文章目录
- 1. 迭代器
- 2. 生成器
- 3. 标准库
- 3.1 过滤
- 3.2 映射
- 3.3 合并
- 3.4 排列组合
- 3.5 重新排列
- 4. yield from
- 5. 可迭代的归约函数
- 6. iter 还可以传入2个参数
- 7. 生成器当成协程
learn from 《流畅的python》
1. 迭代器
- 所有生成器都是迭代器,因为生成器完全实现了迭代器接口
- 序列可以迭代的原因:
iter函数,解释器需要迭代对象x时,会自动调用iter(x) - 内置的
iter:先检查是否实现了__iter__,不然,检查是否实现__getitem__并创建迭代器
标准的迭代器接口有两个方法
__next__返回下一个可用的元素,如果没有元素了,抛出StopIteration异常__iter__返回 self,以便在应该使用可迭代对象的地方使用迭代器,例如 在 for 循环中
不要在可迭代对象的类中实现迭代器,一举两得?错误,大佬教我不要这么做!
- 为了支持多种遍历,需要获取独立的多个迭代器,每次调用
iter()都创建独立的迭代器对象
可迭代的对象 一定不能 是 自身的迭代器
也就是说,可迭代的对象 必须实现__iter__方法,但不能实现__next__方法
2. 生成器
只要 Python 函数的定义体中有 yield 关键字,该函数就是生成器函数
调用生成器函数时,会返回一个生成器对象
惰性获取匹配项 re.finditer ,可以节省内存和无效工作
生成器表达式可以理解为列表推导的惰性版本,按需 惰性生成元素
def genAB():print("start")yield 'A'print("continue")yield 'B'print("end")ans1 = [x*2 for x in genAB()] # 循环迭代列表推导生成的 ans1 列表
# 输出以下内容
# start
# continue
# endfor x in ans1:print(x)
# 输出
# AA
# BBans2 = (x*2 for x in genAB()) # 生成器表达式会产出生成器,ans2 是一个生成器对象
# 无输出for x in ans2: # 调用时,才真正执行 genAB 函数产出数值print(x)
# 输出
# start
# AA
# continue
# BB
# end
3. 标准库
import itertools
gen = itertools.count(5, 0.5)
print(next(gen))
print(next(gen))
print(next(gen))
# 5
# 5.5
# 6.0
list(count())会生成无穷的序列,内存会爆炸
gen = itertools.takewhile(lambda n : n < 6, itertools.count(5, 0.5))
print(list(gen)) # [5, 5.5]
takewhile不满足条件时退出
3.1 过滤
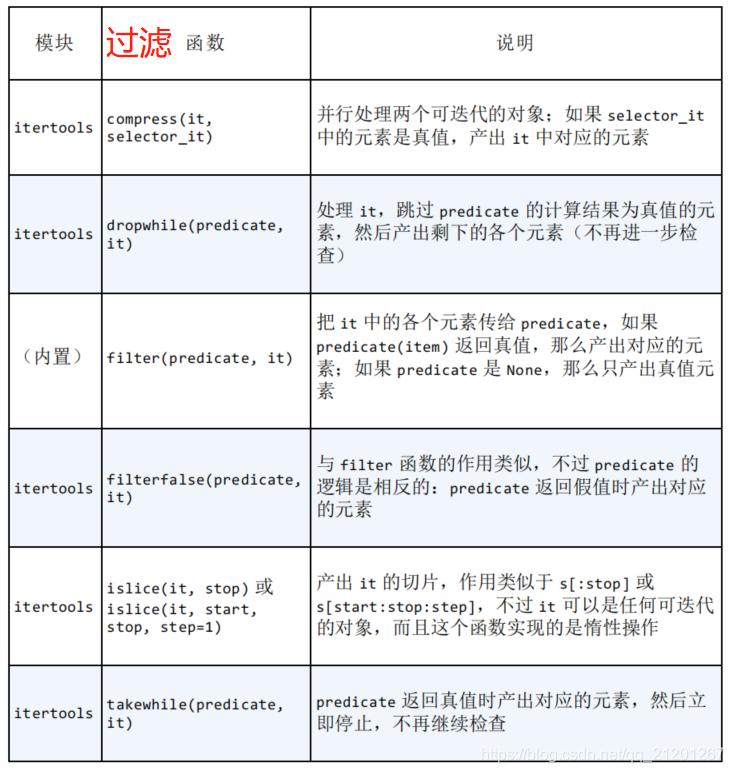
def vowel(c):return c.lower() in "aeiou"print(list(filter(vowel, "Abcdea"))) # ['A', 'e', 'a']
print(list(itertools.filterfalse(vowel, "Abcdea"))) # ['b', 'c', 'd']
print(list(itertools.dropwhile(vowel, "Aardvark")))
# ['r', 'd', 'v', 'a', 'r', 'k'] 遇到不满足的即停止检测
print(list(itertools.takewhile(vowel, "Aardvark")))
# ['A', 'a'] 遇到不满足的即停止检测
print(list(itertools.compress('Aardvark', (1, 0, 1, 1, 0, 1))))
# 产出后者是真值的前者元素 ['A', 'r', 'd', 'a']
print(list(itertools.islice('Aardvark', 4)))
# ['A', 'a', 'r', 'd'] 前 4 个元素
print(list(itertools.islice('Aardvark', 4, 7)))
# ['v', 'a', 'r'] [4,7) 的元素
print(list(itertools.islice('Aardvark', 1, 7, 2)))
# ['a', 'd', 'a'] [1,7) 每 2 个 取一个
3.2 映射

sample = [9, 5, 4, 6, 8, 9]
print(list(itertools.accumulate(sample)))
# [9, 14, 18, 24, 32, 41] 累加求和,前缀和
print(list(itertools.accumulate(sample, min)))
# [9, 5, 4, 4, 4, 4] 累积的最小值
print(list(itertools.accumulate(sample, max)))
# [9, 9, 9, 9, 9, 9]
print(list(itertools.accumulate(sample, operator.mul)))
# [9, 45, 180, 1080, 8640, 77760] 前缀乘积
print(list(itertools.accumulate(range(1, 11), operator.mul)))
# [1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800]
print(list(enumerate("abc", start=2)))
# [(2, 'a'), (3, 'b'), (4, 'c')]
print(list(map(operator.mul, range(11), range(1, 11))))
# x*(x+1) 对应相乘,元素少的结束即停止
print(list(map(lambda a, b: (a, b), range(11), [2, 4, 8])))
# [(0, 2), (1, 4), (2, 8)] 等效于 zip 函数
print(list(itertools.starmap(operator.mul, enumerate('abc', 1))))
# ['a', 'bb', 'ccc']
sample = [2, 3, 4, 5]
print(list(itertools.starmap(lambda a, b: b / a, enumerate(itertools.accumulate(sample), 1))))
# 求累积 均值 [2.0, 2.5, 3.0, 3.5]
3.3 合并

print(list(itertools.chain("ABC", range(5))))
# ['A', 'B', 'C', 0, 1, 2, 3, 4] , 可传入多个可迭代对象
print(list(itertools.chain(enumerate('ABC'))))
# [(0, 'A'), (1, 'B'), (2, 'C')] 传入一个参数,没啥用
print(list(itertools.chain.from_iterable(enumerate('ABC'))))
# 只接收一个参数,且对象是可迭代的
# [0, 'A', 1, 'B', 2, 'C']
print(list(zip('ABC', range(5))))
# [('A', 0), ('B', 1), ('C', 2)] 短的先结束
print(list(zip('ABC', range(5), [10, 20, 30, 40])))
# [('A', 0, 10), ('B', 1, 20), ('C', 2, 30)] 课输入多个参数
print(list(itertools.zip_longest('ABC', range(5))))
# [('A', 0), ('B', 1), ('C', 2), (None, 3), (None, 4)], 以最长的为结束
print(list(itertools.zip_longest('ABC', range(5), fillvalue='?')))
# [('A', 0), ('B', 1), ('C', 2), ('?', 3), ('?', 4)] 填充默认值
# 笛卡尔积,惰性生成
print(list(itertools.product('ABC', range(2))))
# [('A', 0), ('A', 1), ('B', 0), ('B', 1), ('C', 0), ('C', 1)]
print(list(itertools.product('ABC')))
# [('A',), ('B',), ('C',)] 传入一个参数,得到只有一个元素的元组,没啥用
print(list(itertools.product('ABC', repeat=2)))
# [('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'), ('B', 'C'), ('C', 'A'), ('C', 'B'), ('C', 'C')]
# 相当于两重循环
print(list(itertools.product(range(2), repeat=3)))
# [(0, 0, 0), (0, 0, 1), (0, 1, 0), (0, 1, 1), (1, 0, 0), (1, 0, 1), (1, 1, 0), (1, 1, 1)]
# 3 重循环
rows = itertools.product('AB', range(2), repeat=2)
for row in rows: print(row)
# ('A', 0, 'A', 0)
# ('A', 0, 'A', 1)
# ('A', 0, 'B', 0)
# ('A', 0, 'B', 1)
# ('A', 1, 'A', 0)
# ('A', 1, 'A', 1)
# ('A', 1, 'B', 0)
# ('A', 1, 'B', 1)
# ('B', 0, 'A', 0)
# ('B', 0, 'A', 1)
# ('B', 0, 'B', 0)
# ('B', 0, 'B', 1)
# ('B', 1, 'A', 0)
# ('B', 1, 'A', 1)
# ('B', 1, 'B', 0)
# ('B', 1, 'B', 1)
print("-----")
for a in "AB":for b in range(2):for c in "AB":for d in range(2):print((a, b, c, d))
# ('A', 0, 'A', 0)
# ('A', 0, 'A', 1)
# ('A', 0, 'B', 0)
# ('A', 0, 'B', 1)
# ('A', 1, 'A', 0)
# ('A', 1, 'A', 1)
# ('A', 1, 'B', 0)
# ('A', 1, 'B', 1)
# ('B', 0, 'A', 0)
# ('B', 0, 'A', 1)
# ('B', 0, 'B', 0)
# ('B', 0, 'B', 1)
# ('B', 1, 'A', 0)
# ('B', 1, 'A', 1)
# ('B', 1, 'B', 0)
# ('B', 1, 'B', 1) 跟上面结果一致

ct = itertools.count()
print(next(ct), next(ct), next(ct), next(ct), next(ct))
# 0 1 2 3 4
print(list(itertools.islice(itertools.count(1, .3), 3)))
# [1, 1.3, 1.6]
cy = itertools.cycle('ABC')
print(next(cy), next(cy), next(cy), next(cy))
# A B C A, 产生元素的副本,不断重复
print(list(itertools.islice(cy, 7)))
# ['B', 'C', 'A', 'B', 'C', 'A', 'B']
rp = itertools.repeat(7)
print(list(itertools.islice(rp, 10)))
# [7, 7, 7, 7, 7, 7, 7, 7, 7, 7]
print(list(itertools.repeat(8, 4)))
# [8, 8, 8, 8]
print(list(map(operator.mul, range(11), itertools.repeat(5))))
# [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50] 0-10 分别乘以5
3.4 排列组合
print(list(itertools.combinations("ABC", 2)))
# [('A', 'B'), ('A', 'C'), ('B', 'C')]
# 组合:从中取出2个的方案数,无序要求 C32
print(list(itertools.combinations_with_replacement("ABC", 2)))
# [('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'B'), ('B', 'C'), ('C', 'C')]
# 组合:无序,可重复
print(list(itertools.permutations("ABC", 2)))
# [('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')]
# 排列:有顺序要求
print(list(itertools.product("ABC", repeat=2))) # 的笛卡儿积
# [('A', 'A'), ('A', 'B'), ('A', 'C'),
# ('B', 'A'), ('B', 'B'), ('B', 'C'),
# ('C', 'A'), ('C', 'B'), ('C', 'C')]
3.5 重新排列
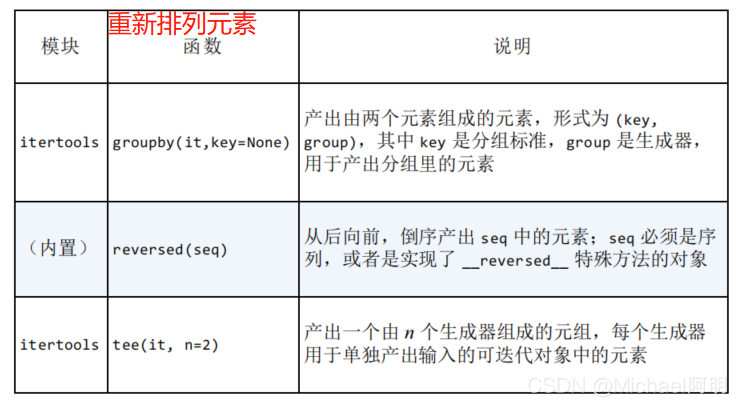
print(list(itertools.groupby("LLLLAAGGG")))
# [('L', <itertools._grouper object at 0x000001A6D638C460>),
# ('A', <itertools._grouper object at 0x000001A6D6538E80>),
# ('G', <itertools._grouper object at 0x000001A6D8F7EA00>)]
for char, group in itertools.groupby("LLLLAAGGG"):print(char, "->", list(group))# L -> ['L', 'L', 'L', 'L']
# A -> ['A', 'A']
# G -> ['G', 'G', 'G']for char, group in itertools.groupby("ALLLLAAGGG"):print(char, "->", list(group))
# A -> ['A'] # 没有相邻的A
# L -> ['L', 'L', 'L', 'L']
# A -> ['A', 'A']
# G -> ['G', 'G', 'G']animals = ['duck', 'eagle', 'rat', 'giraffe', 'bear', 'bat', 'dolphin', 'shark', 'lion']
animals.sort(key=len) # 按长度排序
print(animals)
# ['rat', 'bat', 'duck', 'bear', 'lion', 'eagle', 'shark', 'giraffe', 'dolphin']
for length, group in itertools.groupby(animals, len):print(length, "->", list(group))
# 3 -> ['rat', 'bat']
# 4 -> ['duck', 'bear', 'lion']
# 5 -> ['eagle', 'shark']
# 7 -> ['giraffe', 'dolphin']
for length, group in itertools.groupby(reversed(animals), len):print(length, "->", list(group))
# 7 -> ['dolphin', 'giraffe']
# 5 -> ['shark', 'eagle']
# 4 -> ['lion', 'bear', 'duck']
# 3 -> ['bat', 'rat']
abc = ["apple", "bear", "animals", "bull", "lakers"]
abc.sort()
for char, group in itertools.groupby(abc, lambda x: x[0]):print(char, "->", list(group))
# 按首字母分组
# a -> ['animals', 'apple']
# b -> ['bear', 'bull']
# l -> ['lakers']
# itertools.tee 函数产出多个生成器,每个生成器都 可以产出输入的各个元素
# 默认2个,后面可加参数 n, 输出多个
print(list(itertools.tee("ABC")))
# [<itertools._tee object at 0x000001D4AEEE8AC0>,
# <itertools._tee object at 0x000001D4AEEE8A80>]
g1, g2 = itertools.tee("ABC")
print(next(g1)) # A
print(list(g1)) # ['B', 'C']
print(next(g2), next(g2)) # A B
print(list(g2)) # ['C']
print(list(zip(*itertools.tee('ABC'))))
# [('A', 'A'), ('B', 'B'), ('C', 'C')]
4. yield from
yield from 语句的作用就是把不同的生成器结合在一起使用
def chain(*iterables):for it in iterables:for i in it:yield i
s = "ABC"
t = tuple(range(3))
print(list(chain(s, t)))
# ['A', 'B', 'C', 0, 1, 2]def chain1(*iterables):for it in iterables:yield from it# 完全代替了内层的 for 循环
print(list(chain1(s, t)))
# ['A', 'B', 'C', 0, 1, 2]
5. 可迭代的归约函数
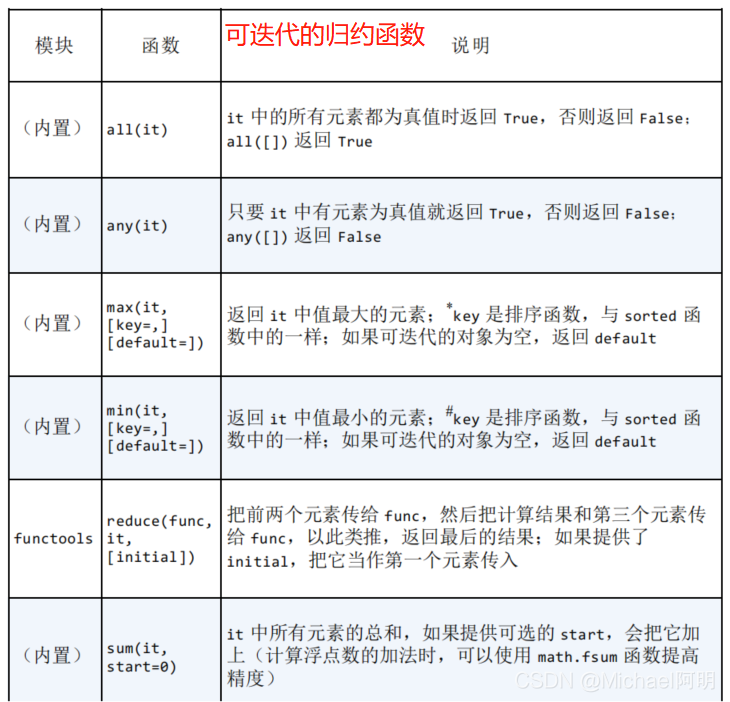
any, all可以短路,一旦确定结果,就停止迭代- 也可以这样调用
max(arg1, arg2, ..., [key=?]) sorted操作完成后返回排序后的 列表。它可以处理任意的可迭代对象
print(all([1, 2, 3])) # True
print(all([0, 2, 3])) # False
print(all([])) # True
print(any([1, 2, 3])) # True
print(any([0, 2, 3])) # True
print(any([0, 0.0])) # False
print(any([])) # False
g = (n for n in [0, 0.0, 7, 8])
print(any(g)) # True 遇到7结束
print(list(g)) # [8] 还剩余8
6. iter 还可以传入2个参数
- 当遇到第二个参数时停止迭代
def d6():return random.randint(1, 6)d6_iter = iter(d6, 1) # 无参函数, 遇到1停止迭代
for roll in d6_iter:print(roll)
# 6
# 2
# 4
# 3
# 2
# 4
# 3
# 5
# 2
# 3
print(list(d6_iter)) # [] 耗尽了
d6_iter = iter(d6, 1)
print(list(d6_iter)) # [4, 5, 3, 6, 2, 5, 4, 6, 5, 6, 6] 随机的
这段代码逐行读取文件,直到遇到空行或者到达文件末尾为止
with open('mydata.txt') as fp:for line in iter(fp.readline, '\n'):process_line(line)
7. 生成器当成协程
.send()方法,后面会学到- 与
.__next__()方法一样,.send()方法致使生成器前进到下一个 yield 语句 .send()方法还允许使用生成器的客户 把 数据 发给 自己,即不管传给.send()方法什么参数,那个参数都会 成为生成器 函数定义体中对应的 yield 表达式的值



)











)
:数据输入与输出)

)
