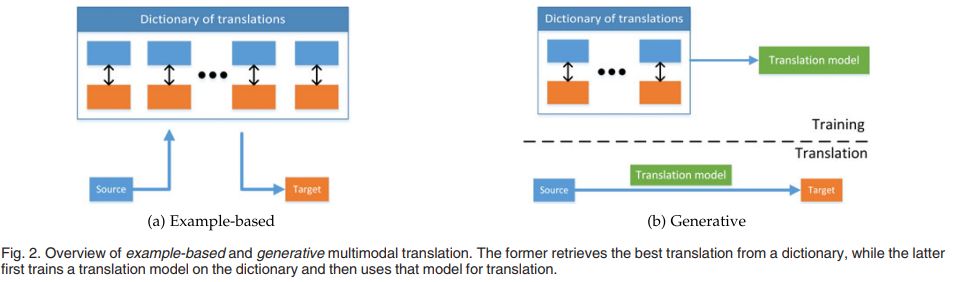
多模态特征翻译
多模态特征翻译分为基于样本的和生成式的:
基于样本的方法从特征字典中找出最佳翻译。基于样本的方法分为基于检索式的和合并的方法。
生成式的方法则是通过样本,训练一个翻译模型,并使用翻译模型完成对特征的转换。生成式的方法有基于语法的、encoder-decoder模型和连续模型。
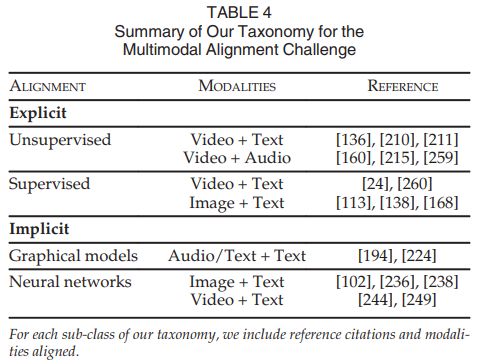
多模态特征对齐
多模态特征对齐是找到同一个实例的不同之间模态特征之间的关系。
显式对齐方法包括监督模型和无监督模型。无监督模型如CCA和DTW(Dynamic time warping)等。
隐式对齐的方法包括图模型和神经网络
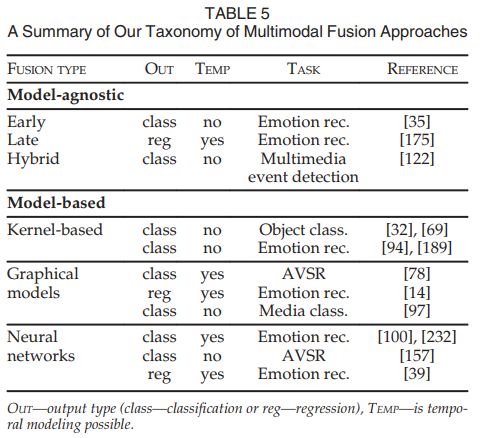
多模态特征融合
多模态特征融合是指将从不同模态的特征集成在一起,共同完成一个任务,如分类。
无模型融合的方法被分为早期模型(基于特征)、晚期模型(基于决策)和混合模型
有模型融合的方法有核方法、图模型方法、神经网络模型方法等。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”





方法能够获取的值)


)








)


