
Cao Y,Huang L, Ji H, et al. Bridge Text and Knowledge by Learning Multi-Prototype Entity Mention Embedding[C]// Meeting of the Association for Computational Linguistics. 2017:1623-1633.
导读:学术界近两年来十分关注如何将文本等非结构化数据和知识库等结构化数据映射到相同的语义空间中,然而在相同的语义空间中建模的过程会受到文本中实体指称(mention)歧义的影响,即文本中的同一个姓名如迈克尔·乔丹可能指的是著名的篮球运动员乔丹也可能是我们敬仰的教授乔丹,那么在语义空间中,因为他们的字面表达相同而将其建模成为统一的向量显然是不合理的。因此,文中提出了一种新的mention向量表示的学习框架Multi-Prototype Entity Mention Embedding (MPME),它可以根据实体指称所对应的词义的不同而联合文本和知识库学习到不同的表示。此外,文中提出了一种类似于语言模型的方法解决了实体指称的语义消歧问题。最后,实验部分利用实体链接任务作为MPME的应用场景,取得了当前最优的实验效果。
研究动机
当前有相当多的工作研究如何将文本和知识库进行关联建模,显然这样会为自然语言处理及知识库相关的研究任务带来比较大的性能提升。当前的研究思路可以粗略地分为两类,其一是利用深度神经网络将实体和词语直接在统一的语义空间中进行建模,但这类方法比较受限于计算复杂度以及语料的规模。其二是分别对知识库中的实体以及文本中的实体指称进行建模,并且利用 wiki 百科中的外链获取 mention 和 entity 之间的关联,相当于在各自训练的过程中加入了一层约束用于确保他们在各自的语义空间中有相似的表达。上述两类方法都会面对同一个实体指称可能对应到多个实体的歧义问题,即文本中提到的迈克尔乔丹可能是教授也可能是运动员或其他不甚知名的人,也会面临多个实体指称对应同一个实体的歧义问题,即文本中出现的姚明和小巨人可能指的同一个人。因此本文着手解决实体指称的语义歧义问题,类似于传统的实体链接任务。
创新点
本文提出了一种新型的实体指称表示学习方法 MPME,结合文本信息以及知识库信息学习实体指称的表示;此外,文中还提出了一种基于语言模型的决策方法来进行实体指称的语义消歧。
模型
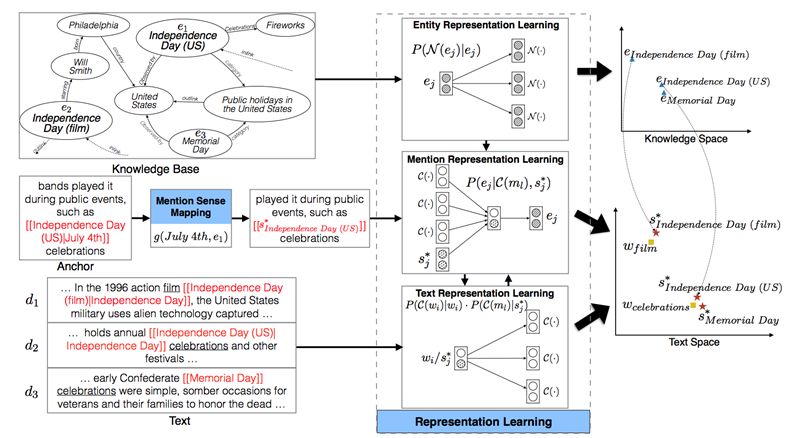
MPME 框架结构示意图
如图所示,模型可以大致分成两个部分。
其一是表示学习部分,通过 Word Embedding 和 Knowledge Graph Embedding 对文本和知识库分别进行建模,其中每个实体指称都对应着一个实体集合,也就是它们潜在的语义。在Entity Representation Learning中,训练的目标是有相似的关联实体的实体之间更相似。在Text Representation Learning中,实体指称将和其他词汇一起通过 Skip-Gram 模型进行训练,在Mention Representation Learning中,实体指称被替换为相应的词义(sense),上下文的表示来自文本表示学习部分,实体的表示来自知识库表示学习部分,目标是得到更好的实体指称的表达sj*,使得根据上下文信息,能够确定实体指称所对应的语义(对应哪个实体)。
其二是测试场景下的消歧部分,模型会综合考虑实体指称对应的上下文信息,以及实体指称对应各个语义的统计概率分布进行计算。
实验结果
文章的目标是训练得到一组高质量的实体指称向量,仍然没有跳出表示学习的框架,因此实验部分首先比较了采用$MPME$之后,训练得到的向量的相似实体指称都有哪些,以及从 mention embedding 和相应的 entity embedding余弦距离的角度进行了分析,各项指标相对对比模型SPME提高了1%左右,这一部分就不做赘述了。
同时,文章利用 mention embedding 在实体链接任务上进行了验证,在AIDA数据集上,不管是有监督的实体链接任务还是无监督的实体链接任务,利用 MPME 均取得了相较于之前最好结果3%左右的提升。
启发
mention 之间的信息
本文中把文本和知识库分别单独进行建模,mention 的建模过程中比较多的考虑 mention 和 entity 之间的关联,所谓的上下文更多的是以词窗口内词汇的形式出现的,而不是上下文中其他的mention,因此有可能会忽略一些关键的信息。传统的实体链接方法中比较多使用的一类是基于图的算法,其优势便在于能够更充分的发掘 mention 和 mention 之间,mention 和 entity 以及 entity 和 entity 直接的结构关联信息,利用这些信息进行消歧已经足够有效(体现在实体链接任务的准确率上),那么也可以尝试利用图结构更好地学习 mention 的表示。
潜在的问题在于,假设 mention 所对应的两个歧义实体属于同一个 category,那么它们会共享十分相似的上下文,通过本文所题出的方法将不能很好的解决这个问题。比如两只都叫做旺财的狗,它们的日常表现应该会比较相似,唯一不同的可能就只有它们的主人不同,这一点需要上下文中 mention 的参与,共同建模。
未登录词的处理
实际的应用场景中,未登录mention的数目理应远多于已经训练的 mention 的数目,这样才能体现出模型或方法的泛化能力,这也为我们提出更加 general 的 framework 提出的新的需求,或者说,训练的过程尽可能简单,所需的额外信息尽可能的少,对未登录词的发现更加友好的框架。
论文笔记整理:吴桐桐,东南大学博士生,研究方向为自然语言问答。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。











+面试题目+6条面试经验)



)


--整体概述)
