个体与集成
- 同质:相同的基学习器,实现容易,但是很难保证差异性。
- 异质:不同的基学习器,实现复杂,不同模型之间本来就存在差异性,但是很难直接比较不同模型的输出,需要复杂的配准方法。

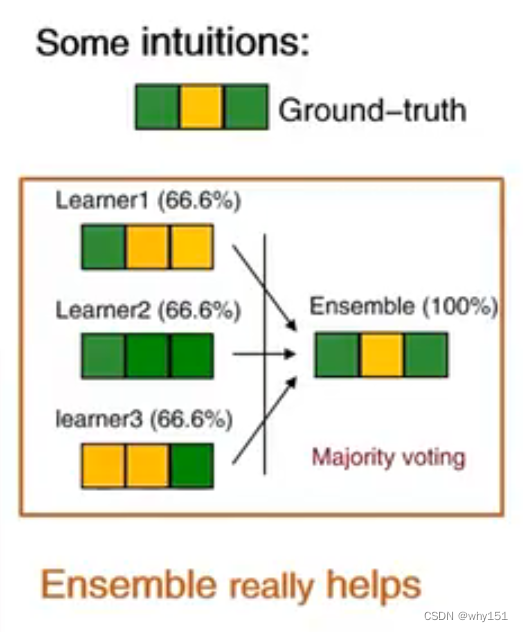

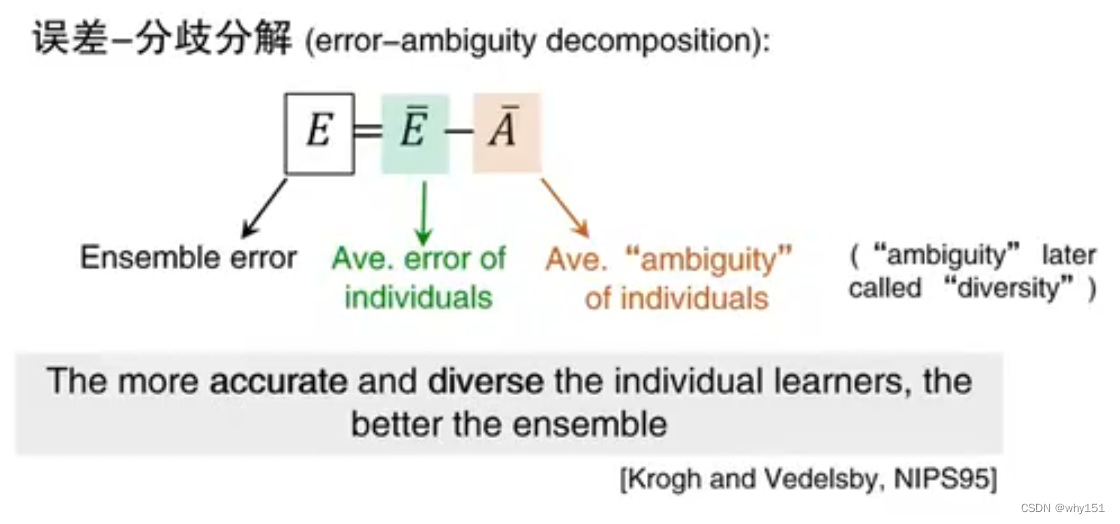
好而不同


boosting
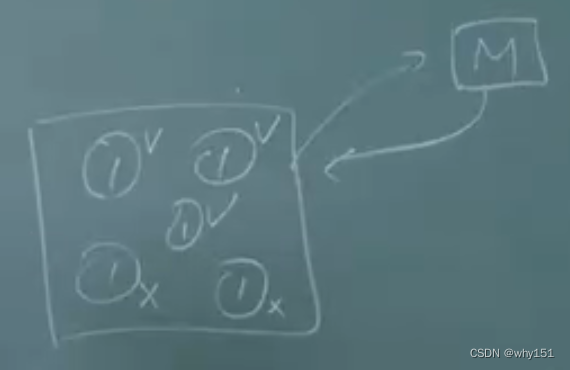
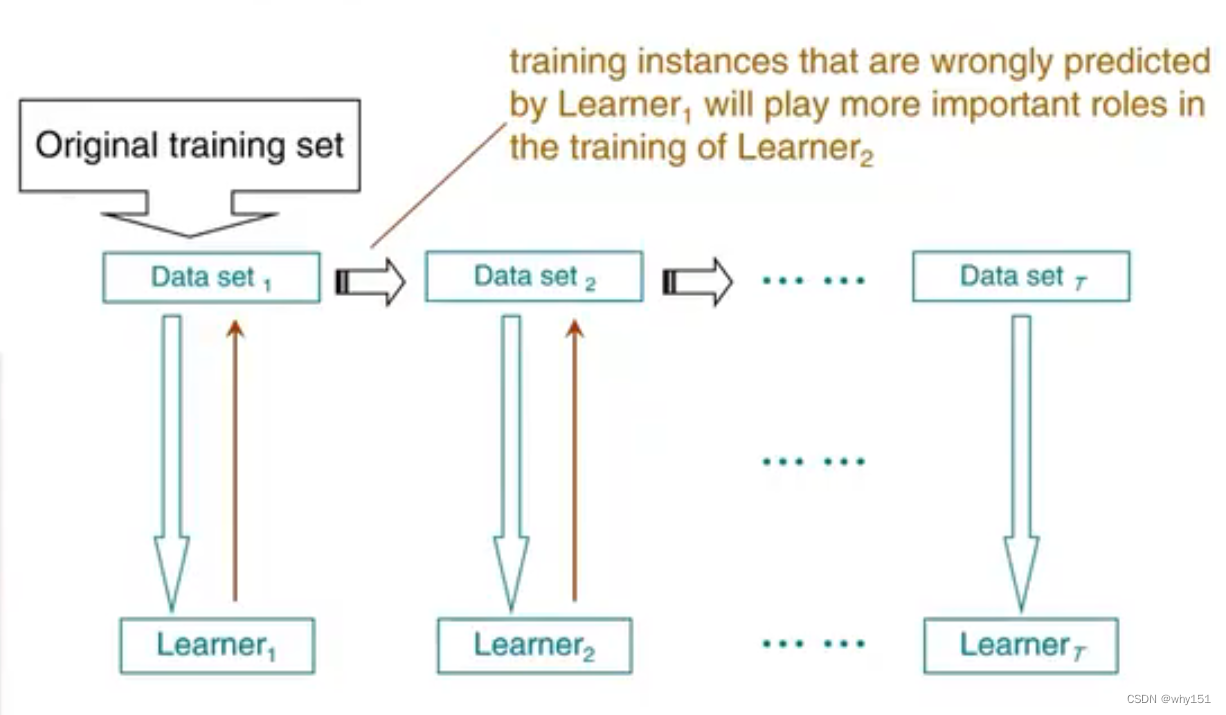
Adaboost


求解h

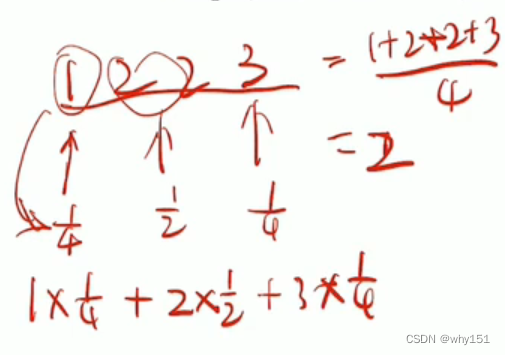


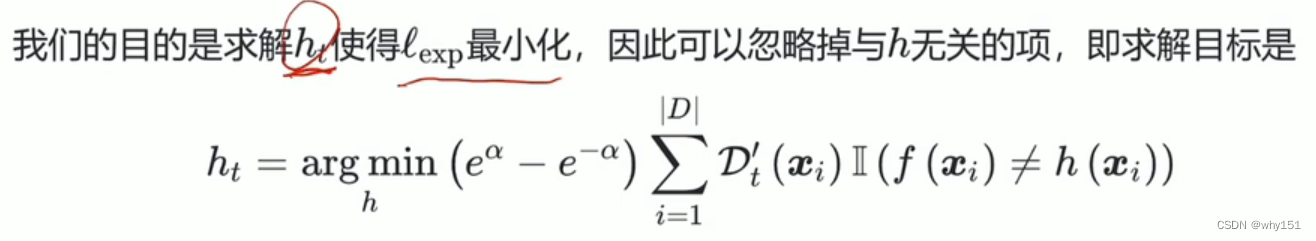



求解alpha


bagging
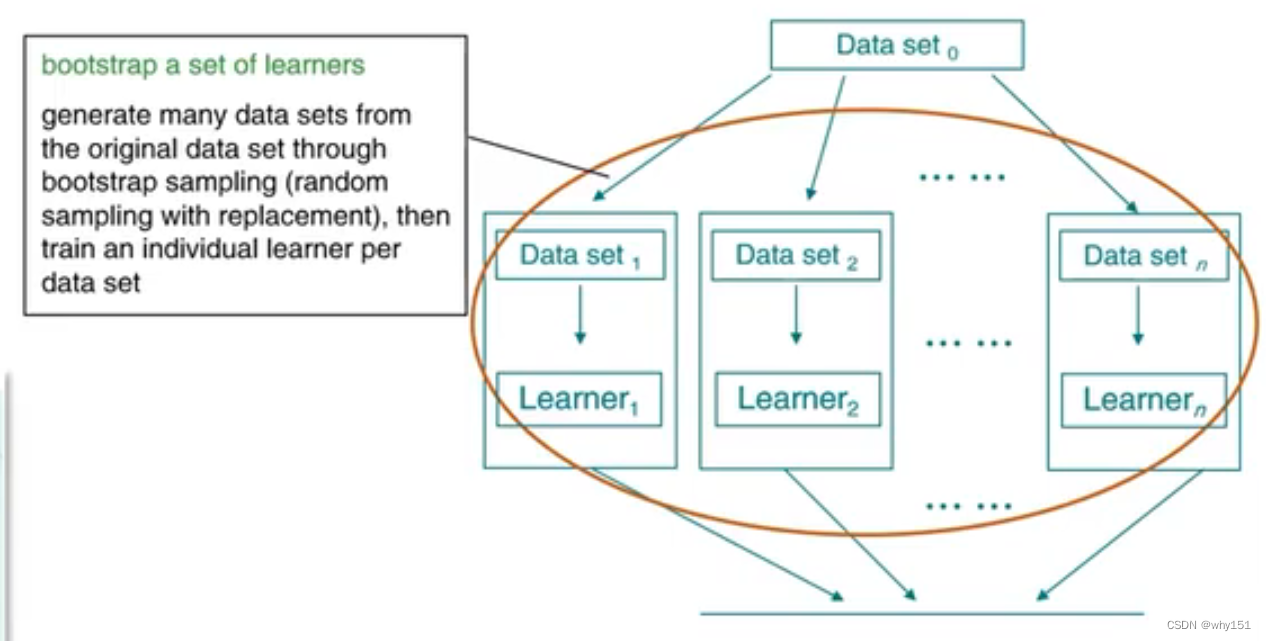
随机森林
数据集划分:使用类似自助法的k折交叉验证,有放回的取出,分别训练T个决策树。
随机:一个是训练集的随机,一个是属性的随机(每次在当前属性中随机取K个构成属性子集,在子集中选择信息增益最大的属性)

结合策略
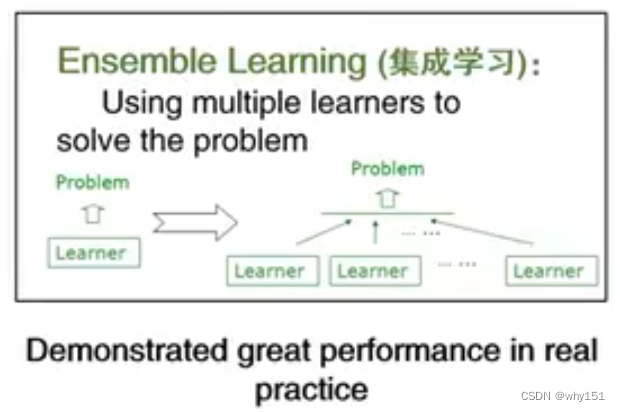
集合的好处
- 可能多个假设在训练集上达到同等性能,使用单学习器可能因为误选而导致泛化性能不佳。
- 单个可能陷入局部极小点。
- 可以使相应的假设空间扩大。
结合方法
平均法
- 简单平均
- 加权平均
投票法
- 绝对多数投票(大于一半则预测为该标记,否则拒绝)
- 相对多数投票
- 加权投票法
学习法
利用初始数据集训练出初级学习器,然后生成一个新数据集,训练一个次级学习器。
多样性增强
- 数据样本扰动
- 输入属性扰动
- 输出表示扰动
- 算法参数扰动
(二))

(王卓教学视频))
】)










)

)
、路由支持以及多线程改进)

 - CSerialPort调试模式的使用)