在上一期图解 图解MySQL | MySQL DDL为什么成本高?中,我们介绍了:
传统情况下,为表添加列需要对表进行重建
腾讯团队为 MySQL 引入了 Instant Add Column 的方案(以下称为 "立刻加列" 功能)可以快速完成 为表添加列 的任务
同时我们留了以下思考题:
"立刻加列" 是如何工作的 ?
所谓 "立刻加列" 是否完全不影响业务,是否是真正的 "立刻" 完成 ?
本期我们针对这几个问题来进行讨论:
传统情况
我们先回顾一下,在没有 "立刻加列" 功能时,加列操作是怎么完成的。我们也借此来熟悉一下本期的图例:
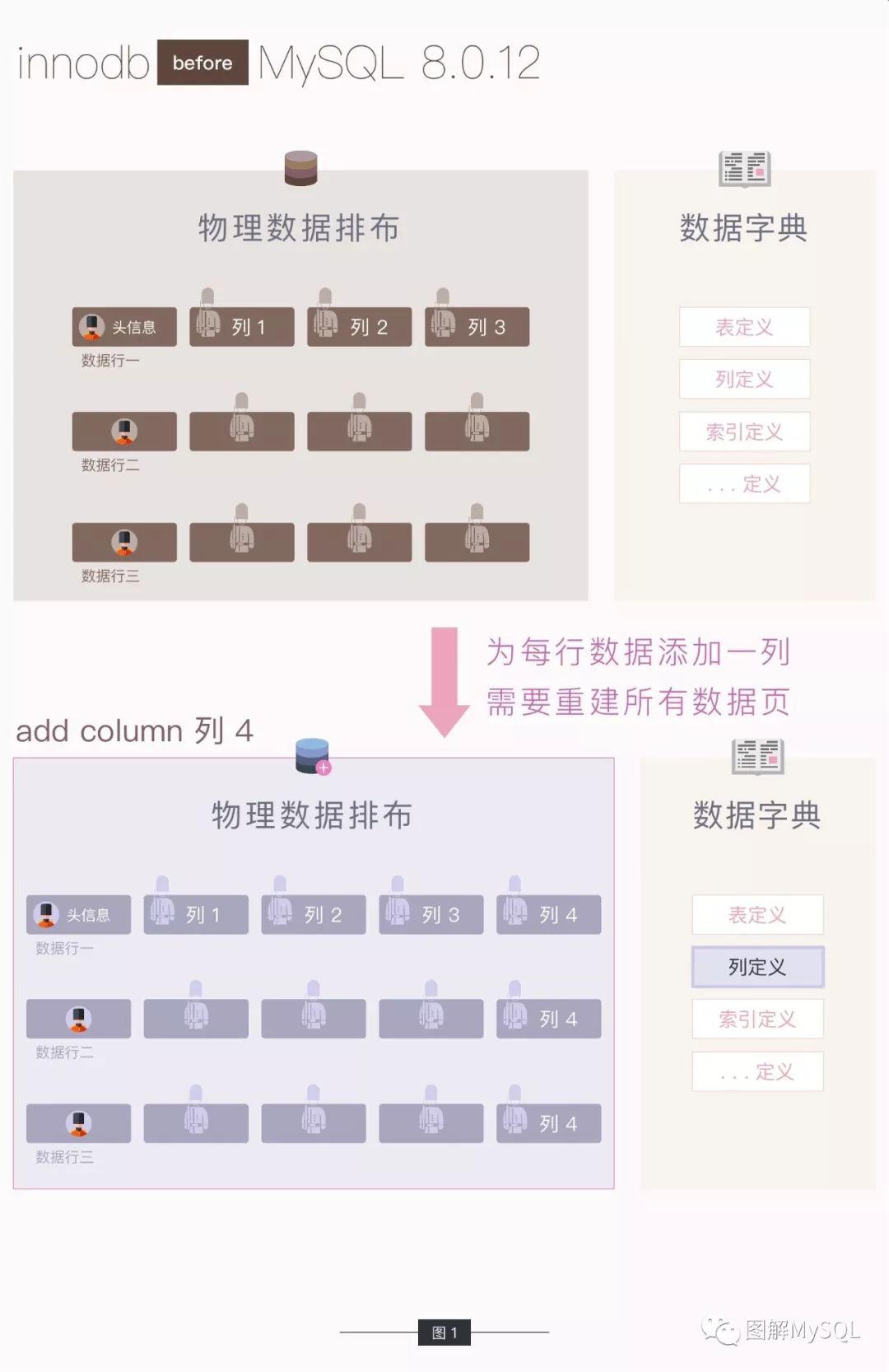
当进行 加列操作 时,所有的数据行 都必须要 增加一段数据(图中的 列 4 数据)
如上一期图解所讲,当改变数据行的长度,就需要 重建表空间(图中灰蓝的部分为发生变更的部分)
数据字典中的列定义也会被更新
以上操作的问题在于 每次加列 操作都需要重建表空间,这就需要大量 IO以及大量的时间
立刻加列
"立刻加列" 的过程如下图:
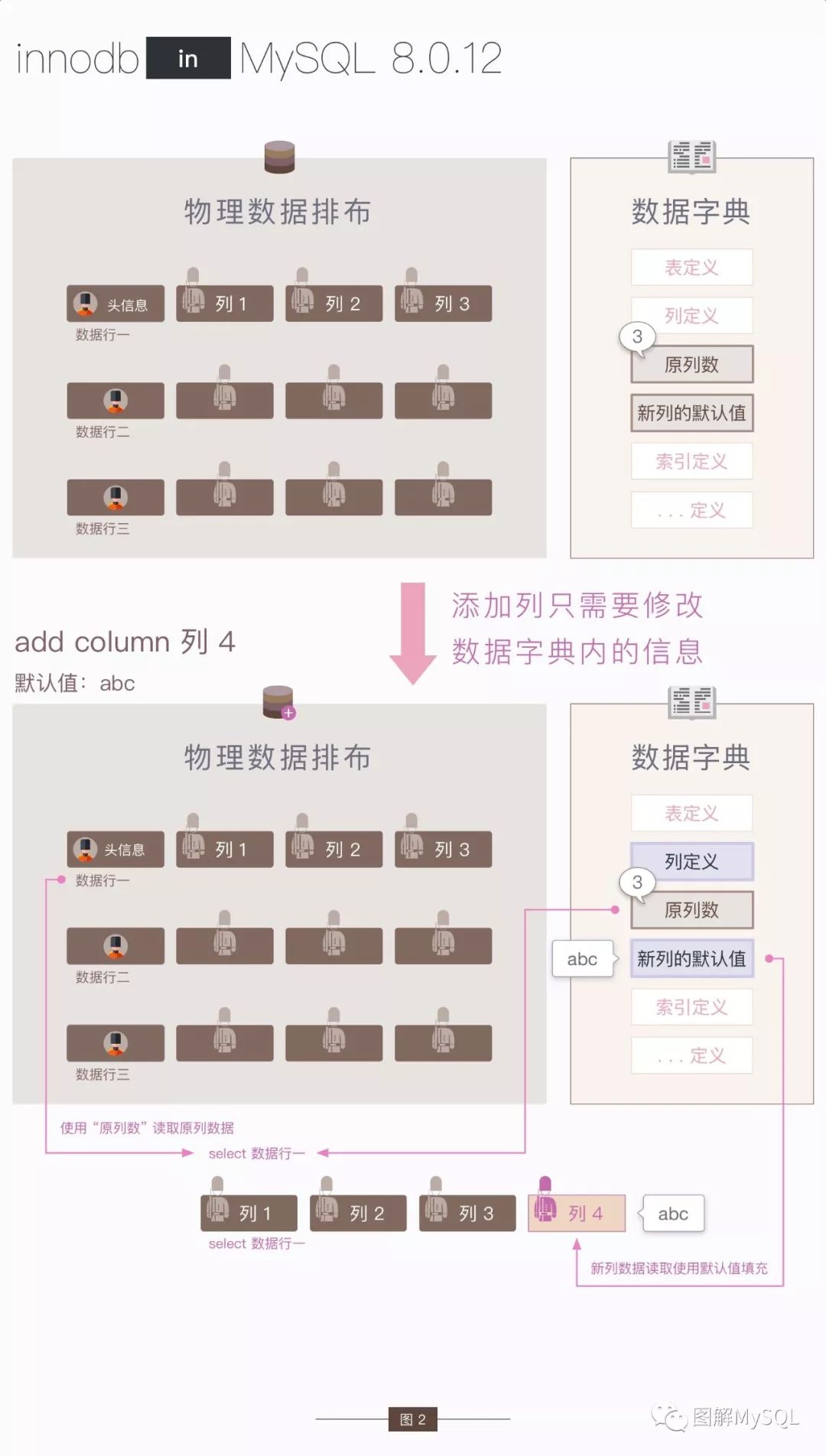
"立刻加列" 时,只会变更数据字典中的内容,包括:
在列定义中增加 新列的定义
增加 新列的默认值
"立刻加列" 后,当要读取表中的数据时:
由于 "立刻加列" 没有 变更行数据,读取的行数据只有 3 列
MySQL 会将 新增的第 4 列的默认值,追加到 读取的数据后
以上过程描述了 如何读取 在 "立刻加列" 之前写入的数据,其实质是:在读取数据的过程中,"伪造" 了一个新列出来
那么如何读取 在 "立刻加列" 之后 写入的数据呢 ? 过程如下图:
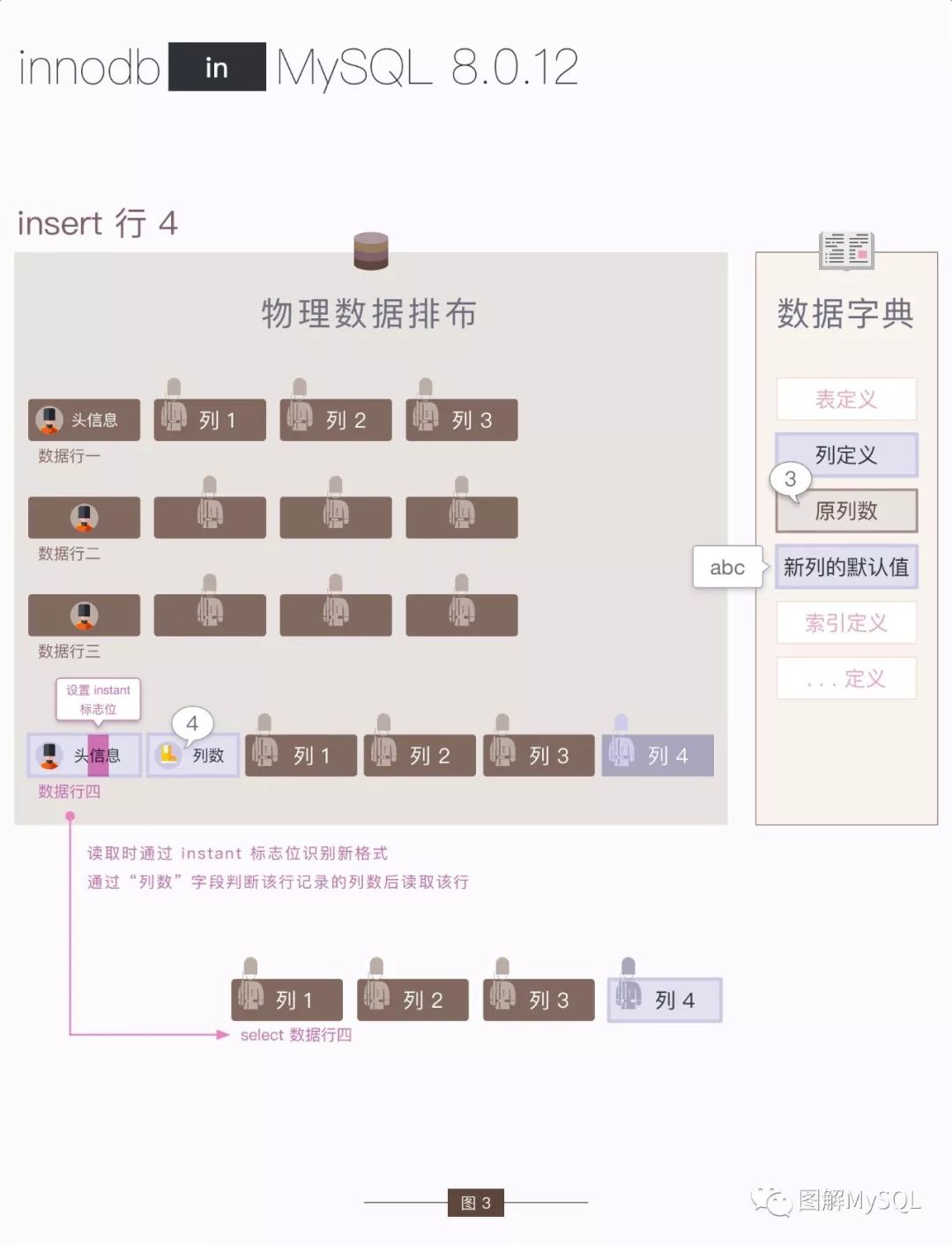
当读取 行 4 时:
通过判断 数据行的头信息中的instant 标志位,可以知道该行的格式是 "新格式":该行头信息后有一个新字段 "列数"
通过读取 数据行的 "列数" 字段,可以知道 该行数据中多少列有 "真实" 的数据,从而按列数读取数据
通过上图可以看到:读取 在"立刻加列" 前/后写入的数据是不同的流程
通过以上的讨论,我们可以总结 "立刻加列" 之所以高效的原因是:
在执行 "立刻加列" 时,不变更数据行的结构
读取 "旧" 数据时,"伪造" 新增的列,使结果正确
写入 "新" 数据时,使用了新的数据格式(增加了instant标志位 和 "列数" 字段),以区分新旧数据
读取 "新" 数据时,可以如实读取数据
那么 我们是否能一直 "伪造" 下去 ? "伪造" 何时会被拆穿 ?
考虑以下场景:
用 "立刻加列" 增加列 A
写入数据行 1
用 "立刻加列" 增加列 B
写入数据行 2
删除列 B
我们推测一下 "删除列 B" 的最小代价:需要修改 数据行中的instant标志位或 "列数" 字段,这至少会影响到 "立刻加列" 之后写入的数据行,成本类似于重建数据
从以上推测可知:当出现 与 "立刻加列" 操作不兼容 的 DDL 操作时,数据表需要进行重建,如下图所示:
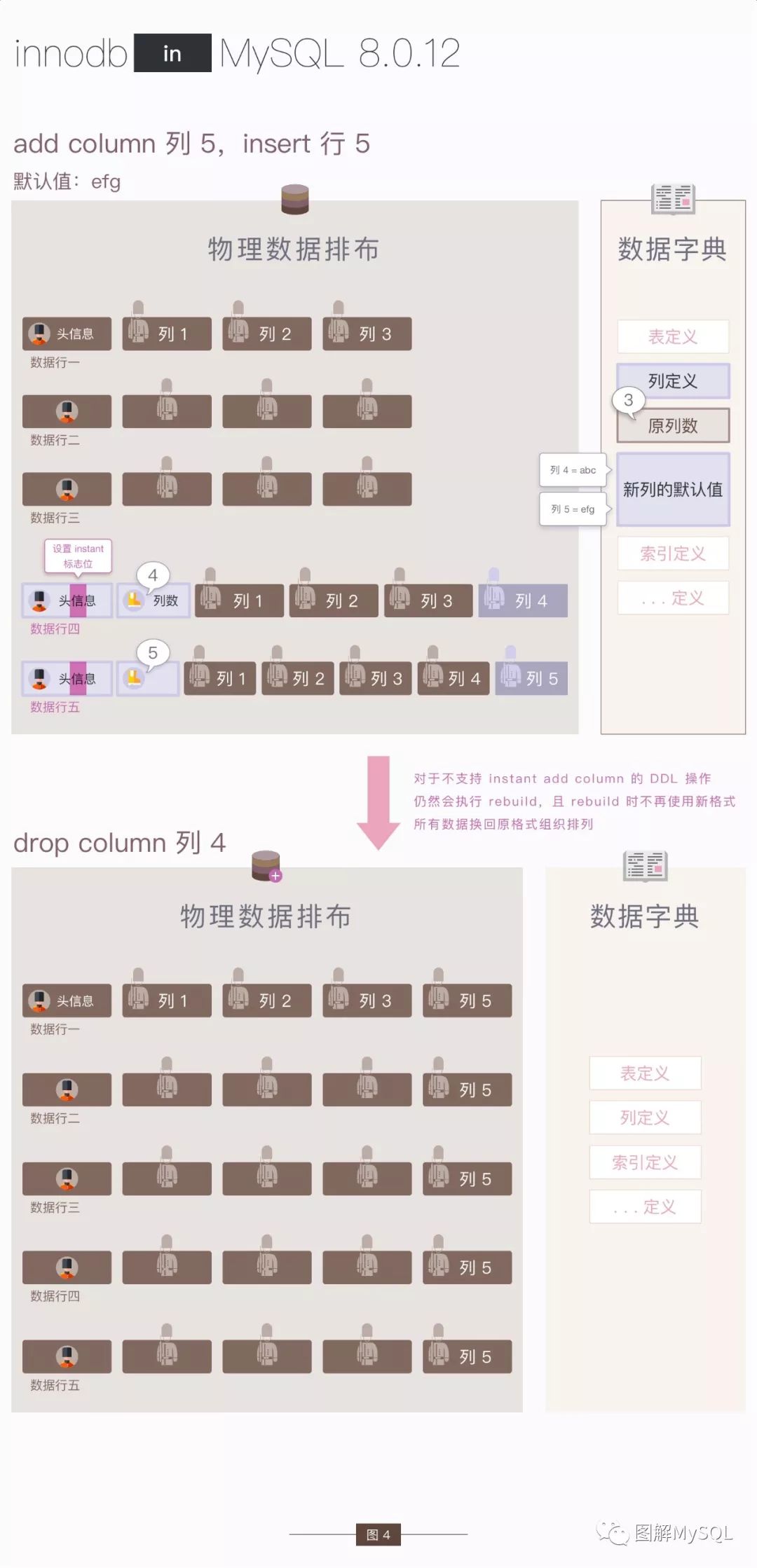
扩展思考题:是否能设计其他的数据格式,取代instant标志位和 "列数" 字段,使得 加列/删列 操作都能 "立刻完成" ?(提示:考虑 加列 - 删列 - 再加列 的情况)
使用限制
在了解原理之后,我们来看看 "立刻加列" 的使用限制,就很容易能理解其中的前两项:
"立刻加列" 的加列位置只能在表的最后,而不能加在其他列之间在元数据中,只记录了 数据行 应有多少列,而没有记录 这些列 应出现的位置。所以无法实现指定列的位置
"立刻加列" 不能添加主键列加列 不能涉及聚簇索引的变更,否则就变成了 "重建" 操作,不是 "立刻" 完成了
"立刻加列"不支持压缩的表格式
按照 WL 的说法:"COMPRESSED is no need to supported"(没必要支持不怎么用的格式)
总结回顾
我们总结一下上面的讨论:
"立刻加列" 之所以高效的原因是:
在执行 "立刻加列" 时,不变更数据行的结构
读取 "旧" 数据时,"伪造" 新增的列,使结果正确
写入 "新" 数据时,使用了新的数据格式 (增加了 instant 标志位 和 "列数" 字段),以区分新旧数据
读取 "新" 数据时,可以如实读取数据
"立刻加列" 的 "伪造" 手法,不能一直维持下去。当发生 与 "立刻加列" 操作不兼容 的 DDL 时,表数据就会发生重建
回到之前遗留的两个问题:
"立刻加列" 是如何工作的 ?
我们已经解答了这个问题
所谓 "立刻加列" 是否完全不影响业务,是否是真正的 "立刻" 完成 ?
可以看到:就算是 "立刻加列",也需要变更 数据字典,那么 该上的锁还是逃不掉的。也就是说 这里的 "立刻" 指的是 "不变更数据行的结构",而并非指 "零成本地完成任务"
本期仍然留下一个思考题:
本文中描述了 在 "立刻加列" 之后 插入 数据行的情况 (数据行会使用新格式)。那么在 "立刻加列" 之后 更新 数据行会发生什么情况呢 ?
 图解MySQL原理
图解MySQL原理
图解MySQL | MySQL DDL为什么成本高?
图解MySQL | [原理解析] XtraBackup增量备份还原
[原理解析] XtraBackup全量备份还原
[原理解析] MySQL使用固定的server_id导致数据丢失
[原理解析] MySQL组提交(group commit)
[原理解析] 设置字符集的参数控制了哪些行为

近期社区动态
第三期 社区技术内容征稿?
所有稿件,一经采用,均会为作者署名。
征稿主题:MySQL、分布式中间件DBLE、数据传输组件DTLE相关的技术内容
活动时间:2019年6月11日 - 7月11日
本期投稿奖励
投稿成功:京东卡200元*1
优秀稿件:京东卡200元*1+社区定制周边(包含:定制文化衫、定制伞、鼠标垫)
优秀稿件评选,文章获得“好看”数量排名前三的稿件为本期优秀稿件。


喜欢点“分享”,不行就“在看”

多喝热水,重启试试












)






