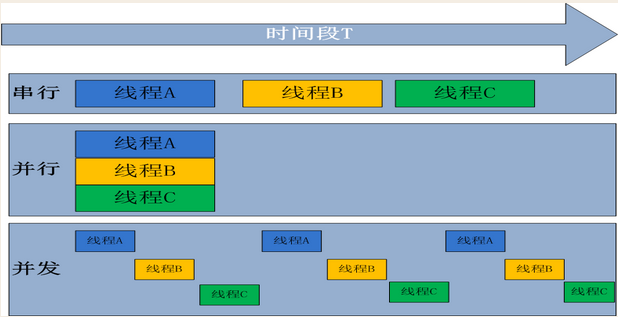
1. 架构师之路(1)---面向过程和面向对象
1、引言
机算机科学是一门应用科学,它的知识体系是典型的倒三角结构,所用的基础知识并不多,只是随着应用领域和方向的不同,产生了很多的分支,所以说编程并不是一件很困难的事情,一个高中生经过特定的训练就可以做得到。但是,会编程和编好程绝对是两码事,同样的程序员,有的人几年之后成为了架构师,有的人却还在不停地coding,只不过ctrl-c、ctrl-v用得更加纯熟了。在中国,编程人员最终的归途无外乎两条:一是转向技术管理,它的终点是CTO;二是继续深入,它的终点是首席架构师,成为CEO的人毕竟是少数。如果你现在还是个普通的程序员,希望继续在技术这条路上前进的话,我想你还是应该先补充一点软件工程的思想,学习一点有关设计模式的知识,只有具备这些能力,你才能从整体和宏观层面来考虑问题、分析问题和解决问题。本人Coding了很多年,中间走了不少弯路,虽然最终没什么大成就,但总算有一些心得,很愿意把自己的一些经验拿出来跟大家分享,这或许对你的发展有所帮助。
由程序员转为架构师,最绕不开的概念就算是面向对象(OO)了。记得在大学的时候,我们专业开了一门课叫《面向对象的编程》。那个时候,我们刚刚学了一门C语言,开发环境用的还是DOS下的TurboC,半点项目开发的经验都没有,纯粹的空对空。所以,一学期下来,我始终处于一种懵懂状态,既没领会面向过程和面向对象到底有什么区别,也没搞懂面向对象能带来什么好处。
2、面向过程(OP)和面向对象(OO)
2.1 蛋炒饭和盖浇饭
有人这么形容OP和OO的不同:用面向过程的方法写出来的程序是一份蛋炒饭,而用面向对象写出来的程序是一份盖浇饭。所谓盖浇饭,北京叫盖饭,东北叫烩饭,广东叫碟头饭,就是在一碗白米饭上面浇上一份盖菜,你喜欢什么菜,你就浇上什么菜。我觉得这个比喻还是比较贴切的。
蛋炒饭制作的细节,我不太清楚,因为我没当过厨师,也不会做饭,但最后的一道工序肯定是把米饭和鸡蛋混在一起炒匀。盖浇饭呢,则是把米饭和盖菜分别做好,你如果要一份红烧肉盖饭呢,就给你浇一份红烧肉;如果要一份青椒土豆盖浇饭,就给浇一份青椒土豆丝。
蛋炒饭的好处就是入味均匀,吃起来香。如果恰巧你不爱吃鸡蛋,只爱吃青菜的话,那么唯一的办法就是全部倒掉,重新做一份青菜炒饭了。盖浇饭就没这么多麻烦,你只需要把上面的盖菜拨掉,更换一份盖菜就可以了。盖浇饭的缺点是入味不均,可能没有蛋炒饭那么香。
到底是蛋炒饭好还是盖浇饭好呢?其实这类问题都很难回答,非要比个上下高低的话,就必须设定一个场景,否则只能说是各有所长。如果大家都不是美食家,没那么多讲究,那么从饭馆角度来讲的话,做盖浇饭显然比蛋炒饭更有优势,他可以组合出来任意多的组合,而且不会浪费。
2.2 软件工程
盖浇饭的好处就是“菜”“饭”分离,从而提高了制作盖浇饭的灵活性。饭不满意就换饭,菜不满意换菜。用软件工程的专业术语就是“可维护性”比较好,“饭”和“菜”的耦合度比较低。蛋炒饭将“蛋”“饭”搅和在一起,想换“蛋”“饭”中任何一种都很困难,耦合度很高,以至于“可维护性”比较差。软件工程追求的目标之一就是可维护性,可维护性主要表现在3个方面:可理解性、可测试性和可修改性。面向对象的好处之一就是显著的改善了软件系统的可维护性。
面向过程(OP)和面向对象(OO)是不是就是指编码的两种方式呢?不是!你拿到了一个用户需求,比如有人要找你编个软件,你是不是需要经过需求分析,然后进行总体/详细设计,最后编码,才能最终写出软件,交付给用户。这个过程是符合人类基本行为方式的:先想做什么,再想如何去做,最后才是做事情。有的同学说:“我没按照你说的步骤做啊,我是直接编码的”。其实,你一定会经历了这三个阶段,只不过你潜意识里没有分得那么清楚。对于拿到需求就编码的人,可能编着编着,又得倒回去重新琢磨,还是免不了这些过程,
以OO为例,对应于软件开发的过程,OO衍生出3个概念:OOA、OOD和OOP。采用面向对象进行分析的方式称为OOA,采用面向对象进行设计的方式称为OOD,采用面向对象进行编码的方式称为OOP。面向过程(OP)和面向对象(OO)本质的区别在于分析方式的不同,最终导致了编码方式的不同。
2.3 面向过程(OP)和面向对象(OO)
(未完待续)
2.3 面向过程编程(OPP) 和面向对象编程(OOP)的关系
关于面向过程的编程(OPP)和面向对象的编程(OOP),给出这它们的定义的人很多,您可以从任何资料中找到很专业的解释,但以我的经验来看,讲的相对枯燥一点,不是很直观。除非您已经有了相当的积累,否则说起来还是比较费劲。
我是个老程序员出身,虽然现在的日常工作更多倾向了管理,但至今依然保持编码的习惯,这句话什么意思呢?我跟大家沟通应该没有问题。无论你是在重复我走过的路,或者已经走在了我的前面,大家都会有那么一段相同的经历,都会在思想层面上有一种理解和默契,所以我还是会尽量按照大多数人的常规思维写下去。
面向过程的编程(OPP)产生在前,面向对象的编程(OOP)产生在后,所以面向对象的编程(OOP)一定会继承前者的一些优点,并摒弃前者存在的一些缺点,这是符合人类进步的自然规律。两者在各自的发展和演变过程中,一定会相互借鉴,相互融合,吸收对方的优点,从而出现某些方面的趋同性。但是,即使两者有更多的相似点,也不会改变它们本质上的不同,因为它们的出发点不同,完全是两种截然不同的思维方式。关于两者的关系,我的观点是这样的:面向对象编程(OOP)在局部上一定是面向过程(OP)的,面向过程的编程(OPP)在整体上应该借鉴面向对象(OO)的思想。这一段说的的确很空洞,而且也一定会有引来争议,不过,我劝您还是在阅读了后面的内容之后,再来评判我观点的正确与否。
象C++、C#、Java等都是面向对象的语言,c,php(暂且这么说,因为php4以后就支持OO)都是面向过程的语言,那么是不是我用C++写的程序一定就是面向对象,用c写的程序一定就是面向过程呢?这种观点显然是没有真正吃透两者的区别。语言永远是一种工具,前辈们每创造出来的一种语言,都是你用来实现想法的利器。我觉得好多人用C#,Java写出来的代码,要是仔细看看,那实际就是用面向对象(OO)的语言写的面向过程(OP)的程序。
所以,即使给关羽一根木棍,给你一杆青龙偃月刀,他照样可以打得你满头是包。你就是扛着个偃月刀,也成不了关羽,因为你缺乏关羽最本质的东西---绝世武功。同样的道理,如果你没有领会OO思想,怎么可能写得出真正的OO程序呢?
那是不是面向过程就不好,也没有存在的必要了?我从来没有这样说过。事实上,面向过程的编程(OPP)已经存在了几十年了,现在依然有很多人在使用。它的优点就是逻辑不复杂的情况下很容易理解,而且运行效率远高于面向对象(OO)编写的程序。所以,系统级的应用或准实时系统中,依然采用面向过程的编程(OPP)。当然,很多编程高手以及大师级的人物,他们由于对于系统整体的掌控能力很强,也喜欢使用面向过程的编程(OPP),比如像Apache,QMail,PostFix,ICE等等这些比较经典的系统都是OPP的产物。象php这些脚本语言,主要用于web开发,对于一些业务逻辑相对简单的系统,也常使用面向过程的编程(OPP),这也是php无法跨入到企业级应用开发的原因之一,不过php5目前已经能够很好的支持OO了。
2.4 详解面向过程的编程(OPP)
在面向对象出现之前,我们采用的开发方法都是面向过程的编程(OPP)。面向过程的编程中最常用的一个分析方法是“功能分解”。我们会把用户需求先分解成模块,然后把模块分解成大的功能,再把大的功能分解成小的功能,整个需求就是按照这样的方式,最终分解成一个一个的函数。这种解决问题的方式称为“自顶向下”,原则是“先整体后局部”,“先大后小”,也有人喜欢使用“自下向上”的分析方式,先解决局部难点,逐步扩大开来,最后组合出来整个程序。其实,这两种方式殊路同归,最终都能解决问题,但一般情况下采用“自顶向下”的方式还是较为常见,因为这种方式最容易看清问题的本质。
我举个例子来说明面向过程的编程方式:
用户需求:老板让我写个通用计算器。
最终用户就是老板,我作为程序员,任务就是写一个计算器程序。OK,很简单,以下就是用C语言完成的计算器:
假定程序的文件名为:main.c。
int main(int argc, char *argv[]){
//变量初始化
int nNum1,nNum2;
char cOpr;
int nResult;
nNum1 = nNum2 = 0;
cOpr = 0;
nResult = 0;
//输入数据
printf("Please input the first number:/r/n");
scanf("%d",&nNum1);
printf("Please input the operator:/r/n");
scanf("%s",&cOpr);
printf("Please input the second number:/r/n");
scanf("%d",&nNum2);
//计算结果
if( cOpr == '+' ){
nResult = nNum1 + nNum2;
}else if( cOpr == '-' ){
nResult = nNum1 - nNum2;
}else{
printf("Unknown operator!");
return -1;
}
//输出结果
printf("The result is %d!",nResult);
return 0;
}
抛开细节不讲,我想大多数人差不多都会这么实现吧,很清晰,很简单,充分体现了“简单就是美”的原则,面向过程的编程就是这样有条理的按照顺序来逐步实现用户需求。
凡是做过程序的人都知道,用户需求从来都不会是稳定的,最多只能够做到“相对稳定”。用户可能会随时提出加个功能,减个功能的要求,也可能会要求改动一下流程,程序员最烦的就是频繁地变动需求,尤其是程序已经写了大半了,但这种情况是永远无法避免的,也不能完全归罪到客户或者需求分析师。
以我们上面的代码为例,用户可能会提出类似的要求:
首先,你程序中实现了“加法”和“减法”,我还想让它也能计算“乘法”、“除法”。
其次,你现在的人机界面太简单了,我还想要个Windows计算器的界面或者Mac计算器的界面。
用户需求开始多了,我得琢磨琢磨该如何去写这段代码了。我今天加了“乘”“除”的运算,明天保不齐又得让我加个“平方”、“立方”的运算,这要是把所有的运算都穷尽了,怎么也得写个千八百行代码吧。还有,用户要求界面能够更换,还得写一大堆界面生成的代码,又得来个千八百行。以后,这么多代码堆在一起,怎么去维护,找个变量得半天,看懂了代码得半天,万一不小心改错了,还得调半天。另外,界面设计我也不擅长,得找个更专业的人来做,做完了之后再加进来吧。这个过程也就是“软件危机”产生的过程。伴随着软件广泛地应用于各个领域,软件开发的规模变得越来越大,复杂度越来越高,而其用户的需求越来越不稳定。
根据用户提出的两个需求,面向过程的编程该如何去应对呢?我想大家都很清楚怎么去改。Very easy,把“计算”和“界面”分开做成两个独立的函数,封装到不同的文件中。
假定程序的文件名为:main.c。
#include "interface.h"
#include "calculate.h"
int main(int argc, char *argv[]){
//变量初始化
int nNum1,nNum2;
char cOpr;
int nResult;
nNum1 = nNum2 = 0;
cOpr = 0;
nResult = 0;
//输入数据
if( getParameters(&nNum1,&nNum2,&cOpr) == -1 )
return -1;
//计算结果
if( calcMachine(nNum1,nNum2,cOpr,&nResult) == -1 )
return -1;
//输出结果
printf("The result is %d!",nResult);
return 0;
}
interface.h:
int getParameters(int *nNum1,int * nNum2,char *cOpr);
interface.c:
int getParameters(int *nNum1,int * nNum2,char *cOpr){
printf("Please input the first number:/r/n");
scanf("%d",nNum1);
printf("Please input the operator:/r/n");
scanf("%s",cOpr);
printf("Please input the second number:/r/n");
scanf("%d",nNum2);
return 0;
}
calculate.h:
int calcMachine(int nNum1,int nNum2,char cOpr, int *nResult);
calculate.c:
int calcMachine(int nNum1,int nNum2,char cOpr,int *nResult){
if( cOpr == '+' ){
*nResult = nNum1 + nNum2;
}else if( cOpr == '-' ){
*nResult = nNum1 - nNum2;
}else{
printf("Unknown operator!");
return -1;
};
return 0;
}
“计算”和“界面”分开之后,添加新功能或者修改bug就方便多了,遇到与“计算”相关的需求就去修改calculate模块,遇到与“界面”相关的需求就去修改interface模块,因此,整个系统模块之间的“耦合度”就被放松了,可维护性有了一定程度的改善。
面向过程的编程(OPP)就是将用户需求进行“功能分解”。把用户需求先分解成模块(.h,.c),再把模块(.h,.c)分解成大的功能(function),然后把大的功能(function)分解成小的功能(function),如此类推。
功能分解是一项很有技术含量的工作,它不仅需要分解者具有丰富的实战经验,而且需要科学的理论作为指导。如何分解,分解原则是什么,模块粒度多大合适?这些都是架构师的要考虑的问题,也是我们后面要着重讲的内容。
面向过程的编程(OPP)优点是程序顺序执行,流程清晰明了。它的缺点是主控程序承担了太多的任务,各个模块都需要主控程序进行控制和调度,主控和模块之间的承担的任务不均衡。
有的人把面向过程定义为:算法 + 数据结构,我觉得也很准确。面向过程的编程中算法是核心,数据处于从属地位,数据随算法而流动。所以采用面向过程的方式进行编程,一般在动手之前,都要编写一份流程图或是数据流图。
--------------------------------------------------------
如果大家对本文有意见尽可争论,欢迎大家随时拍砖。我有着钢铁一样的心脏和城墙一样的脸皮,承受能力极强,所以无论是支持意见还是反对反对意见,我都会认真阅读,只要不是色情淫秽和反动言论,我尽量不删贴。如果碰到不能理解或者错误之处,请指出,我会进行验证和修改。由于个人能力和时间有限,也只能写到这样的水平了,大家谅解。有的朋友找我的qq号,我的资料里就有,加为好友后就可以看到,我的qq对任何人开放。
3 架构师的职责
近来看到CSDN上有个CTO俱乐部,里面聊得是不亦乐乎。我怀着无比崇敬的态度,拜读了一下牛人们的发言。里面有个哥们发起一个话题:“CTO,你多久没有写程序了?”。有人回答:“不写代码的CTO,属于......这公司问题大了!”。看到这里,我就赶紧撤了,怕忍不住反驳几句,反而遭到牛人们的群殴。试想,一个上点规模的IT公司,还得靠CTO来写程序的话,那是不是才叫问题大了呢。当然,我没有做过CTO,所以我有我的不同看法,而且还愿意表达出来,无知者无畏。我情愿相信:我所理解的CTO跟这位CTO所理解的是两回事。所以我想,如果有人能把CTO的职责给标准化了,也许就不会有这么多的争论了。
同样的道理,关于架构师的定义,大家也有着不同的理解。什么是架构师?架构师有哪些职责?我觉得有必要提前明确一下,要不然大家沟通起来也会产生类似问题,子说子理,卯说卯理,但是压根说得不是一码子事。
3.1 什么是架构师
曾经有这么个段子:
甲:我已经应聘到一家中型软件公司了,今天上班的时候,全公司的人都来欢迎我。
乙:羡慕ing,都什么人来了?
甲:CEO、COO、CTO、All of 程序员,还有会计、司机都来了。
乙:哇,他们太重视你了,人才啊,这么多人迎接你!
甲:没有啊,就一个人!
乙:靠,#%¥$%...
很多的创业公司,一人身兼数职的情形还是很常见的。至少,我是经历过的,一个人包办了所有的开发过程,连测试我都做了,绝对的一条龙,但是经常踩钢丝、骑独轮车总会有失足的时候,结果有一次,从我手里发出去的光盘母盘,含有病毒僵尸,以至于被迫收回已经推上市场的2万张光盘,从那之后,我的心脏就开始变得无比坚强,现在就是整个后台服务都瘫痪了,我也只是微微一笑。其实,一个人身兼架构师和程序员,甚至多种角色,没什么不妥,后面还会讲这个话题,这种现象不是中国特色,跟国外是完全接轨的。我曾经跟米国的一个工程师在msn中聊过类似的话题,发现他们的路子跟咱们没什么不同,在IT这个行业,我们跟世界的差距只有1天,他们刚弄出来的新东西,我们这里第2天保准见得到。
架构师这个称呼不是拍脑袋想出来的,是有国际标准(ISO/IEC42010)可查的。架构师是软件开发活动中的众多角色之一,它可能是一个人、一个小组,也可能是一个团队。微软对架构师有一个分类参考,我们参考一下,他们把架构师分为4种:企业架构师EA(Enterprise Architect)、基础结构架构师IA(InfrastructureArchitect)、特定技术架构TSA(Technology-Specific Architect)和解决方案架构师SA (SolutionArchitect)。微软的这个分类是按照架构师专注的领域不同而划分的。
EA的职责是决定整个公司的技术路线和技术发展方向。盖茨给自己的Title就是首席软件架构师,网易丁磊也喜欢这么称呼自己,实际上就是EA角色;IA的工作就是提炼和优化技术方面积累和沉淀形成的基础性的、公共的、可复用的框架和组件,这些都是一个技术型公司传承下来的最宝贵的财富之一;特定技术架构师TSA,他们主要从事类似安全架构、存储架构等专项技术的规划和设计工作;SA的工作则专于解决方案的规划和设计,“解决方案”这个词在中国已经到了严重泛滥的程度,大忽悠们最喜欢把它挂在嘴边。所谓解决方案,就是把产品、技术或理论,不断地进行组合,来创造出满足用户需求的选择。售前工程师一般都是带着它到客户那里去发挥的。
大公司会把各种类型的架构师分得很清楚,小公司一般就不那么讲究了,架构师多数是是IA+TSA+SA,一人包打天下,所以说大公司出专才,小公司出全才。
实际工作中,我们也经常会见到另一种比较简单的分类方式,把架构师分为软件架构师和系统架构师。软件架构师基本上是TSA+IA,这也是程序员最容易突破,最可能走上的一条道路,比如JAVA架构师、DotNet架构师、LAPM架构师等等,我后面所讲的内容都是与软件架构师的相关的话题。系统架构师实际上是SA+TSA,更着力于综合运用已有的产品和技术,来实现客户期望的需求。系统架构师要求通晓软、硬件两方面的知识,所以它的知识体系相对庞杂。关于系统架构师的话题,我们可以稍后再作讨论。
3.2 架构师的职责
架构师需要参与项目开发的全部过程,包括需求分析、架构设计、系统实现、集成、测试和部署各个阶段,负责在整个项目中对技术活动和技术说明进行指导和协调。
架构师主要职责有4条:
1、确认需求
在项目开发过程中,架构师是在需求规格说明书完成后介入的,需求规格说明书必须得到架构师的认可。架构师需要和分析人员反复交流,以保证自己完整并准确地理解用户需求。
2、系统分解
依据用户需求,架构师将系统整体分解为更小的子系统和组件,从而形成不同的逻辑层或服务。随后,架构师会确定各层的接口,层与层相互之间的关系。架构师不仅要对整个系统分层,进行“纵向”分解,还要对同一逻辑层分块,进行“横向”分解。
软件架构师的功力基本体现于此,这是一项相对复杂的工作。
3、技术选型
架构师通过对系统的一系列的分解,最终形成了软件的整体架构。技术选择主要取决于软件架构。
Web Server运行在Windows上还是Linux上?数据库采用MSSql、Oracle还是Mysql?需要不需要采用MVC或者Spring等轻量级的框架?前端采用富客户端还是瘦客户端方式?类似的工作,都需要在这个阶段提出,并进行评估。
架构师对产品和技术的选型仅仅限于评估,没有决定权,最终的决定权归项目经理。架构师提出的技术方案为项目经理提供了重要的参考信息,项目经理会从项目预算、人力资源、时间进度等实际情况进行权衡,最终进行确认。
4、制定技术规格说明
架构师在项目开发过程中,是技术权威。他需要协调所有的开发人员,与开发人员一直保持沟通,始终保证开发者依照它的架构意图去实现各项功能。
架构师与开发者沟通的最重要的形式是技术规格说明书,它可以是UML视图、Word文档,Visio文件等各种表现形式。通过架构师提供的技术规格说明书,保证开发者可以从不同角度去观察、理解各自承担的子系统或者模块。
架构师不仅要保持与开发者的沟通,也需要与项目经理、需求分析员,甚至与最终用户保持沟通。所以,对于架构师来讲,不仅有技术方面的要求,还有人际交流方面的要求。
3.3 架构师的误区
1、架构师就是项目经理
架构师不是项目经理。项目经理侧重于预算控制、时间进度控制、人员管理、与外部联系和协调等等工作,具备管理职能。一般小型项目中,常见项目经理兼架构师。
2、架构师负责需求分析
架构师不是需求分析员。需求分析人员的工作是收集需求和分析需求,并与最终用户、产品经理保持联系。架构师只对最终的需求审核和确认,提出需求不清和不完整的部分,他会跟需求分析员时刻保持联系。架构师是技术专家,不是业务专家。
3、架构师从来不写代码
这是一个尚存争论的问题。目前有两种观点:
观点1:架构师不写代码,写代码纯体力活,架构师写代码大材小用。架构师把UML的各种视图交给开发人员,如果有不明确的地方,可以与架构师随时沟通。
观点2:架构师本来自于程序员,只是比程序员站的层面更高,比程序员唯一多的是经验和知识,所以架构师也免不了写代码。
我个人觉得这两种说法是与架构师的出身和所处的环境有关。
架构师首先是一个技术角色,所以一定是来自于技术人员这个群体,比如系统架构师,多是来自于运维人员,可能本身代码写得并不多,或者说写不出来很漂亮的代码。软件架构师多是来自于程序员,有着程序员的血统和情怀,所以在项目开发过程中,可能会写一些核心代码。我们的理想是架构师不用写代码,但事实上有时候过于理想。架构师写不写代码,可能取决于公司的规模、文化、开发人员的素质等现实情况。另外,架构师也不是跟程序员界限分得那么清楚,按照能力也有高中低之分,写不写代码不是区分两者的根本标准。
3.4 架构师的基本素质
周星驰有个片子《喜剧之王》,剧中的尹天仇整天揣着本《演员的自我修养》,一个好演员不仅需要天赋,也需要一定的理论指导,无师自通的人毕竟是少数。架构师的成长过程也是这样。从普通程序员到高级程序员,再到架构师,是一个经验积累和思想升华的过程。经验积累是一个方面,素质培养是另一个方面,两者相辅相成,所以我觉得有必要把架构师的所要具备的素质罗列一下,作为程序员努力的方向。
1、沟通能力
为了提高效率,架构师必须赢得团队成员、项目经理、客户或用户认同,这就需要架构师具有较强的沟通能力。沟通能力是人类最普遍性的素质要求,技术人员好像容易忽略,想成为架构师就不能忽略。千万不要抱着这样的观念:怀才跟怀孕似的,时间久了总会被人发现的。还是天桥上卖大力丸的哥们说得对:光说不练假把式,光练不说傻把式。看看你周围的头头脑脑们,哪一个不是此中高手,我们千万不要鄙视,认为这是阿谀奉承、投机钻营,凡事都要看到积极的一面,“沟通”的确是一种能力。我认为自己是一个略内向的人,因为我是农村出来的孩子,普通话都说不好,以前或多或少带有点自卑感,幻想着是金子总会发光,所以在职业生涯中吃了不少亏。现在,我深深懂得了沟通的重要性,我会很主动地跟同事们,跟老大们不定时地沟通,感觉工作起来顺畅多了。
这一条我认为最为重要,所以排在首位。我甚至认为下面几条都可以忽略,唯一这一条得牢记,而且要常常提醒自己。
2、领导能力
架构师能够推动整个团队的技术进展,能在压力下作出关键性的决策,并将其贯彻到底。架构师如何来保证这种执行力?这就需要架构师具有领导能力。
架构师的领导能力的取得跟项目经理不太一样。项目经理主要负责解决行政管理,这种能力与技术关系不大,他有人权和财权,再扯上一张“领导”的虎皮,采用“胡萝卜加大棒”的方式,基本上可以保证执行力。架构师在项目里面可能更多地使用非正式的领导力,也就是我们常说的影响力,里面包括个人魅力、技术能力、知识传递等等。
3、抽象思维和分析能力
架构师必须具备抽象思维和分析的能力,这是你进行系统分析和系统分解的基本素质。只有具备这样的能力,架构师才能看清系统的整体,掌控全局,这也是架构师大局观的形成基础。你如何具备这种能力呢?一是来自于经验,二是来自于学习。架构师不仅要具备在问题领域上的经验,也需要具备在软件工程领域内的经验。也就是说,架构师必须能够准确得理解需求,然后用软件工程的思想,把需求转化和分解成可用计算机语言实现的程度。经验的积累是需要一个时间过程的,这个过程谁也帮不了你,是需要你去经历的。但是,如果你有意识地去培养,不断吸取前人的经验的话,还是可以缩短这个周期的。这也是我写作此系列的始动力之一。
4、技术深度和广度
架构师最好精通1-2个技术,具备这种技术能力可以更加深入的理解有关架构的工作原理,也可以拉近和开发人员的距离,并形成团队中的影响力。
架构师的技术知识广度也很重要,需要了解尽可能多的技术,所谓见多识广,只有这样,才可能综合各种技术,选择更加适合项目的解决方案。有的人说,架构师技术广度的要求高于技术深度的要求,这是很有道理的。
总而言之,一句话:架构师是项目团队中的技术权威。
面向过程和面向对象这两个基本概念,不仅架构师需要非常清楚,程序员、设计师也要非常清楚,这也是系统分析、设计和编码最基本的常识。我接触的程序员,很多人只停留在一种“似是而非”的程度,这是不行的,想要继续前进,就得把基础夯实,所以我觉得很有必要先回回炉,补补课。
---------------------------------------------------------------------------------------------------
后记:在讲面向对象之前写了这么一篇,主要就是要把前面漏下的功课补上。
架构师之路(4)---详解面向对象
3.5 详解面向对象的编程(OOP)
3.5.1 什么是面向对象
刚接触编程的时候,多数人本能的反映可能是面向过程(OP)的,而不是面向对象(OO)的。这种现象其实是很正常的,改变思维方式是需要一个过程的,我大体归纳了一下其形成的原因:
1、直接原因
你还没有养成面向对象分析问题和解决问题的习惯。建立面向对象的思维方式需要一定时间的训练和揣摩才能形成,所以你可以在学习或具体项目中刻意地强化这种意识。一般情况下,经过一段时间之后,你会觉得这是自然而然的事情,只有心中OO,眼中自然OO了。
2、历史原因
我们从小接受的培训都是采用面向过程(OP)的方式分析问题和解决问题,尤其是数学,多数是强调按部就班的解决问题,计算机软件的发展一直就与数学是很有渊源,所以,顺理成章的,把面向过程(OP)的方式带入到软件开发也是很自然的事情。
什么是面向对象,或者谈谈你对面向对象的理解,这恐怕是软件开发人员,尤其是程序员和设计师应聘的时候,面试官常最挂在嘴边的问题吧。面向对象对应的英文是Object-Oriented,把Object-Oriented翻译成“面向对象”,我一直觉得这个译法不太确切,因为多数人第一次看到“面向对象”这四个字,都很难从字面上理解它到底是什么意思。后来,我又查阅了一些有关的资料,发现港澳台的计算机书籍中是把它翻译成了“物件导向”,这个译法,我感觉不错,于我心颇有些戚戚焉。“物件导向”比较准确地反映了面向对象认识和解决问题都是要围绕对象展开的。
所以,面向对象的思维方式认为:软件系统是一组交互的对象的集合。一组相关的对象组合为一个子系统,一组子系统继续组合为更复杂的子系统,直至组合成整个系统。
面向对象方式的出发点是尽可能模拟人类习惯的思维方式,将“问题域”中涉及的内容抽象为“对象”,使软件开发的方法与过程尽可能接近人类认识世界解决问题的方法与过程。
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
面向过程认识和解决问题的思维,可以称为“流程论”,重点放在处理过程的步骤,流程是整个系统的核心。
面向对象认识和解决问题的思维,可以称为“组装论”,重心放在对象的抽象和提取上,然后将对象组装为整体。
所以OO和OP从思维方式来讲,出发点还是完全不同的。
3.5.2 OP PK OO
咱们用象棋对战的例子,来比较OP和OO的不同:
红方:功夫熊猫 黑方:悍娇虎 裁判:龟仙人
采用面向过程(OPP)的设计思路,首先分拆整个对战过程,分析双方对战的步骤,得到如下流程:
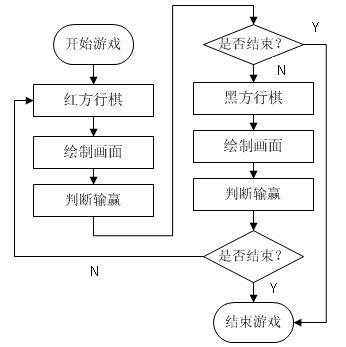
把上面每个步骤分别用函数进行实现,问题就解决了。
我们再来看看面向对象是如何来解决问题,整个象棋游戏可以抽象出3种对象:
1、棋手,负责行棋,这两者行为一致。
2、棋盘,负责绘制棋盘画面。
3、裁判,负责判定诸如吃子、犯规和输赢。
三者之间的关系如下:
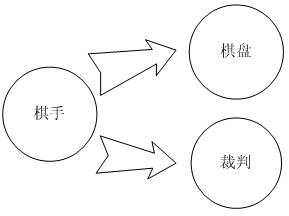
第一类对象棋手负责行棋,并告知第二类对象棋盘中棋子布局的变化,棋盘接收到了棋子布局的变化后,负责在绘制屏幕,同时利用第三类对象裁判来对棋局进行判定。
从以上两种的实现方式可以看出几点:
1、可维护性
面向对象是以数据和功能来划分问题,而不是依据流程和步骤。同样是绘制棋盘的行为,在面向过程的设计中分散在了很多的步骤中,很可能出现在不同的绘制版本中,只是不是很像一份“蛋炒饭”中的鸡蛋?在面向对象的设计中,绘图只可能在棋盘对象中出现,从而保证了绘图的统一,这就是把鸡蛋从“蛋炒饭”中分离出来的效果。
2、可扩展性
假如我要加入悔棋的功能,如果要改动面向过程的设计,那么从行棋到显示再到判定这一连串的步骤都要改动,甚至步骤之间的循序都要进行大规模调整。如果是面向对象的话,只用改动棋盘对象就行了,棋盘对象保存了双方的棋谱,简单回溯,减一就可以了,而显示和判定不涉及,同时整体对各个对象功能的调用顺序都没有变化,改动只限定在了局部。
3.5.3 OO的深层思考
OO认为:软件系统是一组交互的对象的集合。
因为人类对现实世界是非常熟悉的,所以OO就是通过抽象的方式,把问题域映射到现实世界,尽量模拟现实世界的万事万物。通过这种方式,就可以运用现实世界中解决问题的方法与过程,来解决软件领域内的问题。
有人说:OO眼里一切皆对象,这句话还是很有道理的。
OO到底给软件开发带来了什么样的好处?OO的抽象的尺度是如何把握的呢?这都是问题。
(未完待续)
---------------------------------------------------------------------------
后记:今天累了,写到这儿吧。晚上回家的时候碰到两个blond beauty,they are from USA。They want to goto 2nd foreign language colledge,but did not know how to get there. Itold them the correct route in English. 我学了这么多年的英语,终于帮了国际友人一个小忙。
架构师之路(5)---面向对象的设计原则
1 OO的设计原则
采用面向对象的分析和设计思想,为我们分析和解决问题提供了一种全新的思维方式。我们在拿到需求之后(略去OOA,以后补全),接下来的问题就是:如何对系统进行面向对象的设计呢?
按照软件工程的理论,面向对象的设计要解决的核心问题就是可维护性和可复用性,尤其是可维护性,它是影响软件生命周期重要因素。通常情况下,软件的维护成本远远大于初期开发成本。
一个可维护性很差的软件设计,人们通常称之为“臭味”的,形成的原因主要有这么几个:过于僵硬、过于脆弱、复用率低或者黏度过高。相反,一个好的系统设计应该是灵活的、可扩展的、可复用的、可插拔的。在20世纪80到90年代,很多业内专家不断探索面向对象的软件设计方法,陆续提出了一些设计原则。这些设计原则能够显著地提高系统的可维护性和可复用性,成为了我们进行面向对象设计的指导原则:
1、单一职责原则SRP
每一个类应该专注于做一件事情。
2、“开-闭”原则OCP
每一个类应该是对扩展开放,对修改关闭。
3、 里氏代换原则LSP
避免造成派生类的方法非法或退化,一个基类的用户应当不需要知道这个派生类。
4、 依赖倒转原则DIP
用依赖于接口和抽象类来替代依赖容易变化的具体类。
5、 接口隔离原则ISP
应当为客户提供尽可能小的接口,而不是提供大的接口。
其中,“开-闭”原则是面向对象的可复用设计的基石,其他设计原则(里氏代换原则、依赖倒转原则、合成/聚合复用原则、迪米特法则、接口隔离原则)是实现“开-闭”原则的手段和工具。
我会为大家一一进行讲解。
2 单一职责原则SRP(Single-Responsibility Principle)
2.1 什么是单一职责
单一职责就是指一个类应该专注于做一件事。现实生活中也存在诸如此类的问题:“一个人可能身兼数职,甚至于这些职责彼此关系不大,那么他可能无法做好所有职责内的事情,所以,还是专人专管比较好。”我们在设计类的时候,就应该遵循这个单一职责原则。
记得有人比喻过软件开发、设计原则、设计模式之间的关系就是战争、战略和战术的关系,关于设计模式实际上是设计原则的具体应用,以后我们还会讲到这一点。另外,大家都很熟悉计算器的例子,很多的人都愿意以此为例,我们也以计算器编程为例说明单一职责原则:
在有些人眼里,计算器就是一件东西,是一个整体,所以它把这个需求进行了抽象,最终设计为一个Calculator类,代码如下:
class Calculator{
public String calculate() {
Console.Write("Please input the first number:");
String strNum1 = Console.ReadLine();
Console.Write(Please input the operator:");
String strOpr= Console.ReadLine();
Console.Write("Please input the second number:");
String strNum2 = Console.ReadLine();
String strResult = "";
if (strOpr == "+"){
strResult = Convert.ToString(Convert.ToDouble(strNum1) + Convert.ToDouble(strNum2));
}
else if (strOpr == "-"){
strResult = Convert.ToString(Convert.ToDouble(strNum1) - Convert.ToDouble(strNum2));
}
else if (strOpr == "*"){
strResult = Convert.ToString(Convert.ToDouble(strNum1) * Convert.ToDouble(strNum2));
}
else if (strOpr == "/"){
strResult = Convert.ToString(Convert.ToDouble(strNum1) / Convert.ToDouble(strNum2));
}
Console.WriteLine("The result is " + strResult);
}
}
另外,还有一部分人认为:计算器是一个外壳和一个处理器的组合。
class Appearance{
public int displayInput(String &strNum1,String &strOpr, String &strNum2) {
Console.Write("Please input the first number:");
strNum1 = Console.ReadLine();
Console.Write(Please input the operator:");
strOpr= Console.ReadLine();
Console.Write("Please input the second number:");
strNum2 = Console.ReadLine();
return 0;
}
public String displayOutput(String strResult) {
Console.WriteLine("The result is " + strResult);
}
}
class Processor{
public String calculate(String strNum1,String strOpr, String strNum2){
String strResult = "";
if (strOpr == "+"){
strResult = Convert.ToString(Convert.ToDouble(strNum1) + Convert.ToDouble(strNum2));
}
else if (strOpr == "-"){
strResult = Convert.ToString(Convert.ToDouble(strNum1) - Convert.ToDouble(strNum2));
}
else if (strOpr == "*"){
strResult = Convert.ToString(Convert.ToDouble(strNum1) * Convert.ToDouble(strNum2));
}
else if (strOpr == "/"){
strResult = Convert.ToString(Convert.ToDouble(strNum1) / Convert.ToDouble(strNum2));
}
return strResult;
}
}
为什么这么做呢?因为外壳和处理器是两个职责,是两件事情,而且都是很容易发生需求变动的因素,所以把它们放到一个类中,违背了单一职责原则。
比如,用户可能对计算器提出以下要求:
第一,目前已经实现了“加法”、“减法”、“乘法”和“除法”,以后还可能出现“乘方”、“开方”等很多运算。
第二,现在人机界面太简单了,还可能做个Windows计算器风格的界面或者Mac计算器风格的界面。
所以,把一个类Calculator 拆分为两个类Appearance和Processor,一个类做一件事情,这样更容易应对需求变化。如果界面需要修改,那么就去修改Appearance类;如果处理器需要修改,那么就去修改Processor类。
我们再举一个邮件的例子。我们平常收到的邮件内容,看起来是一封信,实际上内部有两部分组成:邮件头和邮件体。电子邮件的编码要求符合RFC822标准。
第一种设计方式是这样:
interface IEmail {
public void setSender(String sender);
public void setReceiver(String receiver);
public void setContent(String content);
}
class Email implements IEmail {
public void setSender(String sender) {// set sender; }
public void setReceiver(String receiver) {// set receiver; }
public void setContent(String content) {// set content; }
}
这个设计是有问题的,因为邮件头和邮件体都有变化的可能性。
1、邮件头的每一个域的编码,可能是BASE64,也可能是QP,而且域的数量也不固定。
2、邮件体中封装的邮件内容可能是PlainText类型,也可能是HTML类型,甚至于流媒体。
所谓第一种设计方式违背了单一职责原则,里面封装了两种可能引起变化的原因。
我们依照单一职责原则,对其进行改进后,变为第二种设计方式:
interface IEmail {
public void setSender(String sender);
public void setReceiver(String receiver);
public void setContent(IContent content);
}
interface IContent {
public String getAsString();
}
class Email implements IEmail {
public void setSender(String sender) {// set sender; }
public void setReceiver(String receiver) {// set receiver; }
public void setContent(IContent content) {// set content; }
}
有的资料把单一职责解释为:“仅有一个引起它变化的原因”。这个解释跟“专注于做一件事”是等价的。如果一个类同时做两件事情,那么这两件事情都有可能引起它的变化。同样的道理,如果仅有一个引起它变化的原因,那么这个类也就只能做一件事情。
2.2 单一职责原则的使用
单一职责原则的尺度如何掌握?我们怎么能知道该拆分还是不应该拆分呢?原则很简单:需求决定。如果你所需要的计算器,永远都没有外观和处理器变动的可能性,那么就应该把它抽象为一个整体的计算器;如果你所需要的计算器,外壳和处理器都有可能发生变动,那么就必须把它拆离为外壳和处理器。
单一职责原则实际上是把相同的职责进行了聚合,避免把相同的职责分散到不同的类之中,这样就可以控制变化,把变化限制在一个地方,防止因为一个地方的变动,引起更多地方的变动的“涟漪效应”,单一职责原则避免一个类承担过多的职责。单一职责原则不是说一个类就只有一个方法,而是具有单一功能。
我们在使用单一职责原则的时候,牢记以下几点:
A、一个设计合理的类,应该仅有一个可以引起它变化的原因,即单一职责,如果有多个原因可以引起它的变化,就必须进行分离;
B、在没有需求变化征兆的情况下,应用单一职责原则或其他原则是不明智的,因为这样会使系统变得很复杂,系统将会变成一堆细小的颗粒组成,纯属于没事找抽;
C、在需求能够预计或实际发生变化时,就应该使用单一职责原则来重构代码,有经验的设计师、架构师对可能出现的需求变化很敏感,设计上就会具有一定的前瞻性。
-------------------------------------------------------------
后记:最近看了一个“现场说法”的电视节目,着实有意思。说是最近有两个偷车大盗被我警方抓获。这俩大盗都是贼中高手,非常了得,不过,他们却有着不同的成长路线。
其中一个大盗,苦心钻研开锁技术,专门去香港学习先进技术,前后花了一百多万,非常舍得投资,回来后屡屡得手。另一个大盗,就比较狡猾,整天到商场的停车场,跟随着宝马、奔驰的车主,在车主购物的时候,伺机偷去车钥匙,然后从停车场把车开走,案发的时候案值达到了千万。呵呵,看来干什么事,都得找到关键所在。
架构师之路(6)---OOD的开闭原则
2 开闭原则(Open-Closed Principle,OCP)
2.1 什么是开闭原则
开闭原则是面向对象设计中“可复用设计”的基石,是面向对象设计中最重要的原则之一,其它很多的设计原则都是实现开闭原则的一种手段。
1988年,Bertrand Meyer在他的著作《Object Oriented Software Construction》中提出了开闭原则,它的原文是这样:“Software entities should be open for extension,but closed for modification”。翻译过来就是:“软件实体应当对扩展开放,对修改关闭”。这句话说得略微有点专业,我们把它讲得更通俗一点,也就是:软件系统中包含的各种组件,例如模块(Modules)、类(Classes)以及功能(Functions)等等,应该在不修改现有代码的基础上,引入新功能。开闭原则中“开”,是指对于组件功能的扩展是开放的,是允许对其进行功能扩展的;开闭原则中“闭”,是指对于原有代码的修改是封闭的,即不应该修改原有的代码。
2.2 如何实现开闭原则
实现开闭原则的关键就在于“抽象”。把系统的所有可能的行为抽象成一个抽象底层,这个抽象底层规定出所有的具体实现必须提供的方法的特征。作为系统设计的抽象层,要预见所有可能的扩展,从而使得在任何扩展情况下,系统的抽象底层不需修改;同时,由于可以从抽象底层导出一个或多个新的具体实现,可以改变系统的行为,因此系统设计对扩展是开放的。
我们在软件开发的过程中,一直都是提倡需求导向的。这就要求我们在设计的时候,要非常清楚地了解用户需求,判断需求中包含的可能的变化,从而明确在什么情况下使用开闭原则。
关于系统可变的部分,还有一个更具体的对可变性封装原则(Principle of Encapsulation of Variation, EVP),它从软件工程实现的角度对开闭原则进行了进一步的解释。EVP要求在做系统设计的时候,对系统所有可能发生变化的部分进行评估和分类,每一个可变的因素都单独进行封装。
我们在实际开发过程的设计开始阶段,就要罗列出来系统所有可能的行为,并把这些行为加入到抽象底层,根本就是不可能的,这么去做也是不经济的,费时费力。另外,在设计开始阶段,对所有的可变因素进行预计和封装也不太现实,也是很难做得到。所以,开闭原则描绘的愿景只是一种理想情况或是极端状态,现实世界中是很难被完全实现的。我们只能在某些组件,在某种程度上符合开闭原则的要求。
通过以上的分析,对于开闭原则,我们可以得出这样的结论:虽然我们不可能做到百分之百的封闭,但是在系统设计的时候,我们还是要尽量做到这一点。
对于软件系统的功能扩展,我们可以通过继承、重载或者委托等手段实现。以接口为例,它对修改就是是封闭的,而对具体的实现是开放的,我们可以根据实际的需要提供不同的实现,所以接口是符合开闭原则的。
2.3 开闭原则能够带来什么好处
如果一个软件系统符合开闭原则的,那么从软件工程的角度来看,它至少具有这样的好处:
可复用性好。
我们可以在软件完成以后,仍然可以对软件进行扩展,加入新的功能,非常灵活。因此,这个软件系统就可以通过不断地增加新的组件,来满足不断变化的需求。
可维护性好。
由于对于已有的软件系统的组件,特别是它的抽象底层不去修改,因此,我们不用担心软件系统中原有组件的稳定性,这就使变化中的软件系统有一定的稳定性和延续性。
2.4 开闭原则与其它原则的关系
开闭原则具有理想主义的色彩,它是面向对象设计的终极目标。因此,针对开闭原则的实现方法,一直都有面向对象设计的大师费尽心机,研究开闭原则的实现方式。后面要提到的里氏代换原则(LSP)、依赖倒转原则(DIP)、接口隔离原则(ISP)以及抽象类(Abstract Class)、接口(Interace)等等,都可以看作是开闭原则的实现方法。
架构师之路(7)---里氏代换原则
4 里氏代换原则(Liskov Substitution Principle, LSP)
4.1 什么是里氏代换原则
里氏代换原则是由麻省理工学院(MIT)计算机科学实验室的Liskov女士,在1987年的OOPSLA大会上发表的一篇文章《Data Abstraction and Hierarchy》里面提出来的,主要阐述了有关继承的一些原则,也就是什么时候应该使用继承,什么时候不应该使用继承,以及其中的蕴涵的原理。2002年,我们前面单一职责原则中提到的软件工程大师Robert C. Martin,出版了一本《Agile Software Development Principles Patterns and Practices》,在文中他把里氏代换原则最终简化为一句话:“Subtypes must be substitutable for their base types”。也就是,子类必须能够替换成它们的基类。
我们把里氏代换原则解释得更完整一些:在一个软件系统中,子类应该可以替换任何基类能够出现的地方,并且经过替换以后,代码还能正常工作。
4.2 第一个例子:正方形不是长方形
“正方形不是长方形”是一个理解里氏代换原则的最经典的例子。在数学领域里,正方形毫无疑问是长方形,它是一个长宽相等的长方形。所以,我们开发的一个与几何图形相关的软件系统中,让正方形继承自长方形是顺利成章的事情。现在,我们截取该系统的一个代码片段进行分析:
长方形类Rectangle:
class Rectangle {
double length;
double width;
public double getLength() { return length; }
public void setLength(double height) { this.length = length; }
public double getWidth() { return width; }
public void setWidth(double width) { this.width = width; }
}
正方形类Square:
class Square extends Rectangle {
public void setWidth(double width) {
super.setLength(width);
super.setWidth(width);
}
public void setLength(double length) {
super.setLength(length);
super.setWidth(length);
}
}
由于正方形的度和宽度必须相等,所以在方法setLength和setWidth中,对长度和宽度赋值相同。类TestRectangle是我们的软件系统中的一个组件,它有一个resize方法要用到基类Rectangle,resize方法的功能是模拟长方形宽度逐步增长的效果:
测试类TestRectangle:
class TestRectangle {
public void resize(Rectangle objRect) {
while(objRect.getWidth() <= objRect.getLength() ) {
objRect.setWidth( objRect.getWidth () + 1 );
}
}
}
我们运行一下这段代码就会发现,假如我们把一个普通长方形作为参数传入resize方法,就会看到长方形宽度逐渐增长的效果,当宽度大于长度,代码就会停止,这种行为的结果符合我们的预期;假如我们再把一个正方形作为参数传入resize方法后,就会看到正方形的宽度和长度都在不断增长,代码会一直运行下去,直至系统产生溢出错误。所以,普通的长方形是适合这段代码的,正方形不适合。
我们得出结论:在resize方法中,Rectangle类型的参数是不能被Square类型的参数所代替,如果进行了替换就得不到预期结果。因此,Square类和Rectangle类之间的继承关系违反了里氏代换原则,它们之间的继承关系不成立,正方形不是长方形。
4.3 第二个例子:鸵鸟不是鸟
“鸵鸟非鸟”也是一个理解里氏代换原则的经典的例子。“鸵鸟非鸟”的另一个版本是“企鹅非鸟”,这两种说法本质上没有区别,前提条件都是这种鸟不会飞。生物学中对于鸟类的定义:“恒温动物,卵生,全身披有羽毛,身体呈流线形,有角质的喙,眼在头的两侧。前肢退化成翼,后肢有鳞状外皮,有四趾”。所以,从生物学角度来看,鸵鸟肯定是一种鸟。
我们设计一个与鸟有关的系统,鸵鸟类顺理成章地由鸟类派生,鸟类所有的特性和行为都被鸵鸟类继承。大多数的鸟类在人们的印象中都是会飞的,所以,我们给鸟类设计了一个名字为fly的方法,还给出了与飞行相关的一些属性,比如飞行速度(velocity)。
鸟类Bird:
class Bird {
double velocity;
public fly() { //I am flying; };
public setVelocity(double velocity) { this.velocity = velocity; };
public getVelocity() { return this.velocity; };
}
鸵鸟不会飞怎么办?我们就让它扇扇翅膀表示一下吧,在fly方法里什么都不做。至于它的飞行速度,不会飞就只能设定为0了,于是我们就有了鸵鸟类的设计。
鸵鸟类Ostrich:
class Ostrich extends Bird {
public fly() { //I do nothing; };
public setVelocity(double velocity) { this.velocity = 0; };
public getVelocity() { return 0; };
}
好了,所有的类都设计完成,我们把类Bird提供给了其它的代码(消费者)使用。现在,消费者使用Bird类完成这样一个需求:计算鸟飞越黄河所需的时间。
对于Bird类的消费者而言,它只看到了Bird类中有fly和getVelocity两个方法,至于里面的实现细节,它不关心,而且也无需关心,于是给出了实现代码:
测试类TestBird:
class TestBird {
public calcFlyTime(Bird bird) {
try{
double riverWidth = 3000;
System.out.println(riverWidth / bird.getVelocity());
}catch(Exception err){
System.out.println("An error occured!");
}
};
}
如果我们拿一种飞鸟来测试这段代码,没有问题,结果正确,符合我们的预期,系统输出了飞鸟飞越黄河的所需要的时间;如果我们再拿鸵鸟来测试这段代码,结果代码发生了系统除零的异常,明显不符合我们的预期。
对于TestBird类而言,它只是Bird类的一个消费者,它在使用Bird类的时候,只需要根据Bird类提供的方法进行相应的使用,根本不会关心鸵鸟会不会飞这样的问题,而且也无须知道。它就是要按照“所需时间 = 黄河的宽度 / 鸟的飞行速度”的规则来计算鸟飞越黄河所需要的时间。
我们得出结论:在calcFlyTime方法中,Bird类型的参数是不能被Ostrich类型的参数所代替,如果进行了替换就得不到预期结果。因此,Ostrich类和Bird类之间的继承关系违反了里氏代换原则,它们之间的继承关系不成立,鸵鸟不是鸟。
4.4 鸵鸟到底是不是鸟?
“鸵鸟到底是不是鸟”,鸵鸟是鸟也不是鸟,这个结论似乎就是个悖论。产生这种混乱有两方面的原因:
原因一:对类的继承关系的定义没有搞清楚。
面向对象的设计关注的是对象的行为,它是使用“行为”来对对象进行分类的,只有行为一致的对象才能抽象出一个类来。我经常说类的继承关系就是一种“Is-A”关系,实际上指的是行为上的“Is-A”关系,可以把它描述为“Act-As”。关于类的继承的细节,我们可以单独再讲。
我们再来看“正方形不是长方形”这个例子,正方形在设置长度和宽度这两个行为上,与长方形显然是不同的。长方形的行为:设置长方形的长度的时候,它的宽度保持不变,设置宽度的时候,长度保持不变。正方形的行为:设置正方形的长度的时候,宽度随之改变;设置宽度的时候,长度随之改变。所以,如果我们把这种行为加到基类长方形的时候,就导致了正方形无法继承这种行为。我们“强行”把正方形从长方形继承过来,就造成无法达到预期的结果。
“鸵鸟非鸟”基本上也是同样的道理。我们一讲到鸟,就认为它能飞,有的鸟确实能飞,但不是所有的鸟都能飞。问题就是出在这里。如果以“飞”的行为作为衡量“鸟”的标准的话,鸵鸟显然不是鸟;如果按照生物学的划分标准:有翅膀、有羽毛等特性作为衡量“鸟”的标准的话,鸵鸟理所当然就是鸟了。鸵鸟没有“飞”的行为,我们强行给它加上了这个行为,所以在面对“飞越黄河”的需求时,代码就会出现运行期故障。
原因二:设计要依赖于用户要求和具体环境。
继承关系要求子类要具有基类全部的行为。这里的行为是指落在需求范围内的行为。图中鸟类具有4个对外的行为,其中2个行为分别落在A和B系统需求中:
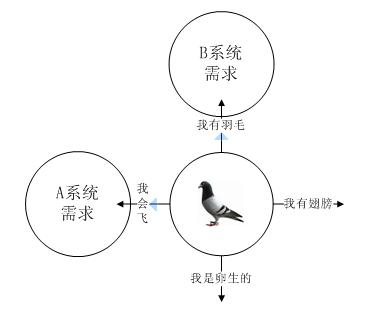
系统需求和对象关系示意图
A需求期望鸟类提供与飞翔有关的行为,即使鸵鸟跟普通的鸟在外观上就是100%的相像,但在A需求范围内,鸵鸟在飞翔这一点上跟其它普通的鸟是不一致的,它没有这个能力,所以,鸵鸟类无法从鸟类派生,鸵鸟不是鸟。
B需求期望鸟类提供与羽毛有关的行为,那么鸵鸟在这一点上跟其它普通的鸟一致的。虽然它不会飞,但是这一点不在B需求范围内,所以,它具备了鸟类全部的行为特征,鸵鸟类就能够从鸟类派生,鸵鸟就是鸟。
所有派生类的行为功能必须和使用者对其基类的期望保持一致,如果派生类达不到这一点,那么必然违反里氏替换原则。在实际的开发过程中,不正确的派生关系是非常有害的。伴随着软件开发规模的扩大,参与的开发人员也越来越多,每个人都在使用别人提供的组件,也会为别人提供组件。最终,所有人的开发的组件经过层层包装和不断组合,被集成为一个完整的系统。每个开发人员在使用别人的组件时,只需知道组件的对外裸露的接口,那就是它全部行为的集合,至于内部到底是怎么实现的,无法知道,也无须知道。所以,对于使用者而言,它只能通过接口实现自己的预期,如果组件接口提供的行为与使用者的预期不符,错误便产生了。里氏代换原则就是在设计时避免出现派生类与基类不一致的行为。
4.5 如何正确地运用里氏代换原则
里氏代换原则目的就是要保证继承关系的正确性。我们在实际的项目中,是不是对于每一个继承关系都得费这么大劲去斟酌?不需要,大多数情况下按照“Is-A”去设计继承关系是没有问题的,只有极少的情况下,需要你仔细处理一下,这类情况对于有点开发经验的人,一般都会觉察到,是有规律可循的。最典型的就是使用者的代码中必须包含依据子类类型执行相应的动作的代码:
动物类Animal:
public class Animal{
String name;
public Animal(String name) {
this.name = name;
}
public void printName(){
try{
System.out.println("I am a " + name + "!");
}catch(Exception err){
System.out.println("An error occured!");
}
}
}
猫类Cat:
public class Cat extends Animal{
public Cat(String name){
super(name);
}
public void Mew(){
try{
System.out.println("Mew~~~ ");
}catch(Exception err){
System.out.println("An error occured!");
}
}
}
狗类Dog:
public class Dog extends Animal {
public Dog(String name) {
super(name);
}
public void Bark(){
try{
System.out.println("Bark~~~ ");
}catch(Exception err){
System.out.println("An error occured!");
}
}
}
测试类:TestAnimal
public class TestAnimal {
public void TestLSP(Animal animal){
if (animal instanceof Cat ){
Cat cat = (Cat)animal;
cat.printName();
cat.Mew();
}
if (animal instanceof Dog ){
Dog dog = (Dog)animal;
dog.printName();
dog.Bark();
}
}
}
象这种代码是明显不符合里氏代换原则的,它给使用者使用造成很大的麻烦,甚至无法使用,对于以后的维护和扩展带来巨大的隐患。实现开闭原则的关键步骤是抽象化,基类与子类之间的继承关系就是一种抽象化的体现。因此,里氏代换原则是实现抽象化的一种规范。违反里氏代换原则意味着违反了开闭原则,反之未必。里氏代换原则是使代码符合开闭原则的一个重要保证。
我们常见这样的代码,至少我以前的Java和php项目中就出现过。比如有一个网页,要实现对于客户资料的查看、增加、修改、删除功能,一般Server端对应的处理类中都有这么一段:
if(action.Equals(“add”)){
//do add action
}
else if(action.Equals(“view”)){
//do view action
}
else if(action.Equals(“delete”)){
//do delete action
}
else if(action.Equals(“modify”)){
//do modify action
}
大家都很熟悉吧,其实这是违背里氏代换原则的,结果就是可维护性和可扩展性会变差。有人说:我这么用,效果好像不错,干嘛讲究那么多呢,实现需求是第一位的。另外,这种写法看起来很很直观的,有利于维护。其实,每个人所处的环境不同,对具体问题的理解不同,难免局限在自己的领域内思考问题。对于这个说法,我觉得应该这么解释:作为一个设计原则,是人们经过很多的项目实践,最终提炼出来的指导性的内容。如果对于你的项目来讲,显著增加了工作量和复杂度,那我觉得适度的违反并不为过。做任何事情都是个度的问题,过犹不及都不好。在大中型的项目中,是一定要讲究软件工程的思想,讲究规范和流程的,否则人员协作和后期维护将会是非常困难的。对于小型的项目可能相应的要简化很多,可能取决于时间、资源、商业等各种因素,但是多从软件工程的角度去思考问题,对于系统的健壮性、可维护性等性能指标的提高是非常有益的。像生命周期只有一个月的系统,你还去考虑一大堆原则,除非脑袋被驴踢了。
实现开闭原则的关键步骤是抽象化,基类与子类之间的继承关系就是一种抽象化的体现。因此,里氏代换原则是实现抽象化的一种规范。违反里氏代换原则意味着违反了开闭原则,反之未必。里氏代换原则是使代码符合开闭原则的一个重要保证。
通过里氏代换原则给我们带来了什么样的启示?
类的继承原则:如果一个继承类的对象可能会在基类出现的地方出现运行错误,则该子类不应该从该基类继承,或者说,应该重新设计它们之间的关系。
动作正确性保证:符合里氏代换原则的类扩展不会给已有的系统引入新的错误。
架构师之路(8)---IoC框架
1 IoC理论的背景
我们都知道在面向对象的应用中,软件系统都是由N个对象组成的,它们通过彼此的合作,最终实现业务逻辑。
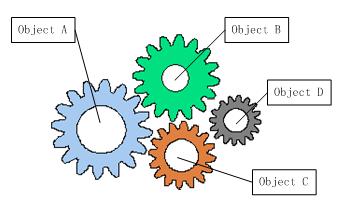
图1:耦合在一起的对象
如果我们打开机械式手表的后盖,就会看到与上面类似的情形,各个齿轮分别带动时针、分针和秒针顺时针旋转,从而在表盘上产生正确的时间。上图画的就是这样的一个齿轮组,它拥有多个独立的齿轮,这些齿轮相互啮合在一起,协同工作,来共同完成某项任务。我们可以看到,在齿轮组中,如果有一个齿轮出了问题,就可能会影响到整个齿轮组的运转。
齿轮组中各个齿轮之间的啮合关系,与软件系统中对象与对象之间的耦合关系,非常类似。对象之间的耦合关系是必要的,是协同工作的基础,当然也是无法避免的,否则无法保证系统整体的正常运转。目前,很多工业级的应用越来越庞大,对象之间的依赖关系也越来越复杂,就会出现对象之间的多重依赖性关系,因此,架构师和设计师对系统进行分析和设计将面临很大的挑战。对象之间耦合度过高的系统,必然会出现牵一发而动全身的情形。
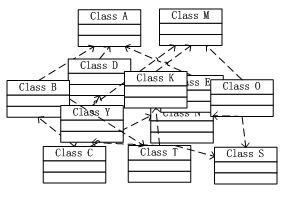
图2:对象之间复杂的依赖关系
耦合关系不仅会出现在对象与对象之间,也会出现在软件系统的各模块之间,以及软件系统和硬件系统之间。如何降低系统之间、模块之间和对象之间的耦合度,是软件工程永远追求的目标之一。
所以有人就提出来IOC理论,用来实现对象之间的“解耦”,目前已被广泛应用于很多项目中。
2 什么是控制反转(IoC)
IoC是Inversion of Control的缩写,多数书籍翻译成“控制反转”,还有些书籍翻译成为“控制反向”或者“控制倒置”,这些都大同小异,我个人觉得这个翻译有待商榷,容易引起歧义,是不是翻译为 “控制转移”会更好一些。
1996年,Michael Mattson在一篇有关探讨面向对象框架的文章中,首先提出了IoC这个概念。对于面向对象设计及编程的基本思想,前面我们已经讲了很多了,不再赘述,读者可以参考我前面的文章,简单来说就是把复杂系统分解成相互合作的对象,这些对象类的内部实现是透明的,从而降低了解决问题的复杂度,而且可以灵活地被重用和扩展。IoC理论提出的观点大体是这样的:借助于“第三方”实现具有依赖关系的对象之间的解耦,如下图:
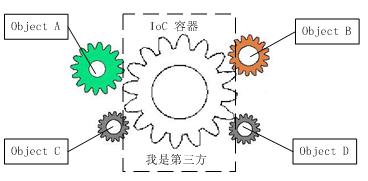
图3:IoC解耦示意图
大家看到了吧,由于引进了中间的“第三方”,也就是IoC容器,使得A、B、C、D这4个对象没有了耦合关系,齿轮之间的传动全部依靠“第三方”了,所有对象的控制权全部上缴给“第三方”,这就是“控制反转”说法的由来,意思就是各个对象的控制权都被转移给“第三方”了。
从另一个角度来看,作为“第三方”的IoC容器成了整个系统的关键核心,它起到了一种类似“粘合剂”的作用,把系统中的所有对象粘合在一起发挥作用,如果没有这个“粘合剂”,对象与对象之间会彼此失去联系,这就是所谓的Ioc容器被称为“粘合剂”的原因。
我们再把上图中间的Ioc容器拿掉后,整个系统变为这样的情形:
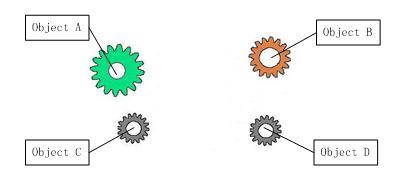
图4:拿掉IoC容器后的系统
拿掉IoC容器后,我们看到的就是系统开发所需要完成的全部内容,这时候,A、B、C、D这4个对象之间已经没有了耦合关系,彼此毫不影响,所以当你在实现ClassA的时候,根本不用再考虑B、C和D了,系统对象之间的依赖已经降低到了最低程度。至于IoC容器,你可以到开源组织的网站上找一找,里面有很多比较成熟而且Free的,使用起来非常简便。
如果真能实现控制反转,对于系统开发而言,这将是一件多么美好的事情!
3 什么是依赖注入(DI)
我们先看一些生活中的例子,帮助你理解依赖注入(DI):
3.1 主机和内置硬盘
我们平时所用的电脑,它的硬盘安装在主机里面,从电脑的外部,我们是看不见硬盘的。所以,我们通常认为,电脑的所有部件是融为一体的。

图5:主机和内置硬盘
对于一体机而言,一旦出现了问题,我们可能无法准确地判断到底是什么零部件出现了问题,有可能是CPU坏了,也有可能是主板烧了,还有可能是内存松动了。还有的时候,比如,电脑硬盘出现了问题,可能导致整台电脑都无法使用。从这个例子,我们可以看到部件之间“紧密耦合”的产生的问题:无法准确的定位和诊断故障所在。这种情形,在软件工程的理论中,称之为可理解性和可测试性差。
如果你想修理电脑的硬盘,那么在修理过程中就必须小心翼翼,不要把其它的部件再搞坏了,比如不慎把内存给碰松动了,硬盘固然是修好了,但整台电脑仍然无法使用。这种情形,在软件工程的理论中,称之为可修改性差。
可理解性、可测试性、可修改性组成了系统的可维护性,一体机的可维护性就表现得比较差。
3.2 主机和USB设备
大家对USB接口和设备应该都很熟悉。自从有了USB接口,给我们使用电脑带来了很大的方便,现在有很多的外部设备都支持USB接口。

图6:主机和USB设备
从软件工程角度,我们分析一下USB带来的好处:
1、USB设备作为主机的外部设备,在插入主机之前,与主机没有任何的关系,两者都可独立进行测试,无论两者中的任何一方出现什么的问题,都不会影响另一方的运行,所以可维护性比较好。
2、同一个USB设备可以插接到不同的支持USB的任何主机,也就是USB设备可以被重复利用,所以可复用性比较好。
3、支持热插拔,只要是支持USB接口的设备都可以接入,所以可扩展性比较好,非常灵活。
3.3 依赖注入
2004年,MartinFowler从另一个角度来思考这个问题,提出了“哪些方面的控制被反转了?”这样一个问题,并给出了答案:“依赖对象的获得被反转”。于是,他给“控制反转”取了一个他认为更合适的名字叫做“依赖注入(DependencyInjection)”。他的这个答案,实际上点明了实现IoC理论的解决方法。所谓依赖注入,就是由IoC容器在运行期间,动态地将某种依赖关系注入到对象之中。
依赖注入(DI)和控制反转(IoC)是从不同的角度的描述的同一件事情,都是指通过引入第三方,即IoC容器,实现软件系统中对象之间的解耦。
控制反转能够带给系统开发的好处,与USB机制带来的好处基本类似,而且依赖注入的实现跟USB机制也完全一样。USB机制是现实中依赖注入的很好的案例。我们用一个实际的例子,分析一下USB机制:
任务:主机通过USB接口读取一个文件。
思路:首先,必须制定一个USB接口标准,主机对USB设备的访问严格按照USB接口标准,USB设备提供的功能也必须符合USB接口标准。
当主机需要获取一个文件的时候,它直接去读取USB接口,根本不会关心USB接口上连接的是什么设备。
如果我给主机连接上一个U盘,那么主机就从U盘上读取文件;如果我给主机连接上一个外接硬盘,那么主机就从外接硬盘上读取文件。选取何种外部设备的权力由我说了算,也就是控制权归我。
至此,依赖注入的思路已经非常清楚:当主机需要读取文件的时候,我就把它所要依赖的外部设备,挑出来一个,帮他挂接上。这个过程就是一个被依赖的对象在系统运行时被注入另外一个对象内部的过程。在这个过程中,我就起到了IoC容器的作用。
我们再把依赖注入应用到软件工程中:
ClassA依赖于Class B,当Class A需要用到Class B的时候,IoC容器就会立刻创建一个Class B送给ClassA使用。IoC容器就是一个类制造工厂,你需要什么,直接来拿,直接用就可以了,而不需要去关心你所用的东西是如何制成的,也不用关心最后是怎么被销毁的,这一切全由IoC容器包办。
4 实现IoC容器
----------------------------------------------------
后记:之所以突然跳跃到39,是因为有的同学基础比较好,已经没有必要阅读有关面向对象、设计模式以及软件工程的基本理论,那么可以从这里开始阅读。基础需要继续补全的同学,可以从4继续看,我会定期在两个方向进行更新。框架理论,是架构师知识体系中非常重要的部分,我会逐步结合实例,把常见的一些框架方面的知识与大家共享。




![[JMX一步步来] 9、基于JBoss来写MBean](http://blog.sohu.com/images/person/2005/12/26/1135589435968_2575.jpg)