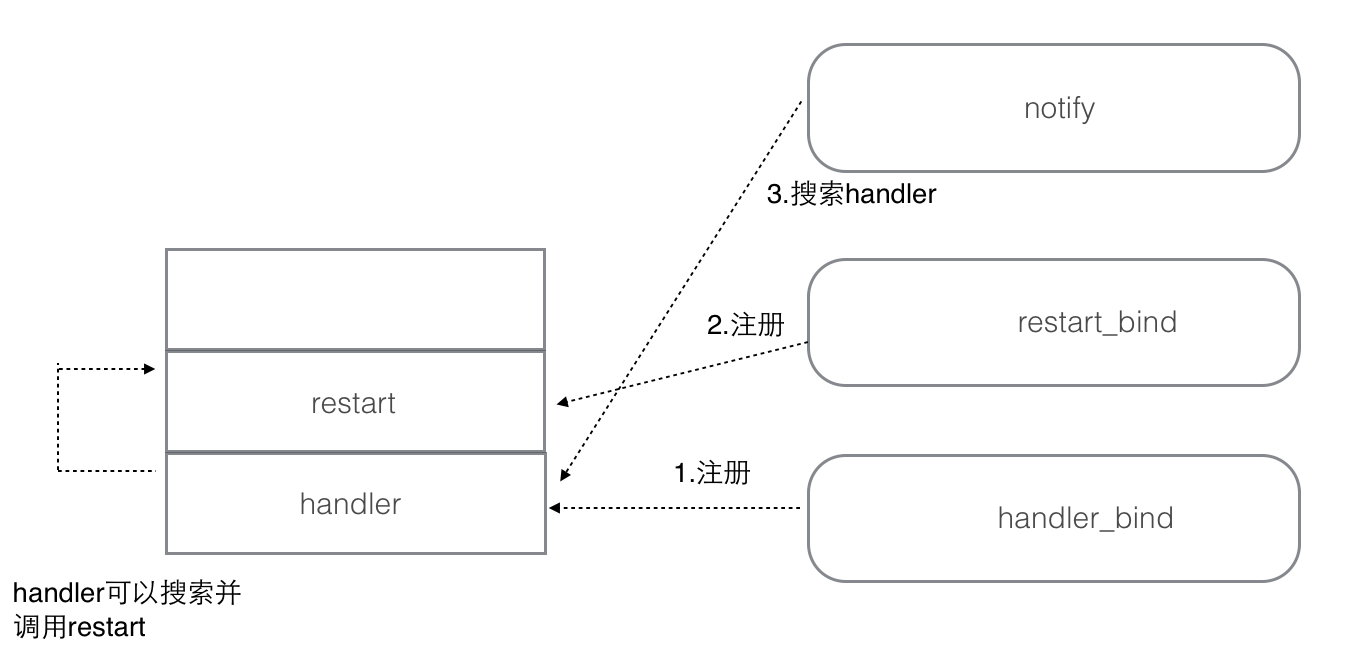
文 | 王喆
源 | 王喆的机器学习笔记
作为互联网的核心应用“搜广推”,三个方向基本都是互联网公司的标配。各头部公司的搜广推系统也都各自发展成了集成了多种模型、算法、策略的庞然大物,想一口气讲清楚三者的区别并不容易。不过万事总有一个头绪,对于一个复杂问题,直接深入到细节中去肯定是不明智的,我们还是要回到问题的本质上来,回到搜广推分别想解决的根本问题上来,才能一步步的把这三个问题分别理清楚。
根本问题上的区别
广告
一个公司要搭建广告系统,它的商业目的非常直接,就是要解决公司的收入问题。所以广告算法的目标就是为了直接增加公司收入。
推荐
推荐算法虽然本质上也是为了增加公司收入,但其直接目标是为了增加用户的参与度。只有用户的参与度高了,才能让广告系统有更多的inventory,进而增加公司营收。
搜索
搜索要解决的关键问题全部是围绕着用户输入的搜索词展开的。虽然现在搜索越来越强调个性化的结果,但是一定要清楚的是,推荐算法强调的个性化永远只是搜索算法的补充。“围绕着搜索词的信息高效获取问题“才是搜索算法想解决的根本问题。
正是因为三者间要解决的根本问题是不同的,带来了三者算法层面的第一个区别,那就是优化目标的区别。
优化目标的区别

广告
各大公司广告算法的预估目标非常统一,就是预估CTR和CVR。这是跟当前效果类广告的产品形态密切相关的。因为CPC和CPA计价仍是效果类广告系统的主流计价方式。所以只有预估出CTR和CVR,才能反向推导出流量的价值,并进一步给出合理的出价。所以针对这样的目标,广告算法非常看重把预估偏差当作首要的评价指标。
推荐
推荐算法的预估目标就不尽相同,视频类更多倾向于预测观看时长,新闻类预测CTR,电商类预估客单价等等这些跟用户参与度最相关的业务指标。而且由于推荐系统的推荐场景是生成一个列表,所以更加关注item间的相对位置,因此评估阶段更倾向于用AUC,gAUC,MAP这些指标作为评价标准。
搜索
搜索的预估目标又有所不同,因为相比广告和推荐,搜索某种意义上说是存在着“正确答案”的。所以搜索非常看重能否把这些正确答案给召回回来(广告和推荐也关注召回率,但重要性完全不同)。所以搜索系统往往会针对召回率,MAP,NDCG这些指标进行优化。
总的来说,广告算法是要“估得更准”,推荐算法是要整体上“排的更好”,搜索算法是要“搜的更全”。
算法模型设计中的区别
优化目标有区别,这就让它们算法模型设计中的侧重点完全不一样:
广告
由于广告算法要预测“精准”的CTR和CVR,用于后续计算精确的出价,因此数值上的“精准”就是至关重要的要求,仅仅预估广告间的相对位置是无法满足要求的。这就催生了广告算法中对calibration方法的严苛要求,就算模型训练的过程中存在偏差,比如使用了负采样、weighted sampling等方式改变了数据原始分布,也要根据正确的后验概率在各个维度上矫正模型输出。此外,因为广告是很少以列表的形式连续呈现的,要对每一条广告的CTR,CVR都估的准,广告算法大都是point wise的训练方式。
推荐
推荐算法的结果往往以列表的形式呈现,因此不用估的那么准,而是要更多照顾一个列表整体上,甚至一段时间内的内容多样性上对于用户的“吸引力”,让用户的参与度更高。因此现在很多头部公司在算法设计时,不仅要考虑当前推荐的item的吸引力,甚至会有一些list level,page level的算法去衡量整体的效果进行优化。也正因为这一点,推荐算法有大量不同的训练方式,除了point-wise,还有pair-wise,list-wise等等。此外为了增加用户的长期参与度,还对推荐内容的多样性,新鲜度有更高的要求,这就让探索与利用,强化学习等一些列方法在推荐场景下更受重视。
搜索
对于搜索算法,我们还是要再次强调搜索词的关键性,以及对搜索词的理解。正因为这样,搜索词与其他特征组成的交叉特征,组合特征,以及模型中的交叉部分是异常重要的。对于一些特定场景,比如搜索引擎,我们一定程度上要抑制个性化的需求,更多把质量和权威性放在更重要的位置。

辅助策略和算法上的区别
除了主模型的差异,跟主模型配合的辅助策略/算法也存在着较大的区别。
广告
广告系统中,CTR等算法只是其中关键的一步,估的准CTR只是一个前提,如何让广告系统盈利,产生更多收入,还需要pacing,bidding,budget control,ads allocation等多个同样重要的模块协同作用,才能让平台利益最大化,这显然是比推荐系统复杂的。
推荐
推荐系统中,由于需要更多照顾用户的长期兴趣,需要一些补充策略做出一些看似“非最优”的选择,比如探索性的尝试一些长尾内容,在生成整个推荐列表时要加入多样性的约束,等等。这一点上,广告系统也需要,但远没有推荐系统的重视程度高。
搜索
搜索系统中,大量辅助算法还是要聚焦在对搜索词和内容的理解上。因此搜索系统往往是应用NLP模型最重的地方,因为需要对大量内容进行预处理,embedding化,进而生成更理解用户语义的结果。比如最典型的例子就是airbnb对搜索词embedding化后,输入滑雪skiing,会返回更多滑雪胜地的地点,而不是仅仅是字面上的匹配。

模型本身的差异
最后才谈到模型本身的差异,因为相比上面一路走来的关键问题,模型本身的差异反而是更细节的问题,这里从模型结构的层面谈一个典型的差异:
在广告模型中,用户的兴趣是不那么连贯的,因此容易造成sequential model的失效,attention机制可能会更加重要一些。
推荐模型中,如果不抓住用户兴趣的连续变化,是很难做好推荐模型的,因此利用sequential model来模拟用户兴趣变化往往是有收益的。
搜索模型中,搜索词和item之间天然是一个双塔结构,因此在模型构建的时候各种交叉特征,模型中的各种交叉结构往往是搜索类模型的重点。当然,在构建良好的交叉特征之后,使用传统的LTR,GBDT等模型也往往能够取得不错的结果。



系统层面的痛点
总体感觉上,广告算法的问题更加琐碎,各模块协同工作找到平台全局利润最大化方法的难度非常大,系统异常复杂到难以掌控的地步,这是广告算法工程师的痛点;
而推荐算法这边,问题往往卡在长期利益与短期利益的平衡上,在模型结构红利消失殆尽的今天,如何破局是推荐算法工程师们做梦都在想的问题。
搜索算法则往往把重心放在搜索词和item的内容理解上,只要能做好这一点,模型结构本身反而不是改进的关键点了,但是在多模态的时代,图片、视频内容的理解往往是制约搜索效果的痛点。
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!