【编者按】本文作者为 John Matson,主要介绍 mysql 性能监控应该关注的 4 大指标。 文章系国内 ITOM 管理平台 OneAPM 编译呈现。
MySQL 是什么?
MySQL 是现而今最流行的开源关系型数据库服务器。由 Oracle 所有,MySQL 提供了可以免费下载的社区版及包含更多特性与支持的商业版。从 1995 年首发以来,MySQL 衍生出多款备受瞩目的分支,诸如具有相当竞争力的 MariaDB 及 Percona。
关键 MySQL 统计指标
如果你的数据库运行缓慢,或者出于某种原因无法响应查询,技术栈中每个依赖数据库的组件都会遭受性能问题。为了保证数据库的平稳运行,你可以主动监控以下四个与性能及资源利用率相关的指标:
-
查询吞吐量
-
查询执行性能
-
连接情况
-
缓冲池使用情况
MySQL 用户可以接触到数百个数据库指标,因此,在本文中,笔者将专注于能帮助我们实时了解数据库健康与性能的关键指标。
本文参考了我们在监控入门系列文章中介绍的指标术语,后者为指标收集与告警提供了基础框架。
不同版本与技术的兼容性
本系列文章讨论的一些监控策略只适用于 MySQL 5.6 与 5.7 版本。这些版本间的差异将在后文中提及。
本文列出的大多数指标与监控策略同样适用于与 MySQL 兼容的技术,诸如 MariaDB 与 Percona 服务器,不过带有一些明显的差别。例如,MySQL Workbench(工作台) 中的一些特性(在本系列第二篇中有详细介绍)就与当下的一些 MariaDB 版本不兼容。
Amazon RDS 用户应该查看我们专门制作的 MySQL 在 RDS 以及与 MySQL 兼容的 Amazon Aurora监控手册。
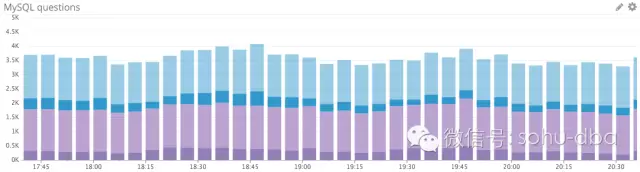
查询吞吐量
| 名称 | 描述 | 指标类型 | 可用性 |
|---|---|---|---|
| Questions | 已执行语句(由客户端发出)计数 | Work:吞吐量 | 服务器状态变量 |
| Com_select | SELECT 语句 | Work:吞吐量 | 服务器状态变量 |
| Writes | 插入,更新或删除 | Work:吞吐量 | 根据服务器状态变量计算得到 |
在监控任何系统时,你最关心的应该是确保系统能够高效地完成工作。数据库的工作是运行查询,因此在本例中,你的首要任务是确保 MySQL 能够如期执行查询。
MySQL 有一个名为 Questions 的内部计数器(根据 MySQL 用语,这是一个服务器状态变量),客户端每发送一个查询语句,其值就会加一。由 Questions 指标带来的以客户端为中心的视角常常比相关的Queries 计数器更容易解释。作为存储程序的一部分,后者也会计算已执行语句的数量,以及诸如PREPARE 和 DEALLOCATE PREPARE 指令运行的次数,作为服务器端预处理语句的一部分。
通过以下指令,查询诸如 Questions 或 Com_select 服务器状态变量的值:
SHOW GLOBAL STATUS LIKE "Questions"; +---------------+--------+ | Variable_name | Value | +---------------+--------+ | Questions | 254408 | +---------------+--------+
你也可以监控读、写指令的分解情况,从而更好地理解数据库的工作负载、找到可能的瓶颈。通常,读取查询会由 Com_select 指标抓取,而写入查询则可能增加三个状态变量中某一个的值,这取决于具体的指令:
Writes = Com_insert + Com_update + Com_delete
应该设置告警的指标:Questions
当前的查询速率通常会有起伏,因此,如果基于固定的临界值,查询速率常常不是一个可操作的指标。但是,对于查询数量的突变设置告警非常重要——尤其是查询量的骤降,可能暗示着某个严重的问题。
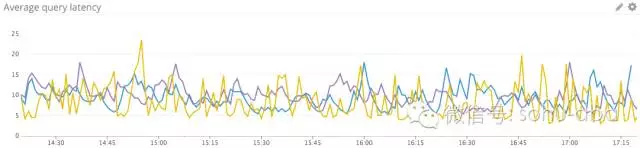
查询性能
| 名称 | 描述 | 指标类型 | 可用性 |
|---|---|---|---|
| 查询运行时间 | 每种模式下的平均运行时间 | Work:性能 | 性能模式查询 |
| 查询错误 | 出现错误的 SQL 语句数量 | Work:错误 | 性能模式查询 |
| Slow_queries | 超过可配置的long_query_time 限制的查询数量 | Work:性能 | 服务器状态变量 |
MySQL 用户监控查询延迟的方式有很多,既可以通过 MySQL 内置的指标,也可以通过查询性能模式。从 MySQL 5.6.6 版本开始默认启用,MySQL 的 performance_schema 数据库中的表格存储着服务器事件与查询执行的低水平统计数据。
性能模式语句摘要
性能模式的 events_statements_summary_by_digest 表格中保存着许多关键指标,抓取了与每条标准化语句有关的延迟、错误和查询量信息。从该表截取的一行样例显示,某条语句被执行了两次,平均执行用时为 325 毫秒(所有计时器的测量值都以微微秒为单位):
*************************** 1. row *************************** SCHEMA_NAME: employees DIGEST: 0c6318da9de53353a3a1bacea70b4fce DIGEST_TEXT: SELECT * FROM `employees` WHERE `emp_no` > ? COUNT_STAR: 2 SUM_TIMER_WAIT: 650358383000 MIN_TIMER_WAIT: 292045159000 AVG_TIMER_WAIT: 325179191000 MAX_TIMER_WAIT: 358313224000 SUM_LOCK_TIME: 520000000 SUM_ERRORS: 0 SUM_WARNINGS: 0 SUM_ROWS_AFFECTED: 0 SUM_ROWS_SENT: 520048 SUM_ROWS_EXAMINED: 520048... SUM_NO_INDEX_USED: 0 SUM_NO_GOOD_INDEX_USED: 0 FIRST_SEEN: 2016-03-24 14:25:32 LAST_SEEN: 2016-03-24 14:25:55
摘要表会标准化所有语句(如上面的 DIGEST_TEXT 一栏所示),忽略数据值,规范化空格与大小写,因此,下面的两条查询会被认为是相同的:
select * from employees where emp_no >200;
SELECT * FROM employees WHERE emp_no > 80000;
想要按模式抽取出以微秒为单位的平均运行时间,你可以这样查询性能模式:
SELECT schema_name, SUM(count_star) count , ROUND( (SUM(sum_timer_wait) / SUM(count_star)) / 1000000) AS avg_microsec FROM performance_schema.events_statements_summary_by_digest WHERE schema_name IS NOT NULL GROUP BY schema_name; +--------------------+-------+--------------+ | schema_name | count | avg_microsec | +--------------------+-------+--------------+ | employees | 223 | 171940 | | performance_schema | 37 | 20761 | | sys | 4 | 748 | +--------------------+-------+--------------+
相似地,按模式计算出现错误的语句总数,可以这么做:
SELECT schema_name, SUM(sum_errors) err_countFROM performance_schema.events_statements_summary_by_digest WHERE schema_name IS NOT NULL GROUP BY schema_name; +--------------------+-----------+ | schema_name | err_count | +--------------------+-----------+ | employees | 8 | | performance_schema | 1 | | sys | 3 | +--------------------+-----------+
sys 模式
用上面的方式查询性能模式能以编程方式有效地从数据库中检索出指标。然而,对于特别查询或调查,使用 MySQL 的 sys 模式通常更为简单。sys 模式以人们更易读的格式提供了一个有条理的指标集合,使得对应的查询更加简单。例如,想要找出最慢的语句(运行时间在 95 名开外):
SELECT * FROM sys.statements_with_runtimes_in_95th_percentile;
或者查看哪些标准化语句出现了错误:
SELECT * FROM sys.statements_with_errors_or_warnings;
在 sys 模式的文档中,详细介绍了许多有用的例子。sys 模式在 MySQL 5.7.7 版本中是默认包含的。不过,MySQL 5.6 用户通过简单的几个指令就能安装它。
慢查询
除了性能模式与 sys 模式中丰富的性能数据,MySQL 还提供了一个 Slow_queries 计数器,每当查询的执行时间超过 long_query_time 参数指定的值之后,该计数器就会增加。默认情况下,该临界值设置为 10 秒。
SHOW VARIABLES LIKE 'long_query_time'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+
long_query_time 参数的值可通过一条指令进行调整。例如,将慢查询临界值设置为 5 秒:
SET GLOBAL long_query_time = 5;
(请注意,你可能要关闭会话,再重新连接至数据库,这些更改才能在会话层生效。)
调查查询性能问题
如果你的查询运行得比预期要慢,很可能是某条最近修改的查询在捣鬼。如果没有发现特别缓慢的查询,接下来就该评估系统级指标,寻找核心资源(CPU,磁盘 I/O,内存以及网络)的限制。CPU 饱和与 I/O 瓶颈是常见的问题根源。你可能还想检查 Innodb_row_lock_waits 指标,该指标记录着 InnoDB 存储引擎不得不停下来获得某行的锁定的次数。从 MySQL 5.5 版本起,InnoDB 就是默认的存储引擎,MySQL 对 InnoDB 表使用行级锁定。
为了提高读取与写入操作的速度,许多用户会想通过调整 InnoDB 使用的缓冲池大小来缓存表与索引数据。本文的第二部分会对监控与调整缓冲池大小做详细解读。
应该设置告警的指标:
-
查询运行时间:管理关键数据库的延迟至关重要。如果生产环境中数据库的平均查询运行时间开始下降,应该寻找数据库实例的资源限制,行锁或表锁间可能的争夺,以及客户端查询模式的变化情况。
-
查询错误:查询错误的猛增可能暗示着客户端应用或数据库本身的问题。你可以使用 sys 模式快速查找可能导致问题的查询。例如,列举出返回错误数最多的 10 条标准化语句:
SELECT * FROM sys.statements_with_errors_or_warnings ORDER BY errors DESC LIMIT 10;
-
Slow_queries:如何定义慢查询(并由此设置long_query_time参数)取决于你的用户案例。但是,无论你如何定义 “慢”,你都会想知道慢查询的数量是否超出了基准水平。为了找出真正执行缓慢的查询,你可以询问 sys 模式,或深入了解 MySQL 提供的慢查询日志(该功能默认是禁用的)。有关启用并读取慢查询日志的更多信心,请参考 MySQL 文档。
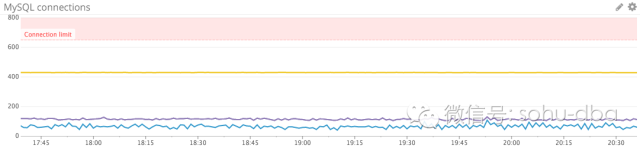
连接
| 名称 | 描述 | 指标类型 | 可用性 |
|---|---|---|---|
| Threads_connected | 当前开放的连接 | 资源: 利用率 | 服务器状态变量 |
| Threads_running | 当前运行的连接 | 资源: 利用率 | 服务器状态变量 |
| Connection_errors_internal | 由服务器错误导致的失败连接数 | 资源: 错误 | 服务器状态变量 |
| Aborted_connects | 尝试与服务器进行连接结果失败的次数 | 资源: 错误 | 服务器状态变量 |
| Connection_errors_max_connections | 由 max_connections 限制导致的失败连接数 | 资源: 错误 | 服务器状态变量 |
检查并设置连接限制
监控客户端连接情况相当重要,因为一旦可用连接耗尽,新的客户端连接就会遭到拒绝。MySQL 默认的连接数限制为 151,可通过下面的查询加以验证:
SHOW VARIABLES LIKE 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 151 | +-----------------+-------+
MySQL 的文档指出,健壮的服务器应该能够处理成百上千的连接数。
“常规情况下,Linux 或 Solaris 应该能够支持 500 到 1000 个同时连接。如果可用的 RAM 较大,且每个连接的工作量较低或目标响应时间较为宽松,则最多可处理 10000 个连接。而 Windows 能处理的连接数一般不超过 2048 个,这是由于该平台上使用的 Posix 兼容层。”
连接数限制可以在系统运行时进行调整:
SET GLOBAL max_connections = 200;
然而,此设置会在服务器重启时恢复为默认值。想要永久地改变连接数限制,可以在 my.cnf 配置文件中添加如下配置(查看本文了解如何定位配置文件):
max_connections = 200
监控连接使用率
MySQL 提供了 Threads_connected 指标以记录连接的线程数——每个连接对应一个线程。通过监控该指标与先前设置的连接限制,你可以确保服务器拥有足够的容量处理新的连接。MySQL 还提供了Threads_running 指标,帮助你分隔在任意时间正在积极处理查询的线程与那些虽然可用但是闲置的连接。
如果服务器真的达到 max_connections 限制,它就会开始拒绝新的连接。在这种情况下,Connection_errors_max_connections 指标就会开始增加,同时,追踪所有失败连接尝试的Aborted_connects 指标也会开始增加。
MySQL 提供了许多有关连接错误的指标,帮助你调查连接问题。Connection_errors_internal 是个很值得关注的指标,因为该指标只会在错误源自服务器本身时增加。内部错误可能反映了内存不足状况,或者服务器无法开启新的线程。
应该设置告警的指标
-
Threads_connected:当所有可用连接都被占用时,如果一个客户端试图连接至 MySQL,后者会返回 “Too many connections(连接数过多)” 错误,同时将Connection_errors_max_connections的值增加。为了防止出现此类情况,你应该监控可用连接的数量,并确保其值保持在max_connections限制以内。 -
Aborted_connects:如果该计数器在不断增长,意味着用户尝试连接到数据库的努力全都失败了。此时,应该借助Connection_errors_max_connections与Connection_errors_internal之类细粒度高的指标调查该问题的根源。
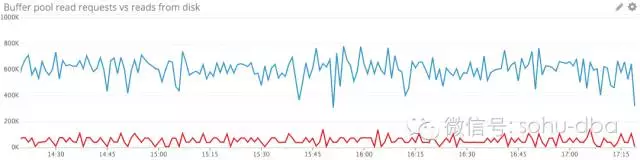
缓冲池使用情况
| 名称 | 描述 | 指标类型 | 可用性 |
|---|---|---|---|
| Innodb_buffer_pool_pages_total | 缓冲池中的总页数 | 资源: 利用率 | 服务器状态变量 |
| 缓冲池使用率 | 缓冲池中已使用页数所占的比率 | 资源: 利用率 | 根据服务器状态变量计算得到 |
| Innodb_buffer_pool_read_requests | 向缓冲池发送的请求 | 资源: 利用率 | 服务器状态变量 |
| Innodb_buffer_pool_reads | 缓冲池无法满足的请求 | 资源: 饱和度 | 服务器状态变量 |
MySQL 默认的存储引擎 InnoDB 使用了一片称为缓冲池的内存区域,用于缓存数据表与索引的数据。缓冲池指标属于资源指标,而非工作指标,前者更多地用于调查(而非检测)性能问题。如果数据库性能开始下滑,而磁盘 I/O 在不断攀升,扩大缓冲池往往能带来性能回升。
检查缓冲池的大小
默认设置下,缓冲池的大小通常相对较小,为 128MiB。不过,MySQL 建议可将其扩大至专用数据库服务器物理内存的 80% 大小。然而,MySQL 也指出了一些注意事项:InnoDB 的内存开销可能提高超过缓冲池大小 10% 的内存占用。并且,如果你耗尽了物理内存,系统会求助于分页,导致数据库性能严重受损。
缓冲池也可以划分为不同的区域,称为实例。使用多个实例可以提高大容量 (多 GiB) 缓冲池的并发性。
缓冲池大小调整操作是分块进行的,缓冲池的大小必须为块的大小乘以实例的数目再乘以某个倍数。
innodb_buffer_pool_size = N * innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances
块的默认大小为 128 MiB,但是从 MySQL 5.7.5 开始可以自行配置。以上两个参数的值都可以通过如下方式进行检查:
SHOW GLOBAL VARIABLES LIKE "innodb_buffer_pool_chunk_size"; SHOW GLOBAL VARIABLES LIKE "innodb_buffer_pool_instances";
如果 innodb_buffer_pool_chunk_size 查询没有返回结果,则表示在你使用的 MySQL 版本中此参数无法更改,其值为 128 MiB。
在服务器启动时,你可以这样设置缓冲池的大小以及实例的数量:
$ mysqld --innodb_buffer_pool_size=8G
--innodb_buffer_pool_instances=16
在 MySQL 5.7.5 版本,你可以通过 SET 指令在系统运行时修改缓冲池的大小,并精确到字节数。例如,假设有两个缓冲池实例,你可以将其总大小设置为 8 GiB,这样每个实例的大小即为 4 GiB。
SET GLOBAL innodb_buffer_pool_size=8589934592;
关键的 InnoDB 缓冲池指标
MySQL 提供了许多关于缓冲池及其利用率的指标。其中一些有用的指标能够追踪缓冲池的总大小,缓冲池的使用量,以及其处理读取操作的效率。
指标 Innodb_buffer_pool_read_requests 及 Innodb_buffer_pool_reads 对于理解缓冲池利用率都非常关键。Innodb_buffer_pool_read_requests 追踪合理读取请求的数量,而Innodb_buffer_pool_reads 追踪缓冲池无法满足,因而只能从磁盘读取的请求数量。我们知道,从内存读取的速度比从磁盘读取通常要快好几个数量级,因此,如果 Innodb_buffer_pool_reads 的值开始增加,意味着数据库性能大有问题。
缓冲池利用率是在考虑扩大缓冲池之前应该检查的重要指标。利用率指标无法直接读取,但是可以通过下面的方式简单地计算得到:
(Innodb_buffer_pool_pages_total - Innodb_buffer_pool_pages_free) / Innodb_buffer_pool_pages_total
如果你的数据库从磁盘进行大量读取,而缓冲池还有许多闲置空间,这可能是因为缓存最近才清理过,还处于热身阶段。如果你的缓冲池并未填满,但能有效处理读取请求,则说明你的数据工作集相当适应目前的内存配置。
然而,较高的缓冲池利用率并不一定意味着坏消息,因为旧数据或不常使用的数据会根据 LRU 算法 自动从缓存中清理出去。但是,如果缓冲池无法有效满足你的读取工作量,这可能说明扩大缓存的时机已至。
将缓冲池指标转化为字节
大多数缓冲池指标都以内存页面为单位进行记录,但是这些指标也可以转化为字节,从而使其更容易与缓冲池的实际大小相关联。例如,你可以使用追踪缓冲池中内存页面总数的服务器状态变量找出缓冲池的总大小(以字节为单位):
Innodb_buffer_pool_pages_total * innodb_page_size
InnoDB 页面大小是可调整的,但是默认设置为 16 KiB,或 16,384 字节。你可以使用 SHOW VARIABLES 查询了解其当前值:
SHOW VARIABLES LIKE "innodb_page_size";
结论
在本文中,我们介绍了许多你应该加以监控从而了解 MySQL 活动与性能表现的重要指标。如果你正在踌躇 MySQL 监控方案,抓取下面列出的指标能让你真正理解数据库的使用模式与可能的限制情况。这些指标也能帮助你发现,何时扩展服务器内存或将数据库移至更为强大的主机,从而保持良好的应用性能。
-
查询吞吐量
-
查询延迟与错误
-
客户端连接与错误
-
缓冲池利用率
鸣谢
非常感谢来自 Oracle 的 Dave Stokes 与 VividCortex 的 Ewen Fortune,他们在本文发布之前提供了许多宝贵的反馈意见。
本文系 OneAPM 工程师编译整理。OneAPM Cloud Insight 集监控、管理、计算、协作、可视化于一身,帮助所有 IT 公司,减少在系统监控上的人力和时间成本投入,让运维工作更加高效、简单。想技术文章,请访问 OneAPM 官方技术博客。
原文地址:https://www.datadoghq.com/blog/monitoring-mysql-performance-metrics/
http://blog.oneapm.com/apm-tech/754.html
http://blog.oneapm.com/apm-tech/755.html
)
)



)
Ubuntu14中安装GraphicsMagick)




性能对比 测试 。 Servlet的性能应该是最好的,可以做为参考基准,其它测试都要向它看齐,参照...)
--三种方案对比)





--结构光深度测距)
