1. 正则表达式概述
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
正则表达式,又称正规表示法、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
1.1 正则表达式的目的
- 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”)
- 可以通过正则表达式,从字符串中获取我们想要的特定部分
1.2 正则表达式的特点
- 灵活性、逻辑性和功能性非常的强;
- 可以迅速地用极简单的方式达到字符串的复杂控制。
- 对于刚接触的人来说,比较晦涩难懂。
由于正则表达式主要应用对象是文本,因此它在各种文本编辑器场合都有应用,小到著名编辑器EditPlus,大到Microsoft Word、Visual Studio等大型编辑器,都可以使用正则表达式来处理文本内容
2. 正则表达式基础知识
2.1 元字符
正则表达式主要依赖于元字符。
元字符不代表他们本身的字面意思, 他们都有特殊的含义。 一些元字符写在方括号中的时候有一些特殊的意思。 以下是一些元字符的介绍:
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符 |
| [ ] | 字符种类. 匹配方括号内的任意字符 |
| [^ ] | 否定的字符种类. 匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符 |
| + | 匹配>=1个重复的+号前的字符 |
| ? | 标记?之前的字符为可选 |
| {n,m} | 匹配num个中括号之前的字符 (n <= num <= m) |
| (xyz) | 字符集, 匹配与 xyz 完全相等的字符串 |
| | | 或运算符,匹配符号前或后的字符 |
| \ | 转义字符,用于匹配一些保留的字符 `[ ] ( ) { } . * + ? ^ $ \ |
| ^ | 从开始行开始匹配 |
| $ | 从末端开始匹配 |
2.2 常见符号
2.2.1 字符
| 符号 | 说明 |
|---|---|
| X | 字符X |
| \\ | 反斜线 |
| \t | 制表符 (‘\u0009’) |
| \n | 回车 |
| \r | 换行 |
| \f | 换页符 (‘\u000C’) |
| \a | 报警 (bell) 符 (‘\u0007’) |
2.2.2 字符类
| 符号 | 说明 |
|---|---|
| [abc] | a、b或c |
| [^abc] | 任何字符,除了a、b或c |
| [a-zA-Z] | a到z,或A到Z |
| [0-9] | 0到9的字符 |
| [a-d[m-p]] | a到 d或 m 到 p:[a-dm-p](并集) |
| [a-z&&[def]] | d、e或 f(交集) |
| [a-z&&[^bc]] | a到 z,除了 b和 c:[ad-z](减去) |
| [a-z&&[^m-p]] | a到 z,而非 m到 p:[a-lq-z](减去) |
| \u4E00-\u9FA5 | 中文字符 |
2.2.3 预定义字符
| 符号 | 说明 |
|---|---|
| . | 任何字符 |
| \d | 数字:[0-9] |
| \D | 非数字: [^0-9] |
| \s | 空白字符:[ \t\n\x0B\f\r] |
| \S | 非空白字符:[^\s] |
| \w | 单词字符:[a-zA-Z_0-9] |
| \W | 非单词字符:[^\w] |
2.3 中括号表达式
范围匹配,一种特殊的匹配单个字符的方法。
- 即[ ]表达式,用来匹配单个字符,只不过这一个字符的所在范围有中括号内的表达式来确定
- 枚举:
[abc],表示匹配a、b、c的任意一个 - 范围:
[a-f],表示匹配a-f之间的任意一个字符,包括边界,其中右边界一定要≥左边界,否则引擎编译错误 - 并:
[a-cm-p],就表示a-c的范围和m-p的范围求并,其实前面的abc之类的枚举也是一种并运算 - 交:
[a-z&&b-d],就表示a-z的范围和b-d的范围求交,结果等于[b-d] - 补:
[^abc]表示非a、b、c的任意一个字符,[^a-f]表示非a-f的任一字符;^也是一个脱字符,必须是中括号表达式的第一个字符,否则不起任何作用。补的是^后面紧跟的整个表达式。 - 嵌套:
[a-m&&[def]],a-m和[def]都表示范围,因此可以做运算,结果等于[d-f] - 有了上面这些基本运算,就可以构造一些很复杂的运算了:
[a-z&&[^bc]] == [ad-z],但是注意不要用^构造复杂表达式,以下一些表达式将不起作用!^后面紧跟一个[ ]嵌套:^[a-d],非法!不起任何作用^后面是一个运算(交并补):^a-cf-h、^a-z&&c-h、^^a-c,都是非法的!!不起任何作用!!^后面只能跟单纯的枚举和范围运算!!例如[^azh]、[^a-h]等;
2.4 边界匹配器
| 符号 | 说明 |
|---|---|
| ^ | 行开头 |
| $ | 行结尾 |
| \b | 单词边界 |
| \B | 非单词边界 |
| \A | 输入的开头 |
| \G | 上一个匹配的结尾 |
| \Z | 输入的结尾,仅用于最后的结束符(如果有的话) |
| \z | 输入的结尾 |
2.4.1 贪婪与懒惰数量词
- 贪婪数量词
| 符号 | 说明 |
|---|---|
| X? | 0次或1次 |
| X* | 0次以上 |
| X+ | 1次以上 |
| X{n} | 恰好n次 |
| X{n,} | 至少n次 |
| X{n,m} | n-m次 |
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。在贪婪数量词后面加上?就是懒惰匹配。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权——The match that begins earliest wins。
- 懒惰限定符
| 代码/语法 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
2.4.2 分组和捕获
分组可以分为两种形式,捕获组和非捕获组。
1、捕获组
捕获组可以通过从左到右计算其开括号来编号。例如,在表达式 ((A)(B©))中,存在四个这样的组:
- 分组0:
((A)(B(C))) - 分组1:
(A) - 分组2:
(B(C)) - 分组3:
(C)
正则表达式中每个"()"内的部分算作一个捕获组,每个捕获组都有一个编号,从1,2…,编号0代表整个匹配到的内容,组零始终代表整个表达式。
之所以这样命名捕获组是因为在匹配中,保存了与这些组匹配的输入序列的每个子序列。捕获的子序列稍后可以通过 Back 引用(反向引用) 在表达式中使用,也可以在匹配操作完成后从匹配器检索。
Back引用(\n)是说在后面的表达式中我们可以使用组的编号来引用前面的表达式所捕获到的文本序列。注意:反向引用,引用的是前面捕获组中的文本而不是正则,也就是说反向引用处匹配的文本应和前面捕获组中的文本相同,这一点很重要。
例如 ([" ']).*\1 其中使用了分组,\1就是对引号这个分组的引用,它匹配包含在两个引号或者两个单引号中的所有字符串,如,“abc” 或 "’ " 或’ " ’ ,但是请注意,它并不会对"a’或者 'a"匹配。原因上面已经说明,Back引用只是引用文本而不是表达式。
捕获组的作用就是为了可以在正则表达式内部或者外部(Java方法)引用它。在另一个字符串引用捕获组的内容的方法(“$”),在替换中常用$匹配组的内容。$n用来匹配第n个()里的内容。
利用Matcher中的group(int group)获取捕获组内容。
2、捕获组命名
如果捕获组的数量非常多,那都用数字进行编号并引用将会非常混乱,并且难以记忆每个捕获组的内容及意义,因此对捕获组命名显得尤为重要;Java 7开始提供了对捕获组命名的语法,并且可以通过捕获组的名称对捕获组反向引用(内外都行)。
命名捕获组的语法格式:(?<自定义名>expr),例如:(?<year>\d{4})-(?<date>\d{2}-(?<day>\d{2})),有三个命名捕获组year、date和day,从左到右编号分别为1、2、3(编号同样是有效的)
命名捕获组的反向引用:
- 正则表达式内引用:
\k<捕获组名称>,例如:(?<year>\d{4})-\k<year>可以匹配1999-1999; - 外部引用:Matcher对象的start、end、group的String name参数指定要查询的捕获组的名称。
普通捕获组和命名捕获组的混合编号:
- 普通捕获组是相对命名捕获组的,即没有显式命名的捕获组;
- 当所有捕获组都是命名捕获组时那么编号规则和原来相同,即按照左括号(的出现顺序来编号;
- 当普通捕获组和命名捕获组同时出现时,编号规则为:先不忽略命名捕获组,只对普通捕获组按照左括号顺序编号,然后再对命名捕获组从左往右累计编号,例如:先忽略命名命名捕获组
<date>,先对普通捕获组编号\d{4}是1,\d\d是2,然后再接着累加地对命名捕获组编号,因此<date>是3;
3、非捕获组
非捕获组,只需要将捕获组中"()“变为”(?:)"即可。
以 (?) 开头的组是纯的非捕获组,它不捕获文本 ,也不针对组合计进行计数。就是说,如果小括号中以?号开头,那么这个分组就不会捕获文本,当然也不会有组的编号,因此也不存在Back引用。
我们通过捕获组就能够得到我们想要匹配的内容了,那为什么还要有非捕获组呢?原因是捕获组捕获的内容是被存储在内存中,可供以后使用,比如反向引用就是引用的内存中存储的捕获组中捕获的内容。而非捕获组则不会捕获文本,也不会将它匹配到的内容单独分组来放到内存中。所以,使用非捕获组较使用捕获组更节省内存。在实际情况中我们要酌情选用。
2.5 前后关联约束(前后预查)
前置约束和后置约束都属于非捕获簇(用于匹配不在匹配列表中的格式)。 前置约束用于判断所匹配的格式是否在另一个确定的格式之后。
例如, 我们想要获得所有跟在 $ 符号后的数字, 我们可以使用正向向后约束 (?<=\$)[0-9\.]*。这个表达式匹配 $ 开头, 之后跟着 0,1,2,3,4,5,6,7,8,9,. 这些字符可以出现大于等于 0 次。
前后关联约束如下:
| 符号 | 描述 |
|---|---|
| ?= | 前置约束-存在 |
| ?! | 前置约束-排除 |
| ?<= | 后置约束-存在 |
| ?<! | 后置约束-排除 |
?=exp前置约束(存在)
?=exp 前置约束(存在), 表示第一部分表达式必须跟在 ?=exp 定义的表达式之后.
返回结果只瞒住第一部分表达式. 定义一个前置约束(存在)要使用 (). 在括号内部使用一个问号和等号: (?=exp).
前置约束的内容写在括号中的等号后面. 例如, 表达式 [T|t]he(?=\sfat) 匹配 The 和 the, 在括号中我们又定义了前置约束(存在) (?=\sfat) ,即 The 和 the 后面紧跟着 (空格)fat.
"[T|t]he(?=\sfat)" => The fat cat sat on the mat.
?!exp前置约束-排除
前置约束-排除 ?! 用于筛选所有匹配结果, 筛选条件为 其后不跟随着定义的格式 前置约束-排除 定义和 前置约束(存在) 一样, 区别就是 = 替换成 ! 也就是 (?!exp).
表达式 [T|t]he(?!\sfat) 匹配 The 和 the, 且其后不跟着 (空格)fat.
"[T|t]he(?!\sfat)" => The fat cat sat on the mat.
?<=exp后置约束-存在
后置约束-存在 记作(?<=exp)用于筛选所有匹配结果, 筛选条件为 其前跟随着定义的格式. 例如, 表达式 (?<=[T|t]he\s)(fat|mat) 匹配 fat 和 mat, 且其前跟着 The 或 the.
"(?<=[T|t]he\s)(fat|mat)" => The fat cat sat on the mat.
?<!exp后置约束-排除
后置约束-排除 记作 (?<!exp)用于筛选所有匹配结果, 筛选条件为 其前不跟着定义的格式. 例如, 表达式 (?<!(T|t)he\s)(cat)匹配 cat, 且其前不跟着 The 或 the.
"(?<![T|t]he\s)(cat)" => The cat sat on cat.
2.6 标志
标志也叫修饰语, 因为它可以用来修改表达式的搜索结果. 这些标志可以任意的组合使用, 它也是整个正则表达式的一部分.
| 标志 | 描述 |
|---|---|
| i | 忽略大小写. |
| g | 全局搜索. |
| m | 多行的: 锚点元字符 ^ $ 工作范围在每行的起始. |
忽略大小写 (Case Insensitive)
修饰语 i 用于忽略大小写. 例如, 表达式 /The/gi 表示在全局搜索 The, 在后面的 i 将其条件修改为忽略大小写, 则变成搜索 the 和 The, g 表示全局搜索.
"The" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
全局搜索 (Global search)
修饰符 g 常用语执行一个全局搜索匹配, 即(不仅仅返回第一个匹配的, 而是返回全部). 例如, 表达式 /.(at)/g 表示搜索 任意字符(除了换行) + at, 并返回全部结果.
"/.(at)/" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
多行修饰符 (Multiline)
多行修饰符 m 常用语执行一个多行匹配.
像之前介绍的 (^,$) 用于检查格式是否是在待检测字符串的开头或结尾. 但我们如果想要它在每行的开头和结尾生效, 我们需要用到多行修饰符 m.
例如, 表达式 /at(.)?$/gm 表示在待检测字符串每行的末尾搜索 at后跟一个或多个 . 的字符串, 并返回全部结果.
"/.at(.)?$/" => The fatcat saton the mat."/.at(.)?$/gm" => The fatcat saton the mat.
3. 正则表达式的应用
String 类提供的几个特殊方法
| 方法声明 | 功能描述 |
|---|---|
| matches() | 判断该字符串是否匹配指定的正则表达式 |
| replaceAll() | 将该字符串所有匹配正则表达式的子串替换成指定的字符串 |
| replaceFirst() | 将该字符串中第一个匹配正则表达式的子串替换成指定的字符串 |
| split(String regex) | 以regex为分隔符,将该字符串分割成多个子串 |
3.1 匹配功能
public boolean matches(String regex) // 编译给定正则表达式并尝试将给定输入与其匹配。
校验邮箱
package cn.itcast_02;
import java.util.Scanner;
/** 校验邮箱* * 分析:* A:键盘录入邮箱* B:定义邮箱的规则* 1517806580@qq.com* liuyi@163.com* linqingxia@126.com* fengqingyang@sina.com.cn* fqy@itcast.cn* C:调用功能,判断即可* D:输出结果*/
public class RegexTest {public static void main(String[] args) {//键盘录入邮箱Scanner sc = new Scanner(System.in);System.out.println("请输入邮箱:");String email = sc.nextLine();//定义邮箱的规则//String regex = "[a-zA-Z_0-9]+@[a-zA-Z_0-9]{2,6}(\\.[a-zA-Z_0-9]{2,3})+";String regex = "\\w+@\\w{2,6}(\\.\\w{2,3})+";//调用功能,判断即可boolean flag = email.matches(regex);//输出结果System.out.println("flag:"+flag);}
}
3.2 分割功能
public String[] split(String regex) // 根据指定的正则表达式分割字符串
代码示例:我有如下一个字符串:”91 27 46 38 50”,请写代码实现最终输出结果是:”27 38 46 50 91”
package cn.itcast_03;
import java.util.Arrays;
/** 我有如下一个字符串:"91 27 46 38 50"* 请写代码实现最终输出结果是:"27 38 46 50 91"* * 分析:* A:定义一个字符串* B:把字符串进行分割,得到一个字符串数组* C:把字符串数组变换成int数组* D:对int数组排序* E:把排序后的int数组在组装成一个字符串* F:输出字符串*/
public class RegexTest {public static void main(String[] args) {// 定义一个字符串String s = "91 27 46 38 50";// 把字符串进行分割,得到一个字符串数组String[] strArray = s.split(" ");// 把字符串数组变换成int数组int[] arr = new int[strArray.length];for (int x = 0; x < arr.length; x++) {arr[x] = Integer.parseInt(strArray[x]);}// 对int数组排序Arrays.sort(arr);// 把排序后的int数组在组装成一个字符串StringBuilder sb = new StringBuilder();for (int x = 0; x < arr.length; x++) {sb.append(arr[x]).append(" ");}//转化为字符串String result = sb.toString().trim();//输出字符串System.out.println("result:"+result);}
}
3.3 替换功能
public String replaceAll(String regex,String replacement)
使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。
- 论坛中不能出现数字字符,用*替换
package cn.itcast_04;
/** 替换功能* String类的public String replaceAll(String regex,String replacement)* 使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。 */
public class RegexDemo {public static void main(String[] args) {// 定义一个字符串String s = "helloqq12345worldkh622112345678java";// 我要去除所有的数字,用*给替换掉// String regex = "\\d+";// String regex = "\\d";//String ss = "*";// 直接把数字干掉String regex = "\\d+";String ss = "";String result = s.replaceAll(regex, ss);System.out.println(result);}
}
3.4 获取功能
Pattern和Matcher类的使用
package cn.itcast_05;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/** 获取功能* Pattern和Matcher类的使用* * 模式和匹配器的基本使用顺序*/
public class RegexDemo {public static void main(String[] args) {// 模式和匹配器的典型调用顺序// 把正则表达式编译成模式对象Pattern p = Pattern.compile("a*b");// 通过模式对象得到匹配器对象,这个时候需要的是被匹配的字符串Matcher m = p.matcher("aaaaab");// 调用匹配器对象的功能boolean b = m.matches();System.out.println(b);//这个是判断功能,但是如果做判断,这样做就有点麻烦了,我们直接用字符串的方法做String s = "aaaaab";String regex = "a*b";boolean bb = s.matches(regex);System.out.println(bb);}
}
3.5 Pattern 匹配模式
Pattern类为正则表达式的编译表示形式。指定为字符串的表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建Matcher对象,依照正则表达式,该对象可与任意字符序列匹配。执行匹配所涉及的所有状态都驻留在匹配器中,所以多个匹配器可以共享同一个模式。
| 方法声明 | 功能描述 |
|---|---|
| compile() | 把正则表达式编译成匹配模式 |
| matcher() | 根据匹配模式去匹配指定的字符串,得到匹配器 |
3.6 Matcher 匹配器
| 方法声明 | 功能描述 |
|---|---|
| matches() | 匹配字符串 |
| find() | 查找有没有满足条件的子串 |
| group() | 获取满足条件的子串 |
| reset() | 将Matcher的状态重新设置为最初的状态 |
| reset(CharSequence input) | 重新设置Matcher的状态,并且将候选字符序列设置为input后进行Matcher, 这个方法和重新创建一个Matcher一样,只是这样可以重用以前的对象。 |
| start() | 返回Matcher所匹配的字符串在整个字符串的的开始下标 |
| start(int group) | 指定你感兴趣的sub group,然后返回sup group(子分组)匹配的开始位置。 |
| end() | 返回在以前的匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量。 |
- 注意事项
Pattern类为正则表达式的编译表示形式。指定为字符串的正则表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建Matcher对象,依照正则表达式,该对象可以与任意字符序列匹配。执行匹配所涉及的所有状态都驻留在匹配器中,所以多个匹配器可以共享同一模式
分组:简单的说,分组其实就是为了能够指定同一个规则可以使用多少次。正则表达式中的分组就是整个大的正则表达式和用()圈起来的内容。
在这个正则表达式"\w(\d\d)(\w+)"中
- 分组0:是"\w(\d\d)(\w+)"
- 分组1:是(\d\d)
- 分组2:是(\w+)
如果我们稍稍变换一下,将原先的正则表达式改为"(\w)(\d\d)(\w+)",我们的分组就变成了
- 分组0:是"\w(\d\d)(\w+)"
- 分组1:是"(\w)"
- 分组2:是"(\d\d)"
- 分组3:是"(\w+)"
我们看看和正则表达式”\w(\d\d)(\w+)”匹配的一个字符串A22happy
- group(0)是匹配整个表达式的字符串的那部分A22happy
- group(1)是第1组(\d\d)匹配的部分:22
- group(2)是第2组(\w+)匹配的那部分happy
public static void main(String[] args) {String Regex="\\w(\\d\\d)(\\w+)";String TestStr="A22happy";Pattern p=Pattern.compile(Regex);Matcher matcher=p.matcher(TestStr);if (matcher.find()) {int gc=matcher.groupCount();for (int i = 0; i <= gc; i++) {System.out.println("group "+i+" :"+matcher.group(i));}}
}
- start()方法的使用
public static void testStart(){//创建一个 Matcher ,使用 Matcher.start()方法String candidateString = "My name is Bond. James Bond.";String matchHelper[] ={" ^"," ^"};Pattern p = Pattern.compile("Bond");Matcher matcher = p.matcher(candidateString);//找到第一个 'Bond'的开始下标matcher.find();int startIndex = matcher.start();System.out.println(candidateString);System.out.println(matchHelper[0] + startIndex);//找到第二个'Bond'的开始下标matcher.find();int nextIndex = matcher.start();System.out.println(candidateString);System.out.println(matchHelper[1] + nextIndex);
}
运行结果:

/*** 测试matcher.group方法*/
public static void testGroup() {// 创建一个 PatternPattern p = Pattern.compile("Bond");// 创建一个 Matcher ,以便使用 Matcher.group() 方法String candidateString = "My name is Bond. James Bond.";Matcher matcher = p.matcher(candidateString);// 提取 groupmatcher.find();System.out.println(String.format("group匹配的字符串 : %s",matcher.group()));System.out.println(String.format("匹配的开始位置 : %d", matcher.start()));System.out.println(String.format("匹配的结束位置 : %d", matcher.end()));System.out.println("---再次使用matcher.find()方法,看看matcher中group、start、end方法的效果");matcher.find();System.out.println(String.format("group匹配的字符串 : %s",matcher.group()));;System.out.println(String.format("匹配的开始位置 : %d", matcher.start()));System.out.println(String.format("匹配的结束位置 : %d", matcher.end()));System.out.println(String.format("candidateString字符串的长度 : %d", candidateString.length()));
}
运行结果:

- 获取由三个字符组成的单词
package cn.itcast_05;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/** 获取功能:* 获取下面这个字符串中由三个字符组成的单词* da jia ting wo shuo,jin tian yao xia yu,bu shang wan zi xi,gao xing bu?*/
public class RegexDemo2 {public static void main(String[] args) {// 定义字符串String s = "da jia ting wo shuo,jin tian yao xia yu,bu shang wan zi xi,gao xing bu?";// 规则String regex = "\\b\\w{3}\\b";// 把规则编译成模式对象Pattern p = Pattern.compile(regex);// 通过模式对象得到匹配器对象Matcher m = p.matcher(s);// 调用匹配器对象的功能// 通过find方法就是查找有没有满足条件的子串// public boolean find()// boolean flag = m.find();// System.out.println(flag);// // 如何得到值呢?// // public String group()// String ss = m.group();// System.out.println(ss);//// // 再来一次// flag = m.find();// System.out.println(flag);// ss = m.group();// System.out.println(ss);while (m.find()) {System.out.println(m.group());}// 注意:一定要先find(),然后才能group()// IllegalStateException: No match found// String ss = m.group();// System.out.println(ss);}
}
- 判断身份证:要么是15位,要么是18位,最后一位可以为字母,并写程序提出其中的年月日。
public static void main(String[] args) {testID_Card();
}public static void testID_Card() {// 测试是否为合法的身份证号码String[] strs = { "130681198712092019", "13068119871209201x","13068119871209201", "123456789012345", "12345678901234x","1234567890123" };// 准备正则表达式(身份证有15位和18位两种,身份证的最后一位可能是字母)String regex = "(\\d{14}\\w)|\\d{17}\\w";// 准备开始匹配,判断所有的输入是否是正确的Pattern regular = Pattern.compile(regex); // 创建匹配的规则PatterStringBuilder sb = new StringBuilder();// 遍历所有要匹配的字符串for (int i = 0; i < strs.length; i++) {Matcher matcher = regular.matcher(strs[i]);// 创建一个Matchersb.append("身份证: ");sb.append(strs[i]);sb.append(" 匹配:");sb.append(matcher.matches());System.out.println(sb.toString());sb.delete(0, sb.length());// 清空StringBuilder的方法}GetBirthDay(strs);}private static void GetBirthDay(String[] strs) {System.out.println("准备开始获取出生日期");// 准备验证规则Pattern BirthDayRegular = Pattern.compile("(\\d{6})(\\d{8})(.*)");// .*连在一起就意味着任意数量的不包含换行的字符Pattern YearMonthDayRegular = Pattern.compile("(\\d{4})(\\d{2})(\\d{2})");for (int i = 0; i < strs.length; i++) {Matcher matcher = BirthDayRegular.matcher(strs[i]);if (matcher.matches()) {Matcher matcher2 = YearMonthDayRegular.matcher(matcher.group(2));if (matcher2.matches()) {System.out.println(strs[i]+" 中的出生年月分解为: "+"年" + matcher2.group(1) + " 月:" + matcher2.group(2) + " 日:" + matcher2.group(3));}}}
}
运行结果:

4. 正则表达式工具类
import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** 正则工具类 提供验证邮箱、手机号、电话号码、身份证号码、数字等方法*/
public final class RegexUtils {/*** 验证Email* * @param email* email地址,格式:zhangsan@sina.com,zhangsan@xxx.com.cn,xxx代表邮件服务商* @return 验证成功返回true,验证失败返回false ^ :匹配输入的开始位置。 \:将下一个字符标记为特殊字符或字面值。* :匹配前一个字符零次或几次。 + :匹配前一个字符一次或多次。 (pattern) 与模式匹配并记住匹配。 x|y:匹配 x 或* y。 [a-z] :表示某个范围内的字符。与指定区间内的任何字符匹配。 \w :与任何单词字符匹配,包括下划线。* * {n,m} 最少匹配 n 次且最多匹配 m 次 $ :匹配输入的结尾。*/public static boolean checkEmail(String email) {String regex = "^(\\w)+(\\.\\w+)*@(\\w)+((\\.\\w{2,3}){1,3})$";return Pattern.matches(regex, email);}/*** 验证身份证号码* * @param idCard* 居民身份证号码15位或18位,最后一位可能是数字或字母* @return 验证成功返回true,验证失败返回false*/public static boolean checkIdCard(String idCard) {String regex = "[1-9]\\d{13,16}[a-zA-Z0-9]{1}";return Pattern.matches(regex, idCard);}/*** 验证手机号码(支持国际格式,+86135xxxx...(中国内地),+00852137xxxx...(中国香港))* * @param mobile* 移动、联通、电信运营商的号码段* <p>* 移动的号段:134(0-8)、135、136、137、138、139、147(预计用于TD上网卡)* 、150、151、152、157(TD专用)、158、159、187(未启用)、188(TD专用)* </p>* <p>* 联通的号段:130、131、132、155、156(世界风专用)、185(未启用)、186(3g)* </p>* <p>* 电信的号段:133、153、180(未启用)、189* </p>* <p>* 虚拟运营商的号段:170* </p>* @return 验证成功返回true,验证失败返回false*/public static boolean checkMobile(String mobile) {String regex = "(\\+\\d+)?1[34578]\\d{9}$";return Pattern.matches(regex, mobile);}/*** 验证固定电话号码* * @param phone* 电话号码,格式:国家(地区)电话代码 + 区号(城市代码) + 电话号码,如:+8602085588447* <p>* <b>国家(地区) 代码 :</b>标识电话号码的国家(地区)的标准国家(地区)代码。它包含从 0 到 9* 的一位或多位数字, 数字之后是空格分隔的国家(地区)代码。* </p>* <p>* <b>区号(城市代码):</b>这可能包含一个或多个从 0 到 9 的数字,地区或城市代码放在圆括号——* 对不使用地区或城市代码的国家(地区),则省略该组件。* </p>* <p>* <b>电话号码:</b>这包含从 0 到 9 的一个或多个数字* </p>* @return 验证成功返回true,验证失败返回false*/public static boolean checkPhone(String phone) {// String regex = "(\\+\\d+)?(\\d{3,4}\\-?)?\\d{7,8}$";String regex = "^1\\d{10}$";return Pattern.matches(regex, phone);}/*** 验证整数(正整数和负整数)* * @param digit* 一位或多位0-9之间的整数* @return 验证成功返回true,验证失败返回false*/public static boolean checkDigit(String digit) {String regex = "\\-?[1-9]\\d+";return Pattern.matches(regex, digit);}/*** 验证整数和浮点数(正负整数和正负浮点数)* * @param decimals* 一位或多位0-9之间的浮点数,如:1.23,233.30* @return 验证成功返回true,验证失败返回false*/public static boolean checkDecimals(String decimals) {String regex = "\\-?[1-9]\\d+(\\.\\d+)?";return Pattern.matches(regex, decimals);}/*** 验证空白字符* * @param blankSpace* 空白字符,包括:空格、\t、\n、\r、\f、\x0B* @return 验证成功返回true,验证失败返回false*/public static boolean checkBlankSpace(String blankSpace) {String regex = "\\s+";return Pattern.matches(regex, blankSpace);}/*** 验证中文* * @param chinese* 中文字符* @return 验证成功返回true,验证失败返回false*/public static boolean checkChinese(String chinese) {String regex = "^[\u4E00-\u9FA5]+$";return Pattern.matches(regex, chinese);}/*** 验证日期(年月日)* * @param birthday* 日期,格式:1992-09-03,或1992.09.03* @return 验证成功返回true,验证失败返回false*/public static boolean checkBirthday(String birthday) {String regex = "[1-9]{4}([-./])\\d{1,2}\\1\\d{1,2}";return Pattern.matches(regex, birthday);}/*** 验证URL地址* * @param url* 格式:http://blog.csdn.net:80/xyang81/article/details/7705960? 或* http://www.csdn.net:80* @return 验证成功返回true,验证失败返回false*/public static boolean checkURL(String url) {String regex = "(https?://(w{3}\\.)?)?\\w+\\.\\w+(\\.[a-zA-Z]+)*(:\\d{1,5})?(/\\w*)*(\\??(.+=.*)?(&.+=.*)?)?";return Pattern.matches(regex, url);}/*** 匹配中国邮政编码* * @param postcode* 邮政编码* @return 验证成功返回true,验证失败返回false*/public static boolean checkPostcode(String postcode) {String regex = "[1-9]\\d{5}";return Pattern.matches(regex, postcode);}/*** 匹配IP地址(简单匹配,格式,如:192.168.1.1,127.0.0.1,没有匹配IP段的大小)* * @param ipAddress* IPv4标准地址* @return 验证成功返回true,验证失败返回false*/public static boolean checkIpAddress(String ipAddress) {String regex = "[1-9](\\d{1,2})?\\.(0|([1-9](\\d{1,2})?))\\.(0|([1-9](\\d{1,2})?))\\.(0|([1-9](\\d{1,2})?))";return Pattern.matches(regex, ipAddress);}public static boolean checkNickname(String nickname) {String regex = "^[a-zA-Z0-9\u4E00-\u9FA5_]+$";return Pattern.matches(regex, nickname);}public static boolean hasCrossSciptRiskInAddress(String str) {String regx = "[`~!@#$%^&*+=|{}':;',\\[\\].<>~!@#¥%……&*——+|{}【】‘;:”“’。,、?-]";if (str != null) {str = str.trim();Pattern p = Pattern.compile(regx, Pattern.CASE_INSENSITIVE);Matcher m = p.matcher(str);return m.find();}return false;}
}
4.1 常用正则表达式
说明:正则表达式通常用于两种任务:1.验证,2.搜索/替换。用于验证时,通常需要在前后分别加上^和$,以匹配整个待验证字符串;搜索/替换时是否加上此限定则根据搜索的要求而定,此外,也有可能要在前后加上\b而不是^和$。此表所列的常用正则表达式,除个别外均未在前后加上任何限定,请根据需要,自行处理。
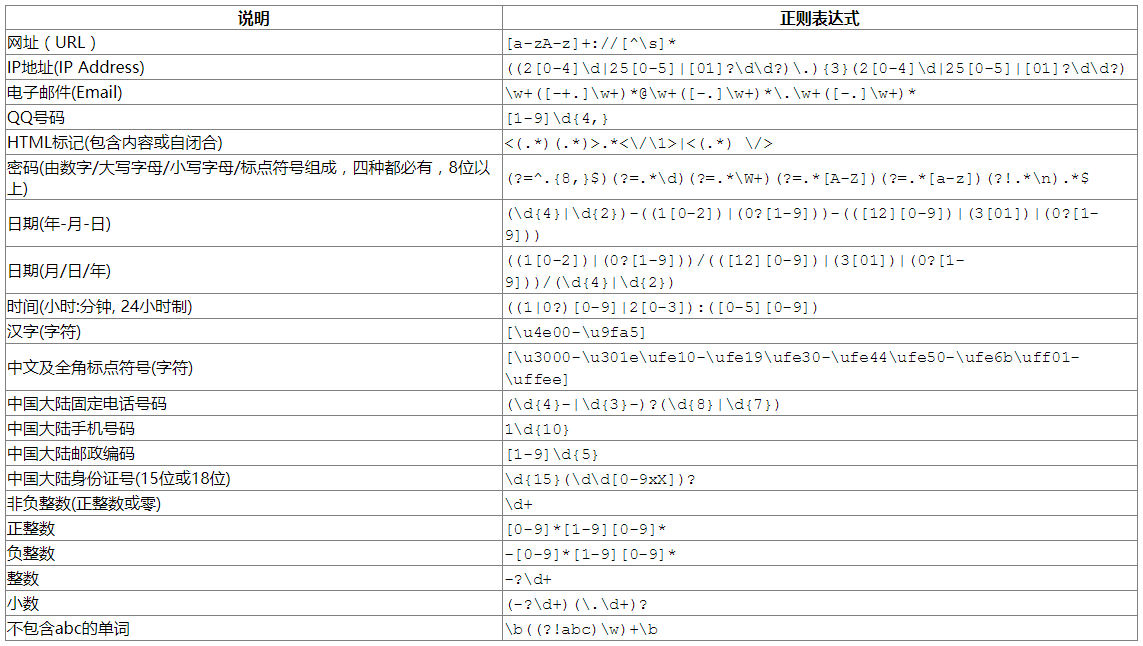
4.2 校验数字的表达式
1. 数字:^[0-9]*$
2. n位的数字:^\d{n}$
3. 至少n位的数字:^\d{n,}$
4. m-n位的数字:^\d{m,n}$
5. 零和非零开头的数字:^(0|[1-9][0-9]*)$
6. 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7. 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
8. 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
9. 有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
10. 有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
11. 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
12. 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
13. 非负整数:^\d+$ 或 ^[1-9]\d*|0$
14. 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
15. 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
16. 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
17. 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
18. 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
19. 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
4.3 校验字符的表达式
1. 汉字:^[\u4e00-\u9fa5]{0,}$
2. 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
3. 长度为3-20的所有字符:^.{3,20}$
4. 由26个英文字母组成的字符串:^[A-Za-z]+$
5. 由26个大写英文字母组成的字符串:^[A-Z]+$
6. 由26个小写英文字母组成的字符串:^[a-z]+$
7. 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
8. 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
9. 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
10. 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
11. 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
12. 禁止输入含有~的字符:[^~\x22]+
4.4 特殊需求表达式
1. Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2. 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?3. InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$4. 手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5. 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6. 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}7. 身份证号(15位、18位数字):^\d{15}|\d{18}$8. 短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9. 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10. 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11. 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12. 日期格式:^\d{4}-\d{1,2}-\d{1,2}13. 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$14. 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15. 钱的输入格式:i. 有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$ii. 这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$iii. 一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$iv. 这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$v. 必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$vi. 这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$vii. 这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$viii. 1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里16. xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$17. 中文字符的正则表达式:[\u4e00-\u9fa5]18. 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))19. 空白行的正则表达式:\n\s*\r (可以用来删除空白行)20. HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)21. 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)22. 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)23. 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)24. IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)25. IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))



(二))

(王卓教学视频))
】)










)

)