
来源: 脑极体
近期在生命科学领域,有一则爆炸性的新闻,DeepMind 的Al phaFold2模型,将人类的98.5%的蛋白质,全部预测了一遍,并且做成了数据集免费开源,供科研圈的人使用。
开放的数据集不仅包括人类蛋白质组,还有大肠杆菌、果蝇、小鼠等20个具有科研常用生物的蛋白质组数据,总计超过35万个蛋白质的结构。phaFold2模型的目标是为所有具有已知序列的蛋白提供预测结构。Deepmind计划在年底将预测数量增加到1.3亿个,而这个数量已经达到了人类已知蛋白质总数的一半。
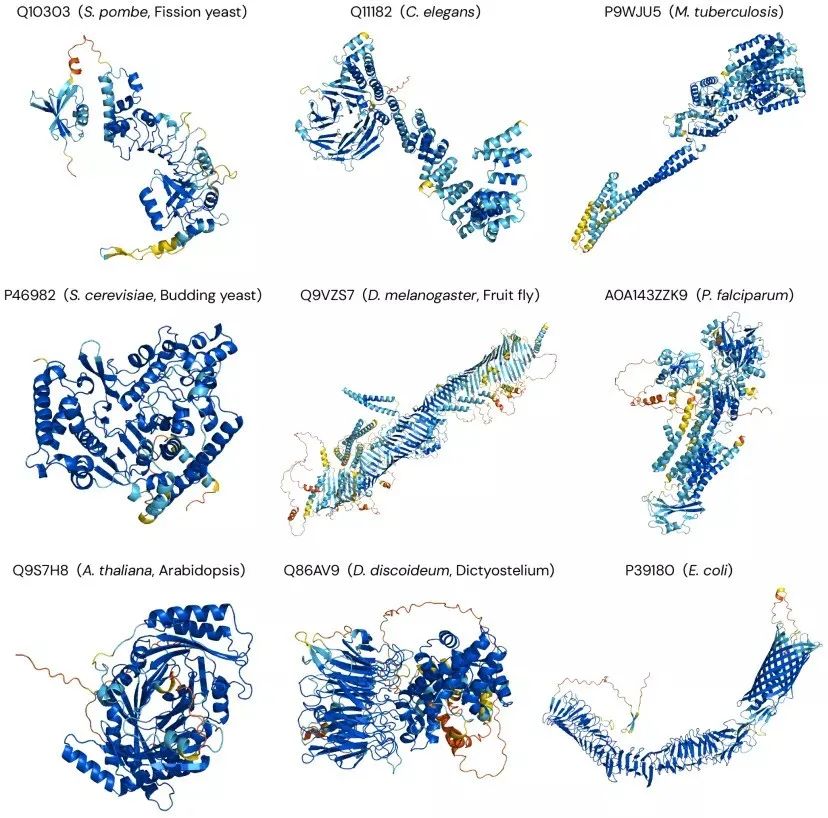
科研圈因为这一新闻都炸锅了,平时需要花费数月、数年的才能完成的事情,只需要几天就可以搞定,大家无一不在赞叹这个具有划时代意义的时刻。DeepMind联合创始人兼CEO Demis Hassabis谈道:“我认为这是DeepMind整个10年多生命周期的顶峰。”对于研究人员来说,丰富的蛋白质结构数据有了,开展下一步的研究就顺畅了。
内行人看门道,外行人看热闹,对于学术圈人的集体高潮,外行人的内心都有个大大的问号,预测这么多的蛋白质结构究竟有什么卵用?人类为何一直在和蛋白质死磕?
研究蛋白质的意义
回答这个问题之前,不得不提及生命科学领域最重要的中心法则:遗传信息在细胞内的生物大分子间转录从DNA→RNA→蛋白质。
如何理解呢?在生物世代繁衍的过程中,生物会把自身携带的遗传物质DNA分子,通过复制传递给后代,而在每一代生物从生到死的过程中,这套DNA分子以自身为设计蓝图,指导生产大量的蛋白质分子,执行支持生物生存和活动的全部功能。

中心法则的一端是DNA,一端是蛋白质,DNA可以看做是工厂里面生产制造的设计图纸,而蛋白质就是有各种功能的零部件,造出来的蛋白质有的跑去参与体内各种生物化学反应,比如食物的消化有各种酶的参与,有的在血液中(血红蛋白)积极的运输养料,有的作为信使在细胞之间传递信号,有的作为卫士,参与生物体的免疫大战,各种设计组装出厂的不同蛋白质可以让遗传、发育、繁殖、代谢等生命活动正常运行开展。
对蛋白质进行系统深入的研究,能让我们从更深层次诠释生命体的构成和运作变化规律,进而全面揭示生命运行、发展的机制,激发生物科学、药物研发、合成生物学方面的发展。
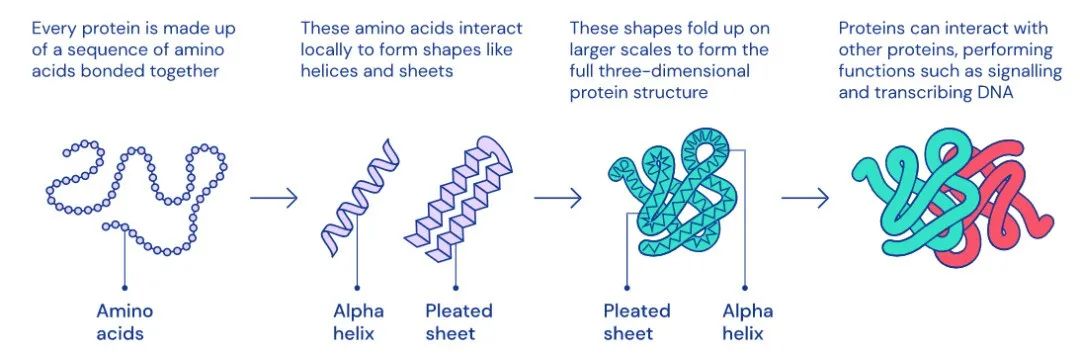
我们在中学就已经简单了解过蛋白质了。蛋白质是生物构成的重要基本物质,由各种氨基酸组成,其排列方式和位置的差异使得其种类极其繁多,结构复杂。每种蛋白质的空间结构和功能都大不相同,也因为蛋白质的空间结构,不同的折叠方式使得蛋白质具有的活性和生物性能不定,而这个复杂的特性也就注定了研究蛋白质的路径困难重重。
蛋白质研究的波折之路
蛋白质早在18世纪就被法国化学家发现,但是因为技术条件的限制,直到20世纪初,科学家才能根据一些技术去深入的研究蛋白质。因为蛋白质结构的复杂与种类极其繁多,研究了解的过程极其费时费力。
对于早期的生化学家来说,研究蛋白质的困难在于难以获取大量的纯化的蛋白质用于研究,因此早期的研究工作就是在各种纯化蛋白质的路上。后来有生物公司1950年在牛胰腺中纯化了核糖核酸酶a,并免费提供给科学家使用,科学家的大量试验逐渐打开。
1949年,英国生化学家桑格用8年的时间测试出了胰岛素(蛋白质)的51个氨基酸的排列顺序,验证了蛋白质是由氨基酸所形成的线性多聚体。因这一研究桑格被授予1958年诺贝尔化学奖。人们运用桑格的方法对许多别的蛋白质迅速进行了测序,桑格的研究为1965年第一次人工合成胰岛素铺平了道路。
人类第一次知悉蛋白质分子结构是在1959年,英国科学家 Max Perutz 利用X射线衍射的方法,根据射线被散射的角度推测电子的位置解析了肌红蛋白分子的三维结构,自此之后,X射线衍射成为解析高分辨率蛋白质结构最有力的工具。除了X射线衍射之外,后期科学家们常用的研究工具还有核磁共振与冷冻电子显微镜技术。
虽然有设备辅助研究,但是现实测试技术的局限,施行起来成本过高,按照传统的实验步骤,从基因序列到相应的蛋白质结构测定之间还要经过基因表达、蛋白质的提取和纯化、结晶、X射线衍射分析等步骤。由于蛋白质结构和性质的多样性,这些步骤大多没有固定的规律可循。
历史上有科学家耗费几十年时间才能得到一个清晰的蛋白质三维结构,蛋白质三维结构的测定成了生物学领域非常困难的研究。至今为止没有AI技术的协助,三维结构被看清的量也仅仅只有17万个,这跟蛋白质的总量相比差距大的跟九牛一毛似的。
对于蛋白质的结构来说,就算我们看得清测得出它的形态,但是关于其折叠的方向在三维空间中有10^300种方式,为何就选择折叠为现在的状态,这个过程和选择的路径没法解析。因为研究的方法与内容都极其困难,所以研究蛋白质的结构以及定性就真的只有死磕这一条路了。半个多世纪以来,研究蛋白质结构的相关工作只要有新的发现就会喜提诺贝尔奖,至今为止仅仅蛋白质领域已经拿过20多项诺贝尔奖。
也有一批科学家跳出肉眼观测的技术思路困境,另辟蹊径,绕开费事费钱的传统技术的试验步骤,从蛋白质的氨基酸序列直接进行计算预测它们的三维结构。
站在AI巨人肩膀上研发
实现从氨基酸预测蛋白质结构的大前提就是计算机技术的发展。1998年,华盛顿大学的 David Baker 教授开发了一套名为 “Rosetta”(罗塞塔石碑)的计算机程序来预测蛋白质结构。但是因为算力的有限,不能暴力地穷举,因此在早期的预测中,主要用来处理氨基酸数量很小、排列比较规则的蛋白质。对于复杂的蛋白质也只能望洋兴叹了。
为了获得对蛋白质结构预测技术水平的客观评估,由马里兰大学的John Moult领导的一组科学家在1994年创立了CASP(结构预测的关键评估),预测者可以在一个双盲框架内评估他们的方法,以促进研究、监测进展,并建立蛋白质结构预测的最新水平。
得益于卷积神经网络的发展,Deepmind的研究在第十四届CASP比赛中大放异彩,团队使用基于注意力机制的神经网络,依靠端到端的优化整体构建结构,内置了大量的序列、结构和宏基因组等多重比较信息,其预测的GDT-TS中值达到了92.4分,远远高于第二名。这是个什么水平呢?据悉,GDT-TS的得分在70分左右,说明其结果具有准确的全局和局部拓扑结构的模型。超过80分,结构细节的建模越来越正确,超过95分,模型就像根据实验数据建立的模型一样准确。
人工智能技术作为预测蛋白质结构的辅助手段,通过暴力的学习穷举,将科学家本来需要几年几十年预测的时间缩短为几日,并且对于简单的蛋白质分子来说结构的预测已经非常精准,而这样的结局就会让科学家们转身投入到深度理解蛋白质本身的机理的研究中。
纵观科学史,每次科学家在所在领域内取得重大的进步,都离不开当时技术的支持。无论是在蛋白质提纯的困难年代,还是观察蛋白质的冷电镜技术时代,科学家研究的工具都依赖于当时的最高科技水平。在AI时代,因为算力和算法模型的极大提升,我们见证了蛋白质结构预测的历史时刻。
AlphaFold2的数据库现已开源并且还在不断地增加新蛋白质结构预测,这也成为了科学家进行蛋白质研究的宝藏数据库。不过算出结构也只是生物科学领域的初步阶段,指明了方向后续的进展还得需要试验与头脑的风暴。对于没有在已有蛋白质结构数据集训练的其他蛋白质结构,其研究仍然是谜一般的存在,这也给科学家们留下了很大的研究空间。
不过AlphaFold2 这样的高精度模型,总的来说还是极大地推动科学家的研究与发展,拓展了对蛋白质进行功能分析、以及下游应用的范围,科学家们得以在各个领域展开开拓性的研究,比如一些癌症、病毒类感染的疾病研究,抗生素、靶向药的开发,研发新效率的酶等为健康与环保的层面做出贡献。
站在神经网络与深度学习的技术巨人的肩膀上,生命科学领域的发展已经有了质的飞跃,AI对于蛋白质的预测也不再依赖人类的先验知识去做结构预测,相比几年前引起轰动的 AlphaGo,AlphaFold 也让深度学习与神经网络好好秀了把肌肉。科学的创新离不开技术工具的强力辅助,而蛋白质这个能够影响生命进程的分子,技术为我们打开了研究它的大门,这些海量的蛋白质结构信息被技术释放,背后的解读与分析可能蕴含着生命信息的密码。下一个生命科学领域的革命性研究成果,炸出来的是什么我们无法想象。在生命科学研究中体验开盲盒的快乐,也是从来没有想过的惊喜,期待下一个未来。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”





-数据链路层设备)

-以太网)


-IEEE802.11无线局域网)


-广域网-PPP协议和HDLC协议)
——适配器模式)





