
来源:凹非寺
人工神经网络可以从动物大脑中学到什么?
最新一期Nature子刊上,就刊登了这样一篇文章。美国冷泉港实验室的神经科学家Anthony M. Zador,对当下人工神经网络的研究思路进行了深刻反思与批判:
大多数动物行为不是通过监督或者无监督算法就能模拟的。
具体来说,动物天生具备高度结构化的大脑连接,使它们能够快速学习。从出生下时的神经结构就决定了动物具有哪些技能,再通过后天学习变得更加强大。
由于连接过于复杂无法在基因组中明确指定,因此必须通过“基因瓶颈”进行压缩。但人工神经网络还不具备这种能力。
但这也表明,AI有潜力通过类似的方式快速学习。
也就是说,通过反思当前的研究方式能够发现,我们现在关于深度学习的研究从出发点的侧重似乎就搞错了,先天架构比后天训练重要得多。
这个结论一出现,就在推特上引发了巨大的反响,不到一天,点赞数超过了1.8K,各大论坛上也少不了各种讨论。不少网友表示,文章让人有一种醍醐灌顶的感觉。
一研究者表示,很喜欢这篇文章,尤其是其中具体说明了进化与学习之间的生物学差异,以及在深度学习中能借鉴的思路见解。
机器学习研究者、fixr.com网站的CEO Andres Torrubia表示,这个研究不禁让人想到权重无关的人工神经网络,接下来的重点是如何在“遗传瓶颈”中进行编码了。
还有研究人员提出了新思路,猜测基因瓶颈与今年ICLR 2019的最佳论文“彩票假设”理论中得到的简化表示之间有相似之处。
是项怎样的研究,让AIer的思路一下子如此开阔?

先天的重要性
机器能在多长时间内取代人类的工作?1956年,AI先驱Herbert Simon曾预言,机器能够在二十年内完成人类可以做的任何工作。
虽然这个预测离AI的发展轨道偏离了太远,但那时已经有了类似通用人工智能(AGI)的概念。
今天的科技界这种乐观情绪再次高涨,主要源于人工神经网络和机器学习的进展,但离设想的达到人类智慧的水平还很远。
人工神经网络可以在国际象棋和围棋等游戏中击败人类对手,但在大多数方面,比如语言、推理、常识等,还无法接近四岁儿童的认知能力。
也许更引人注目的是人工神经网络更接近于接近简单动物的能力。用人工智能的先驱之一Hans Moravec的话说:
人脑中高度发达的感知与运动部分的编码,是从生物界十亿年的进化经验中学到的。我们称之为“推理”的深思熟虑的过程,是人类思维能力中最薄弱的一个,因为依靠无意识的感知运动的支持才能生效。
与人工智能网络相比,动物严重依赖于后天学习与先天机制的融合。这些先天机制通过进化产生,在基因组中完成了编码,并采取一定规则连接大脑。
所以,基因瓶颈(genomic bottleneck)了解一下?
在这篇文章中,研究人员引入了这个概念,具体来说,是指压缩到基因组中的任何先天行为都是进化过程带来的,这是连接到大脑规则的一种约束。
而下一代机器学习的算法的突破点,很有可能就在基因瓶颈上。
而这,也是当前机器学习算法与人类思维方式最大差别。
算力促进神经网络发展
在AI的早期阶段,有符号主义和连接主义两种主义之争。
Marvin Minsky等人支持的符号主义认为,应该由程序员来编写AI系统运行的算法。而连接主义认为,在人工神经网络方法中,系统可以从数据中学习。
符号主义可以视为心理学家的方法,它从人类认知处理中获取灵感,而不是像连接主义那样试图打开黑匣子,使用神经元组成的人工神经网络,从神经科学中获取灵感。
符号主义是是20世纪60~80年代人工智能的主导方法,但从之后被连接主义的的人工神经网络方法所取代。
但是现代人工神经网络与三十年前的仍然十分相似。神经网络大部分进步可以归因于计算机算力的增加。
仅仅因为摩尔定律,今天的计算机速度比当年快了几个数量级,并且GPU加快了人工神经网络的速度。
大数据集的可用性是神经网络快速发展的第二个原因:收集用于训练的大量标记图像数据集,在谷歌出现之前是非常困难的。
最后,第三个原因是现代人工神经网络比之前只需要更少的人为干预。现代人工神经网络,特别是“深度网络” 可以从数据中学习适当的低级表示(例如视觉特征),而不是依靠手工编程。

在神经网络的研究中,术语“学习”的意义与神经科学和心理学不同。在人工神经网络中,学习是指从输入数据中提取结构统计规律的过程,并将该结构编码为网络参数。这些网络参数包含指定网络所需的所有信息。
例如,一个完全连接的由N个神经元组成的网络,每个神经元都有一个相关联的参数,以及另外N2个参数来指定神经元突触的连接强度,总共有N+N2个自由参数。当神经元的数量N很大时,完全连接的神经网络参数为O(N+N2)。
从数据中提取结构,并将该结构编码为网络参数(即权重和阈值),有三种经典范例。
在监督学习中,数据由输入项(例如,图像)和标签(例如,单词“长颈鹿”)成对组成,目标是找到为新的一对数据生成正确标签的网络参数。
在无监督学习中,数据没有标签,目标是发现数据中的统计规律,而没有明确指导查找的规则。例如,如果有足够的长颈鹿和大象的图片,最终神经网络可能会推断出两类动物的存在,而不需要明确标记它们。
最后,在强化学习中,数据用于驱动动作,并且这些动作的成功与否是基于“奖励”信号来评估的。
人工神经网络的许多进步都是为监督学习开发更好的工具。监督学习的一个主要考虑因素是“泛化”。随着参数数量的增加,网络的“表现力” ,即网络可以处理的输入输出映射的复杂性也随之增加。
有足够的自由参数的网络可以拟合任何函数。但是,在没有过拟合的情况下,训练网络所需的数据量通常也会随着参数的数量而变化。如果网络具有太多的自由参数,则网络存在过拟合的风险。
在人工神经网络研究中,网络的灵活性与训练网络所需的数据量之间的这种差异称为“偏差 - 方差权衡”。
具有更大灵活性的网络更强,但如果没有足够的训练数据,网络对测试数据的预测可能会非常不正确,甚至远比简单且功能较弱的网络的预测结果差。
用“蜘蛛侠” 的话来说就是:能力越大责任越大。偏差-方差权衡解释了为什么大型网络需要大量标记的训练数据。
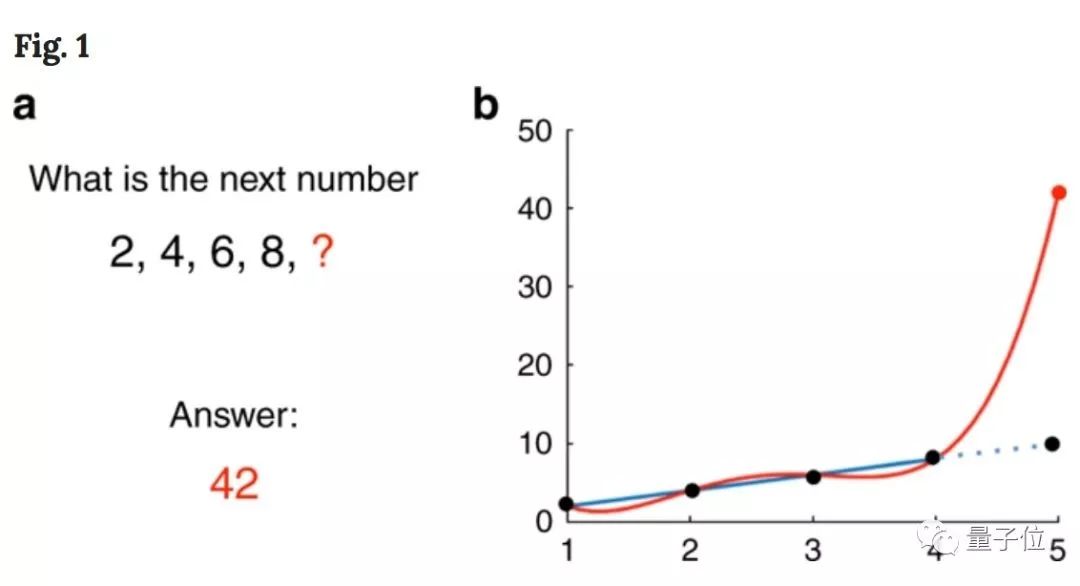
比如一组数2、4、6、8,下一个数字什么,人会很自然的想到10,但是如果我们使用有4个参数的多项式来拟合,神经网络会告诉我们结果是42。
三巨头如何看待监督学习
神经科学和心理学中的“学习”一词指的是经验导致的长期行为改变。在这种情况下,学习包括动物的行为,例如经典的自发行为以及通过观察或指导学习获得的知识。
尽管神经科学和人工神经网络术语的“学习”存在一些重叠,但在某些情况下,这些术语的差异足以导致混淆。
也许它们之间最大的差异是术语“监督学习”的应用。
监督学习是允许神经网络准确地对图像进行分类的范例。但是,为了确保泛化性能,训练此类网络需要大量数据集。一个视觉查询系统的训练需要107个标注样本。这种训练的最终结果是人工神经网络至少表面上具有模仿人类分类图像的能力,但人工系统学习的过程与新生儿学习的过程几乎没有相似之处。
一年的时间大约107秒,所以要按照这种方法训练孩子,需要不吃不喝不睡觉每一秒都问一个问题,以获得相同数量的标记数据。然而,孩子遇到的大多数图像都没有标注。
因此,可用的标记数据集与儿童学习的速度之间存在着不匹配。显然,儿童并不是主要依靠监督算法来学习对象进行分类。
诸如此类的因素促使人们在机器学习中寻找更强大的学习算法,让AI像孩子一样在几年内掌握驾驭世界的能力。
机器学习领域的许多人,包括三巨头中的Yann Lecun和Geoff Hinton等先驱都认为,我们主要依靠无监督算法而不是监督算法,来学习构建世界表征的范例。
用Yann Lecun的话说:
“如果智能是一块蛋糕,那么大部分蛋糕都是无监督学习,蛋糕上的花就是监督学习,蛋糕上的樱桃就是强化学习。”
由于无监督算法不需要标记数据,因此它们可能会利用我们收到的大量原始未标记的感知数据。实际上,有几种无监督算法产生的表示让人联想到那些在视觉系统中发现的表示。
虽然目前这些无监督算法不能像监督算法那样有效地生成视觉表示,但是没有已知的理论原则或界限排除这种算法的存在。
尽管学习算法的无自由午餐定理指出不存在完全通用的学习算法,在某种意义上说,对于每个学习模型,都存在一个数据分布很差的情况。
每个学习模型必须包含对其可以学习的函数类的隐式或显式限制。因此,虽然孩子在他刚生下来一年内遇到带标注的图像数据很少,但他在那段时间内收到的总感官输入量非常大。
也许大自然已经发展出一种强大的无监督算法来利用这一庞大的数据库。发现这种无监督算法,如果它存在的话,那将为下一代人工神经网络奠定基础。
从动物的学习方式中学习
学习行为和天生行为的区别在哪?
核心需要解决的问题是,动物如何在出生后迅速学习,也不需要大量训练数据加持。
和动物相比,人类是一个例外:成熟的时间比其他动物都要长。松鼠可以在出生后的几个月内从一棵树跳到另一棵树,小马可以在几小时内学会走路,小蜘蛛一出生就可以爬行。
这样的例子表明,即使是最厉害的无监督算法,也会面临实际案例上的挑战。
因此,如果无监督机制无法解释动物如何在出生时和不久之后就具有如此的领悟能力,那么对于机器来说,是否有替代方案?但事实是,许多人类感官表达和行为基本上是天生的。
从进化角度来看,天生的行为对生存和学习是有利的,而先天与学习策略之间的进化权衡也很有意思。
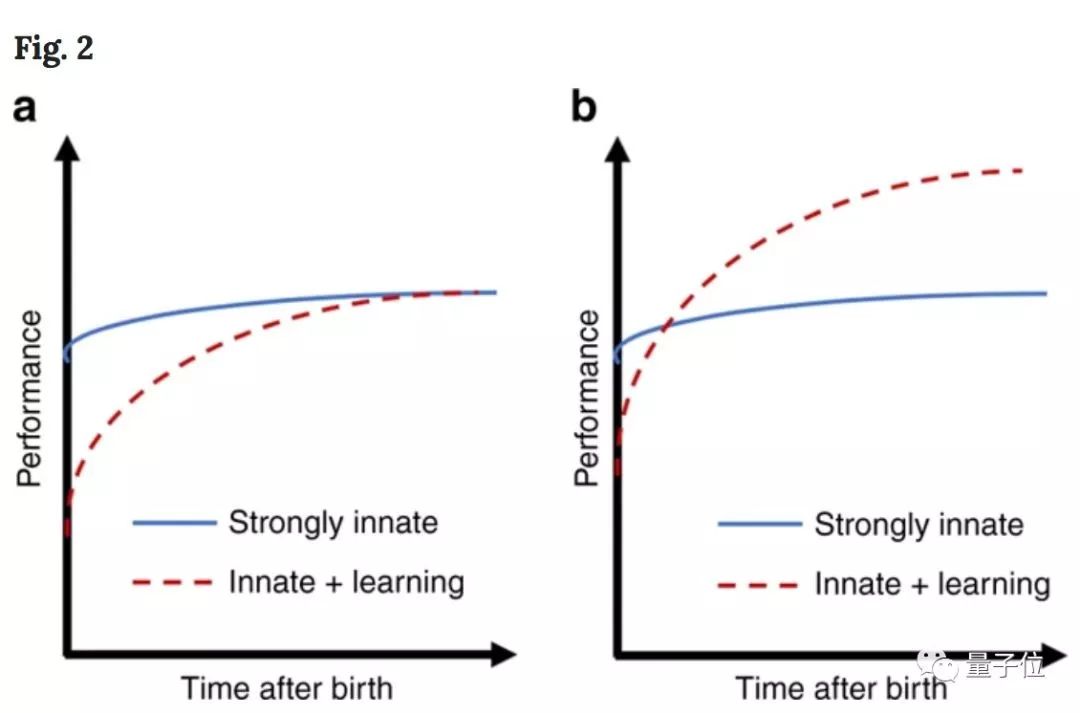
可以看出,通过纯先天学习机制而成熟,与通过额外学习的表现有很大不同。
如果环境迅速变化,从时间角度来看,在其他条件相同的情况下,强烈依赖先天机制的物种将胜过采用混合策略的物种。
基因制定人脑神经网络的布线规则
我们认为动物在出生后如此快速运作的主要原因是,它们严重依赖于先天机制。这些先天机制已经写在了在基因编码里。基因编码蕴含了神经系统的布线规则,这些规则已经被数亿年的进化所选择,也为动物一生中的学习提供了框架。
那么基因是如何说明布线规则的呢?在一些简单的生物体中,基因组具有指定每个神经元连接的能力。以简单的线虫为例,它有302个神经元和大约7000个突触。因此在极端情况下,基因可以编码方式精确地指定神经回路的连接。
但是在较大型动物的大脑中,例如哺乳动物的大脑,突触连接不能如此精确地被基因指定,因为基因根本没有足够的能力明确指定每个连接。
人类基因组大约有3×109个核苷酸,因此它可以编码不超过1GB的信息但是人类大脑每个神经元的神经元数量大约为1011神经元,需要3.7×1015bits来制定所有连接。
即使人类基因组的每个核苷酸都用于制定大脑连接,信息容量比神经元连接少6个数量级。
因此在大型和稀疏连接的大脑中,大多数信息可能需要指定连接矩阵的非零元素的位置而不是它们的精确值。基因组无法指定显式制定神经的接线,而必须指定一组规则,用于在孕育过程中连接大脑。
两点启发
将上述思考放到当前深度学习的研究当中,已经有了很多新发现:
动物出生后具备快速学习的能力,主要因为它们天生就有一个高度结构化的大脑连接。后续学习过程中,这种连接就像提供了一个脚手架,在此基础上快速学习,这种类似的学习理念可能会激发新的方法加速AI研究。
先说第一个。
动物行为为天生的而非学习中产生,动物大脑不是白板,相反配备了一个通用的算法,就像当下很多研究人员设想AGI那样。
动物强选择性学习,将学习范围限制在生存必须能力中。
有些观点认为动物倾向快速学习具体事情是依赖于AI研究和认知科学中的元学习和归纳偏差。按照这种说法,神经网络中有一个外循环优化学习机制,产生归纳偏差,让我们快速学习具体任务。
先天机制的重要性也表明,神经网络解决新问题会尽可能尝试那里以前所有相关问题的解决方案,就像迁移学习那样。
但迁移学习与大脑中的先天机制有本质区别,前者的连接矩阵很大程度上属于起点,而在动物体内需要迁移的信息量很小,经过了“瓶颈基因组”,信息的通用性和可塑性更强。
从神经科学的角度来看,应该存在一种更强大的机制,也就是一种转移学习的泛化,不仅能够在视觉模式中运作,还能跨模态进行迁移。
第二个结论是,基因组不直接编码表示或者行为,也不直接编码优化原则。
基因组只能编码布线规则和模式,然后实例化这些规则和表示。进化的目标,就是不断优化这些布线规则,这表明布线拓扑和网络架构是人工系统中的优化目标。而传统的人工神经网络很大程度上忽略了网络架构的细节。
目前,人工神经网络仅利用了其中一小部分可能的网络架构,还有待发现更强大的、受大脑皮层启发的架构。
其实现在来看,神经处理过程可以通过神经实验显示出来,通过记录神经活动,间接推断出神经表征和布线。
目前,已经有方法可以直接确定布线和脑回路,也就是说,大脑皮层连接的细节有可能不久后就会获取到,并为神经网络的研究提供实验依据。

这些启发不难让人联想起谷歌大脑团队发布的新研究。只靠神经网络架构搜索出的网络WANN,即权重不可知神经网络。不训练,不调参,就能直接执行任务。
它在MNIST数字分类任务上,未经训练和权重调整,就达到了92%的准确率,和训练后的线性分类器表现相当,前景无限。
结论
大脑能为AI研究提供帮助是人工神经网络研究的基础。
人工神经网络试图捕捉神经系统的关键点:许多简单的神经单元,通过突触连接并行运行。
人工神经网络的一些最近的进展也来自神经科学的启发。比如DeepMind钟爱的强化学习算法,也诞生过AlphaGo Zero这样的新研究,这就是从动物学习的研究中汲取灵感的范例。同样,卷积神经网络的灵感来自视觉皮层的结构。
但反过来说,AI的进一步发展是否会方便动物大脑的研究,仍然存在争议。
我们认为这不太可能,因为我们对机器的要求,有时被误导为通用人工智能,根本不是通用的。
这样与人类技能类似的能力,只有与大脑类似的机器才能实现它。但机器与人脑的构造完全不同。
飞机的设计起源于鸟,但最后远优于鸟:飞得更快、适应更高的海拔、更长的距离、具有更大的货容量。但飞机不能潜入水中捕鱼,或者从树上猛扑去捕鼠。
同样,现代计算机已经通过一些措施大大超过人类的计算能力,但是无法在定义为通用AI的明确的任务上与人类能力对应。
如果我们想要设计一个能够完成人类所有工作的系统,就需要根据相同的设计原则构建它。
传送门
Nature报道地址:
https://www.nature.com/articles/s41467-019-11786-6
Reddit讨论区:
https://www.reddit.com/r/MachineLearning/comments/ctu0aj/research_a_critique_of_pure_learning_and_what/
Twitter讨论区:
https://twitter.com/TonyZador/status/1164362711620362240

张亚勤、刘慈欣、周鸿祎、王飞跃、约翰.翰兹联合推荐
这是一部力图破解21世纪前沿科技大爆发背后的规律与秘密,深度解读数十亿群体智能与数百亿机器智能如何经过50年形成互联网大脑模型,详细阐述互联网大脑为代表的超级智能如何深刻影响人类社会、产业与科技未来的最新著作。
《崛起的超级智能;互联网大脑如何影响科技未来》2019年7月中信出版社出版。刘锋著。了解详情请点击:【新书】崛起的超级智能:互联网大脑如何影响科技未来
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



 . var in python...)
















__MessageFormat用法)