
来源:AI科技大本营
翻译 & 整理:杨阳
“科学不能告诉我们应该做什么,只能告诉我们能做什么。”
——让-保罗·萨特《存在与虚无》
这一年,AI又有哪些前沿技术突破呢?通过汇总梳理2022年10大AI技术,AI科技大本营发现,这些突破主要集中在图像、视频和语音语义领域。从具体技术来看,虽然有像扩散模型等最新的模型范式,但GAN仍然占据着重要的地位。而卷积和神经网络,以及强化学习等深度学习算法,是被期待获得更多突破的领域。
然而,略微遗憾的是,前些年被寄予厚望的自动驾驶在这一年似乎没有显著进展,尽管Waymo和Cuise在凤凰城和旧金山开启了服务,但如何解决安全问题仍然是一大难题。对此,它们希望通过传统摄像技术附加3D点云同时实现物体和距离的双重感知保障,但是否有效还需验证。
整体上,当下的AI仍处于技术革新的验证阶段,离真正落地产业化看似还有一些距离。但大模型、多模态掀起的AIGC风暴,已经席卷了整个世界。

傅立叶卷积:实现在线图片修复
你是否有过这样的经历,当和朋友拍了一张非常棒的照片后,突然身后有不适合的场景,比如有人在你身后抢拍。不论是不合适的人还是有一个垃圾桶,如果你在自拍之前没有避开,那这张照片似乎就毁了。
然而,如果有AI来辅助,你的这张照片很可能重新焕发生机。一项通过使用傅立叶卷积的掩模绘画技术可以自动删除图像中不需要的人或物,而且可以直接在Intasgram上修改后发帖。只需要点击一下,就可以像专业的PS设计师一样随时改图。

“选中—删除”,效果堪比PS
论文地址:https://arxiv.org/pdf/2109.07161.pdf

基于GAN的面部编辑:遇见二十年后的自己
你想看看二十年后的自己长什么样吗?一项基于GAN的面部编辑技术,可以让你看到未来的自己。对于大部分图像设计师来说,进行面部“改良”并不是什么难事,但大多时候需要消耗很长的时间,少说也需要几个小时,多则数百上千小时。但如果你使用AI工具,这项工作很可能在几分钟之内就能完成。

除了可以预测未来容貌,或者让自己看起来更年轻,这项技术也可以添加各类表情,包括微笑。目前这项技术主要应用于图片,也可以用于视频,包括应用在电影行业中。
论文地址:https://arxiv.org/abs/2201.08361

神经网络渲染:拍照生成虚拟3D图像和视频
当你在玩游戏的时候,有没有想过各个场景中的物体是怎么做出来的?确实可能是插画师画的。但如果有一台相机,可以从不同角度拍摄几张照片,通过神经网络的渲染,就可以在虚拟空间中生成逼真的物体、人物,或者是场景的3D图像。

尽管目前这项技术还面临着诸如场景融合等方面的挑战,但从现实世界取材,生成虚拟3D世界的趋势已经势不可挡。
论文地址:https://arxiv.org/pdf/2201.02533.pdf

DALL·E2:文本生成图片火爆一整年
文本生成图像这一年的火爆无需赘言,掀起这一趋势的非DALL·E2莫属。在DALL·E生成图形的基础上,升级版的DALL·E2学会了图像修复的新技能。在一项对DALL·E2的测试中,它甚至可以理解场景中图像之间的相互关系,包括水可以反射影像,准确将不同方位的物体在水中实现位置精确的投影。

DALL·E2在水中反射火烈鸟
DALL·E2 扩散模型是一种从随机噪声开始学习并不断迭代,通过更改噪声以返回到图像的模型。相较GAN,通过扩散模型,文本生成图像得以更加快速地实现。
论文地址:https://cdn.openai.com/papers/dall-e-2.pdf

SpeechPainter:用AI进行语音和语法的修复
AI不仅可以修复图像,也可以修复语音。一款名为SpeechPainter的语音修复工具可以根据用户定义的修复目标进行音频的修复。具体来说,它不仅可以合成语音中的空白音轨,还可以纠正错误的语法表达和不标准的发音。
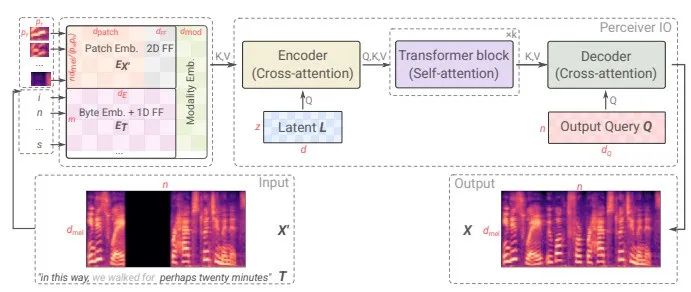
基于感知器IO的SpeechPainter模型
通过GAN的生成器和辨别器,一方面训练生成新的数据,输入音轨;判别器则对训练集中生成的样本进行真伪的判别。
论文地址:https://arxiv.org/pdf/2202.07273.pdf

ChatGPT:压轴出场,惊艳四方
前些天,AI的网络世界中充斥着ChatGPT。其实AI语音并不稀奇了,ChatGPT凭什么火爆网络?首先,是因为它的大模型属性,与它的前一代 GPT-3相比,ChatGPT理论上更擅长交谈;其次,“强化学习”是给ChatGPT赋予魔力的关键所在。最后,是算法的再训练。
基于以上特性,ChatGPT被寄予迈向对话式AI的第一步。不过,它确实有超越以往AI语音助手的更加强大的理解能力,甚至可以“自我”纠错。这让人产生错觉,怀疑它是否有意识,或者哪怕是高级智能,但实际上它还仅仅是算法而已。

官网博客地址:https://openai.com/blog/chatgpt/

语言翻译:如何将一个模型扩展到数百种语言?
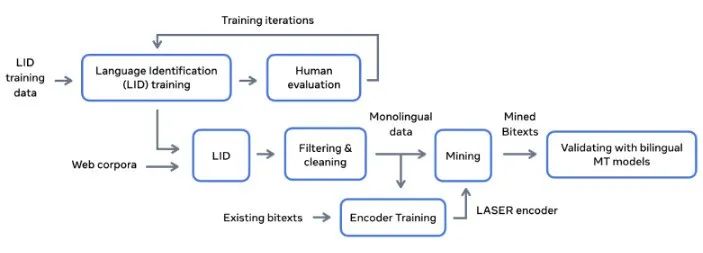
像ChatGPT一样的语言模型确实很炫酷,但它们也有一个共同的问题——只适用于英语。而只要不是英语世界的人,就无法通过这些语言模型来做任何操作。然而,目前世界上已经查明的语言种类一共有5671种,如果每种语言都做一个模型显然是不现实的。
Meta AI的语言模型“不让任何语言掉队”可以通过一个模型翻译数百种不同的语言,目前已经可以翻译200种语言。如何仅通过少量的数据来提升低资源语言的性能?通过稀疏门控专家混合网络 (MoE)可以实现跨语言迁移和干扰之间的更为优化的权衡。
相关阅读地址:https://www.louisbouchard.ai/no-language-left-behind/

自动驾驶:结合激光雷达和摄像头进行3D物体检测
图像和语言太“闹腾”,终于轮到自动驾驶了。实际上,自动驾驶这两年的热度骤降,离成为人工智能的皇冠似乎越来越远,甚至有知名的从业者非常悲观,认为现有的技术不可能实现真正意义上的自动驾驶。
能否实现自动驾驶更加准确的视觉识别,决定了它的安全程度。特斯拉只使用摄像头来探寻外界,但大多数自动驾驶,比如Waymo,会同时使用摄像头和3D雷达传感器。这些雷达传感器的作用路径很容易理解,它们不像摄像头一样产生图像,而是通过点云。
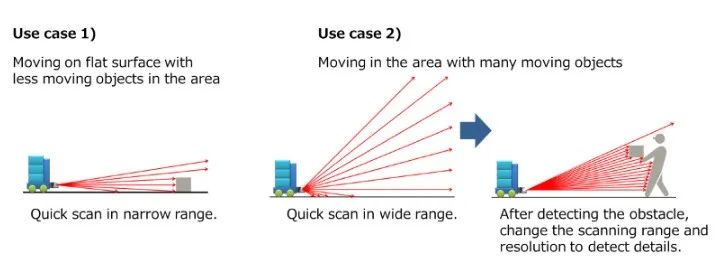
和摄像头呈现图像作用机制不同,雷达传感器主要通过计算脉冲激光投射到物体上的传播时间来测算物体之间的距离。通过传统摄像头和雷达传感器的结合,同时显示物体信息和距离信息,可以让自动驾驶更加安全。
论文地址:https://openaccess.thecvf.com/content/ICCV2021/papers/Piergiovanni_4D-Net_for_Learned_Multi-Modal_Alignment_ICCV_2021_paper.pdf

人工智能多面手Gato,为什么说它很厉害?
Gato是Deepmind创建的多模态代理,它可以控制机械臂,代玩Atari游戏,标注图片标题,以及和人聊天,可以说是AI模型界的变形金刚。

相较于其他AI模型,Gato不仅精通某个领域,它还接受了604项具有不同模式、观察和动作规范的任务训练,使其成为完美的多面手。Gato的精进似乎预示着通用人工智能 (AGI) 的到来。
论文地址:https://storage.googleapis.com/deepmind-media/A%20Generalist%20Agent/Generalist%20Agent.pdf

“看到”声音:观察不可察觉的高频振动
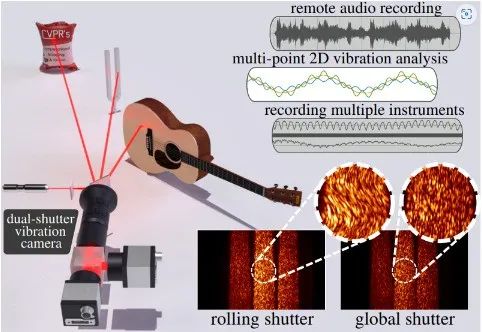
你没有看错,这项AI技术就是要让你“看到”声音。卡耐基梅隆大学的博士后研究员发明了一种让人们看到声音的方法。通过一种新型的摄像系统和成像设备,能够让我们看到肉眼所看不到的声音。
该系统的工作原理是分析使用卷帘快门和全局快门拍摄的图像的斑点图案的差异。算法计算两个视频流中斑点模式的差异,并将这些差异转换为振动以重建声音。通过更好地观察到不可察觉的高频振动,为计算机视觉开辟了新的应用。
论文地址:https://www.louisbouchard.ai/cvpr-2022-best-paper/
参考链接:
1、https://github.com/louisfb01/best_AI_papers_2022
2、https://www.louisbouchard.ai/lama/
3、https://www.louisbouchard.ai/stitch-it-in-time/
4、https://www.louisbouchard.ai/neroic/
5、https://www.louisbouchard.ai/speech-inpainting-with-ai/
6、https://www.louisbouchard.ai/waymo-lidar/
7、https://www.louisbouchard.ai/deepmind-gato/
8、https://www.louisbouchard.ai/no-language-left-behind/
9、https://www.louisbouchard.ai/cvpr-2022-best-paper/
10、https://www.louisbouchard.ai/chatgpt/
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”




)

的数组以及next数组求解)
与词向量的训练)












