
Citation: Wang H, Zhang F, Xie X, et al. DKN: Deep Knowledge-Aware Networkfor News Recommendation[J]. 2018.
Published at: The 27th International Conference on World Wide Web (WWW'18)
URL:https://arxiv.org/pdf/1801.08284.pdf
Motivation
推荐系统最初是为了解决互联网信息过载的问题,帮助用户针推荐其感兴趣的内容并给出个性化的建议。新闻具有高度时效性和话题敏感性的特点,一般而言新闻的热度不会持续太久,而且用户关注的话题也多是有针对性的。其次,新闻的语言高度浓缩,往往包含很多常识知识,而目前基于词汇共现的模型,很难发现这些潜在的知识。因此这篇文章提出了 DKN,将知识表示融合到新闻推荐系统中。
DKN Model
首先看一下 DKN 模型的框架,如下图所示。
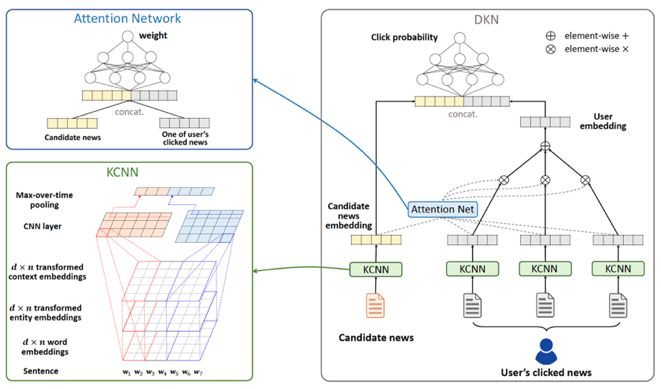
DKN 模型主要分成三部分:知识抽取(Knowledge Distillation)、知识感知卷积神经网络(KCNN: Knowledge-aware CNN)、用于抽取用户兴趣的注意力网络(Attention Network: Attention-based UserInterest Extraction)。下面对这三部分进行详细的介绍。
1. 知识抽取
知识抽取模块的输入是一些用户点击的新闻标题以及候选新闻的标题。整个过程可以参见下图。
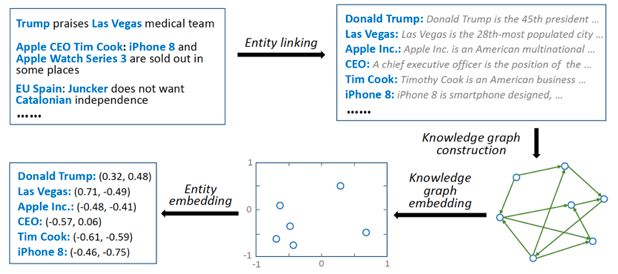
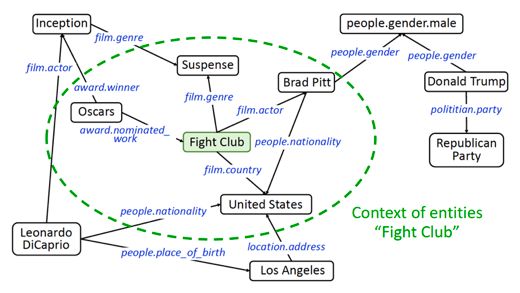
首先将标题拆成一组词,然后将标题中的词与知识库的实体进行链接。如果可以找到词所对应的实体,那么再接着找出距离链接实体一跳之内的所有邻接实体,并将这些邻接实体称之为上下文实体。寻找上下文实体的过程如下图所示。
这样,根据新闻标题可以得到三部分的信息,分别是词,链接实体,以及上下文实体。利用 word2vec 模型可以得到词的向量表示,利用知识图谱嵌入模型(这里用的 TransD)可以得到知识库实体的向量表示。其中,链接实体的表示就是 TransD 的训练结果,如果链接不上就 padding。上下文实体的表示就是对多个实体的表示进行平均,如果前一步没有链接实体这里也同样 padding。由此分别得到了词、链接实体、上下文实体的向量表示。
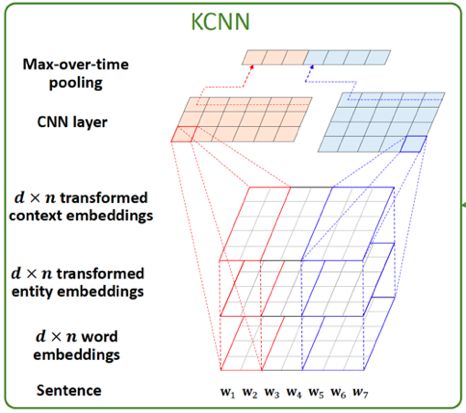
2. 知识感知卷积神经网络 KCNN
在得到新闻标题三方面信息的向量表示之后,下一步是要将它们放到同一个模型中进行训练。但是这里存在的问题是,三者不是通过同一个模型学出来的,直接放到同一个向量空间不合理。这篇文章使用的方法是,先把链接实体、上下文实体的向量表示通过一个非线性变换映射到同一个向量空间:
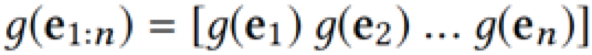
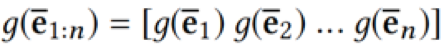
然后类似于图像中 RGB 的三通道,将词、链接实体、上下文实体的向量表示作为CNN多通道的输入。这样 KCNN 的输入就可以表示为
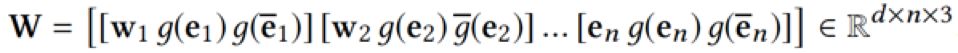
然后通过卷积操作得到新闻标题的向量表示
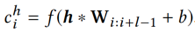
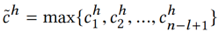
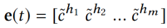
KCNN 的架构可以参加下图。这里还用了不同大小的卷积核进行卷积。
3. 注意力网络
给定用户 i 的点击历史新闻:
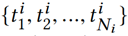
通过 KCNN 得到它们的向量表示:
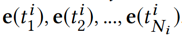
采用一个 DNN 作为注意力网络和一个 softmax 函数计算归一化影响力权重
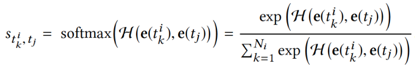
这样可以得到用户i关于候选新闻ti的向量表示:
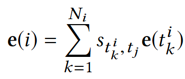
用户i点击新闻 tj 的概率由另一个 DNN 预测
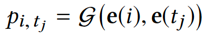
Experiments
数据集
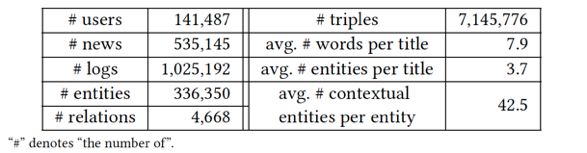
这篇文章的数据来自 bing 新闻的用户点击日志,包含用户 id,新闻 url,新闻标题,点击与否(0未点击,1点击)。搜集了 2016 年 10 月 16 日到 2017 年 7 月 11 号的数据作为训练集。2017年7月12号到8月11日的数据作为测试集合。使用的知识图谱数据是 Microsoft Satori。以下是一些统计数据以及分布。
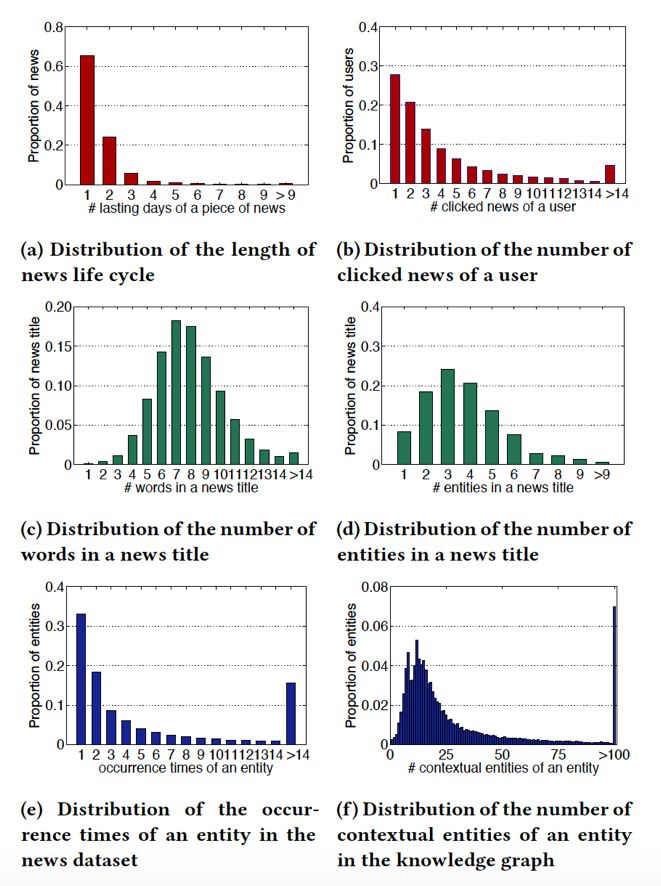
实验结果
实验用的评价指标是 AUC 和 F1。
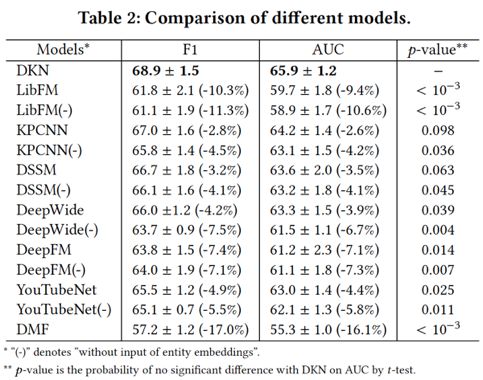
对比实验结果如下表所示。
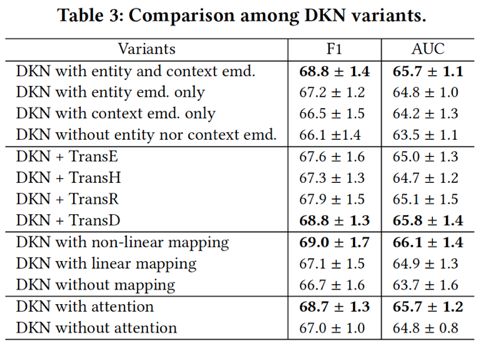
下面这张表展示了 DKN 本身的一些变量对实验结果的影响
笔者认为,DKN 的特点是融合了知识图谱与深度学习,从语义层面和知识两个层面对新闻进行表示,而且实体和单词的对齐机制融合了异构的信息源,能更好地捕捉新闻之间的隐含关系。利用知识提升深度神经网络的效果将会是一个不错的方向。
本文作者邓淑敏,浙江大学计算机学院2017级直博生,研究方向为知识图谱与文本联合表示学习,动态知识图谱,时序预测。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。

事理图谱构建项目)

















