论文笔记整理:余海阳,浙江大学硕士,研究方向为知识图谱、自然语言信息抽取。

链接:https://www.aaai.org/Papers/AAAI/2019/AAAI-GaoTianyu.915.pdf
动机
现有的关系分类方法主要依赖于远程监控(DS),因为目前还没有大规模的监控训练数据集。虽然DS自动标注了足够多的数据用于模型训练,但是这些数据的覆盖范围仍然相当有限,同时很多长尾关系仍然存在数据稀疏的问题。另外直觉上说,人们可以通过学习很少的实例来掌握新的知识。因此我们通过将RC问题形式化为一个少样本学习(FSL)问题,给出了一个不同的RC观点。然而,目前的FSL模型主要针对低噪声的任务,难以直接处理文本的多样性和噪声。在本文中,我们提出了一种基于混合注意力机制的原型网络来解决含噪的少样本RC问题。我们设计了基于原型网络的实例级和特征级注意方案,分别突出了关键的实例和特征,显著提高了RC模型在含噪FSL场景中的性能和鲁棒性。此外,我们的注意方案加快了RC模型的收敛速度。实验结果表明,我们的基于注意力混合模型需要更少的训练迭代,并且优于最先进的基线模型。
亮点
文章的亮点主要包括:
(1)提出了一种基于混合注意力机制的原型网络来处理含噪的少样本关系分类任务,实例级的注意力强调与查询有关的实例,特征级注意力减轻了少样本稀疏性的问题;
(2)训练时相比其他FSL模型收敛得更快。
相关工作
一.少样本的关系分类:
关系分类是信息提取中重要的任务,对下游NLP领域如机器翻译、阅读理解、常识推理等都有帮助。然而传统的关系分类任务需要大量的监督数据,人为打标的方式成本又是十分昂贵的。虽然之后提出的远程监督方法打标的方式可以快速构造大量的监督训练数据,但是这样构建的数据集噪音太大,对关系分类的准确率影响很大。直觉上说,人们可以通过学习很少的实例来掌握新的知识。因此我们通过将关系分类形式化为一个少样本学习问题,给出了一个不同的视角解决关系分类。
少样本学习(FSL)允许模型在数据不足的情况下学习高质量的特性,而不需要添加像远程监督这样构建的大规模数据集。许多研究者将迁移学习方法应用于FSL的预训练-微调模型,该模型将潜在的信息从包含足够多的常见类中转移到只有很少实例的不常见类。另外度量学习方法提出了学习类间距离分布的方法,其中相同类在距离空间上是相邻的。最近,元学习的概念被提出,它鼓励模型从以前的经验中学习快速学习能力,并迅速推广到新的概念中。
在这些模型中,原型网络实现简单,训练速度快,在多个FSL任务上都达到了最先进的结果。它计算每个类的原型类型,并通过计算它们的欧式距离对查询实例进行分类。我们提出的方法是基于原型网络的。近年来,虽然少样本学习发展迅速,但大部分工作集中在CV的应用上。流行的FSL数据集Omniglot和mini-ImageNet 都是为CV应用程序设计的。然而关于采用FSL进行NLP任务的系统研究还很少。
二.原型网络:
如图为原型网络求解少样本关系分类任务的原型方法。原型网络的直觉比较简单,它假设在语义空间中具有相同类的实例是相互靠近的,靠近的中心点就是每个关系的原型。样本通过学习投影到语义空间中,并且让相同关系的样本尽可能靠近,在通过求均值的方法直接求出每个关系的原型。查询样本所属的关系通过求解样本与每个关系的欧式距离,距离最近的就是该查询样本所属的关系。
模型
文中设计的混合注意力机制的原型网络模型如下:
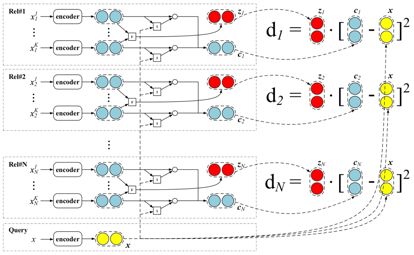
基本模型主要包括:
(1)样本实例编码:输入的每个实例句子,计算每个词语的word embedding和相对两个实体的positionembedding,将两个embedding拼接起来后输入到CNN网络中再做最大池化,输出的结果就是每个实例句子的编码信息。
(2)原型网络计算原型:原始的原型网络计算原型的方法是在suppprt set中求实例句子的平均值作为每个关系的原型。我们任何原型网络求解原型的思想,但是直接求平均的方法对每个输入样本的权重默认为相同值,这样当输入样本很少时,并且样本中带有噪音的情况下会明显影响原型的求解。
(3)样本实例级的注意力机制:基于上面所说,在少样本学习中若是训练过程样本带有噪音会明显影响原型的求解。我们提出了样本实例级的的注意模块,将更多的注意力放在与查询相关的实例上,减少了噪声的影响。我们将求解原型的公式从 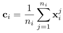 修改为
修改为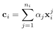 ,其中αj定义为
,其中αj定义为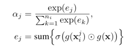
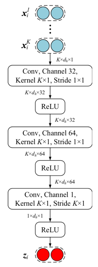
(4)特征级的注意力机制:原始的原型网络使用简单的欧式距离作为距离函数。由于少样本学习中支持集中实例较少,从支持集中提取的特征存在数据稀疏的问题。因此,在特征空间中对特殊关系进行分类时,某些维度具有更强的区分能力。我们提出了一种基于特征级的注意方法,以缓解特征稀疏性问题,并以更合适的方式测量空间距离。我们将公式 d(s1, s2) = (s1-s2)2 修改为d(s1,s2) = zi *(s1-s2)2,其中zi通过下图的特征级注意力提取器计算的。
实验
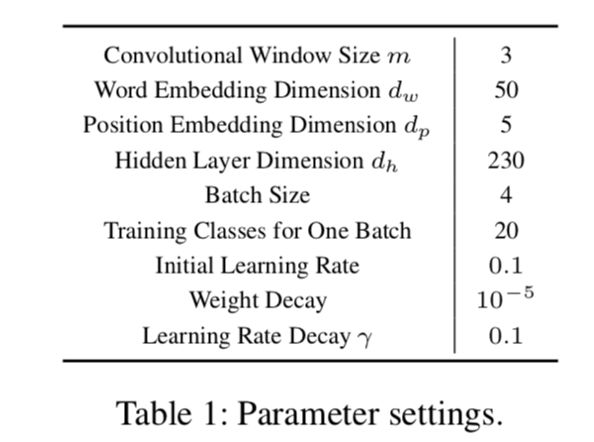
我们在FewRel数据集上评估我们的模型,这个数据集一共有100个关系,每个关系700条句子。另外为了证明模型在含噪数据上的鲁棒性,我们人为的设置了含噪数据:0%、10%、30%、50%。其他超参数设置如下:
具体实验结果如下表所示:
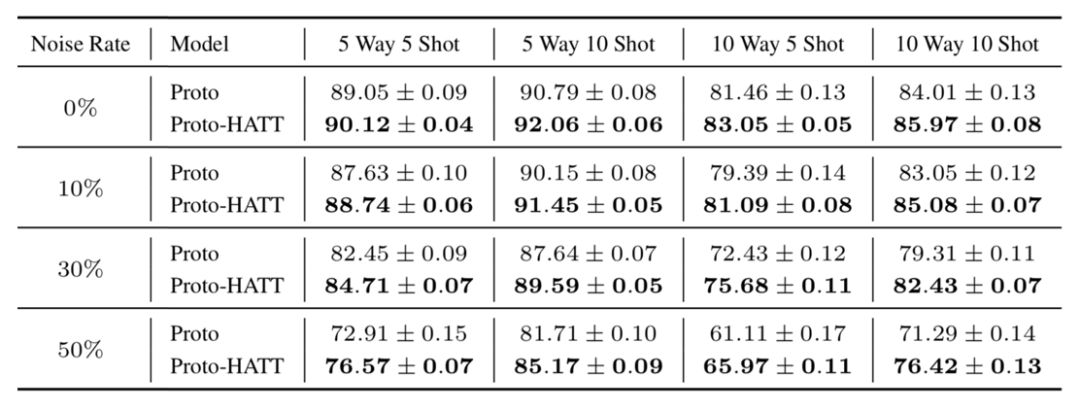
上表报告了在不同实验设置下对测试集的混合注意力和不混合注意力的原型网络的准确性。我们将原始的原型网络命名为“Proto”。“Proto- IATT”、“Proto- FATT”和“Proto- HATT”分别是实例级、特征级和混合注意的模型。从表中我们可以发现,我们的混合注意力为基础的原型网络在面对噪声数据时更加健壮。随着噪声率的提高,我们提出的模型的优点变得更加明显。
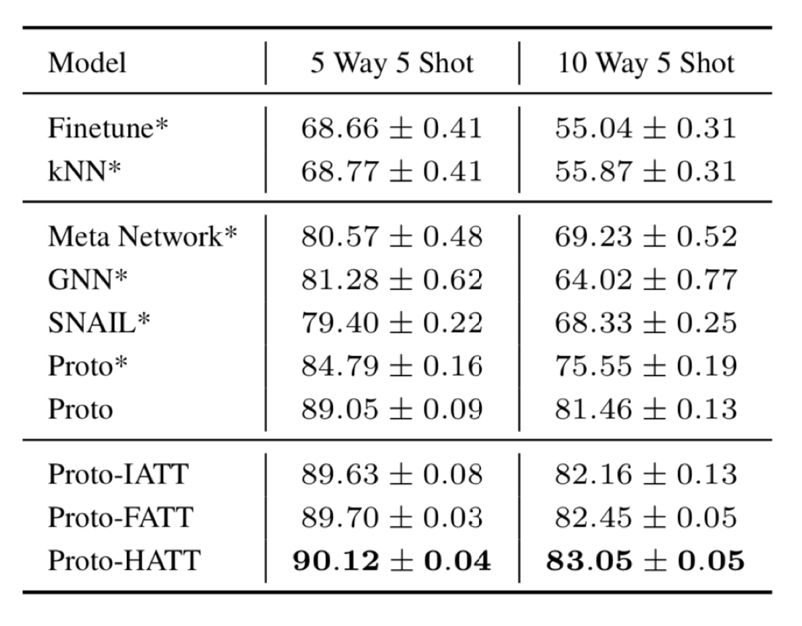
通过对实例和特征的混合关注和不同的评分,我们的模型知道在训练时应该关注实例和特征的哪些部分,同时捕获正确的反向传播路径。这有助于模型抵御数据噪声的不利影响。我们的模型在干净数据上甚至比基线做得更好,这证明了混合注意力在处理干净数据的少样本学习任务中也是有用的。我们并与其它FSL模型和RC模型进行了比较。对于RC模型,我们采用Finetune或kNN等简单的少样本模型方法对RC模型进行综合评价。对于FSL模型,我们对比了Meta Network (Munkhdalai and Yu 2017)、GNN (Garcia and Bruna 2018)和SNAIL(Mishraet al. 2018),这些都是目前最先进的FSL模型。如表所示,我们的两个注意力模块都提出了改进性能的方法,我们提出的基于注意的混合方法取得了最好的效果。
总结
在本文中,我们提出了一种基于混合注意力的原型网络来完成含噪的少样本关系分类任务。我们的混合注意力机制由两个模块组成,一个实例级的注意力突出了与查询相关性更高的实例,另一个特征级的注意力机制减轻了特征稀疏性的问题。在我们的实验中,我们评估了我们的模型在几个随机噪声设置和少样本设置,表明了我们的混合注意力机制FSL模型显著提高了鲁棒性和计算效率。我们的模型不仅达到了最先进的结果,并在有噪声的数据中表现得更好,而且在训练时收敛得更快。在未来,我们将探索将我们的混合注意方案与其他FSL模型相结合,并采用更多的神经编码器使我们的模型更通用。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。
:如何从0到1设计一个消息队列中间件)
)




:详解RocketMQ的架构设计、关键特性、与应用场景)
)

+python读写文件txt +文本数据预处理)




)

![lambda函数+map函数的结合使用 list(map(lambda x: list(x)[0], X))](http://pic.xiahunao.cn/lambda函数+map函数的结合使用 list(map(lambda x: list(x)[0], X)))


