本文转载自公众号:AI前线。
 作者 | Diego Ongaro,Simon Fell 译者 | 盖磊 编辑 | Natalie AI 前线导读:eBay 工程人员于 5 月 1 日在 官方技术博客 上发布了开源的分布式知识图谱存储 Beam,Beam 实现了事实数据的 RDF 存储,并支持类 SPARQL 查询。
作者 | Diego Ongaro,Simon Fell 译者 | 盖磊 编辑 | Natalie AI 前线导读:eBay 工程人员于 5 月 1 日在 官方技术博客 上发布了开源的分布式知识图谱存储 Beam,Beam 实现了事实数据的 RDF 存储,并支持类 SPARQL 查询。Beam 是一种分布式知识图谱存储,以 Apache 2.0 开源许可发布。Beam 历经四人年(person-year)的工程探索和开发,提供了大量值得关注的新特性!此博客文章将介绍 Beam 及其实现,并阐述我们选择开源 Beam 的原因。
Beam 实现了分布式知识图谱存储Beam 是一种知识图谱存储,也可称为 RDF 存储或三元组存储。知识图谱适合建模世界知识百科这样通过复杂关系高度互联的数据。例如,Wikidata 是一种以结构化数据和关系表示维基百科的数据集,非常适合于知识图谱表示。知识图谱存储支持对数据执行多样性查询,提供实时数据接口、辅助机器学习应用,以及基于现有知识理解非结构化的新信息。
在知识图谱中,数据以单一表模式表示事实。每个事实条目包括主体(Subject)、谓词(Predicate)和客体(Object)三个元素。这种事实条目表示方式,支持存储根据复杂查询灵活组织数据,并通过推理提高数据的抽象层级。下表列出了小部分知识图谱的表示。
| 主体 | 谓词 | 客体 |
|---|---|---|
| <John_Scalzi> | <born> | <Fairfield> |
| <John_Scalzi> | <lives> | <Bradford> |
| <John_Scalzi> | <wrote> | <Old_Mans_War> |
Beam 使用类似于 RDF 的数据表示,并支持类 SPARQL 查询语言。Beam 对数据表示和查询支持的详细信息,参见项目 GitHub 代码库提供的 docs/query.md。
Beam 实现为分布式存储,在设计上支持无法被单一服务器有效存储的大规模图。Beam 可通过水平扩展支持高性能查询和大规模数据集。虽然 Beam 的写入速度无法扩展,但其部署通常可支持每秒数万次数据更改。我们已运行由 20 台服务器组成的 Beam 部署和离线用例近一年时间,通常情况下已加载了 25 亿条事实数据。尽管我们并未对 Beam 做压力测试,但我们相信 Beam 的性能远超当前的容量和规模。
Beam 的架构Beam 的架构如图一所示,其架构围绕一种中心化日志构建,图中每个框图表示了分布式网络中的一个独立进程。中心化日志并非一个新概念,已在 Tango 等系统使用,但并未得到普遍重视。Beam 中,所有的写入请求排序写入一个只添加的中心化日志。日志作为网络服务,在分布式系统内部多次复制,实现容错和持久化。多个视图服务器(view server)分别读取日志,顺序应用其中的条目,并确定性地更新各服务器的本地状态。因此,不同的视图服务器维护着不同的状态。API 层接收来自客户的请求,将写入请求附加到日志中,并从视图服务器获取数据以响应读取请求。
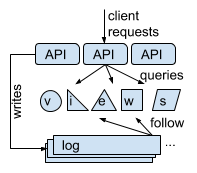
图一 Beam 的中心化日志架构
中心化日志在本质上存在一个瓶颈问题,即日志附加的最大速率决定了整个数据集更新的最大速率。另一方面,中心化日志简化了很多特性的实现,例如跨分区交易、一致性查询和历史全局快照、复制、数据迁移、集群成员管理、分区和数据集的多方式索引等。详细信息,参见项目 GitHub 代码库提供的 docs/central_log_arch.md。
Beam 的详细实现如图二所示。其中,日志接口采用模块化设计。Beam 当前推荐使用 Apache Kafka 实现日志,支持新日志在确认前持久化写入磁盘的配置。Beam 已提供了一种称为“DiskView”的单视图实现。DiskView 支持以两种运行模式,即分别根据知识图谱事实条目的“主体 - 谓词”和“谓词 - 客体”组合构建索引。典型的 Beam 部署将对每种模式各建立三个基于多划分的副本。DiskViews 使用同样支持模块化的 RocksDB 存储事实条目。API 服务器提供复杂的查询处理器,我们将在下面详细介绍。Beam 提供称为事务计时器的轻量级进程。在 API 服务器出现故障而导致事务处理缓慢时,事务计时器将对事务做超时处理。
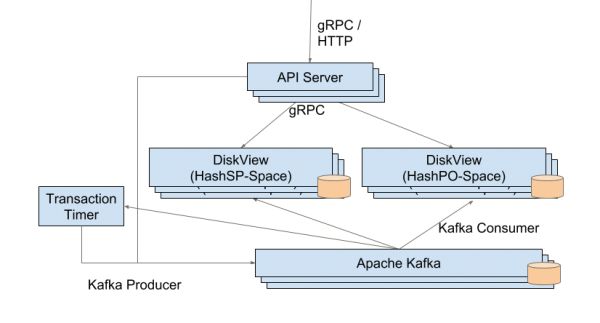
图二 Beam 的详细实现结构图
API 服务器提供了丰富的功能,难以用一个简单的框图表示。API 服务器中实现了整个查询处理器,如图三所示。Beam 的查询处理器实现了一种类似于 SPARQL 子集的查询语言,语法类似于 SQL 语句,但适用于知识图谱查询。查询处理器包括解析器、基于代价的查询规划器和并发执行引擎。解析器将初始查询语句解析为抽象语法树(AST)。查询规划器为抽象语法树添加数据统计信息,进而给出高效的执行计划。查询执行引擎运行执行计划,使用批处理和留处理方式实现高性能查询。执行引擎基于 View Client/RPC Fanout 模块,从多个视图服务器高效获取数据。详细信息,参见项目 GitHub 代码库提供的 docs/protobeam_v3.md。
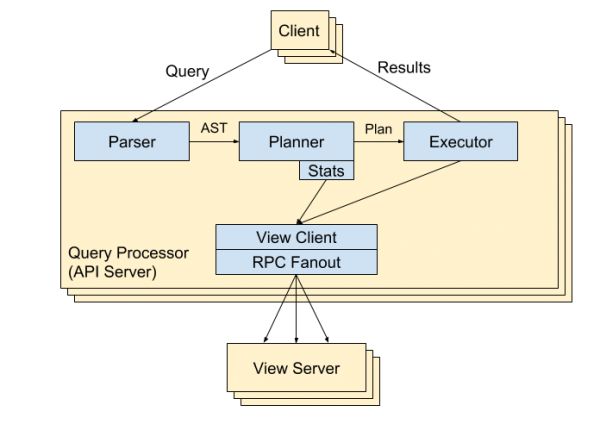
图三 Beam 的查询处理器结构
我们为什么选择开源 Beam我们从 Beam 的实现中获得了大量经验教训。最初,我们从头开始构建了一种 基于内存的键值存储(即 ProtoBeam 第一版),随后迭代更新为 基于磁盘的属性图存储(即 ProtoBeam 第二版),进而实现了 知识图谱存储 (即 ProtoBeam 第三版)。之后,我们将原型系统工程化实现可用于生产环境的代码、完善文档、开展测试并审核代码。在此过程中,我们在工程上做了一些有益的取舍,撰写了大量详细的阶段性文档,阐述了我们的考虑随时间演进的情况。总体情况和详细信息,参见项目 GitHub 代码库提供的 docs/README.md。
尽管 Beam 项目已取得了很大进展,但不幸的是我们无法继续全职投入其中,难以独力将其实现为我们希望看到的完备系统。我们仍然认为,Beam 时一个非常值得关注的项目,具有很好的基础,可服务于他人:
尽管我们的目标是实现可部署于生产环境中的 Beam,但许多用例不需要生产层级的服务。Beam 已可以很好地支持一些离线、非关键或研究型应用。
Beam 可受益于他人的贡献。我们很高兴看到 Beam 项目由于他人的贡献而继续推进。如考虑做出贡献,可详览 GitHub issues。
即便不考虑整体使用 Beam,该项目提供的许多内部软件包也可用于其它一些项目中,例如其中的 fanout 和 查询规划器 模块。
最后一点,Beam 也是一个非常适于他人从中学习的项目。它提供了很好的中心日志架构参考,也是一个具有相当规模的 Go 项目。
我们希望大家关注 Beam 项目,不吝指教。欢迎提出软件缺陷、特性需求,并以 GitHub Issues(https://github.com/eBay/beam/issues) 方式提出问题。
查看英文原文:
https://www.ebayinc.com/stories/blogs/tech/beam-a-distributed-knowledge-graph-store/
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客




)

,基于bow_pairwise模式及框架原理介绍)

)





)




)