如今很多有编程能力的小伙伴已经不满足手动搜索内容了,都希望通过编写爬虫软件来快速获取需要的内容,那么如何使用python制作爬虫呢?下面小编给大家讲解一下思路
工具/原料
python
方法/步骤
1
首先我们需要确定要爬取的目标页面内容,如下图所示比如要获取温度值
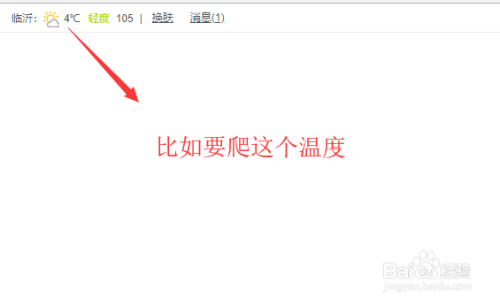
2
然后我们需要打开浏览器的F12,查找所要获取内容的特征,比如他有哪些样式标签或者ID属性
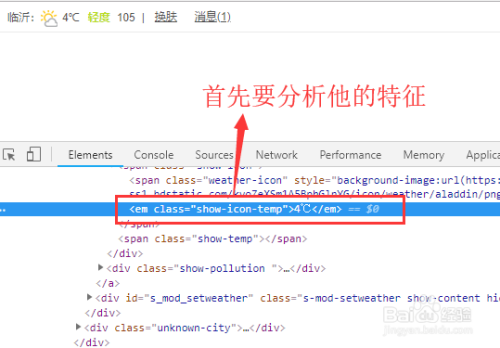
3
接下来我们打开cmd命令行界面,导入requests库和html库,如下图所示,这个lxml需要大家自行下载安装
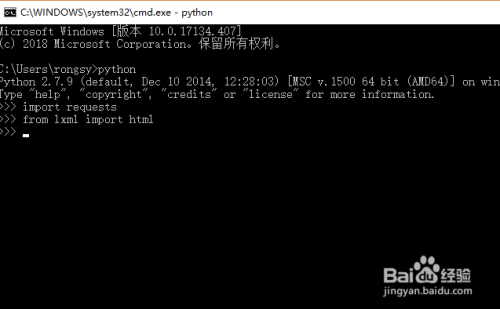
4
接着就是通过requests库将页面内容获取过来,然后用lxml下的html将其转化为文本,如下图所示
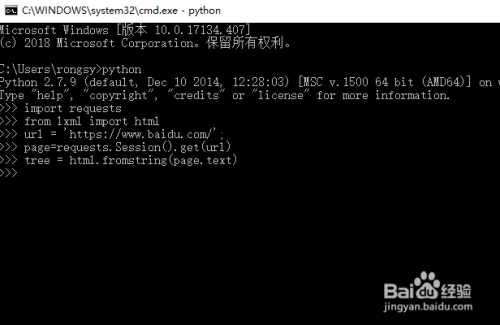
5
接下来就是通过xpath语法进行特定元素内容的查找,这里一般会用到class或者id的名称,如下图所示
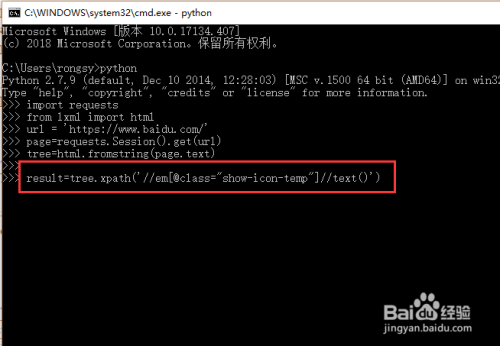
6
最后运行程序就可以获取到需要的内容了,如下图所示
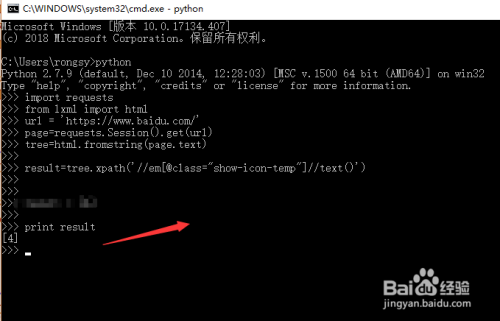
7
综上所述,运用python制作爬虫主要是运用requests获取内容,然后根据内容进行特定元素查找,这只是最简单的流程,不过即使在复杂的爬虫也是这几步
END
经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。
举报作者声明:本篇经验系本人依照真实经历原创,未经许可,谢绝转载。
展开阅读全部











)






![一条龙操作有效解决PermissionError: [WinError 5] 拒绝访问的问题](http://pic.xiahunao.cn/一条龙操作有效解决PermissionError: [WinError 5] 拒绝访问的问题)
