文章目录
- 1. 词嵌入 Word Embeddings
- 2. 分类模型
- 3. 文档相似度
- 练习:
- 1. 使用文档向量训练模型
- 2. 文本相似度
learn from https://www.kaggle.com/learn/natural-language-processing
1. 词嵌入 Word Embeddings
参考博文:05.序列模型 W2.自然语言处理与词嵌入 https://michael.blog.csdn.net/article/details/108886394
类似的词语有着类似的向量表示,向量间可以相减作类比
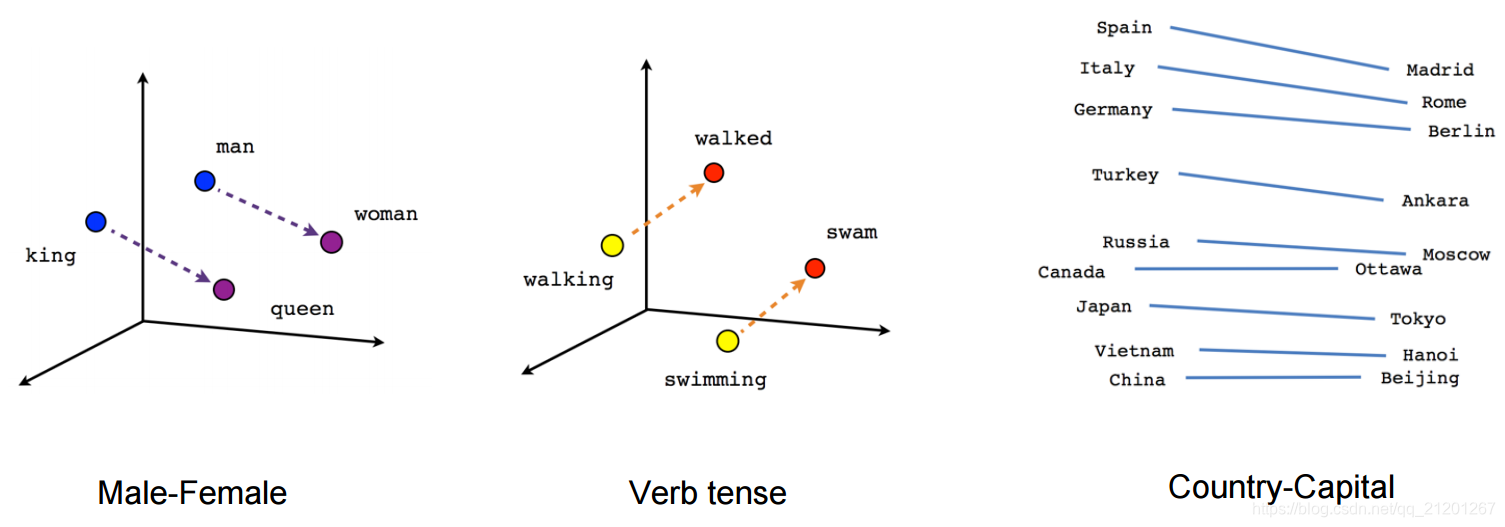
- 加载模型
import numpy as np
import spacy# Need to load the large model to get the vectors
nlp = spacy.load('en_core_web_lg')
- 提取单词向量
text = "These vectors can be used as features for machine learning models."
with nlp.disable_pipes():vectors = np.array([token.vector for token in nlp(text)])
vectors.shape
# (12, 300) 12个词,每个是300维的词向量
- 合并单词向量为文档向量,最简单的做法是,平均每个单词的向量
import pandas as pd# Loading the spam data
# ham is the label for non-spam messages
spam = pd.read_csv('../input/nlp-course/spam.csv')with nlp.disable_pipes():doc_vectors = np.array([nlp(text).vector for text in spam.text])
doc_vectors.shape
# (5572, 300)
2. 分类模型
有了文档向量,你可以使用 sklearn 模型、XGB模型等进行建模
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(doc_vectors, spam.label, test_size=0.1, random_state=1)
- SVM 的例子
from sklearn.svm import LinearSVC# Set dual=False to speed up training, and it's not needed
svc = LinearSVC(random_state=1, dual=False, max_iter=10000)
svc.fit(X_train, y_train)
print(f"Accuracy: {svc.score(X_test, y_test) * 100:.3f}%", )
Accuracy: 97.312%
3. 文档相似度
cosine similarity 余弦相似度 cosθ=a⋅b∥a∥∥b∥\cos \theta=\frac{\mathbf{a} \cdot \mathbf{b}}{\|\mathbf{a}\|\|\mathbf{b}\|}cosθ=∥a∥∥b∥a⋅b
def cosine_similarity(a, b):return a.dot(b)/np.sqrt(a.dot(a) * b.dot(b))
a = nlp("REPLY NOW FOR FREE TEA").vector
b = nlp("According to legend, Emperor Shen Nung discovered tea when leaves from a wild tree blew into his pot of boiling water.").vector
cosine_similarity(a, b)
输出:
0.7030031
练习:
试试你为餐馆建立的情绪分析模型。在给定的一些示例文本的数据集中找到最相似的评论。
%matplotlib inlineimport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import spacy# Set up code checking
from learntools.core import binder
binder.bind(globals())
from learntools.nlp.ex3 import *
print("\nSetup complete")
- 加载模型、数据
# Load the large model to get the vectors
nlp = spacy.load('en_core_web_lg')review_data = pd.read_csv('../input/nlp-course/yelp_ratings.csv')
review_data.head()

reviews = review_data[:100]
# We just want the vectors so we can turn off other models in the pipeline
with nlp.disable_pipes():vectors = np.array([nlp(review.text).vector for idx, review in reviews.iterrows()])
vectors.shape
# (100, 300) 前100条评论的向量表示
- 为了节省时间,加载已经处理好的所有评论词向量
# Loading all document vectors from file
vectors = np.load('../input/nlp-course/review_vectors.npy')
1. 使用文档向量训练模型
- SVM
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(vectors, review_data.sentiment, test_size=0.1, random_state=1)# Create the LinearSVC model
model = LinearSVC(random_state=1, dual=False)
# Fit the model
model.fit(X_train, y_train)# run to see model accuracy
print(f'Model test accuracy: {model.score(X_test, y_test)*100:.3f}%')
输出:
Model test accuracy: 93.847%
- KNN
# Scratch space in case you want to experiment with other models
from sklearn.neighbors import KNeighborsClassifier
second_model = KNeighborsClassifier(5)
second_model.fit(X_train, y_train)
print(f'Model test accuracy: {second_model.score(X_test, y_test)*100:.3f}%')
输出:
Model test accuracy: 86.998%
2. 文本相似度
- Centering the Vectors
有时在计算相似性时,人们会计算所有文档的平均向量,然后每个文档的向量减去这个向量。为什么你认为这有助于相似性度量?
有时候你的文档已经相当相似了。例如,这个数据集是对企业的所有评论,这些文档之间有很强的相似度,与新闻文章、技术手册和食谱相比。最终你得到0.8和1之间的所有相似性,并且没有反相似文档(相似性<0)。当中心化向量时,您将比较数据集中的文档,而不是所有可能的文档。
- 找到最相似的评论
review = """I absolutely love this place. The 360 degree glass windows with the
Yerba buena garden view, tea pots all around and the smell of fresh tea everywhere
transports you to what feels like a different zen zone within the city. I know
the price is slightly more compared to the normal American size, however the food
is very wholesome, the tea selection is incredible and I know service can be hit
or miss often but it was on point during our most recent visit. Definitely recommend!I would especially recommend the butternut squash gyoza."""def cosine_similarity(a, b):return np.dot(a, b)/np.sqrt(a.dot(a)*b.dot(b))review_vec = nlp(review).vector## Center the document vectors
# Calculate the mean for the document vectors, should have shape (300,)
vec_mean = vectors.mean(axis=0) # 平均向量
# Subtract the mean from the vectors
centered = vectors - vec_mean # 中心化向量# Calculate similarities for each document in the dataset
# Make sure to subtract the mean from the review vector
sims = [cosine_similarity(centered_vec, review_vec - vec_mean) for centered_vec in centered]# Get the index for the most similar document
most_similar = np.argmax(sims)
print(review_data.iloc[most_similar].text)
输出:
After purchasing my final christmas gifts at the Urban Tea Merchant in Vancouver, I was surprised to hear about Teopia at the new outdoor mall at Don Mills and Lawrence when I went back home to Toronto for Christmas.
Across from the outdoor skating rink and perfect to sit by the ledge to people watch, the location was prime for tea connesieurs... or people who are just freezing cold in need of a drinK!
Like any gourmet tea shop, there were large tins of tea leaves on the walls, and although the tea menu seemed interesting enough, you can get any specialty tea as your drink. We didn't know what to get... so the lady suggested the Goji Berries... it smelled so succulent and juicy... instantly SOLD! I got it into a tea latte and watched the tea steep while the milk was steamed, and surprisingly, with the click of a button, all the water from the tea can be instantly drained into the cup (see photo).. very fascinating!The tea was aromatic and tasty, not over powering. The price was also very reasonable and I recommend everyone to get a taste of this place :)
- 评论1

- 与评论1最相似的评论

- 看看相似的评论
如果你看看其他类似的评论,你会看到很多咖啡店。为什么你认为咖啡评论和只提到茶的例子评论相似?
咖啡店的评论也将类似于我们的茶馆评论,因为咖啡和茶在语义上是相似的。大多数咖啡馆都提供咖啡和茶,所以你会经常看到这两个词同时出现。
刷完了课程,获得鼓励证书,继续加油!

我的CSDN博客地址 https://michael.blog.csdn.net/
长按或扫码关注我的公众号(Michael阿明),一起加油、一起学习进步!


)


--序列)


 解决方案)
--字典与集合)
![[Kaggle] Spam/Ham Email Classification 垃圾邮件分类(spacy)](http://pic.xiahunao.cn/[Kaggle] Spam/Ham Email Classification 垃圾邮件分类(spacy))
—— 大纲内容与基本功能分析)

--函数)
)
—— 思维导图)

--类与对象)

)
