可信知识实证在UGC时代情报应用中的思考与探索
在当前互联网高度发达、可发布信息源和信息渠道猛增且多元化的大背景下,信息形态变得广泛且多模。从传统的纸质文档,到中期的电子结构化文档、电子非结构化文本,再到如今的语音信息、图片信息、视频流信息鼎立的局面,信息市场变得复杂而多变。
在UGC(用户生产内容)以及数据众包生产的大环境下,存在广泛的信息过载和信息混乱的问题。但情报的挖掘、信息的二次加工显得尴尬且必须,这对数据生产中的数据获取端、知识抽取环节以及业务端三个方向提出了更高的要求。
事实上,支撑起目前自然语言处理相关落地产品的数据来源大多来自开源信息情报,门户网站、各大垂直网站、论坛社区、“两微一条”、政府报告、研究报告、政策公告、百科问答等公共数据。这为舆情监控、事件热点挖掘、智能问答、文本生成、知识图谱可视化、风险推理等多个落地应用带来了诸多挑战。
数据地平线充分认识到“可信知识实证”的重要性,并在底层知识库构建、自然语言处理组件开发、产品应用上引入了可信知识溯源的思想,探索形成了多个可信语言资源库、知识抽取平台、大规模事理学习系统以及投研逻辑管理平台。本期围绕“可信知识实证在UGC时代情报落地中的思考与探索”这一主题进行分享。
一、UGC时代下的信息乱象
搜索引擎和UGC(用户创作内容)无疑是当代生活中重要的科技力量,但它们产生的副作用也是客观存在的,这直接带来了两个突出的问题,即信息过载以及信息模糊化。信息过载带给用户一种视觉上的压迫感,而模糊化使得信息流中混杂着可信度参差不齐的元素,极大地扰乱了信息市场的正常运转和人为决策。

图1-谣言不断的信息乱象图
例如,新冠肺炎疫情防控过程中,关于防护措施以及感染情况的造谣传播行为直接干扰疫情决策;杭州女子莫名失踪案中,网红蹲守事发现场直播并对案情涉及主人公进行身份、行为猜测,并发布不实信息的行为,直接妨碍公安事务管理;搜索引擎中返回用户问题不实答案造成伤害;用户对常用成语、对联、古诗词的篡改所引起的学生误导等,明显揭露出了当前社会对信息可靠性的迫切需求。
谣言与辟谣两者之间的斗争在信息市场上频频上演,信息的准确性、可靠性、实时性与全面性成为了目前信息处理领域对信息本身提出的四个要求,这一点,在严重依赖该信息而作出某种决策的行为或工作中表现得更为强烈。然而,就谣言和不实信息的斗争而言,其需要花费大量的人力、物力,并对现行技术提出了极高的要求,无论在内容生产、内容加工还是在内容消费上,“知识可靠性验证”的需求呼之欲出。
二、信息乱象下的情报挖掘应对措施
在信息乱象下的大背景下,进行情报的挖掘、信息的二次加工显得尴尬且必须,这对数据生产中的各个环节的监控提出了更高的要求:
1、 在数据获取端引入评分和审核机制
数据获取端还有一道前序操作,即数据的生产控制,这一部分质量和可靠性的把控需要由发布平台的机构进行控制,但由于这一措施需要将用户进行创作限制,并可能会因此引起部分用户的抵触,还需为事先制定出发布规范和惩罚措施,这一控制需要花费大量的人力物力。有代表性的,如学术论文的写作、众包环节下的Wiki百科编辑等都是这一工作的典型代表。
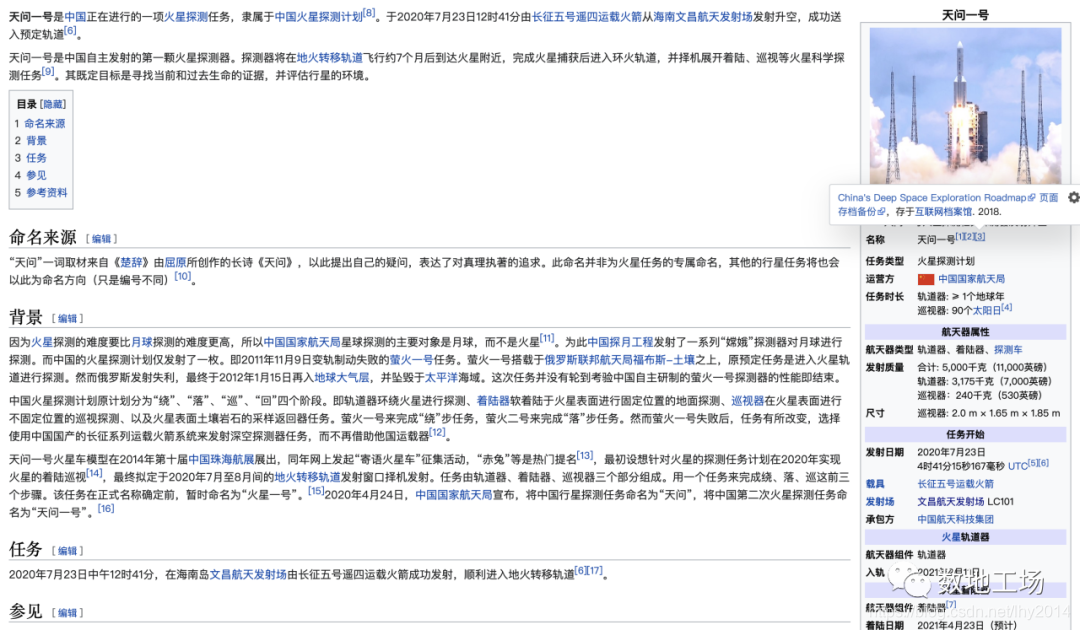
图2-Wiki百科中对知识信息的来源控制
在数据生产环节之后,许多数据获取方式都具备限制性。这主要体现在对数据源的考虑上,在实际的业务场景中,需要充分考虑网站的权威性(从发布主体性质、发布主体的发布行为)、网站的安全性、网站来源的数据规模等多个因素。典型地,在具体实施的过程中,会请相关业务专家通过对网站的建模结果中对网站进行打分,并从中选择得分较高的数据源(若国家政府部门、意见领袖等)作为目标数据源,或者将得分作为一个知识置信度计算因子融入到结构化知识的打分模型当中。
2、 在抽取环节加入知识校验和过程数据关联组件
知识抽取是对信息进行挖掘,也是保证知识准确性和可靠性最关键,也是难度最大的环节,主要体现在对原始真实内容的还原、数据内容真假性甄别、数据内容的算法抽取可靠性三个方面。
首先,对原始真实内容的还原,指的是对所获取到的多源异构文本的内容处理上。在工业场景中,会经常遇到图片型pdf、文本型pdf、docx、ppt、纯文本等文本格式,mp3、wav等音频格式,mp4、rmvb等视频格式,如何通过格式转换、版式分析以及文字流转写等方式将原始文本中的信息准确、完整的整理输出,十分重要。例如,进行pdf处理过程中,常处理表格合并、段落合并,网页文本处理中常需要处理噪声标签的干扰去除等,OCR处理中常常存在偏差,这都使得原始真实内容上存在误差。
在这里插入图片描述
图3-pdf文档内容还原中的表格问题
其次,针对数据内容真假性甄别,是在进行原始内容抽取后需要准确处理的一道工序。在数据内容真假上,存在通过人工构造谎言和谣言数据集进行训练,形成分类模型的工作,但这一工作受限于训练语料的规则,效果会受到很大限制。
另一个工作是真假性核查的工作,例如,在进行金融文档核查过程中,借助数据指标知识、跨篇章文本之间的关联关系等外部消息,以及内部文本上下文之间的勾稽关系对内部文本的准确性进行核查,也可以引入成立性规则与外部常识知识库的方式进行准确性校验。
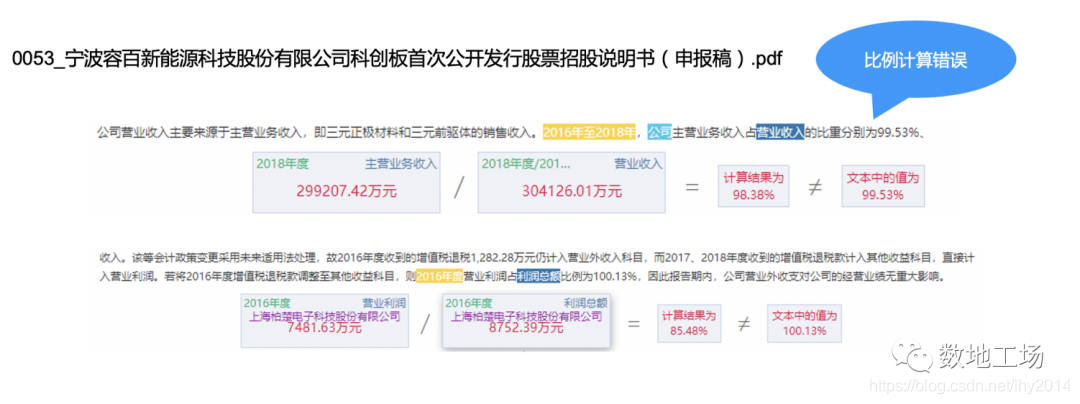
图4-pdf文档真实性审查中的数据真实性校验
最后,在数据内容的算法抽取可靠性的把控上,引入迭代模型,实现递增式学习,在抽取过程中,充分重视人机协作的方式,开发各类的数据观察工作、数据校验工具、错误归因工具、错误解释工具以及回归测试工具等,使系统可配置。同样地,过程文本数据也重要,在算法进行知识抽取的环节中,应该将该结构化知识来源的各项元数据信息进行记录和关联,这一关联的操作能够给后续的业务开展留出较高的可扩展性和灵活性。
3、 在业务端调整知识交互形式与用户反馈接口
知识交互形式与用户反馈接口的建立是业务端进行调整的一个可行方向,虽然这在具体实施上会因业务而异。知识的可靠性、实时性和全面性是制约知识应用的重要因素,在充分承认现有自然语言处理知识抽取技术还不成熟的现实条件下,需要在技术现有情况和用户需求这一天平中选择一个平衡点,即在用户端和产品展示端之间的一个信任支点。
将抽取过程、展示过程以及推理决策过程透明化是取信用户的一条可行方式,这与现在知识可解释性上存在某种关联。例如,在结构化搜索场景中,将已给出结构化知识的关联来源信息、评分信息进行关联展示,并让用户参与对评分或结果的标记,这能够使得这层信任逐步建立起来。采用这种人机协作,机器负责推荐并透明化,用户负责对结果进行自行判定和干预,无论对于系统自身,还是对于业务的推进来说,都是大有裨益的。
三、基于多环节可信知识溯源的大规模实时事理学习系统
知识溯源是有效减轻当前输入数据源不准确的重要途径,从底层数据获取中引入数据源的评分机制,并使用可解释程度高的语言资源和处理组件,在多环节中确保知识可信。
数据地平线一直致力于可信的底层语言资源建设。一方面,我们建成了可信度较高的基础语言知识库,包括几十个种类的领域词典、词法和句法规则库、基础知识图谱等。其中,同义知识库、概念知识库、抽象知识库、事理知识库等知识库已部分对外开放。另一方面,我们建设了可信知识抽取过程中所需要的自然语言处理平台,如数地工场。

图5-可信模式下的知识处理平台-数地工场
基于可信的基础语言知识库和文本处理组件,我们在大规模实时事理学习系统“学迹”中引入了动态知识可溯源的展示模式。其核心思想在于:在返回用户所检索字符串关联知识的基础上,从知识可信度评分、知识存现出处(句子级)两个角度,结合动态友好的交互方式,做到“来源可查”、“可信量化”、“精确到句”、“一触即达”。如下图所示,给出了“新冠肺炎疫情蔓延”在基于开源情报数据中得到的结构化事理知识的结果。
在这里插入图片描述
图6-学迹搜索结果中的知识实证截图
为此,数据地平线为此设计了一套可靠的知识可信度评分算法。随着信息源不断增加,先前学习到的知识的可信度会被不断更新,错误结果的权重被自动纠正,根据可信度排序,可以看到“学迹”最有把握的知识。
同样,数据地平线尝试了一种友好的方式来最大化地展示事理学习的动态过程。我们用连线和层级表示的方式,为每条知识都提供可视化的学习实证,从中可以看到知识的创造者、知识的创造时间、知识出现的上下文,知识学习来源的评分。
四、人机协作和实证模式下的投研逻辑管理平台
数据地平线在金融事理图谱以及金融领域的业务和技术沉淀,推出了一款基于人机协作和实证模式的投研管理平台“投研云图”。
投研云图平台是一款面向投资研究人员的逻辑图谱创建、管理和研究工具,通过结合大规模数据采集技术,事理逻辑抽取、知识图谱、情感分析等自然语言处理技术以及用户可视化交互等技术,以机器智能推荐辅助、人工自定义编辑相结合的人际协作交互方式,从而支持投资逻辑图谱的创建、共享、管理、应用等服务。
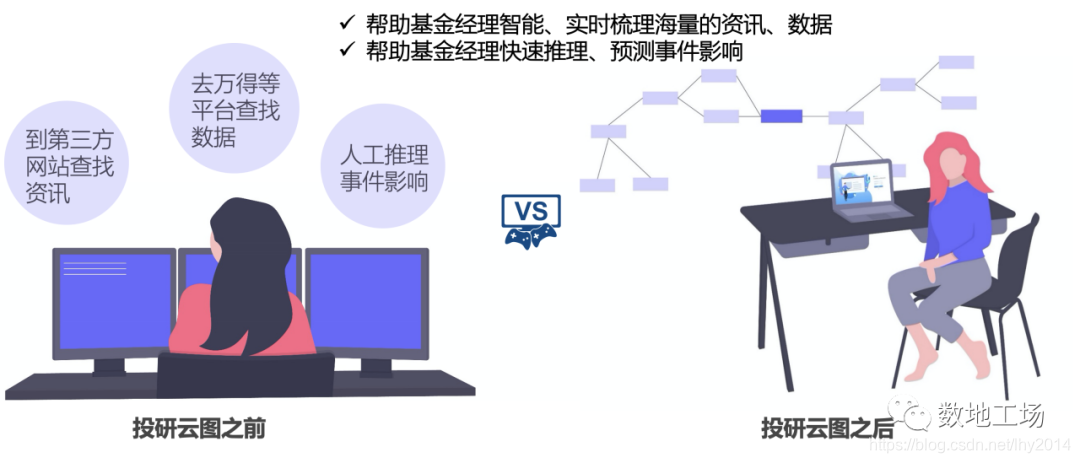
图7-投研云图的用户场景截图
“人机协作”和“知识实证”是投研云图思想的两个基本核心点,从消息面和数据面两个角度出发,完成研究逻辑的自管理。在具体实现上:
首先,在底层可信知识的构建环节,依托后台面向开源情报挖掘形成的事理图谱、产业链图谱数据,也可根据用户自定义自有文本,自动挖掘形成相关结构化知识,完成海量实证逻辑知识自动构建。
其次,在人机交互方式的逻辑链条构建环节,基于事理图谱知识库,结合底层推荐组件,以实证的方式推荐给用户,并使得用户可以根据自己的主观判断,结合关联的实证信息,快速地完成事件、行业数据、产业链三个层面的推荐,完成基于海量实证逻辑知识库的潜在事件推荐和行业数据推荐。
最后,在利用人机交互完成逻辑知识库的自动构建之后,可实现基于海量实证逻辑知识库的历史实证展示、基于自建领域事理的逻辑监测等多个功能。
投研云图平台的核心目标是构建一个以现有自然语言处理技术为核心的机器智能辅助、人工编辑为主的领域逻辑知识管理的监测预警平台,以满足各行业逻辑知识的创建、积累和管理。知识的可信、可控、通过实证方式辅助用户进行自查、自管理是其中的核心。
五、总结
支撑目前自然语言处理相关落地产品的数据来源,大多来自开源信息情报、门户网站、各大垂直网站、论坛社区、“两微一条”、政府报告、研究报告、政策公告、百科问答等公共数据,这为舆情监控、事件热点挖掘、智能问答、文本生成、知识图谱可视化、风险推理等多个落地应用带来了诸多挑战。
为了应对这一挑战,从经验上来说,可以在数据获取端引入评分和审核机制,在抽取环节加入知识校验和过程数据关联组件,对原始真实内容的还原、数据内容真假性甄别、数据内容的算法抽取可靠性等三个方面作相应工作。
数据地平线充分认识到了“可信知识实证”的重要性,并在底层知识库构建、自然语言处理组件开发、产品应用上引入了可信知识溯源的思想,探索形成了多个可信语言资源库、知识抽取平台、大规模事理学习系统、投研逻辑管理平台。
在大规模事理学习系统“学迹”中,数据地平线设计了一套可靠的知识可信度评分算法,并尝试了一种友好的方式来最大化地展示事理学习的动态过程。
投研逻辑管理平台“投研云图”以现有自然语言处理技术为核心的机器智能辅助、人工编辑为主进行领域逻辑知识管理的监测预警,知识的可信、可控、通过实证方式辅助用户进行自查、自管理是其中的根本核心点。
参考
1.数据地平线:https://datahorizon.cn
2.数地工场:https://nlp.datahorizon.cn
3.学迹:https://xueji.datahorizon.cn
4.投研云图:https://yuntu.datahorizon.cn
5.https://zh.wikipedia.org/wiki/天问一号
If any question about the project or me ,see https://liuhuanyong.github.io/.
如有自然语言处理、知识图谱、事理图谱、社会计算、语言资源建设等问题或合作,可联系我:
1、我的github项目介绍:https://liuhuanyong.github.io
2、我的csdn技术博客:https://blog.csdn.net/lhy2014
3、我的联系方式: 刘焕勇,中国科学院软件研究所,lhy_in_blcu@126.com.
4、我的共享知识库项目:刘焕勇,数据地平线,http://www.openkg.cn/organization/datahorizon.
5、我的工业项目:刘焕勇,数据地平线,大规模实时事理学习系统:https://xueji.datahorizon.cn.
6、我的工业项目:刘焕勇,数据地平线,面向事件和语义的自然语言处理工具箱:https://nlp.datahorizon.cn

)
:JVM+高并发性能+单点登录+微服务)



按位输入))
大数据进展如何?)





)
,面试58题实拍!)




