
链接:http://www.public.asu.edu/~cbaral/papers/2018-aaai-psl.pdf
概述
视觉问答(Visual Question Answering)现有两大类主流的问题, 一是基于图片的视觉问答(ImageQuestion Answering), 二是基于视频的视觉问答( Video Question Answering).而后者在实际处理过程中, 常常按固定时间间隔取帧,将视频离散化成图片(frame)的序列,剔除大量冗余的信息, 以节省内存.
当前视觉问答的研究主要关注以下三个部分:
延续自然语言处理中, 对注意力机制(Attention Mechanism) 和记忆网络(Memory Network) 的研究,旨在通过改进二者提高模型对文本和图像信息的表达能力,通过更丰富的分布式表示来提升模型的精度.另一方面,也可以视作是对神经计算机(Neural Machine) 其中键值模块(Key-value, 对应注意力)和缓存模块(Cache, 对应记忆网络)的改进.
密集地研究可解释性(Interpretability)和视觉推理(Visual Reasoning) . 对同领域多源异构数据,这类研究方向将问答视为一种检索或人机交互方式,希望模型能提供对交互结果(即答案)的来由解释.
将文本或图像, 以及在图像中抽取的一系列信息, 如场景图谱(SceneGraph), 图片标题(Image Caption)等视为是”知识来源”, 在给定一个问题时,如何综合考虑所有的知识,并推断出最后的答案.
文章开头提到的论文,便是朝着第三个方向再迈进一步.
模型
本文提出的主要模型,是一个基于一阶谓词概率软逻辑(Probabilistic Soft Logic)的显式推理机. 如果你已经训练好了一个用于视觉问答的神经网络模型,那么这个显式推理机可以根据模型的输出结果, 综合考虑信息后,更正原本模型的输出结果. 这样的后处理能提升模型的精度.下图就是一个这样的例子.
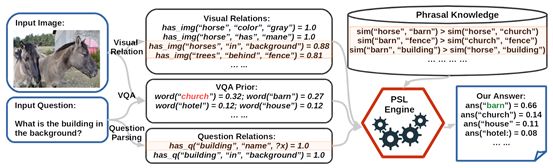
图 1:一个正面例子
图 1 中红色六边形标示的 “PSL Engine”, 是显式推理的核心部分.通过这一个部分, 将 “VQA” 的预测结果与” Visual Relation(视觉关系)”,“Question Relation(问题关键词关系)”和”Phrasal Knowledge(语言常识)”三部分信息综合起来,进行推理, 更新答案. 此处是一个正向例子.
推理过程具体如下:
生成 VQA 答案: 存在一个视觉问答的神经网络模型, 对于这幅图片和相应问题,预测出最有可能的答案是:教堂(church) 和谷仓(barn).
生成Visual Relation: 通过利用Dense Captioning system(Johnson, Karpathy, and Fei-Fei 2016) 生成图片的文本描述, 再用Stanford Dependency Parsing(De Marneffe et al. 2006) 抽取生成描述中的关键词,再启发式的方法为关键词对添加上关系,构成三元组.这代表了从图片中抽取出有效的结构化信息.
生成 Question Relation: 再次使用StanfordDependency Parsing及启发式方法抽取问题中包含的三元组信息.
生成 Phrasal Knowledge: 将所有相关关键词在ConceptNet 和词向量中索引,并计算相似度.
由概率软逻辑推理引擎综合前面四步生成的所有信息, 更新 VQA 答案对应的得分,并重新排序,得到新的结果.
在推理过程中,使用了概率软逻辑, 来综合考量各种生成的事实. 其核心思想是: 由谓词和变元组成的命题, 真值不在局限于1或0(真或假), 而是可以在闭区间[0, 1]上取值. 一个简单的例子是:
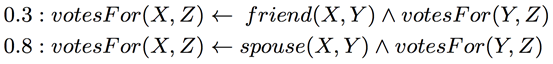
“X和Y是朋友关系且Y为 Z投票, 蕴含X为 Z 投票”的权重是0.3. 而“X和Y是伴侣关系且Y为Z投票, 蕴含X 为 Z 投票”的权重是0.8. 回到本文的例子, 综合所有生成的命题并进行推理的过程如下:
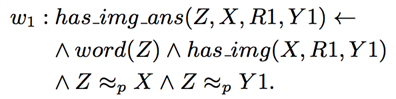
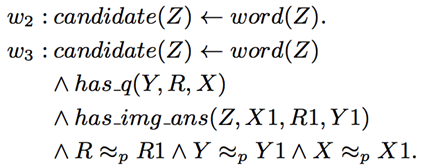
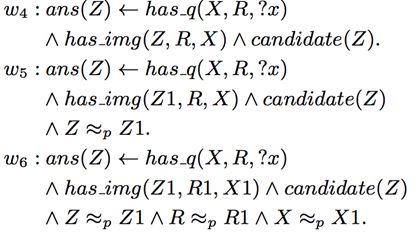
在此, 命题的权重w_i 是需要学习的部分. 而优化的目标是使得满足最多条件的正确答案的权重最高.
实验
在数据集MSCOCO-VQA(Antol et al. 2015) 测试. 让我们看看效果:

图 2:实验结果中的 8 个例子
笔记整理:杨海宏,浙江大学博士,研究方向为知识问答与推理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。

)


--整体概述)














