
管道方式是Transformers库中高度集成的极简使用方式。使用这种方式来处理NLP任务,只需要编写几行代码就能实现。通过本例的练习可以使读者对Transformers库的使用快速上手。
1 在管道方式中指定NLP任务
Transfomers库的管道方式使用起来非常简单,核心步骤只有两步:
(1)直接根据NLP任务对pipeline类进行实例化,便可以得到能够使用的模型对象。
(2)将文本输入模型对象,进行具体的NLP任务处理。
1.1 管道方式的工作原理
在Transformers库中pipeline类的源码文件pipelines.py里,可以找到管道方式自动下载的预编译模型地址。可以根据这些地址,使用第三方下载工具将其下载到本地。
1.1.1 pipelines配置文件的位置
虚拟环境文件夹\Lib\site-packages\transformers\pipelines\__init__.py1.1.2 文件视图
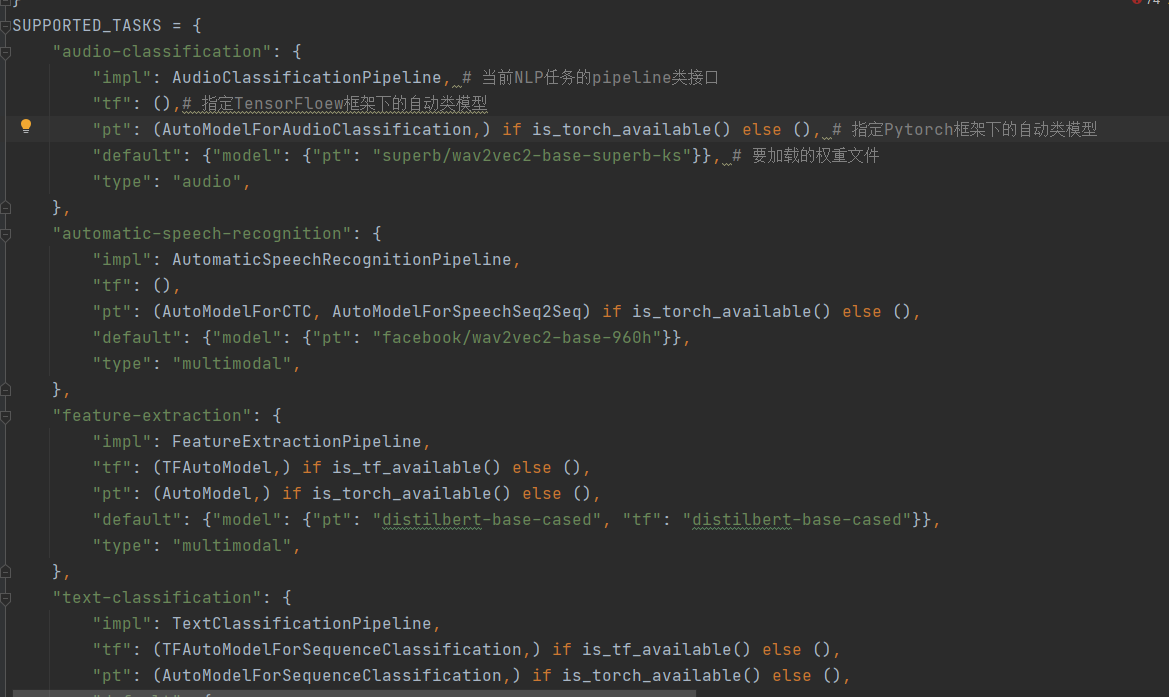
1.1.3 管道文件配置
# 在SUPPORTED_TASKS对象中,每个字典元素的key值方NLP任务名称,每个字典元素的value值为该NLP任务的具体配置。SUPPORTED_TASKS = {"audio-classification": {"impl": AudioClassificationPipeline, # 当前NLP任务的pipeline类接口"tf": (),# 指定TensorFloew框架下的自动类模型"pt": (AutoModelForAudioClassification,) if is_torch_available() else (), # 指定Pytorch框架下的自动类模型"default": {"model": {"pt": "superb/wav2vec2-base-superb-ks"}}, # 要加载的权重文件"type": "audio",},1.1.4 管道方式的内部调用关系
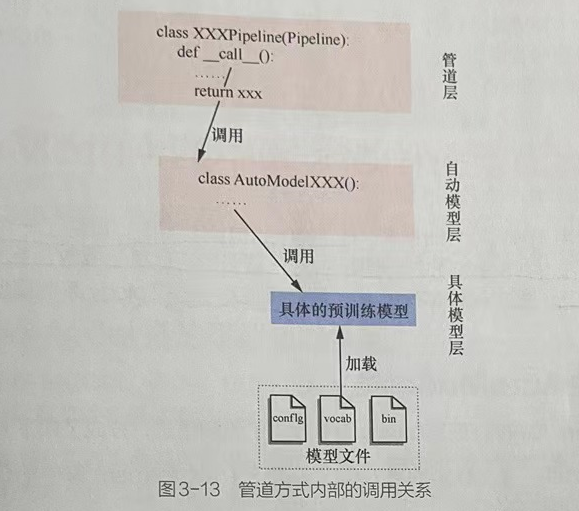
1.1.5 pipeline类接口
XXXPipeline类为每个NLP任务所对应的类接口,该接口与具体的NLP任务的对应关系如下:
- 文本分类任务:类接口为TextClassificationPipeline
- 特征提取任务:类接口为FeatureExtractionPipeline
- 完形填空任务:类接口为FillMaskPipeline
- 阅读理解任务:类接口为QuestionAnsweringPipeline
- 实体词识别任务:类接口为NerPipeline
管道层对下层的自动模型层进行了二次封装,完成了NLP任务的端到端实现。
1.2 在管道方式中加载指定模型
在实际应用中,也可以修改SUPPORTED._TASKS对象中的设置加载指定模型;还可以按照实例中的手动加载模型方式,加载本地已有的预训练模型。
1.2.1 加载指定模型的通用语法
# <task-name>代表任务字符串,如文本分类任务就是“sentiment--anaysis:
# <model name>:代表加载的模型:在手动加载模式下,<model name>可以是本地的预训练模型文件;在自动加载模式下,<model name>是预训练模型的唯一标识符。
pipeline("<task-name>",model="<model-name>")
pipeline('<task-name>',model='<model name>',tokenizer='<tokenizer_name>')2 文本分类任务
2.1 文本分类的定义
文本分类是指模型可以根据文本中的内容来进行分类。文本分类模型一般是通过有监督训练得到的。对文本内容的具体分类方向,依赖于训练时所使用的样本标签。
2.1.1 文本分类的举例
如根据内容对情绪分类、根据内容对商品分类等。
2.2 代码实现:完成文本分类任务
# 代码实现:完成文本分类任务
from transformers import *
nlp = pipeline("sentiment-analysis") # 文本分类模型
print(nlp("I like this book!"))
# [{'label': 'POSITIVE', 'score': 0.9998674392700195}]
# 输出结果的前两行是下载模型的信息,最后一行是模型输出的结果。3 特征提取任务
3.1 特征提取的含义
特征提取任务只返回文本处理后的特征,属于预训练模型范畴。
特征提取任务的输出结果需要结合其他模型一起工作,不是端到端解决任务的模型,对句子进行特征提取后的结果可以当作词向量来使用。
3.2 torchtext库的内置预训练词向量与管道方式来完成特征提取的对比
- 直接使用torchtext库的内置预训练词向量进行转化,也可以得到类似形状的结果。直接使用内置预训练词向量进行转化的方式对算力消耗较小,但需要将整个词表载入内存,对内存消耗较大。
- 使用管道方式来完成特征提取任务,只适用于数据预处理阶段。虽然会消耗一些算力,但是内存占用相对可控(只是模型的空间大小),如果再配合剪枝压缩等技术,更适合工程部署。如果要对已有的BERTology注意系列模型进行微调——对Transformers库中的模型进行再训练,还需要使用更底层的类接口。
3.3 代码实现:完成特征提取任务
# 代码实现:完成特征提取任务
from transformers import *
import numpy as np
nlp_features = pipeline('feature-extraction')
output = nlp_features('Shanxi University is a university in Shanxi.')
print(np.array(output).shape)
# (1, 12, 768)4 完形填空/遮蔽语言建模任务
4.1 完形填空/遮蔽语言建模任务的定义
它属于BERT模型在训练过程中的一个子任务。
4.2 任务概述
在训练BERT模型时,利用遮蔽语言的方式,先对输入序列文本中的单词进行随机遮蔽,并将遮蔽后的文本输入模型,令模型根据上下文中提供的其他非遮蔽词预测遮蔽词的原始值。一旦BERT模型训练完成,即可得到一个能够处理完形填空任务的模型MLM。
4.3 代码实现:完成完形填空任务
# 代码实现:完成完形填空任务
from transformers import *
nlp_fill = pipeline("fill-mask") # 文本分类模型
print(nlp_fill.tokenizer.mask_token)
print(nlp_fill(f"Li Jinhong wrote many {nlp_fill.tokenizer.mask_token} about artificial intelligence technology and helped many people."))# 从输出结果中可以看出,模型输出了分值最大的前5名结果。其中第1行的结果预测出了被遮蔽的单词为books
# [{'score': 0.5444340109825134, 'token': 2799, 'token_str': ' books', 'sequence': 'Li Jinhong wrote many books about artificial intelligence technology and helped many people.'},
# {'score': 0.32027241587638855, 'token': 7201, 'token_str': ' articles', 'sequence': 'Li Jinhong wrote many articles about artificial intelligence technology and helped many people.'},
# {'score': 0.024945968762040138, 'token': 27616, 'token_str': ' essays', 'sequence': 'Li Jinhong wrote many essays about artificial intelligence technology and helped many people.'},
# {'score': 0.021165795624256134, 'token': 6665, 'token_str': ' papers', 'sequence': 'Li Jinhong wrote many papers about artificial intelligence technology and helped many people.'},
# {'score': 0.018288355320692062, 'token': 22064, 'token_str': ' blogs', 'sequence': 'Li Jinhong wrote many blogs about artificial intelligence technology and helped many people.'}]
5 阅读理解/问答任务
5.1 阅读理解/问答任务的定义
阅读理解任务/问答任务,即输入一段文本和一个问题,令模型输出结果。
5.2 代码实现:完成阅读理解任务
# 代码实现:完成阅读理解任务
from transformers import *
nlp_qa = pipeline("question-answering")
context = 'Shanxi University is a university in Shanxi.'
question = 'Where is Shanxi University?'
print(nlp_qa(context = context,question = question))
# {'score': 0.926823079586029, 'start': 37, 'end': 43, 'answer': 'Shanxi'}6 摘要生成任务
6.1 摘要生成的定义
摘要生成任务的输入是一段文本,输出是一段相对于输入较短的文字。
6.2 代码实现:完成摘要生成任务
# 代码实现:完成摘要生成任务【太大了,没运行】
from transformers import *
TEXT_TO_SUMMARIZE = '''
In this notebook we will be using the transformer model, first introduced in this paper. Specifically, we will be using the BERT (Bidirectional Encoder Representations from Transformers) model from this paper.
Transformer models are considerably larger than anything else covered in these tutorials. As such we are going to use the transformers library to get pre-trained transformers and use them as our embedding layers. We will freeze (not train) the transformer and only train the remainder of the model which learns from the representations produced by the transformer. In this case we will be using a multi-layer bi-directional GRU, however any model can learn from these representations.
'''
summarizer = pipeline('summarization')
print(summarizer(TEXT_TO_SUMMARIZE))7 实体词识别任务
7.1 实体词识别的定义
实体词识别任务是NLP中的基础任务。它用于识别文本中的人名(PER)、地名(LOC)、组织(ORG)以及其他实体(MISC)等。
实体词识别任务本质上是一个分类任务,它又被称为序列标注任务。实体词识别是句法分析的基础,同时句法分析也是NLP任务的核心。
7.2 代码实现:完成实体词识别任务
# 代码实现:完成实体词识别任务【太大了,没运行】
from transformers import *
nlp_token_class = pipeline("ner")
print(nlp_token_class('Shanxi University is a university in Shanxi.'))8 预训训练模型文件的组成及其加载时的固定文件名称
在pipeline类的初始化接口中,还可以直接指定如载模型的路径,从本地预训练模型进行载入,要求要载入的预训练模型文件心须使用固定的文件名称。
8.1 固定文件名称要求
在pipeline类接口中,预训练模型文件是以套为单位的,每套训练模型文件的组成及其固定的文件名称如下:
- 词表文件:以.txt、.mode或json为扩展名,存放模型中使用的词表文件。固定文件名称为vocab.txt、spiece.model:或vocab.json。
- 词表扩展文件(可选)上以.txt为扩展名,补充原有的词表文件。固定文件名称为merges.txt。
- 配置文件:以json为扩展名,存放模型的超参数配置。固定文件名称为coig,json。
- 权重文件:以.bin加为扩展名,存放模型中各个参数具体的值。固定文件名称为pytorch_model.bin。
8.2 加载模型的步骤
当通过指定预训练模型目录进行加载时,系统只会在目录里搜索固定名称的模型文件,当没有找到固定名称的模型文件时,将返回错误。
8.3 代码实现:加载自定义模型,并完成预测
# 代码实现:完成摘要生成任务
# 在摘要任务的基础上,加载自定义模型,并完成预测。from transformers import *TEXT_TO_SUMMARIZE = '''
In this notebook we will be using the transformer model, first introduced in this paper. Specifically, we will be using the BERT (Bidirectional Encoder Representations from Transformers) model from this paper.
Transformer models are considerably larger than anything else covered in these tutorials. As such we are going to use the transformers library to get pre-trained transformers and use them as our embedding layers. We will freeze (not train) the transformer and only train the remainder of the model which learns from the representations produced by the transformer. In this case we will be using a multi-layer bi-directional GRU, however any model can learn from these representations.
'''
# 官方模板
# summarizer = pipeline('summarization')
# 自定义模板
tokenizer = AutoTokenizer.from_pretrained(r'./bart-large-cnn/')
summarizer = pipeline("summarization", model=r'./bart-large-cnn/', tokenizer=tokenizer)
print(summarizer(TEXT_TO_SUMMARIZE))

)






![一条龙操作有效解决PermissionError: [WinError 5] 拒绝访问的问题](http://pic.xiahunao.cn/一条龙操作有效解决PermissionError: [WinError 5] 拒绝访问的问题)






——基础使用)


