原文链接:https://www.sohu.com/a/336251713_610300
有人做出了中文版GPT-2,可用于写小说、诗歌、新闻等;15亿参数版GPT-2被两名研究生复现
</div>
原标题:有人做出了中文版GPT-2,可用于写小说、诗歌、新闻等;15亿参数版GPT-2被两名研究生复现
乾明 发自 凹非寺

GPT-2,逆天的语言AI模型,编故事以假乱真,问答翻译写摘要都行。
问世之后横扫各大语言建模任务,引发了大量关注以及研究者跟进研究。
之后,围绕着GPT-2产生了各种实用性应用:比如;高中生等等。
现在,又有两个围绕这一语言AI模型的成果出现。
- 一是中文版GPT-2开源(非官方),可以写诗,新闻,小说、剧本,或是训练通用语言模型。
- 二是,两名硕士研究生花5万美元复制了OpenAI一直磨磨唧唧开源的15亿参数版GPT-2。
GPT-2发布以来,虽然关注甚多,但在中文语境中的应用非常少。
最直接的因素,就在于没有中文版,或者说是没有人基于中文语料去大规模复现。
现在,有人这样做了。
一位名叫”Zeyao Du“(位于南京)的开发者,在GitHub上开源了的GPT-2 Chinese。
可以用于写诗、新闻、小说和剧本,或是训练通用语言模型。
项目中默认使用BERT的tokenizer处理中文字符,支持字为单位或是分词模式或是BPE模式,并支持大语料训练。
目前项目主要架构已经稳定,具体的训练语料,作者也附上了相应的链接:
大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP
https://github.com/brightmart/nlp_chinese_corpus
中文文本分类数据集THUCNews
http://thuctc.thunlp.org/#%E8%8E%B7%E5%8F%96%E9%93%BE%E6%8E%A5
效果如何,大家可以自己感受下:
下图是他们使用较大规模训练后自由生成的文本。其中模型参数约80M,机器为四个2080Ti,训练步数140万步,语料3.4G,Batch Size 8。

下图是他们生成的斗破苍穹样例。模型参数约为50M,Batch Size 32,语料库为16MB斗破苍穹小说内容。

△[SEP]表示换行。
斗破苍穹语料:
https://github.com/GaoPeng97/transformer-xl-chinese/tree/master/data/doupo
下图是限定了生成体裁后的古诗歌生成样例(来自GitHub开发者@JamesHujy),参数未说明:

GPT-2 Chinese项目传送门:
https://github.com/Morizeyao/GPT2-Chinese
15亿参数版GPT-2
能够实现逆天效果GPT-2模型,用到了15亿个参数。
在发布这一模型的时候,OpenAI说,这个模型实在太厉害了,要慢慢开源。
于是就开始了“挤牙膏”开源之旅,从今年2月到现在,才开源到了7.74 亿参数版本。
这一路上,有不少人都表示非常难以忍耐。
比如慕尼黑工业大学的一名大三本科生,在两个月的时间里,付出了200个小时的时间,花费了大约6000人民币,复现了GPT-2项目,并在7月初放出了15亿参数的版本。
至于效果如何,并没有太多展示,项目链接:
https://github.com/ConnorJL/GPT2
现在,又有人忍不住了。
有两名布朗大学的硕士研究生,搞出了一个15亿参数的GPT-2模型,命名OpenGPT-2,还放出来了效果对比。
Google Colab地址:
https://colab.research.google.com/drive/1esbpDOorf7DQJV8GXWON24c-EQrSKOit
模型权重:
https://drive.google.com/drive/u/0/folders/1KfK5MXtvgH8C615UUZoKPIUVJYIdJxX1
搞出来之后,他们在博客中说,其实想要复制GPT-2并不难,绝大多数感兴趣的人都可以复制。比如,他们就可以复现论文中的很多结果,而且并没有语言建模的经验。
当然,得有钱。他们完整复制出来,花了大约5万美元,还只是云端训练成本。
具体的复制难点有两个,一是模型,二是数据。
模型上面,他们基于Grover模型,并对代码库进行修改,来实现GPT-2的语言建模训练的目标。
Grover模型论文地址:
https://arxiv.org/abs/1905.12616
因为Grover的模型是在类似的大型语料库上训练的,所以很多代码和超参数都可以重复使用。他们并没有大幅改变其中的超参数。
数据集方面,在很大程度上都保证了与OpenAI的处理方式相同,但并不能保证其中细节相同,最后得出了数据集OpenWebTextCorpus:
https://skylion007.github.io/OpenWebTextCorpus/
如此做出来的模型,效果如何?从定量维度上来看,在多个数据集上困惑度都与GPT-2原版接近:
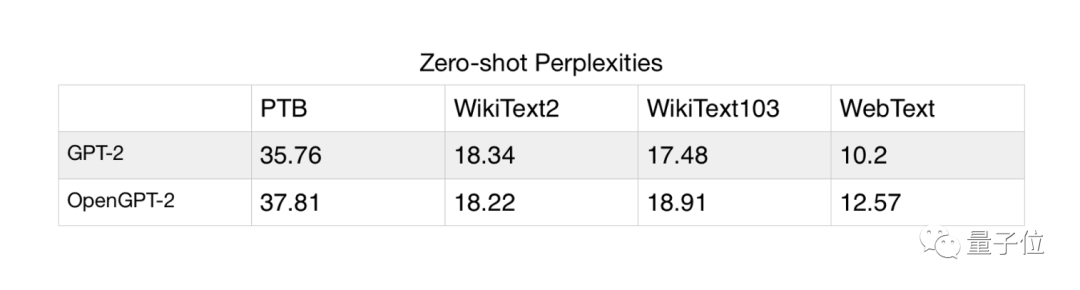
定性维度上,就仁者见仁智者见者了,在Reddit上有人支持,但也有人觉得他们的模型效果不好。
这两位硕士研究生,也在博客中放了一个与官方GPT-2一样的案例:
给出 “Recycling is good for the world. NO! YOU COULD NOT BE MORE WRONG!!”的提示。
复制版OpenGPT-2给出的结果如下:
That´s because recycling is all about selling to customers who cannot afford to recycle. If you don’t have any interest in recycling, in whatever form, then you could well be doing your own global environmental benefit if you just got rid of it.
Let me explain. Recycling takes time, money and energy, and it doesn’t really solve the problem.
If you go to recycling drop-off shops and they just sort out your recyclables for you then it means there is no need to sell them again to the local recycling company; they just take it back from you and you can just dump it.
There is nothing clever about this approach, in fact it just shuffles the problem around instead of solving it.
……
更多内容,可以前往两位研究生的博客文章中查看:
https://medium.com/@vanya_cohen/opengpt-2-we-replicated-gpt-2-because-you-can-too-45e34e6d36dc
官方原版的GPT-2,给出结果如下:
Recycling is NOT good for the world. It is bad for the environment, it is bad for our health, and it is bad for our economy. I’m not kidding. Recycling is not good for the environment. It is destructive to the earth and it is a major contributor to global warming.
Recycling is not good for our health. It contributes to obesity and diseases like heart disease and cancer. Recycling is bad for our economy. It increases the cost of a product, and in turn, the price of everything that is made with that product.
Recycling is not good for our nation. We pay a tremendous price for the privilege of having the world’s most advanced and efficient recycling system. Recycling is a huge, colossal waste of time, energy, money, and resources.
And THAT is why we need to get back to basics and get back to basics in our recycling efforts. One of the best ways to start is to look at the process of creating a paper product.
……
更多内容,可以前往OpenAI博客中查看:
https://openai.com/blog/better-language-models/#sample8
你觉得模型效果如何?返回搜狐,查看更多
责任编辑:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/479693.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

一份来自清华的数据分析笔记,请查收!

LeetCode 9. 回文数


transformer xl在文本生成上面的应用
:Redis为什么是单线程、及高并发快的3大原因详解)
Redis系列教程(四):Redis为什么是单线程、及高并发快的3大原因详解

Bing与DuckDuckGo搜索结果惊人一致?Google展现强势差异



springboot(ssm在线互动学习网站 在线课程管理系统 Java系统

java程序员学习路线以及我的学习经验


这几个模型不讲“模德”,我劝它们耗子尾汁
:深入详解Synchronized同步锁的底层实现)
Java多线程系列(六):深入详解Synchronized同步锁的底层实现

LeetCode 89. 格雷编码

清华CrossWOZ,助你徒手搭建任务导向对话系统


分布式数据层中间件详解:如何实现分库分表+动态数据源+读写分离

清华硕士眼中的2021届算法岗秋招
)
LeetCode 124. 二叉树中的最大路径和(DFS)
)