本文转载自公众号:AI 时间。


《AI108将》是AI时间全新的AI行业人物专访栏目。
艾伦·麦席森·图灵说:有时,那些人们对他们并不抱有期望的人,却能做到人们不敢期望的事情。Sometimes It's very people who no one imagines angthing of who do the thing no one can imagine.
百度李彦宏说:为什么大家觉得人工智能没有用?我在美国读书的时候,我就很喜欢人工智能这门课,但是学完之后,教授说其实没用。
“人工智能没有一个真正有商业价值的应用,你将来靠这个是找不着工作的。”
现在,全球AI领域从业人员仅30万,但人才缺口达到了200万。
对AI不抱希望的美国教授,恐怕现在很难理解中国政府将人工智能写进《中国制造2025发展规划》的初衷。
但中国的AI从业者懂。
我们寻找在中国的人工智能领域已经占有一席之地,或者正在路上的创业者,投资人,专家和媒体人,试图通过他们的故事来拼起属于我们中国的AI谱系。将不可能变为可能只是前菜。我们希望几十年后科兹威尔的奇点临近之时,《AI108将》可以作为一部真实可信的历史文献,供后人(或许是机器人)参考研究。
ALL IN AI,ALL IN人工智能。
一个引子
今年1月,工信部信息通信管理局约谈了百度、支付宝和今日头条,称其非法调用用户手机权限。
幸灾乐祸的腾讯紧跟着发布了《2017年度网络隐私安全及网络欺诈行为分析报告》。
报告显示:去年下半年,安卓手机App中有98.5%都在获取用户隐私权限,相较于上半年增长近2%。获取用户手机隐私权限的iOS应用比例上升,达到81.9%。有9%的安卓应用在2017下半年存在越界获取用户隐私权限的现象。
不过常在河边走哪有不湿鞋。
上个月,有网友反映在使用QQ浏览器打开某些网页的时候会引起vivo NEX摄像头缓缓弹出。有网友怀疑打开QQ浏览器时,软件存在偷拍用户的嫌疑。
QQ浏览器发布情况说明,确认存在摄像头被调起,不过这一动作不会开启摄像头,更不会拍摄或记录。

打脸与否我们暂时无法判别,但是毋庸讳言,我们几乎每天都会接收到各种各样的推荐信息,从新闻、购物到吃饭、娱乐。个性化推荐系统作为一种信息过滤的重要手段,可以依据我们的习惯和爱好推荐合适的服务。
话说回来,巨头们如果真的想要给你推荐广告,真的有必要冒着被发现的风险偷拍你吗?
扪心自问一下,你家里是有矿还是咋地?别自作多情了。
推荐系统和知识图谱
微软研究院发布的一篇文章认为,传统的推荐系统只使用用户和物品的历史交互信息(显式或隐式反馈)作为输入,这会带来两个问题:
一, 在实际场景中,用户和物品的交互信息往往是非常稀疏(sparse)的。例如,一个电影类APP可能包含了上万部电影,然而一个用户打过分的电影可能平均只有几十部。使用如此少量的已观测数据来预测大量的未知信息,会极大地增加算法的过拟合(overfitting)风险;
二,对于新加入的用户或者物品,由于系统没有其历史交互信息,因此无法进行准确地建模和推荐,这种情况也叫做冷启动问题(cold start problem)。
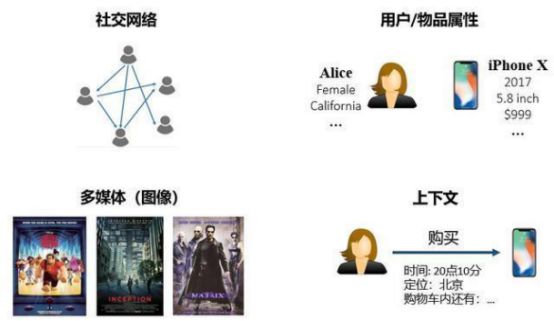
解决稀疏性和冷启动问题的一个常见思路是在推荐算法中额外引入一些辅助信息(side information)作为输入。辅助信息可以丰富对用户和物品的描述、增强推荐算法的挖掘能力,从而有效地弥补交互信息的稀疏或缺失。常见的辅助信息包括:
社交网络(social networks):一个用户对某个物品感兴趣,他的朋友可能也会对该物品感兴趣;
用户/物品属性(attributes):拥有同种属性的用户可能会对同一类物品感兴趣;
图像/视频/音频/文本等多媒体信息(multimedia):例如商品图片、电影预告片、音乐、新闻标题等;
上下文(context):用户-物品交互的时间、地点、当前会话信息等。
……
如何根据具体推荐场景的特点将各种辅助信息有效地融入推荐算法一直是推荐系统研究领域的热点和难点,如何从各种辅助信息中提取有效的特征也是推荐系统工程领域的核心问题。
知识图谱研究应运而生。
《AI时间》有幸采访了知识图谱领域的学术大咖,王昊奋和漆桂林两位专家,听听他们在知识图谱领域的见解和分享,相信不久之后你们家也可以有矿了。

以下是采访内容:
王昊奋:知识图谱为虚拟生命赋能
AI时间:什么是知识图谱?基本原理是什么?历史沿革有哪些?
王昊奋:1)目前知识图谱还处于初期阶段;2)人工干预很重要;3)结构化数据在知识图谱的构建中起到决定性作用;4)各大搜索引擎公司为了保证知识图谱的质量多半采用成熟的算法;5)知识卡片的给出相对比较谨慎;6)更复杂的自然语言查询将崭露头角(如Google的蜂鸟算法)。
此外,知识图谱的构建是多学科的结合,需要知识库、自然语言理解,机器学习和数据挖掘等多方面知识的融合。有很多开放性问题需要学术界和业界一起解决。我们有理由相信学术界在上述方面的突破将会极大地促进知识图谱的发展。
By王昊奋《知识图谱技术原理介绍》

AI时间:为什么Chatbot需要知识图谱(Knowledge Graph,KG)?
王昊奋:知识图谱于2012年由谷歌提出,旨在提供更好的搜索体验。随着整个Web从原先由网页和超链接构成的Web of Docs转换为由实体或概念及他们之间的关系构成的Web of Data,谷歌提出了更准确的语义搜索,旨在解决原有的关键字搜索仅基于字符串无法理解内容语义的局限。
除了搜索,知识图谱也被广泛用于各种问答交互场景中。Watson背后依托DBpedia和Yago等百科知识库和WordNet等语言学知识。类似地,Alexa也依托其早年收购的True Knowledge公司所积累的知识库;Siri则利用DBpedia和可计算的知识服务引擎WolframAlpha;狗尾草公司推出的虚拟美少女机器人琥珀虚颜则用到了首个中文链接知识库Zhishi.me。伴随着机器人和IoT设备的智能化浪潮,智能厨房、智能驾驶和智能家居等应用层出不穷。无独有偶,百度推出的Duer OS和Siri的进化版Viv背后也都有海量知识库的支撑。
KG也可辅助通用人工智能(Artificial General Intelligence,AGI),即在常识推理方面起到作用。过去人们常用图灵测试对机器的智能进行评估,近年来,Winograd Schema Challenge逐渐进入大家的视线。这里举一个指代消解的例子。指代消解是一个经典NLP任务,旨在将代词指向具名实体。
By王昊奋《When KG meets Chatbots》

AI时间:如何理解AI虚拟生命的概念?
王昊奋:首先,Chatbot需要更加个性化的知识图谱。
其次,我们的世界不仅仅是静态的,而是动态地反映各种事物在时空上的变化。因此,我们不仅仅需要刚刚谈到的静态图谱,而是需要思考如何表示和应用动态图谱。
第三,机器人不能只是冷冰冰的回答用户的问题或帮助用户完成特定功能。它需要感知用户的情感并在输出答案回复的同时伴随着相应的情感,这样才更加拟人化。我们发现,之前构建的知识图谱大多是客观的,即描述一些客观的事实。如何在结合个性化图谱时,能包括一些主观知识,进而刻画机器人或用户的情感元素。
第四,我们发现聊天机器人为了完成很多功能需要对接外部服务或开放API。
从聊天机器人升华到虚拟生命,技术方面存在不小的挑战。感知方面需要存在感官选择和整合,全双工模式,多人沟通和远场交互等方面不断提升。在认知方面,意图与表达多样化的识别、情感计算、多轮对话及上下文管理,常识推理,个性化和回复一致性等都是亟待解决的难题。在进化技术方面,深度学习利用大数据的红利,对于特定任务可以做到举一万反一,而我们人类是小数据学习的典范,可以做到举一反三,如何让虚拟生命做到基于小数据的泛化学习是一个核心挑战。此外,自我认知管理,即知道我们知道什么东西,不知道什么东西对于虚拟生命处理拒识也有很大的帮助。当然快速性格建模以及快速价值观的形成都是构建虚拟生命进化技术需要关注的。
By王昊奋《从聊天机器人到虚拟生命:AI技术的新机遇》
漆桂林:知识图谱构建不是一个技术来解决,而是需要一套工程方法
AI时间:我们了解到,您曾作为第二负责人参与了由科大讯飞牵头的863课题“高考机器人”的一个子课题。高考机器人和市面上的聊天机器人异同点有哪些?如何利用知识图谱技术实现这些功能?
漆桂林:高考机器人是一个基于知识图谱的问答机器人,需要利用从高中课本、教辅材料、百科等数据源获取的知识来进行问答。
题目的类型有选择题、填空题、简答题等,知识的获取是半自动的,这跟市面上聊天机器人有本质的区别,因为这些机器人大多是基于FAQ的问答对,需要大量人工配置问答对的工作,聊天机器人的知识库不是知识图谱,只是问答对。

AI时间:我们注意到您在一篇介绍知识图谱的落地应用的文章中,认为这项技术在智能问答和语义搜索等领域应用颇多,认为“Watson系统和很多人工智能系统一样,是高度定制化的,当然,相关技术确实是可以用到多个领域,但是需要有一定的变化。”
知识图谱技术如何与watson这种高度定制化的专家系统相结合?技术优势是什么?
漆桂林:知识图谱技术已经被应用于Watson系统,Watson系统从一些开源的知识图谱中,比如说DBpedia,检索答案。知识图谱只是专家系统的一部分,是解决专家系统的知识获取的关键。
AI时间:知识图谱和深度学习之间的关系是什么?
漆桂林:知识图谱是人工智能中知识工程的一个分支,而深度学习是人工智能中神经网络的一个分支,两者具有相辅相成的关系,我们可以利用深度学习技术来实现知识图谱的构建和推理,也可以利用知识图谱来增强深度学习的可解释性。

AI时间:数据缺失如何解决?我们注意到一些企业如google最近刷屏的你画我猜小程序来获取数据,这是企业的产品优势。科研人员如何获取知识图谱需要的语料?
漆桂林:对于图像识别来说,利用一些小程序获取数据是比较容易的。
但是知识图谱构建不是一个技术来解决,而是需要一套工程方法,这就使得知识图谱学习和应用的门槛比图像识别要高很多。
目前谷歌、微软等公司的知识图谱都是通过从互联网的网页以及用户对网页的浏览以及用户的搜索日志中获取数据。
科研人员要获取数据,可以从百科和各种网站去爬取数据,对数据进行再加工得到知识,还可以通过提供各种知识服务,比如说问答、推荐和搜索,获取用户对数据,从而对图谱进行更新。
AI时间:对于非结构化数据,用知识图谱如何来解决?为什么说知识图谱除了是一门技术,更是一项工程?
漆桂林:这里我先假设非结构化数据指的是文本。首先,非结构化数据可以用来构建知识图谱,这里需要采用自然语言处理的技术,比如说命名实体识别和关系抽取。其次,我们可以利用开源的知识图谱,比如说Zhishi.me,来对非结构化数据进行自动化标注,知识图谱中的实体可以通过实体链接的技术来链接到文本中,这样就可以把知识图谱和文本关联起来,形成一个文本和实体关联图谱,从而辅助智能问答和语义搜索等应用。
AI时间:你曾经在一次专访中提到,对于知识图谱技术的发展而言,一个是缺数据,一个是缺工具。目前是否有改观?如何解决?
漆桂林:对于缺数据这个问题,我其实指的是开源的图谱缺失。目前openKG正在试图处理,openKG已经汇集了百科类的知识图谱以及很多行业图谱,而且也在建立这些图谱之间的链接,这将有助于解决知识图谱的数据缺失问题。缺工具的问题比较明显,这里的工具不是单指某一个算法实现后的工具,而是工具群以及把这些工具群整合在一起的平台。
举个例子,关系抽取有不少算法,也有一些开源的工具,但是商用的时候不是一个算法可以解决问题的,往往需要把一套关系抽取工具集成起来才有效,这种可以解决用户问题的工具是缺失的,需要通过公司化运作来实现。大公司大部分都是这么做的,但是他们的工具只是给自己用,不会开放出来。可喜的是,目前有一些小公司正在做知识图谱的实用工具和平台,今年或者明年应该会有一些很不错的产品出现,这也将是知识图谱快速发展的契机。
大咖推荐
AI时间:目前除了OpenKG.cn这类型的平台,国内还有其他知识图谱的学习渠道吗?
王昊奋&漆桂林:就是没有其他平台(我们才做了OpenKG)。
AI时间:如果想要进入知识图谱研究领域,需要具备哪些基础知识?学习路径是什么?请推荐一些书籍或者课程。
王昊奋&漆桂林:看课程大纲呗(我发誓这是大咖原话,绝对不是我想打广告)

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


-算法思想与经典算法)








)







)