笔记整理 | 谭亦鸣,东南大学博士生。

来源:EACL‘21
链接:https://www.aclweb.org/anthology/2021.eacl-main.300.pdf
概述
知识图谱问答过程一般包括实体链接,多跳推理等步骤,传统方法将各个步骤作为模块单独处理,并流程化实现问答过程,这种方式显然会在流程中形成错误积累。这些步骤(或者说挑战)之间往往存在关联,因此通过一个end2end学习过程力,它们的解决方案也可以相互增强。这篇文章提出了一个基于BERT的神经机器翻译模型CQA-NMT来解决这些挑战,在LOCA和MateQA两个数据集上的实验验证表明了方法的有效性。
贡献
作者表示本文的贡献如下:
1、提出一个多任务模型,将解析自然语言问题的所有任务共同处理。并且可以解决一些新的类型的KGQA挑战。
2、提出使用基于神经机器翻译的方法用于挖掘问题相关的数量不定的relation。
3、研究表明每个自然语言问题解析的子任务之间存在互补性,这种特性将最终反映在提升问答效果上。
4、CQA-NMT能够预测包含在知识子图中的关系,并且帮助预测子图的拓扑结构,实现一个神经网络在知识图谱上的组合推理。
5、在MateQA的结果取得了SOTA
KGQA中的任务
作者首先对KGQA任务中包含的各种任务进行说明:
实体链接标注 自然语言问题中的一些n-gram(n元文法,实际可以视为短语或者字段)与知识图谱中的实体id所对应。实体链接标注的目标是识别这些n-gram并建立与实体id的对应关联。
答案类型标注 每个问题对应的答案实体都有一个实体类型的标签(来自知识图谱),目标就是识别某问题对应答案的类型。
关系序列和拓扑标注(或者路径标注,多跳推理) 由问题中的关系和实体连接起来形成的查询图反映了整个问题描述信息构成的查询路径,这些路径在知识图谱中构成从链接实体到答案实体的可达路径(不一定是最短路径)。
问题类型标注 在知识图谱问答中包含许多类型的问题,例如可以用单个三元组回答的简单问题,或者一些事实查询图结构更复杂的问题,亦或是一些需要聚合操作的问题(计数,交并集等),或者一些是非问(布尔类型)。
接着,针对上述这些任务,作者列出其中包含的关键挑战(对应的例子可以在图1找到):
不完整的实体mention
问题中包含的实体描述往往无法与图谱中完整的命名实体完全匹配(question 8)
协同词义消歧
实体mention的链接目标有时候需要借助其他实体帮助消除歧义(question 7)
避免预期之外的匹配
实体mention链接的对象需要是与问题内容相关的预期对象,但是单纯的字符匹配可能引起图谱中的匹配对象跟问题无关(question 9)
重复实体
知识图谱中可能存在多个具有相同命名的实体
关系名误匹配
问题中的关系描述与图谱中标准的关系描述往往差别甚大(question 2,4,6)
隐含关系
问题中可能存在一些没有被明确提及,但推理中需要使用到的关系信息(question 4)
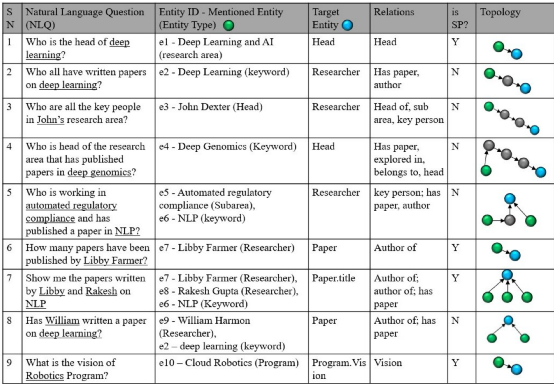

图3给出了CQA-NMT模型的结构和流程,本质上它还是一个encoder-decoder结构,但是涵盖了包括:1. 抽取实体mention然后链接到KG;2.通过游走(推理)生成需要的谓词(关系)序列;3. 预测问题类型;4. 确定答案类型并输出答案;等全部问答任务。
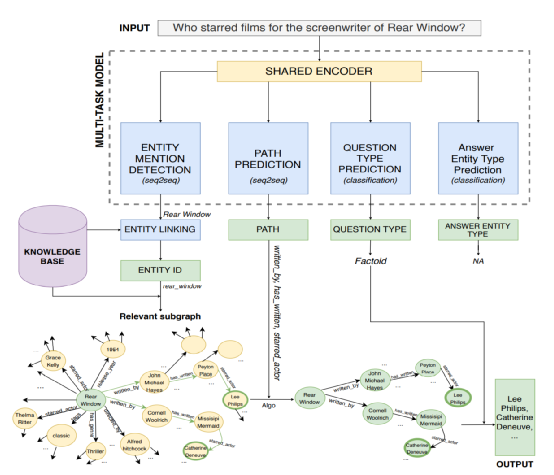

下面分别就多任务模型的各个模块进行说明:
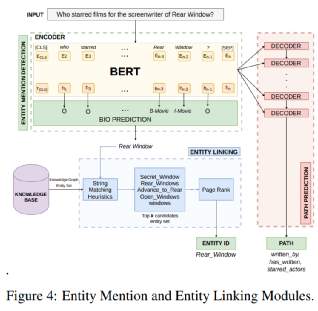
实体mention识别模块
如图4所示,通过使用BERT编码器的隐状态,作者建立了一个序列标注任务模块做实体识别,该模块输入词序列,输出标签序列。本文通过联合了实体类型以及跨度来增强CQA-NMT,softmax层的输出为:
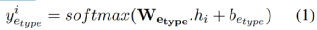
其中,i表示第i个词(位置),h是隐状态。
实体链接模块
实体识别输出了这些:实体词序列(多个)+实体类型标签(对应多个);接下来是将它们链接到图谱上,这里作者使用的是序列匹配+PageRank。通过使用三种序列匹配算法并且投票的方式挑选出候选实体,然后使用pageRank从流行度的角度选出图谱中的实体与问题中的实体mention做链接。
路径预测模块
这一部分的工作是生成问题对应的谓词序列,这里使用到的是一个基于transformer的解码器,也就是把谓词序列视作翻译的解码目标。在这里,作者不限制生成谓词的数量,因为当整个问题的内容解码完成后,生成也就终止了。
问题类型和答案类型预测模块
这两个部分很显然都可以看作分类任务,因此作者同样是使用到实体识别部分的隐状态作为特征,然后预测问题类型和答案类型:
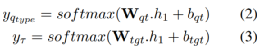
训练的目标则是最大化以下条件概率:
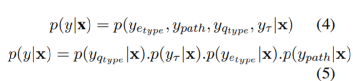
即联合了实体类型,路径以及问题类型还有答案类型一起的最大化概率。
实验部分
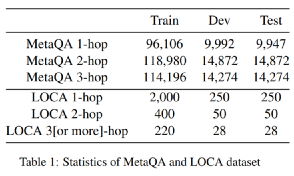
首先是数据方面,本文作者使用到了两个问题集:MateQA和LOCA。前者相对更流行一些,属于典型的多关系问答数据集(最多三跳),不过该数据集不包含问题和答案类型标签,所以作者在这里是定义了一个默认的label。后者的问题类型可以见图1。两者的统计信息都收录在表1。显然LOCA具有更少的训练样本,更多的问题类型,也就有更高的难度。
评价指标方面,对于不同的子任务,作者使用了不同的方法,实体识别和实体类型(F值),问题类型,路径预测以及答案类型(Accuracy)。
实验结果
问答的总体结果如表2
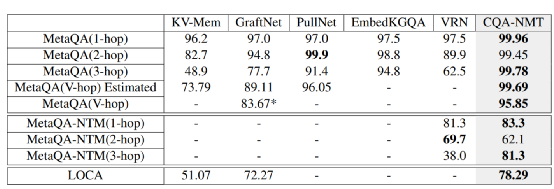

一方面,从这个结果来看,多任务方法取得了作者预期的收益,整体结果优于对比方。其中,NTM数据CQA-NMT在2-hop上效果稀碎,作者认为是zero-shot导致的(3-hop上却又有80+,这里没有进一步做出解释)
LOCA的整体结果低于MateQA,相对更具有挑战性。
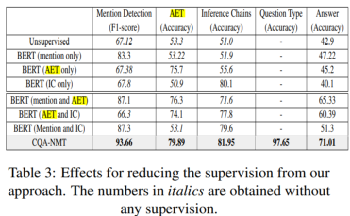
各个子任务的效果见表3:
这张表说明了多任务联合确实体现出了预期的互补性,各个子任务得到了共同提升。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。