一、GAN介绍
生成式对抗网络GAN(Generative Adversarial Networks)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。它源于2014年发表的论文:《Generative Adversarial Nets》,论文地址:https://arxiv.org/pdf/1406.2661.pdf。
模型通过框架中(至少)两个模块:生成模型(Generative model)和判别模型(Discriminative model)的相互博弈学习产生相当好的输出。原始GAN理论中并不要求G和D都是神经网络,只需要是能够拟合相应生成和判别的函数即可。但实际应用中一般均使用深度神经网络DNN/MLP作为G和D。一个优秀的GAN应用需要有良好的的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
GAN将机器学习中的两大模型紧密结合在了一起,在这个框架中将会有两个模型被同时训练:G用来捕获数据分布,D用来估计样本来自训练数据而不是G的概率,G的训练目的是最大化D产生错误的概率。这个框架相当于一个极小化极大的双方博弈。在任意函数G和D的空间中存在唯一解,此时G恢复训练数据分布,且D处处都等于1/2。在G和D由DNN构成的情况下,可以使用反向传播进行训练,在训练或生成样本时不需要任何马尔可夫链或展开的近似推理网络。
以生成图片为例,G为一个生成图片的网络,接收一个随机的噪声z生成图片G(z);D为一个判别网络,判断一张图片x是不是真实的,D(x)表示x是真实图片的概率,若D(x)等于1表示x是100%真实的图片、等于0表示x不可能是真实的图片。训练过程中G和D构成一个动态博弈过程,博弈的结果就是G可以生成足以“以假乱真”的图片G(z),而D难以判断G生成的图片是不是真实的,即D(G(z))=0.5。这样就得到了一个生成模型G,可以用来生成图片。Goodfellow从理论上证明了该算法的收敛性,且在模型收敛时,生成数据和真实数据具有相同的分布。

GAN的应用有:图像生成(超分辨率),语义分割,文字生成,数据增强,信息检索/排序,聊天机器人等。
GAN介绍优势
GAN是更好的生成模型,在某种意义上避免了马尔科夫链式的学习机制,这使得它能够区别于传统的概率生成模型。传统概率生成模型一般都需要进行马可夫链式的采样和推断,而GAN避免了这个计算复杂度特别高的过程,直接进行采样和推断,从而提高了GAN的应用效率,所以其实际应用场景也就更为广泛。
其次GAN是一个非常灵活的设计框架,各种类型的损失函数都可以整合到GAN模型当中,这样使得针对不同的任务,我们可以设计不同类型的损失函数,都会在GAN的框架下进行学习和优化。
再次,最重要的一点是,当概率密度不可计算的时候,传统依赖于数据自然性解释的一些生成模型就不可以在上面进行学习和应用。但是GAN在这种情况下依然可以使用,这是因为GAN引入了一个非常聪明的内部对抗的训练机制,可以逼近一些不是很容易计算的目标函数
怎么去定义一个恰当的优化目标或一个损失?
传统的生成模型,一般都采用数据的似然性来作为优化的目标,但GAN创新性地使用了另外一种优化目标。
首先,它引入了一个判别模型(常用的有支持向量机和多层神经网络)。其次,它的优化过程就是在寻找生成模型和判别模型之间的一个纳什均衡。
GAN所建立的一个学习框架,实际上就是生成模型和判别模型之间的一个模仿游戏。生成模型的目的,就是要尽量去模仿、建模和学习真实数据的分布规律;而判别模型则是要判别自己所得到的一个输入数据,究竟是来自于真实的数据分布还是来自于一个生成模型。通过这两个内部模型之间不断的竞争,从而提高两个模型的生成能力和判别能力。
详细实现过程
假设我们现在的数据集是手写体数字的数据集minst。
初始化生成模型G、判别模型D(假设生成模型是一个简单的RBF,判别模型是一个简单的全连接网络,后面连接一层softmax)这些都是假设,对抗网络的生成模型和判别模型没有任何限制。

例子与训练1
假设有一种概率分布M,它相对于我们是一个黑盒子。为了了解这个黑盒子中的东西是什么,我们构建了两个东西G和D,G是另一种我们完全知道的概率分布,D用来区分一个事件是由黑盒子中那个不知道的东西产生的还是由我们自己设的G产生的。
不断的调整G和D,直到D不能把事件区分出来为止。在调整过程中,需要:
1、优化G,使它尽可能的让D混淆。
2、优化D,使它尽可能的能区分出假冒的东西。
当D无法区分出事件的来源的时候,可以认为,G和M是一样的。从而,我们就了解到了黑盒子中的东西。
例子与训练2
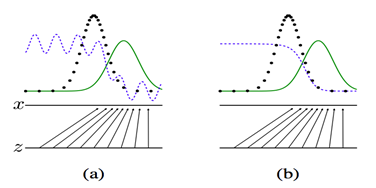
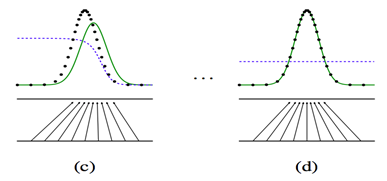
上面四张图a,b,c,d. 黑色的点状线代表M所产生的一些数据,绿色的线代表我们自己模拟的分布G,蓝色的线代表着分类模型D。
a图表示初始状态,b图表示,保持G不动,优化D,直到分类的准确率最高
c图表示保持D不动,优化G,直到混淆程度最高。d图表示,多次迭代后,终于使得G能够完全你和M产生的数据,从而认为,G就是M。
生成式对抗网络的优化是一个二元极小极大博弈(minimax two-player game)问题,它的目的是使生成模型的输出再输入给判别模型时,判别模型很难判断是真实数据还是虚假数据。
极大极小值算法
MiniMax算法(极大极小值算法)是一种找出失败的最大可能性中的最小值的算法(即最小化对手的最大得益),该算法通常是通过递归的形式来实现的;MiniMax算法常用于棋类等两方较量的游戏或者程序中。
该算法是一个零总和算法,即一方要在可选的选项中选择将其优势最大化的选择,另一方则选择令对手优势最小化的一个,其输赢的总和为0(有点像能量守恒,就像本身两个玩家都有1点,最后输家要将他的1点给赢家,但整体上还是总共有2点)。
由于是递归的操作,所以层次深度会非常深,那么可能使用神经网络优化
前向传播阶段
一、可以有两种输入
- 我们随机产生一个随机向量作为生成模型的数据,然后经过生成模型后产生一个新的向量,作为Fake Image,记作D(z)。
- 从数据集中随机选择一张图片,将图片转化成向量,作为Real Image,记作x。
二、将由1或者2产生的输出,作为判别网络的输入,经过判别网络后输入值为一个0到1之间的数,用于表示输入图片为Real Image的概率,real为1,fake为0。
使用得到的概率值计算损失函数,解释损失函数之前,我们先解释下判别模型的输入。根据输入的图片类型是Fake Image或Real Image将判别模型的输入数据的label标记为0或者1。即判别模型的输入类型为 或者 。
判别模型的损失函数
当输入的是从数据集中取出的real Iamge 数据时,我们只需要考虑第二部分,D(x)为判别模型的输出,表示输入x为real 数据的概率,我们的目的是让判别模型的输出D(x)的输出尽量靠近1。
当输入的为fake数据时,我们只计算第一部分,G(z)是生成模型的输出,输出的是一张Fake Image。我们要做的是让D(G(z))的输出尽可能趋向于0。这样才能表示判别模型是有区分力的。
相对判别模型来说,这个损失函数其实就是交叉熵损失函数。计算loss,进行梯度反传。这里的梯度反传可以使用任何一种梯度修正的方法。 当更新完判别模型的参数后,我们再去更新生成模型的参数。
生成模型的损失函数
对于生成模型来说,我们要做的是让G(z)产生的数据尽可能的和数据集中的数据一样。就是所谓的同样的数据分布。那么我们要做的就是最小化生成模型的误差,即只将由G(z)产生的误差传给生成模型。
但是针对判别模型的预测结果,要对梯度变化的方向进行改变。当判别模型认为G(z)输出为真实数据集的时候和认为输出为噪声数据的时候,梯度更新方向要进行改变。 即最终的损失函数为:
其中表示判别模型的预测类别,对预测概率取整,为0或者1.用于更改梯度方向,阈值可以自己设置,或者正常的话就是0.5。
判别模型的目标函数
用数学语言描述整个博弈过程的话,就是:假设我们的生成模型是g(z),其中z是一个随机噪声,而g将这个随机噪声转化为数据类型x,仍拿图片问题举例,这里g的输出就是一张图片。D是一个判别模型,对任何输入x,D(x)的输出是0-1范围内的一个实数,用来判断这个图片是一个真实图片的概率是多大。令Pr和Pg分别代表真实图像的分布与生成图像的分布,我们判别模型的目标函数如下:

整体目标函数
类似的生成模型的目标是让判别模型无法区分真实图片与生成图片,那么整个的优化目标函数如下:

在我们的函数V(D,G)中,第一项是来自实际分布(pdata(x))的数据通过鉴别器(也称为最佳情况)的熵(Entropy)。鉴别器试图将其最大化为1。第二项是来自随机输入(p(z))的数据通过发生器的熵。生成器产生一个假样本, 通过鉴别器识别虚假(也称为最坏的情况)。在这一项中,鉴别器尝试将其最大化为0(即生成的数据是伪造的的概率的对数是0)。所以总体而言,鉴别器正在尝试最大化函数V(D,G)。
另一方面,生成器的任务完全相反,它试图最小化函数V(D,G),使真实数据和假数据之间的区别最小化。这就是说,生成器和鉴别器像在玩猫和老鼠的游戏。
论文中有推导过程,但有些跳步,从这里可以看到详细的推导过程: https://blog.csdn.net/susanzhang1231/article/details/76906340
下图是论文中的算法流程:

训练细节
概括来讲,包括两个阶段:
第一阶段:训练鉴别器,冻结生成器(冻结意思是不训练,神经网络只向前传播,不进行 Backpropagation 反向传播)。
第二阶段:训练生成器,冻结鉴别器。

训练对抗网络的步骤:
- 定义问题。你想生成假的图像还是文字?你需要完全定义问题并收集数据。
- 定义 GAN 的架构。GAN 看起来是怎么样的,生成器和鉴别器应该是多层感知器还是卷积神经网络?这一步取决于你要解决的问题。
- 用真实数据训练鉴别器 N 个 epoch。训练鉴别器正确预测真实数据为真。这里 N 可以设置为 1 到无穷大之间的任意自然数。
- 用生成器产生假的输入数据,用来训练鉴别器。训练鉴别器正确预测假的数据为假。
- 用鉴别器的出入训练生成器。当鉴别器被训练后,将其预测值作为标记来训练生成器。训练生成器来迷惑鉴别器。
- 重复第 3 到第 5 步多个 epoch。
- 手动检查假数据是否合理。如果看起来合适就停止训练,否则回到第 3 步。这是一个手动任务,手动评估数据是检查其假冒程度的最佳方式。当这个步骤结束时,就可以评估 GAN 是否表现良好。
noise输入的解释
假设我们现在的数据集是一个二维的高斯混合模型,那么这么noise就是x轴上我们随机输入的点,经过生成模型映射可以将x轴上的点映射到高斯混合模型上的点。当我们的数据集是图片的时候,那么我们输入的随机噪声其实就是相当于低维的数据,经过生成模型G的映射就变成了一张生成的图片G(x)。
最终两个模型达到稳态的时候判别模型D的输出接近1/2,也就是说判别器很难判断出图片是真是假,这也说明了网络是会达到收敛的。
优势和劣势
优势:
- Markov链不需要了,只需要后向传播就可以了。
- 生成网络不需要直接用样本来更新了,这是一个可能存在的优势。
- 对抗网络的表达能力更强劲,而基于Markov链的模型需要分布比较模糊才能在不同的模式间混合。
劣势:
- 对于生成模型,没有直接的表达,而是由一些参数控制。
- D需要和G同步的很好才可以。
总结

图中上半部分是GAN模型的基本架构。我们先从一个简单的分布中采样一个噪声信号 z(实际中可以采用[0, 1]的均匀分布或者是标准正态分布),然后经过一个生成函数后映射为我们想要的数据分布 Xg (z 和 X 都是向量)。生成的数据和真实数据都会输入一个识别网络 D。识别网络通过判别,输出一个标量,表示数据来自真实数据的概率。
在实现上,G 和 D 都是可微分函数,都可以用多层神经网络实现。因此上面的整个模型的参数就可以利用backpropagation来训练得到。
图中的下半部分是模型训练中的目标函数。仔细看可以发现这个公式很像cross entropy,注意D是 P(Xdata) 的近似。对于 D 而言要尽量使公式最大化(识别能力强),而对于 G 又想使之最小(生成的数据接近实际数据)。
整个训练是一个迭代过程,但是在迭代中,对 D 的优化又是内循环。所以每次迭代,D 先训练 k次,G 训练一次。
拓展延伸
GAN模型最大的优势就是训练简单,但是也有缺点比如训练的稳定性。有趣的是,在这篇文章future work部分,作者提出了5个可能扩展的方向,而现在回过头来看,后续的很多工作真的就是在照着这几个思路填坑。比如第一个conditional generative model就是后面要讲的conditional GAN的思路,而最后一个determing better distribution to sample z from during training则是后面InfoGAN的思路。
所以基于这些,先对关于GANs的一些延伸做个总结,方便以后的学习。
衍生模型结构图:
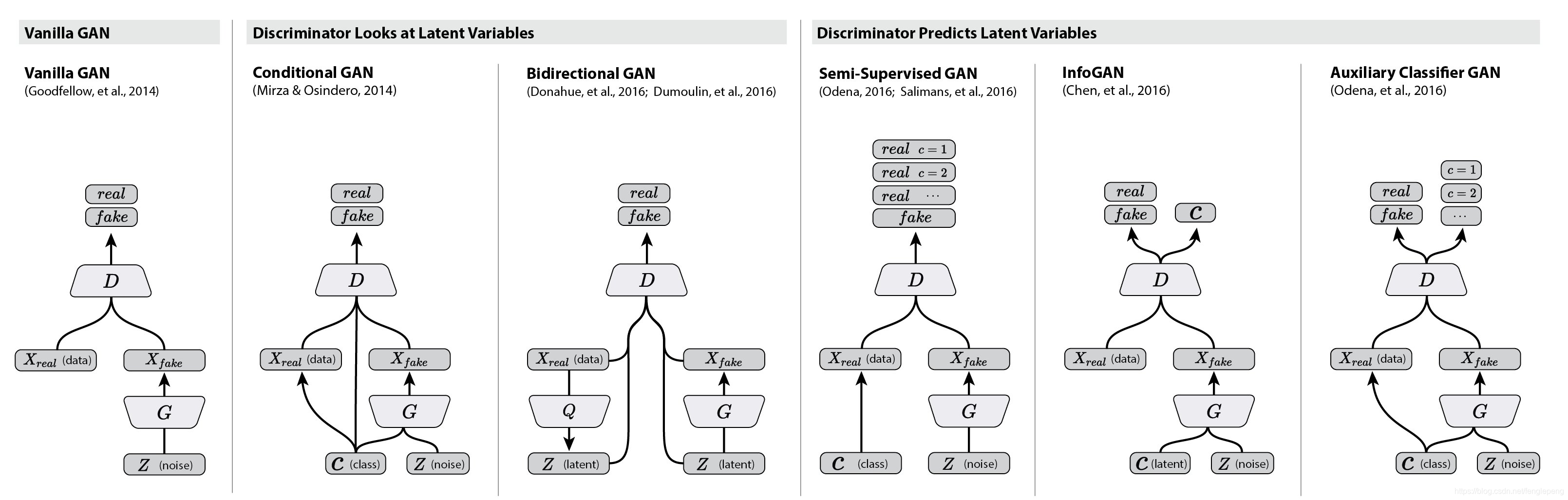
DCGAN
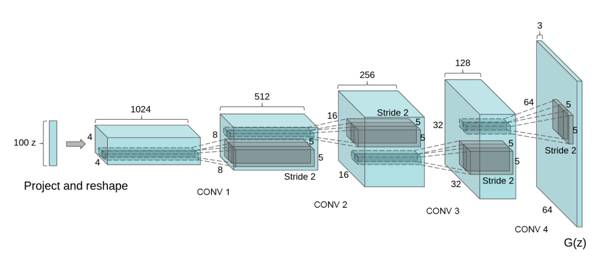
为了方便大家更好地理解生成式对抗网络的工作过程,下面介绍一个GAN的使用场景——在图片中的生成模型DCGAN。
在图像生成过程中,如何设计生成模型和判别模型呢?深度学习里,对图像分类建模,刻画图像不同层次,抽象信息表达的最有效的模型是:CNN (convolutional neural network,卷积神经网络)。

CNN是深度神经网络的一种,可以通过卷积层(convolutional layer)提取不同层级的信息,如上图所示。CNN模型以图片作为输入,以图片、类别抽象表达作为输出,如:纹理、形状等等,其实这与人类对图像的认知有相似之处,即:我们对一张照片的理解也是多层次逐渐深入的。
那么生成图像的模型应该是什么样子的呢?想想小时候上美术课,我们会先考虑构图,再勾画轮廓,然后再画细节,最后填充颜色,这事实上也是一个多层级的过程,就像是把图像理解的过程反过来,于是,人们为图像生成设计了一种类似反卷积的结构:Deep convolutional NN for GAN(DCGAN)
“反卷积”—上采样卷积
反卷积,英文decovolution。根据wiki的定义,其实是对卷积的逆向操作,也就是通过将卷积的输出信号,经过反卷积可以还原卷积的输入信号,还原的不仅仅是shape,还有value。
但是深度学习中的所讲的反卷积实质是transport convolution。只是从2010年一篇论文将其叫做了deconvolution,然后才有了这个名字。先看下卷积的可视化:

4x4的输入信号,经过3x3 的filters,产生了2x2的feature map。那什么是transport-convolution?可视化:

2x2的输入信号,经过3x3 的filters,产生了4x4的feature map。从小的维度产生大的维度,所以transport-convolution又称为上采样卷积。
那为什么叫做transport(转置)?
因为“反卷积”存在于卷积的反向传播中。其中反向传播的滤波器矩阵,是前向传播(卷积)的转置,所以,这就是它的名字的由来。只不过我们把反向传播的操作拿到了前向传播来做,就产生了所谓的反卷积一说。但是transport-convolution只能还原信号的大小,不能还原其value,所以,不能叫做反卷积,不是真正的逆操作。
用到的其他Trick
- 比如D用的是lrelu激活函数,G用的是relu
- 使用batch_normalization.
- 去掉了pooling层,使用stride-convolution(也就是stride=2)
- 学习率必须很小,比如论文中,rate=0.0002
DCGAN采用一个随机噪声向量作为输入,如高斯噪声。输入通过与CNN类似但是相反的结构,将输入放大成二维数据。通过采用这种结构的生成模型和CNN结构的判别模型,DCGAN在图片生成上可以达到相当可观的效果。如下是一些生成的案例照片。
DCGAN结果图-矢量计算:
DCGAN能改进GAN训练稳定的原因
- 使用步长卷积代替上采样层,卷积在提取图像特征上具有很好的作用,并且使用卷积代替全连接层。
生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm)- 在判别器中使用leakrelu激活函数,而不是RELU,防止梯度稀疏,生成器中仍然采用relu,但是输出层采用tanh。
- 使用adam优化器训练,并且学习率最好是`0.0002`,(我也试过其他学习率,不得不说0.0002是表现最好的了)
参考资料
- https://arxiv.org/pdf/1406.2661.pdf
- https://arxiv.org/pdf/1511.06434.pdf
- https://arxiv.org/pdf/1701.07875.pdf




)

安装及使用(网络资料整理))





)
)



)

