learn from 从0开始学大数据(极客时间)
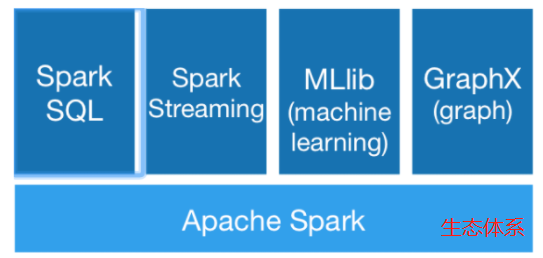
Spark 拥有更快的执行速度
更友好的编程接口
迅速抢占 MapReduce 的市场份额,成为主流的大数据计算框架

val textFile = sc.textFile("hdfs://...")
// 根据 HDFS 路径生成一个输入数据 RDD
val counts = textFile.flatMap(line => line.split(" "))// 每一行文本用空格拆分成单词.map(word => (word, 1))// 每个单词进行转换,word => (word, 1),生成 <Key, Value> 的结构.reduceByKey(_ + _)// 相同的 Key 进行统计,统计方式是对 Value 求和,(_ + _)
counts.saveAsTextFile("hdfs://...")
// 将这个 RDD 保存到 HDFS
RDD 是 Spark 的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写
MapReduce 面向过程的大数据计算
Spark 将大规模数据集合抽象成一个 RDD 对象,然后在这个 RDD 上进行各种计算处理,得到一个新的 RDD,继续计算处理,直到得到最后的结果数据。
Spark 可以理解成是面向对象的大数据计算。
在进行 Spark 编程的时候,思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象
RDD 上定义的函数分两种
- 转换(transformation)函数,返回值还是 RDD
- 执行(action)函数,不再返回 RDD


)

)










 和 delegate(委托)也叫(代理)---辨析)



