目录
1、Spark Executor如何工作
2、Spark Executor工作源码
1、Spark Executor如何工作
当Driver发送过来Task的时候,其实是发送给CoarseGrainedExecutorBackend这个RPCEndpoint,而不是直接发送给Executor(Executor由于不是消息循环体永远也无法接收远程发过来的信息)。
Driver向ExecutorBackend发送LaunchTask,这里实际上是把内容交给线程池中的线程去执行。首先判断Executor是否为空,反序列化TaskDescription,然后调用Executor.launchTask ,launchTask 里面是将Task封装在TaskRunner(是一个runnable对象)里面然后交给线程池中的线程处理。在TaskRunner的run方法里面会导致runTask的执行。
2、Spark Executor工作源码
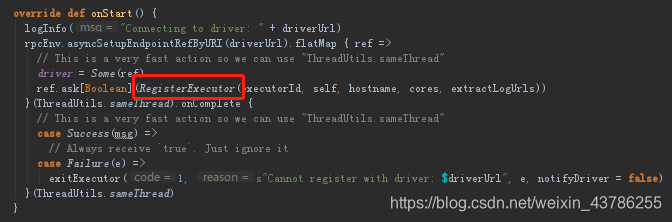
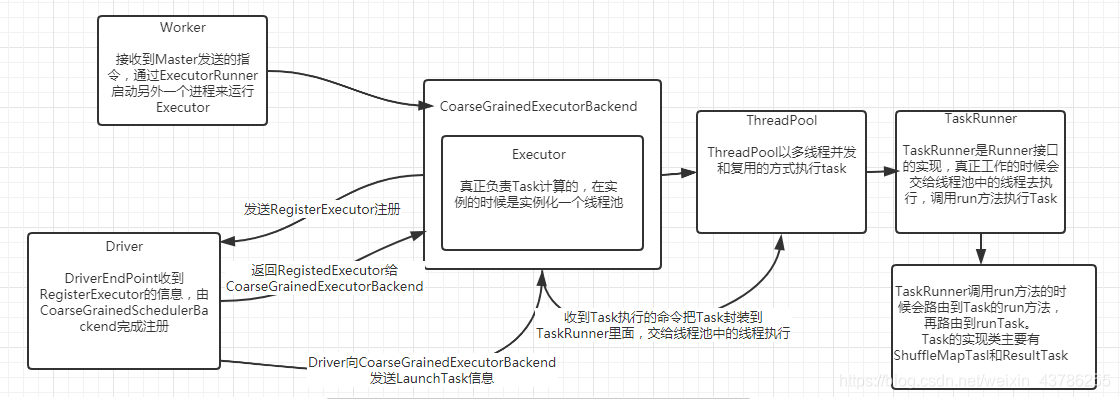
(1)Worker接收到Master发送过来启动Executor的指令,通过ExecutorRunner启动另外一个进程来运行Executor。在这个基础上会启动一个CoarseGrainedExecutorBackend(粗粒度),ExecutorBackend启动的时候这个时候要向Driver注册,通过RegisterExecutor。Driver(CoarseGrainedSchedulerBackend的内部成员DriverEndpoint接收注册)在接收到RegisterExecutor信息后会返回一个信息RegisteredExecutor给CoarseGrainedExecutorBackend。
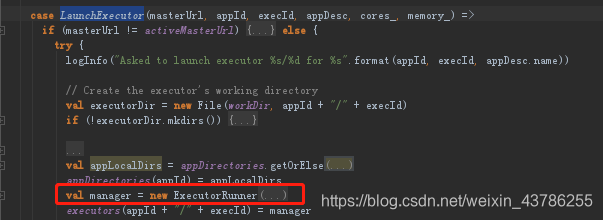
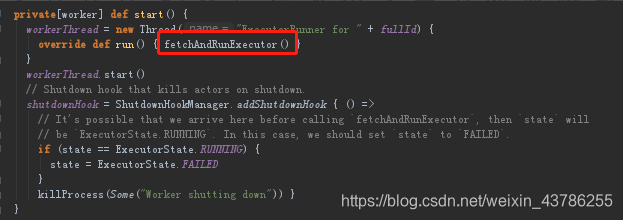

CoarseGrainedExecutorBackend:是Executor运行所在的进程的名称,他本身不会完成具体任务的计算,这个进程里面有个Executor对象和CoarseGrainedExecutorBackend是一一对应的。
Executor:完成具体的计算,真正处理Task的对象,内部通过线程池的方式完成Task的计算。
(2)Driver的CoarseGrainedSchedulerBackend内部的成员DriverEndpoint收到RegisterExecutor后,首先判断ExecutorDataMap中是否有这个ExecutorId。ExecutorDataMap是个内存数据结构(他是CoarseGrainedSchedulerBackend的成员,所以最终是注册给CoarseGrainedSchedulerBackend),他是一个HashMap。
如果ExecutorDataMap中不存在,就进行注册,注册的时候先看看address存在不存在,如果存在直接获取,如果不存在就获取senderAddress。这从实现的角度看adress就是senderAddress。然后相关数据结构添加数据
CoarseGrainedSchedulerBackend.this.synchronized这里加上synchronized是因为集群中有很多ExecutorBackend向Driver注册,担心注册的时候写冲突,所以加上一个同步代码块
最后把消息发还给CoarseGrainedExecutorBackend
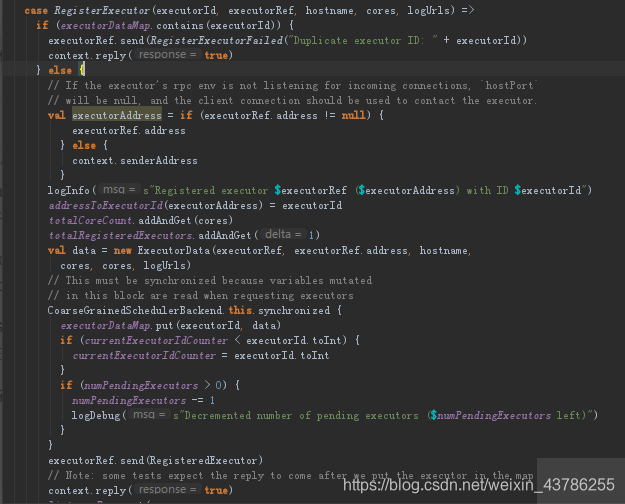
(3)CoarseGrainedExecutorBackend收到RegisterExecutor后就new了一个Executor这个Executor对象是事实上负责Task计算的

(4)在Executor默认构造器中有一个非常关键的内容,有个成员threadPool(线程池)

创建线程池,线程池里面要有线程,线程怎么产生的呢?不会平白无故的产生,所以就搞了一个线程工厂,就是按照某种你需要的格式去产生线程,背后还是new出一个线程


setDamon(True)设置每个线程是后台运行的方式

(5)线程池也准备好后就是等待Driver端发任务过来,是发给CoarseGrainedExecutorBackend不是Executor,因为Executor不可能接收到消息的他本身就不是一个消息循环体。CoarseGrainedExecutorBackend收到LaunchTask后,这里实际上是把内容交给线程池中的线程去执行。判断Executor是否为空,反序列化TaskDescription,然后调用Executor.launchTask

(6)launchTask 里面是将Task封装在TaskRunner(是一个runnable对象)里面然后交给线程池中的线程处理。并把这个任务加入ConcurrentHashMap类型的名称为runningTasks的数据结构中管理。

(7)在TaskRunner的run方法里面会导致runTask的执行
补充:为什么要在worker接收到master发送过来的指令后为什么要启动另外一个进程,也就是说为什么开辟另外一个进程,在另外一个进程中注册给Driver,然后启动Executor。必须启动另外一个进程的原因:①Worker本身是管理当前机器上的资源的,当前机器上的资源变动的时候要汇报给Master,Worker不是用来做计算的不能在Worker里面计算;②Spark集群中可能有很多应用程序就可能有很多的Executor,如果不是为每个Executor启动一个进程而是所有Executor在Worker里面,那么一个程序奔溃了会导致其他程序奔溃。
—— hint机制)
 时间插入、删除和获取随机元素 - 允许重复(vector + 哈希))


)







)


)


)
