论文笔记整理:谭亦鸣,东南大学博士。
来源:WSDM ’20
链接:
https://dl.acm.org/doi/pdf/10.1145/3336191.3371812
1.介绍
知识图谱问答旨在利用知识图谱的结构化信息回答以自然语言提出的问题。当面对多关系问题时,现有基于embedding的方法所采用的构建主题实体子图策略会导致较高的时间复杂,同时,由于数据标注的高成本,精确地给出回答复杂问题得每一步过程是不切实际的,并且只有最终的答案被标注的情况,是一种弱监督。
为了解决上述问题,本文提出一种基于强化学习的神经网络模型,命名为Stepwise Reason Network,该模型将多关系问答视作一个顺序决策问题,通过在知识图谱上做有效路径搜索来获取问题的答案,并利用柱搜索显著减少候选路径的规模。同时,基于注意力机制以及神经网络的策略网络(policy network),能够增强给定问题的不同局部对于三元组选择的影响。
此外,为了缓解弱监督导致的延迟以及奖励稀疏问题,作者提出了一种potential-based的奖励构成方案,用于帮助加快模型训练的收敛速度。
三个benchmark上的实验结果显示,该模型展现出了目前最好的性能。
2.模型
首先,对本文使用的强化学习过程进行说明,该过程包括四个部分:
State,在每个时间节点t,State St= (q, es, et, ht)∈S,其中es表示给定问题q的topic entity,
et表示在时间t时,通过从es出发的path search访问到的实体(visited entity),表示到时间t时,Agent做出的前置决策集。q以及es可以被看做全局信息
Action,在每个时间节点t上的候选action集都基于St得到,A(St)由et在图谱G中所有向外的边组成,A(St) = {(r, e) | (et, r, e)∈G}
Transition,在Action的设定下,状态的转移概率是确定的,且转移过程完全基于知识图谱G,一旦agent选择了action At = (r*,e*),状态将会变为St+1 = (q, es, e*, ht+1)
Reward,reward是由environment传递给agent的特殊信号,表明了agent的目的。一般而言,强化学习的每一步都会得到一个reward,而学习的目的是最大化reward的总数。但是在多关系问答的弱监督场景下,对于每个问题仅最终答案被标注,这使得agent到达正确答案时,只能收到一个积极的最终reward,接下来前置的所有步骤才会被视作正确并收到积极奖励(这种方式拖累了训练的收敛速度),本文在这里采用了一个potential function重构了rewards。
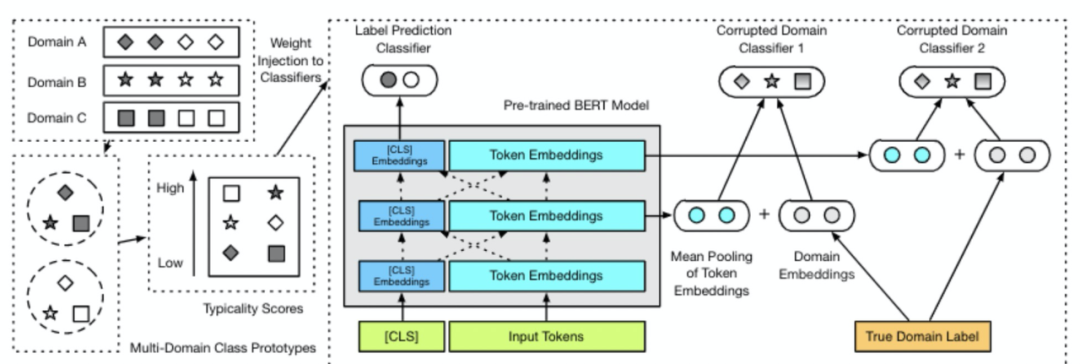
为了实现上述强化学习过程,本文使用了一个深度神经网络将搜索决策参数化(policy network,如下图)。
首先,问题被一个双向GRU编码为向量,之后,这些向量在每个时间点通过对应的单层感知器进行变化,使得问题表示具有步骤感知。同时,历史决策通过其他的GRU网络被编码,这种操作使得问题的不同部分在不同的时间节点被关注,通过注意力层,每个候选action与question进行相互作用,从而得到relation-aware的问题表示;最终基于语义打分(融合了relationembeddings,relation-awarequestion以及decision history)给出候选action的概率分布。
为了处理弱监督造成的影响,作者讨论了两种方案:
其一是提供额外的奖励,以快速的引导模型训练收敛,但是这种做法存在的一个主要风险就是无法保证额外奖励的设计目标与agent的原始目标完全一致(存在造成获得次优方案的风险)
其二则是使用potential-based reward shaping,参照论文《Policy Invariance Under Reward Transformations: Theory and Application toReward Shaping》的做法,作者基于potential function构建了一个reward shaping function。
大体的思路可以描述如下:
该函数的目标是衡量前置决策对于给定问题中的语义信息的覆盖程度,在这里,作者假设“一个正确的决策应该包含一个KG relation,这个relation应该能够对应到给定问题的一部分语义信息上”,potential的计算过程如公式7:
当t>1时,如果选择了正确的路径(action),那么所得的前置问题语义表达与前置决策对应的relation embedding应该具备高相关性。
以此为基础,可以给出potential-based reward shaping function
Reward函数则改写为
3.实验
本文实验使用的benchmark信息如下表:
Baseline包括:IRN, VRN, MemNN, MINERVA
实验结果
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。
点击阅读原文,进入 OpenKG 博客。