文章目录
- 1. 内置序列
- 2. 列表推导 []、生成器() 表达式
- 3. 元组 tuple
- 4. 切片
- 5. `+, *` 操作
- 6. 增量赋值
- 7. 排序
- 8. bisect管理已排序序列
- 8.1 用 bisect.bisect 二分搜索
- 8.2 用 bisect.insort 二分插入新元素
- 9. 列表的替代
- 9.1 数组
- 9.2 内存视图
- 9.3 NumPy、SciPy
- 9.4 队列
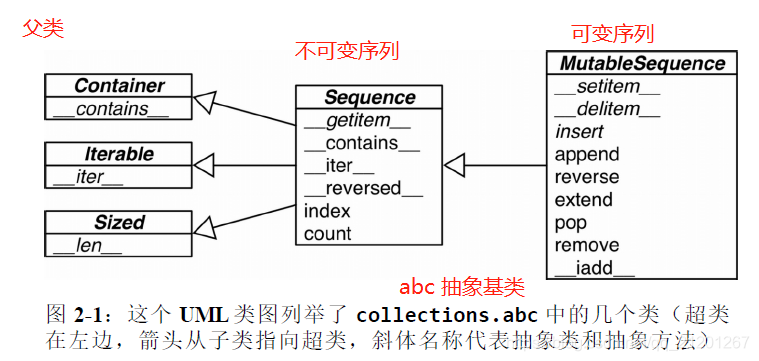
1. 内置序列
- 容器序列:
list, tuple, collections.deque能存放不同类型的数据,存放的是对象的引用 - 扁平序列:
str, bytes, bytearray, memoryview, array.array只能存一种类型,存放的是值(只能存字符、字节、数值这种基础类型)
按照是否可修改:
- 可变序列:
list,bytearray,array.array,collections.deque,memoryview - 不可变序列:
tuple, str, bytes
2. 列表推导 []、生成器() 表达式
- 列表推导有自己的局部作用域
# 列表推导有自己的局部作用域
x = "ABC"
y = [ord(x) for x in x]
print(x) # ABC, x 没有被覆盖
print(y) # [65, 66, 67]
- 列表推导式,只能生成列表类型
# 列推导更简单
symbols = '$¢£¥€¤'
beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
print(beyond_ascii) # [162, 163, 165, 8364, 164]
beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
print(beyond_ascii) # [162, 163, 165, 8364, 164]# 注意以下两个for的顺序,先出现的变量,先遍历完它的组合
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
t_shirts = [(color, size) for color in colors for size in sizes]
print(t_shirts)
# [('black', 'S'), ('black', 'M'), ('black', 'L'),
# ('white', 'S'), ('white', 'M'), ('white', 'L')]t_shirts = [(color, size) for size in sizes for color in colors]
print(t_shirts)
# [('black', 'S'), ('white', 'S'),
# ('black', 'M'), ('white', 'M'),
# ('black', 'L'), ('white', 'L')]
生成器表达式
- 逐个的产出元素,背后遵守了迭代器协议,相比 列表 去初始化其他类型,生成器表达式 更节省内存,它不会一次性产生全部的组合
- 语法跟列表推导差不多,把
[ ]改成( )
# 生成器表达式 ()
symbols = '$¢£¥€¤'
print(tuple(ord(symbol) for symbol in symbols))
import arrayprint(array.array('I', (ord(symbol) for symbol in symbols)))
# ord(symbol) 外面需要括号,因为array需要2个构造参数
# typecode (must be b, B, u, h, H, i, I, l, L, q, Q, f or d)for t_shirt in ('{}, {}'.format(c, s) for c in colors for s in sizes):print(t_shirt)
# black, S
# black, M
# black, L
# white, S
# white, M
# white, L
3. 元组 tuple
- 不可变的列表
- 还可用于 没有字段名的记录
lax_coordinates = (33.9425, -118.408056)
city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014)
traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')]
for passport in sorted(traveler_ids):print('{}/{}'.format(passport[0], passport[1]))print('%s/%s' % passport) # 跟上面的等价, % 运算符把对应元素对应到 %s 处
- 元组拆包
%, =必须保证两侧的元素数量一样,不一样多,可以使用*忽略多余元素
lax_coordinates = (33.9425, -118.408056)
latitude, longitude = lax_coordinates # 元组拆包
print(latitude, longitude) # 33.9425 -118.408056a, b = 1, 2
a, b = b, a
print(a, b) # 2 1print(divmod(20, 8)) # (2, 4)
t = (20, 8)
print(divmod(*t)) # *运算符把可迭代对象拆开作为函数的参数
# (2, 4)
quotient, remainder = divmod(*t)
print(quotient, remainder) # 2 4import os
path, filename = os.path.split("c:/abd/tuple.py")
print(path) # c:/abd
print(filename) # tuple.py
*代替多个元素
a, b, *rest = range(5)
print(a, b, rest) # 0 1 [2, 3, 4]
a, b, *rest = range(3)
print(a, b, rest) # 0 1 [2]
a, b, *rest = range(2) # 不能少于两个元素
print(a, b, rest) # 0 1 []a, *body, c, d = range(5)
print(a, body, c, d) # 0 [1, 2] 3 4
*head, b, c, d = range(5)
print(head, b, c, d) # [0, 1] 2 3 4
- 嵌套元组拆包
metro_areas = [('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]print('{:>15} | {:<9} | {:^9}'.format('table', 'lat.', 'long.'))
# < 左对齐(默认),^居中对齐 > 右对齐
fmt = '{:15} | {:9.3f} | {:9.4f}' # w宽度.n小数点位数
for name, cc, pop, (latitude, longitude) in metro_areas:if longitude <= 0:print(fmt.format(name, latitude, longitude))
# table | lat. | long.
# Mexico City | 19.433 | -99.1333
# New York-Newark | 40.809 | -74.0204
# Sao Paulo | -23.548 | -46.6358
- 有名字的元组
collections.namedtuple,构建一个带字段名的元组和一个有名字的类 - 其构建的实例比普通对象小一些,因为它不会用
__dict__来存放属性
from collections import namedtupleCity = namedtuple('City', 'name country population coordinates')
# 类名, 各个字段名字(数个字符串的可迭代对象 or 空格分割的字符串)
tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667)) # 只接受单一可迭代对象
print(tokyo)
print(tokyo.population) # 通过字段名获取属性
print(tokyo.coordinates)
print(tokyo[1]) # 通过位置获取属性print(City._fields) # 类的所有字段名 ('name', 'country', 'population', 'coordinates')
LatLong = namedtuple('LatLong', 'lat long')
delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889))
delhi = City._make(delhi_data) # 生成类的实例 跟 City(*delhi_data) 一样
print(delhi._asdict()) # 以collections.OrderedDict的形式返回
for k, v in delhi._asdict().items():print(k + ':', v)
4. 切片
像 list, tuple, str 等序列类型都支持切片
seq[start:stop:step]从 start 开始,到 stop(不包含)结束,每间隔 step 个取一次,其调用seq.__getitem__(slice(start, stop, step))
# slice
invoice = """
1909 Pimoroni PiBrella $17.50 3 $52.50
1489 6mm Tactile Switch x20 $4.95 2 $9.90
1510 Panavise Jr. - PV-201 $28.00 1 $28.00
1601 PiTFT Mini Kit 320x240 $34.95 1 $34.95
"""
SKU = slice(0, 6)
DESCRIPTION = slice(6, 30)
UNIT_PRICE = slice(30, 37)
QUANTITY = slice(37, 39)
ITEM_TOTAL = slice(39, None)
line_items = invoice.split('\n')[1:]
for item in line_items:print(item[UNIT_PRICE], item[DESCRIPTION])
# $17.50 Pimoroni PiBrella
# $4.95 6mm Tactile Switch x20
# $28.00 Panavise Jr. - PV-201
# $34.95 PiTFT Mini Kit 320x240
- 给切片赋值(迭代对象),就地修改
# 给切片赋值, 就地修改
l = list(range(10))
print(l) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
l[2:5] = [20, 30] # 替换原list
print(l) # [0, 1, 20, 30, 5, 6, 7, 8, 9]
del l[5 : 7] # 删除段
print(l) # [0, 1, 20, 30, 5, 8, 9]
l[3::2] = [11, 22]
print(l) # [0, 1, 20, 11, 5, 22, 9]
# l[2:5] = 100 # Error can only assign an iterable
5. +, * 操作
- 使用
+*,拼接,产生新的序列 - 注意 不要在
[[list]]*n外侧乘以 n ,它们 n 个都指向同一个list
# * + 操作
l = [1, "abc", 3]
print(2 * l) # [1, 'abc', 3, 1, 'abc', 3]
print(l) # [1, 'abc', 3]
s = "abc"
print(s * 2) # abcabc
print(s) # abc# 注意,坑点
l = [[1, 2, 3]] * 3
print(l) # [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
l[0][0] = 100 # 内部都是指向一个列表
print(l) # [[100, 2, 3], [100, 2, 3], [100, 2, 3]]# 正确写法
l = [[1, 2, 3] for i in range(3)]
print(l) # [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
l[0][0] = 100
print(l) # [[100, 2, 3], [1, 2, 3], [1, 2, 3]]
6. 增量赋值
+=,*=等,+=背后对应于__iadd__()就地加法,如果类没有实现这个方法,会调用__add__()
# 增量操作
l = [1, 2, 3]
print(id(l)) # 2408644481736
l *= 2
print(l) # [1, 2, 3, 1, 2, 3]
print(id(l)) # 2408644481736 , 就地修改t = (1, 2, 3)
print(id(t)) # 1930961968224
t *= 2
print(t) # (1, 2, 3, 1, 2, 3)
print(id(t)) # 1930959535464 , 不可变对象,会产生新的对象(str例外)
7. 排序
list.sort()就地排序,返回 None,没有复制- 内置函数
sorted(),会新建一个列表返回 - 都有关键字,
reverse默认False升序,key排序函数(自定义,len,str.lower)
8. bisect管理已排序序列
8.1 用 bisect.bisect 二分搜索
def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):i = bisect.bisect(breakpoints, score)# bisect同bisect_right,相等的话返回后面的位置return grades[i]ans = [grade(score) for score in [33, 99, 77, 70, 89, 90, 100]]
# bisect_left ['F', 'A', 'C', 'D', 'B', 'B', 'A']
# bisect_right ['F', 'A', 'C', 'C', 'B', 'A', 'A']
print(ans)
8.2 用 bisect.insort 二分插入新元素
insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq 的升序顺序
import random, timerandom.seed(time.time())
l = []
for i in range(7):new_item = random.randrange(20)bisect.insort(l, new_item)print('{:2} ->'.format(new_item), l)
# 17 -> [17]
# 0 -> [0, 17]
# 16 -> [0, 16, 17]
# 6 -> [0, 6, 16, 17]
# 13 -> [0, 6, 13, 16, 17]
# 14 -> [0, 6, 13, 14, 16, 17]
# 1 -> [0, 1, 6, 13, 14, 16, 17]
9. 列表的替代
9.1 数组
- 只包含数字的列表,
array.array比list更高效,支持所有可变序列的操作 - 还可以 从文件读取 和 存入文件,
.frombytes,.tofile
# 数组
from array import array
from random import randomfloats = array('d', (random() for i in range(10 ** 7)))
print(floats[-1]) # 0.7284759170264468
f = open("floats.bin", "wb")
floats.tofile(f)
f.close()
floats1 = array('d')
f = open("floats.bin", "rb")
floats1.fromfile(f, 10 ** 7)
f.close()
print(floats[-1]) # 0.7284759170264468
print(floats == floats1) # True
pickle.dump 几乎可以处理所有内置数字类型(复数,嵌套集合,自定义类)
9.2 内存视图
- 不复制,操作内容
# 内存视图
nums = array('h', [-2, -1, 0, 1, 2]) # h 短整型有符号
menv = memoryview(nums)
print(len(menv)) # 5
print(menv[0]) # -2
menv_oct = menv.cast('B') # B 无符号字符
print(menv_oct.tolist()) # [254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
menv_oct[5] = 4 # 操作位置上的字节
print(nums) # array('h', [-2, -1, 1024, 1, 2])
9.3 NumPy、SciPy
略
9.4 队列
- 列表在 头部 pop,或者 insert 时,比较费时,会移动元素
collections.deque类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型
# deque
from collections import dequedq = deque(range(10), maxlen=10)
print(dq) # deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
dq.rotate(3) # 右移3个
print(dq) # deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
dq.rotate(-4) # 左移4个
print(dq) # deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
dq.appendleft(-1)
print(dq) # deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
dq.extend([11, 22, 33]) # 满了,删除另一端的
print(dq) # deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
dq.extendleft([10, 20, 30, 40]) # 逐个添加到左侧
print(dq) # deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)
- 还有一些
PriorityQueue,Queue,LifoQueue,heapq等队列




)




)



)


)
)

)