文章目录
- 1.JVM的位置
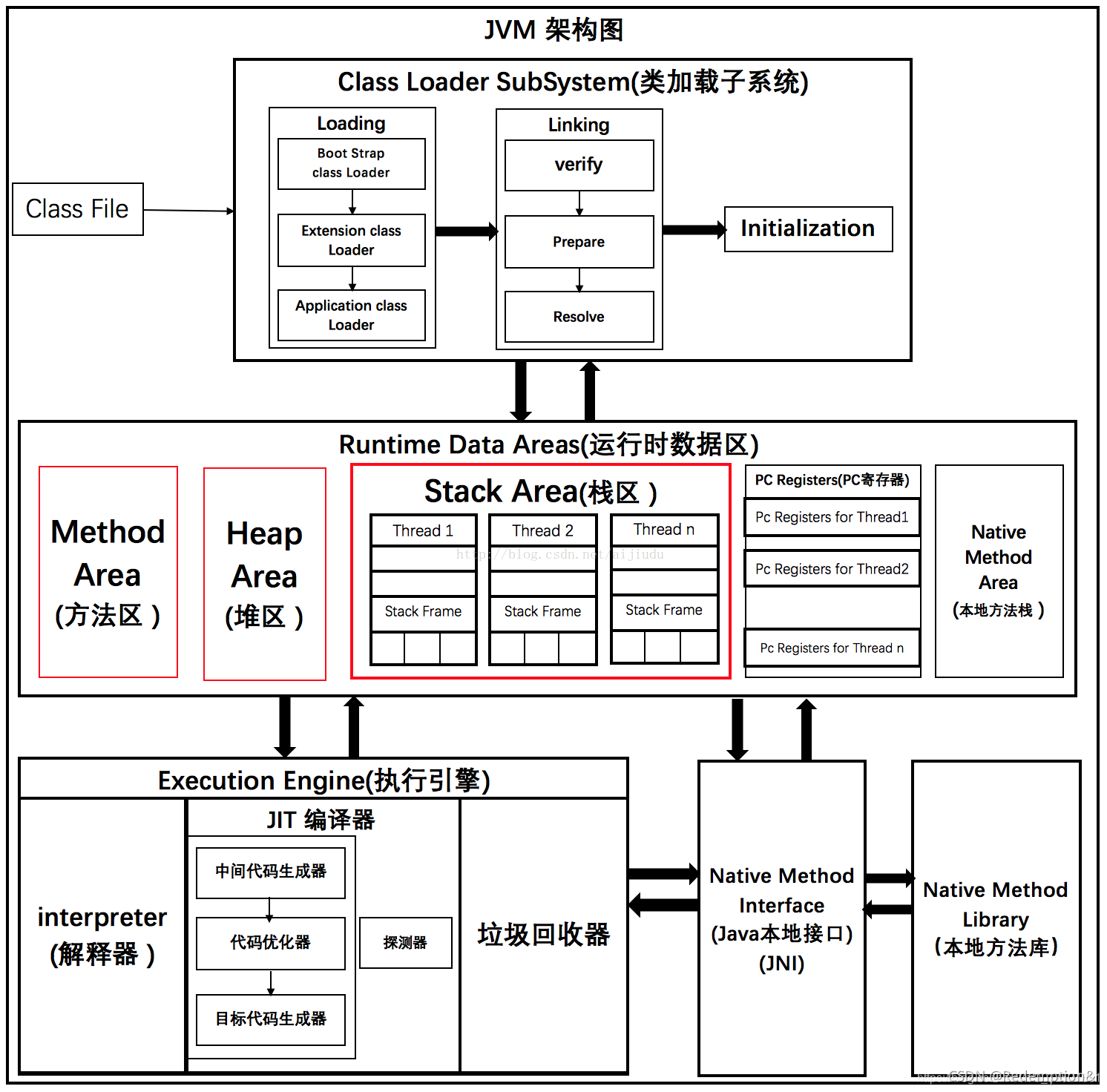
- 2.JVM的体系结构
- 3.类加载器
- 4.双亲委派机制(重要)
- 5.沙箱安全机制(了解)
- 6.native(核心)
- 7.PC寄存器(了解)
- 8.方法区
- 9.栈
- 10.三种JVM
- 11.堆(Heap)
- 12.新生区、老年区
- 13.永久区
- 14.堆内存调优
- 15.GC以及常用算法
- 引用计数法:
- 复制算法:
- 标记清除算法:
- 标记压缩算法:
- 16.JMM
- 1、什么是JMM?
- 2、它干嘛的?
- 3、它该如何学习?
- 17.总结
常见的面试题:
- 请谈一谈你对JVM的理解?Java8虚拟机和之前的变化?
- 什么是OOM,什么是栈溢出?
- JVM的常用调优参数有哪些
- 内存快照如何抓取,怎么分析Dump文件?
- 谈谈JVM中你认识的类加载器
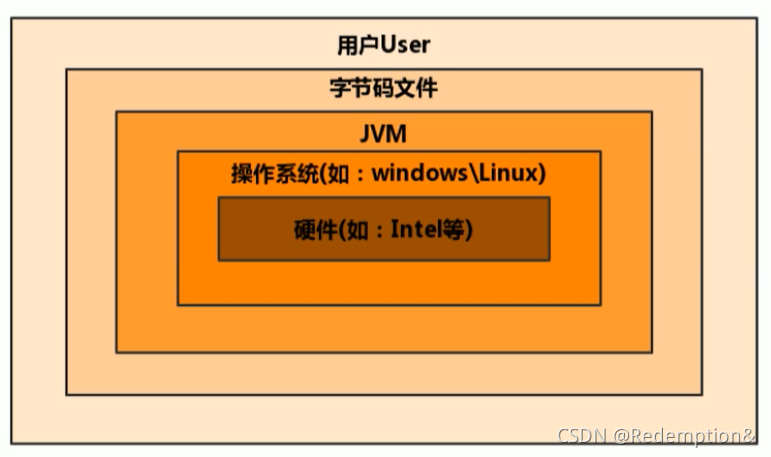
1.JVM的位置
类加载子系统:加载、链接、初始化
第三方插件:执行引擎处
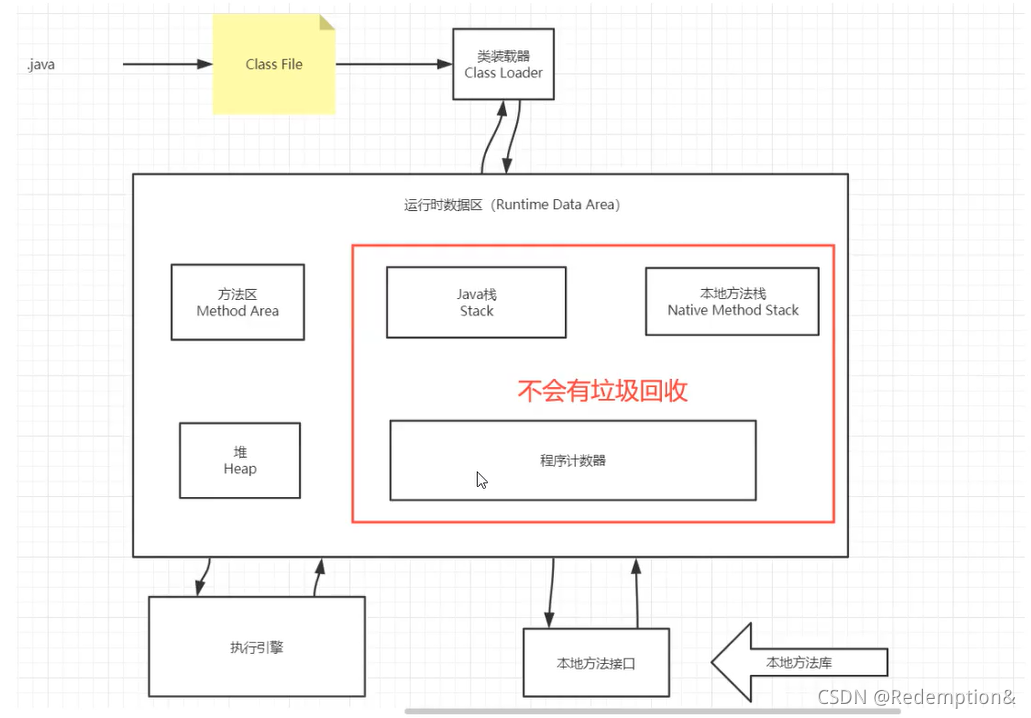
Class File–javac
2.JVM的体系结构
Java栈、本地方法栈、程序计数器不会有垃圾回收,否则程序会死掉
百分之99的JVM调优都是在方法区和堆(99%是堆)中调优,Java栈、本地方法栈、程序计数器是不会有垃圾存在的。
3.类加载器
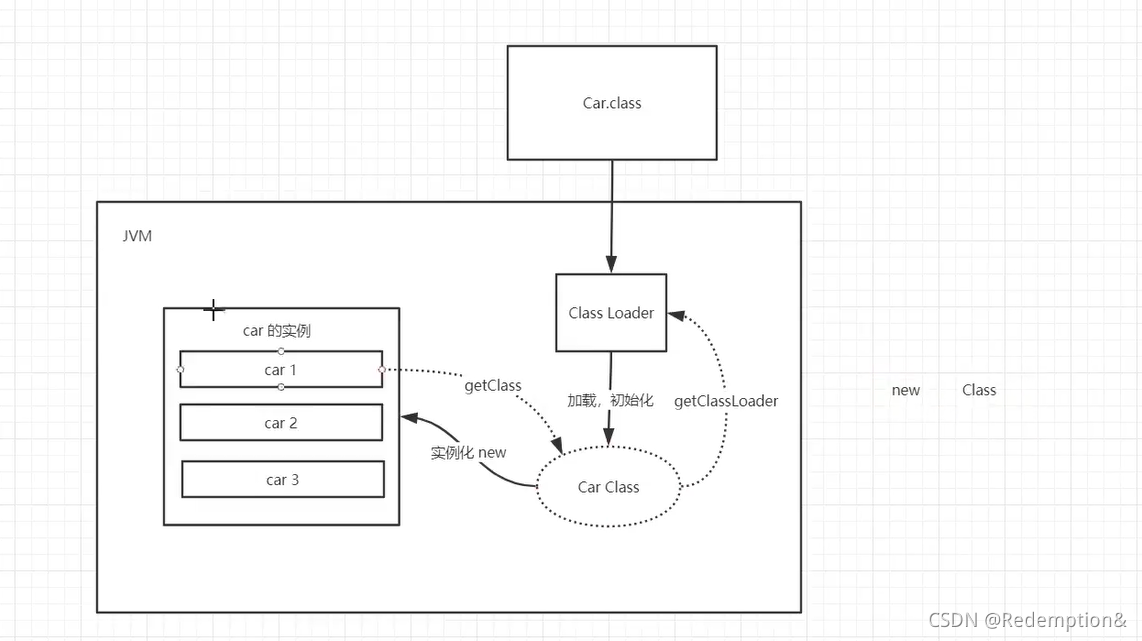
作用:加载class文件 new Student();
(有一个student的类,这个类是抽象的,当使用new关键词new完后变成具体的实例,具体的实例在Java在栈中引用,具体的人实例放在堆中,要去堆中进行真正的数据引用)
类是模板,是抽象的,类实例化得到的对象是具体的。所有的对象反射回去得到的是同一个类模板。
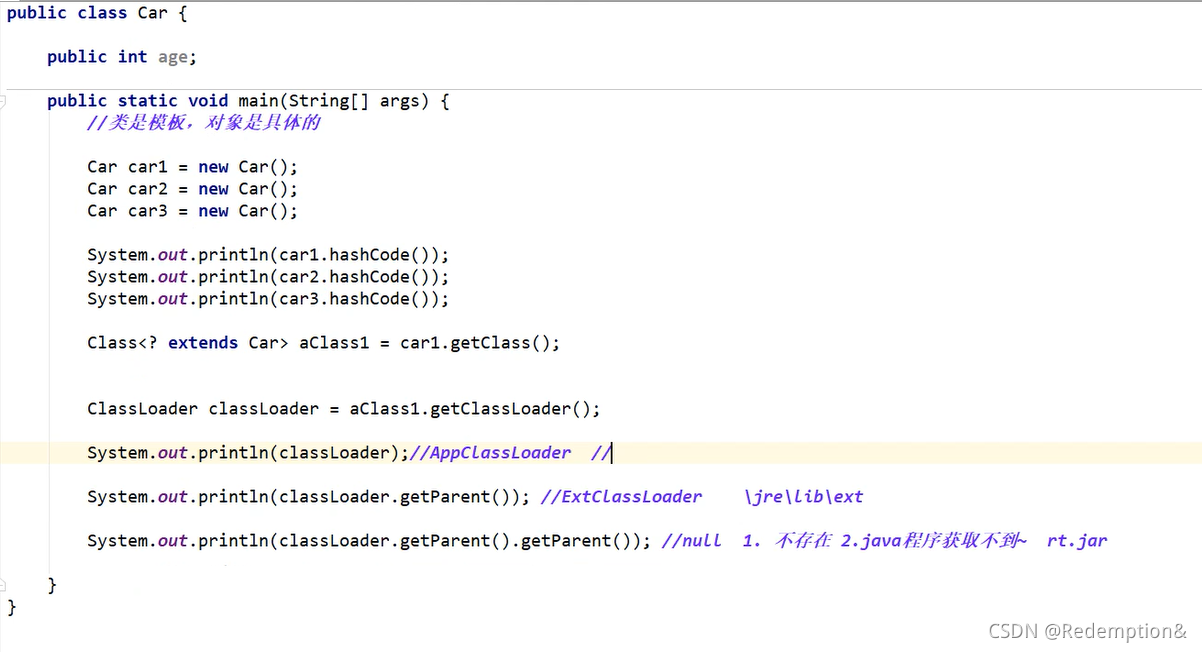
- 虚拟机自带的加载器
- 启动类(根)加载器 BootstrapClassLoader(rt.jar):主要负责加载核心的类库(java.lang.*等),构造ExtClassLoader和APPClassLoader。
- 扩展类加载器 ExtClassLoader(\jre\lib\ext):主要负责加载jre/lib/ext目录下的一些扩展的jar。
- 应用程序加载器 AppClassLoader(当前应用程序加载器):主要负责加载应用程序的主函数类
- 百度:双亲委派机制
4.双亲委派机制(重要)

工作原理:
(1)如果一个类加载器收到了类加载请求,它并不会自己先加载,而是把这个请求委托给父类的加载器去执行
(2)如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的引导类加载器;
(3)如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成加载任务,子加载器才会尝试自己去加载,这就是双亲委派机制
(4)父类加载器一层一层往下分配任务,如果子类加载器能加载,则加载此类,如果将加载任务分配至系统类加载器也无法加载此类,则抛出异常
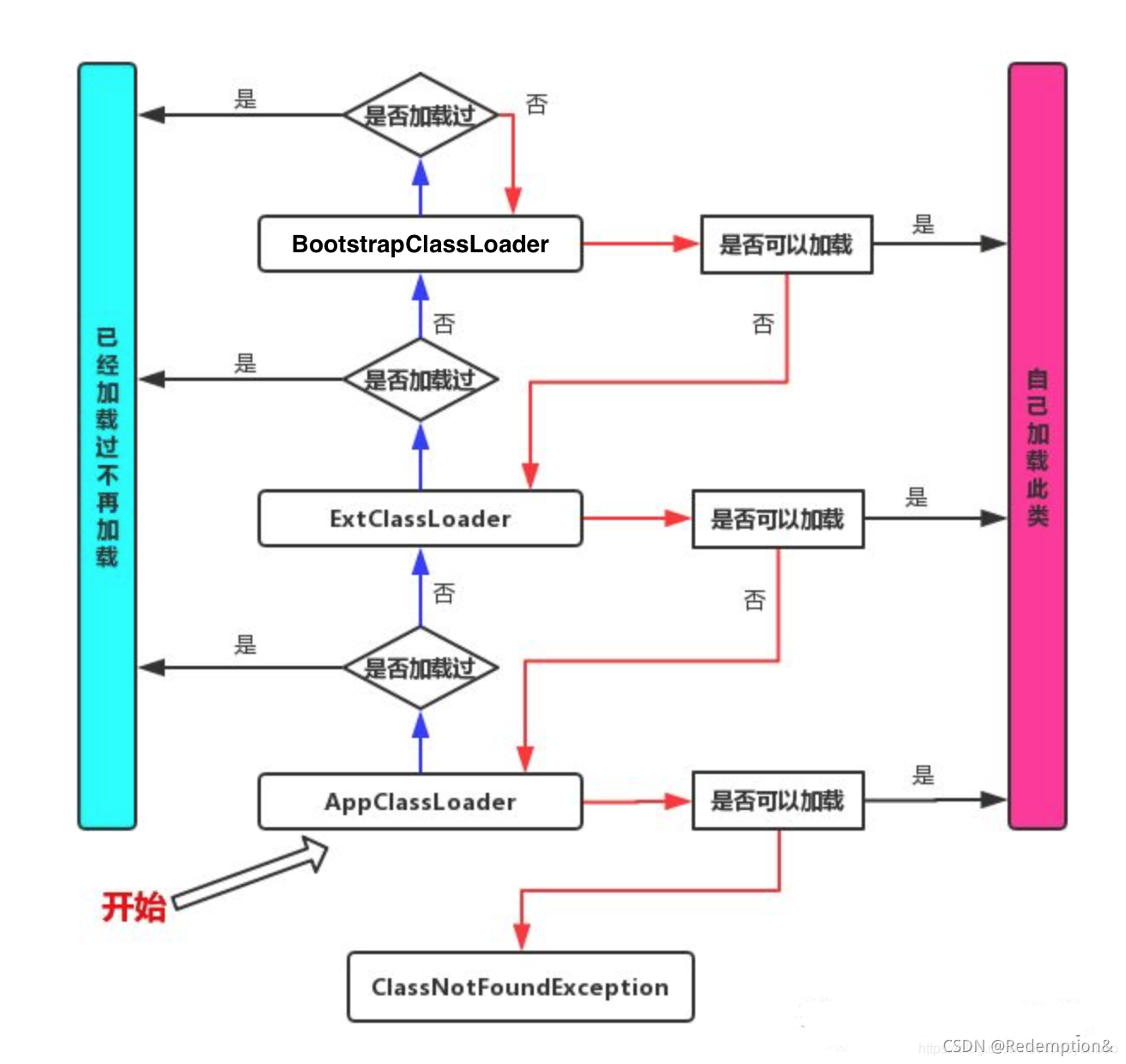
当一个Hello.class这样的文件要被加载时。不考虑我们自定义类加载器,
首先会在AppClassLoader中检查是否加载过,如果有那就无需再加载了。
如果没有,那么会拿到父加载器,然后调用父加载器的loadClass方法。
父类中同理也会先检查自己是否已经加载过,如果没有再往上。
注意这个类似递归的过程,直到到达Bootstrap classLoader之前,都是在检查是否加载过,并不会选择自己去加载。直到BootstrapClassLoader,已经没有父加载器了,这时候开始考虑自己是否能加载了,如果自己无法加载,会下沉到子加载器去加载,一直到最底层,如果没有任何加载器能加载,就会抛出ClassNotFoundException。那么有人就有下面这种疑问了?
为什么要设计这种机制?
这种设计有个好处是,如果有人想替换系统级别的类:String.java。篡改它的实现,在这种机制下这些系统的类已经被Bootstrap classLoader加载过了(为什么?因为当一个类需要加载的时候,最先去尝试加载的就是BootstrapClassLoader),所以其他类加载器并没有机会再去加载,从一定程度上防止了危险代码的植入。
举例一、
我自己建立一个 java.lang.String 类,写上 static 代码块
package java.lang;public class String {static{System.out.println("我是自定义的String类的静态代码块");}
}
在另外的程序中加载 String 类,看看加载的 String 类是 JDK 自带的 String 类,还是我们自己编写的 String 类
public class StringTest {public static void main(String[] args) {java.lang.String str = new java.lang.String();System.out.println("hello,atguigu.com");StringTest test = new StringTest();System.out.println(test.getClass().getClassLoader());}
}
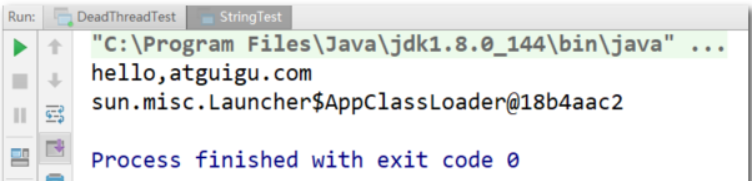
为什么呢?
由于我们定义的String类本应用系统类加载器,但它并不会自己先加载,而是把这个请求委托给父类的加载器去执行,到了扩展类加载器发现String类不归自己管,再委托给父类加载器(引导类加载器),这时发现是java.lang包,这事就归引导类加载器管,所以加载的是 JDK 自带的 String 类
举例二、
在我们自己的 String 类中整个 main() 方法
package java.lang;public class String {static{System.out.println("我是自定义的String类的静态代码块");}//错误: 在类 java.lang.String 中找不到 main 方法public static void main(String[] args) {System.out.println("hello,String");}
}
由于双亲委派机制找到的是 JDK 自带的 String 类,但在引导类加载器的核心类库API里的 String 类中并没有 main() 方法
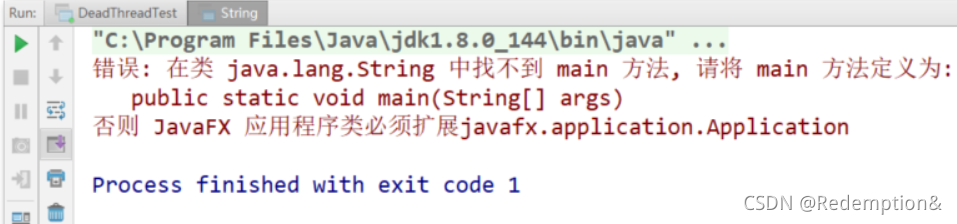
举例三、
举例 3:
在 java.lang 包下整个 ShkStart 类 (自定义类名)
package java.lang;public class ShkStart {public static void main(String[] args) {System.out.println("hello!");}
}
出于保护机制,java.lang 包下不允许我们自定义类
双亲委派机制优势
通过上面的例子,我们可以知道,双亲机制可以
- 避免类的重复加载
- 保护程序安全,防止核心API被随意篡改
- 自定义类:java.lang.String (没用)
- 自定义类:java.lang.ShkStart(报错:阻止创建 java.lang开头的类)
- Class Not Found异常就是这么来的
- Null:Java调用不到。(底层是C、C++写的)Java早期的名字:C+±- Java = C+±-:去掉繁琐的东西,指针,内存管理~
- Java语言保留了C的接口,这些方法就是用native(本地)修饰的,java通过native方法调用操作系统的方法
5.沙箱安全机制(了解)
Java安全模型的核心就是Java沙箱(sanddiox),什么是沙箱?沙箱是一个限制程序运行的环境。沙箱机制就是将Java代码限定在虚拟机 (JVM) 特定的运行范围中,并且严格限制代码对本地系统资源访问,通过这样的措施来保证对代码的有效隔离,防止对本地系统造成破坏。沙箱主要限制系统资源访问,那系统资源包括什么? CPU、内存、文件系统、网络。不同级别的沙箱对这些资源访问的限制也可以不一样。
所有的Java程序运行都可以指定沙箱,可以定制安全策略。
在Java中将执行程序分成本地代码和远程代码两种,本地代码默认视为可信任的,而远程代码则被看作是不受信的。对于授信的本地代码,可以访问一切本地资源。而对于非授信的远程代码在早期的Java实现中,安全依赖于沙箱(Sandbox)机制。如下图所示JDK1.0安全模型
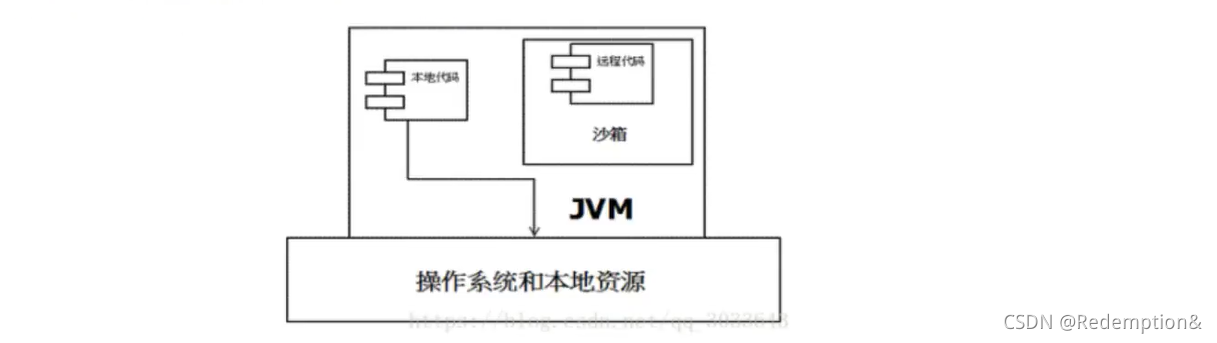
但如此严格的安全机制也给程序的功能扩展带来障碍,比如当用户希望远程代码访问本地系统的文件时候,就无法实现。因此在后续的Java1.1版本中,针对安全机制做了改进,增加了安全策略,允许用户指定代码对本地资源的访问权限。如下图所示JDK1.1安全模型
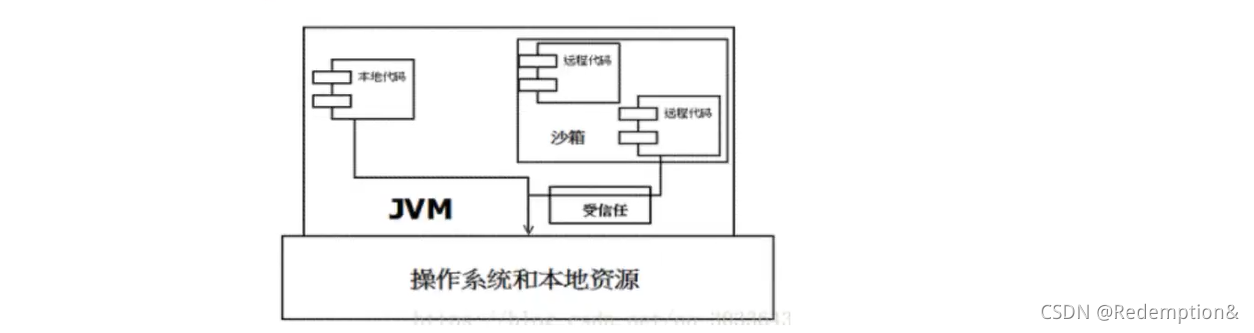
在Java1.2版本中,再次改进了安全机制,增加了代码签名。不论本地代码或是远程代码,都会按照用户的安全策略设定,由类加载器加载到虚拟机中权限不同的运行空间,来实现差异化的代码执行权限控制。如下图所示
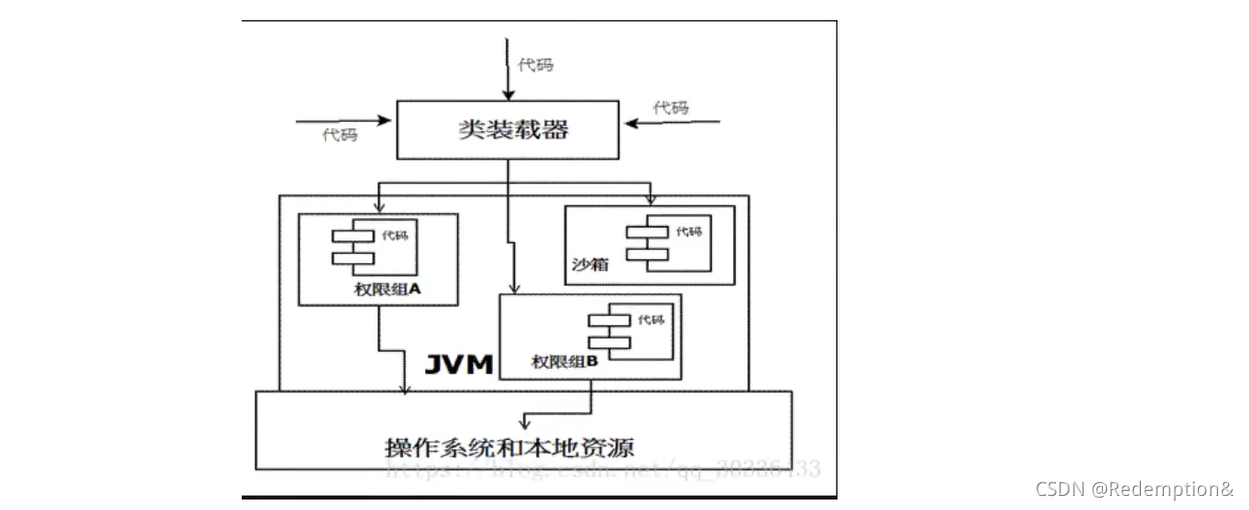
当前最新的安全机制实现,则引入了**域(Domain)**的概念。虚拟机会把所有代码加载到不同的系统域和应用域,系统域部分专门负责与关键资源进行交互,而各个应用域部分则通过系统域的部分代理来对各种需要的资源进行访问。虚拟机中不同的受保护域(Protected Domain),对应不一样的权限(Permission)。存在于不同域中的类文件就具有了当前域的全部权限,如下图所示最新的安全模型(jdk 1.6)
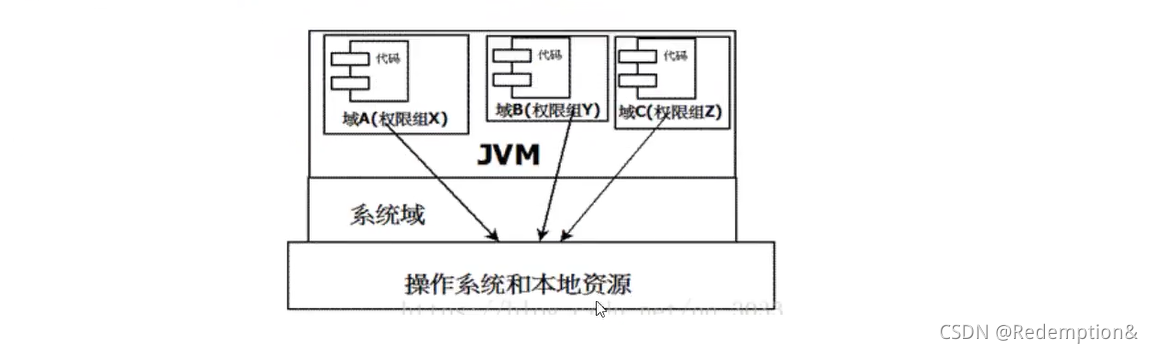
组成沙箱的基本组件
字节码校验器(bytecode verifier):确保Java类文件遵循Java语言规范。这样可以帮助Java程序实现内存保护。但并不是所有的类文件都会经过字节码校验,比如核心类。
类裝载器(class loader) :其中类装载器在3个方面对Java沙箱起作用
它防止恶意代码去干涉善意的代码; //双亲委派机制
它守护了被信任的类库边界;
它将代码归入保护域,确定了代码可以进行哪些操作。
虚拟机为不同的类加载器载入的类提供不同的命名空间,命名空间由一系列唯一的名称组成, 每一个被装载的类将有一个名字,这个命名空间是由Java虚拟机为每一个类装载器维护的,它们互相之间甚至不可见。
类装载器采用的机制是双亲委派模式。
从最内层JVM自带类加载器开始加载,外层恶意同名类得不到加载从而无法使用;
由于严格通过包来区分了访问域,外层恶意的类通过内置代码也无法获得权限访问到内层类,破坏代码就自然无法生效。
●存取控制器(access controller) :存取控制器可以控制核心API对操作系统的存取权限,而这个控制的策略设定,可以由用户指定。
●安全管理器(security manager) : 是核心API和操作系统之间的主要接口。实现权限控制,比存取控制器优先级高。
●安全软件包(security package) : java.security下的类和扩展包下的类,允许用户为自己的应用增加新的安全特性,包括:
安全提供者
消息摘要
数字签名 keytools https
加密
鉴别
6.native(核心)
native:
凡是带了native关键字的,说明java的作用范围达不到了,会去调用底层c语言的库
会进入本地方法栈
调用本地方法本地接口 JNI (Java Native Interface)
JNI作用:开拓Java的使用,融合不同的编程语言为Java所用,最初: C、C++
Java诞生的时候C、C++横行,想要立足,必须要有调用C、C++的程序
它在内存区域中专门开辟了一块标记区域: Native Method Stack,登记native方法
在最终执行的时候,加载本地方法库中的方法通过JNI
例如:Java程序驱动打印机,管理系统,掌握即可,在企业级应用比较少
private native void start0();
调用其他接口:Socket… WebService … http~
目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理设备,在企业级应用中已经比较少见。因为现在的异构领域间通信很发达,比如可以使用Socket通信,也可以使用Web Service等等,不多做介绍!
Native Method Stack
它的具体做法是Native Method Stack 中登记native方法,在 ( Execution Engine ) 执行引擎执行的时候加载Native Libraies。【本地库】
7.PC寄存器(了解)
程序计数器: Program Counter Register
每个线程都有一个程序计数器,是线程私有的,就是一个指针, 指向方法区中的方法字节码(用来存储指向像一条指令的地址, 也即将要执行的指令代码),在执行引擎读取下一条指令, 是一个非常小的内存空间,几乎可以忽略不计
8.方法区
方法区:Method Area
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法,如构造函数,接口代码也在此定义,简单说,所有定义的方法的信息都保存在该区域,此区域属于共享区间;
静态变量、常量、类信息(构造方法、接口定义)、运行时的常量池存在方法区中,但是实例变量存在堆内存中,和方法区无关
static、final、Class、常量池
9.栈
1、栈:数据结构(栈跟队列比较学习)
程序 = 数据结构+算法︰持续学习~
程序 = 框架+业务逻辑︰吃饭~(被淘汰)(springboot+springcloud)
栈:先进后出、后进先出,类似一个桶()
队列:先进先出( FIFO : First Input First Output )
为什么main()先执行,最后结束~(main()方法先压入栈,再压入其他方法,main()最后弹出)
栈溢出:StackOverflowError
public void test(){a();
}
public void a(){test();
}
栈:也叫栈内存
主管程序的运行,生命周期和线程同步;
线程结束,栈内存也就释放,对于栈来说,==不存在垃圾回收的问题;==一旦线程结束,栈就Over;
栈:栈内存中放8大基本类型+对象引用+实例的方法
栈运行原理:栈帧
栈帧:局部变量表+操作数栈
每执行一个方法,就会产生一个栈帧。程序正在运行的方法永远都会在栈的顶部
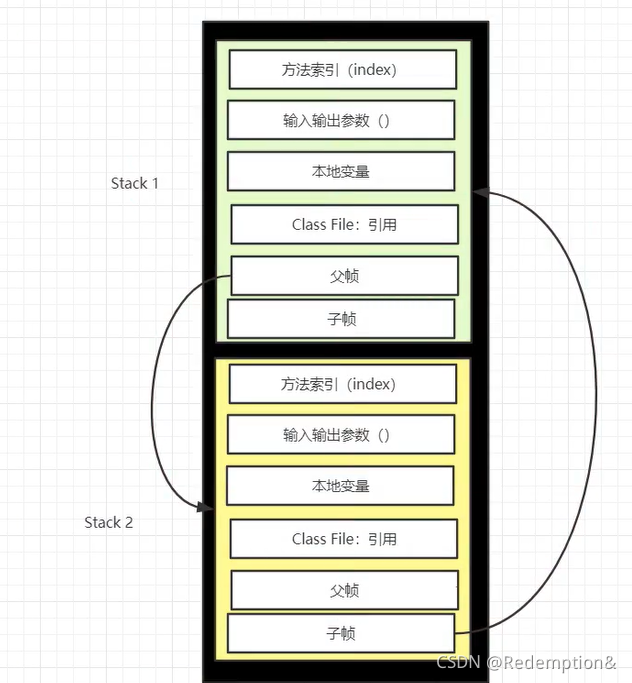
栈+堆+方法区的交互关系:
查的内容:栈具体怎么存
手动画出一个对象实例化的过程在内存中(百度、视频)
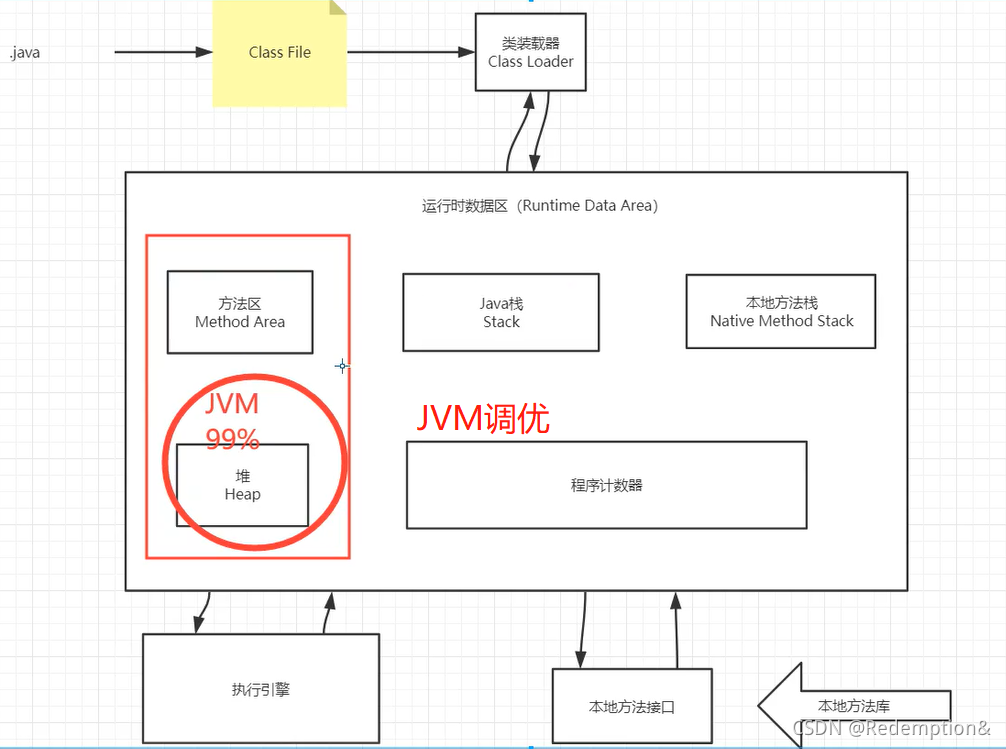
调优是在堆中调优,堆是比较重要的
10.三种JVM
java -version
- Sun: HotSpot (java Hotspot™64-Bit server vw (build 25.181-b13,mixed mode))
- BEA :JRockit
- IBM: j9VM
- 我们学习都是:Hotspot
11.堆(Heap)
一个JVM只有一个堆内存,堆内存的大小是可以调节的。
类加载器读取了类文件后,一般会把什么东西放到堆中?
类,方法,常量,变量~,保存我们所有引用类型的真实对象
堆内存中还要细分为三个区域:
- 新生区(伊甸园区) Young/New
- 养老区 Old
- 永久区 Perm
GC:Garbage recycling
- 轻GC:轻量级垃圾回收,主要是在新生区
- 重GC(Full GC):重量级垃圾回收,主要是养老区,重GC就说明内存都要爆了
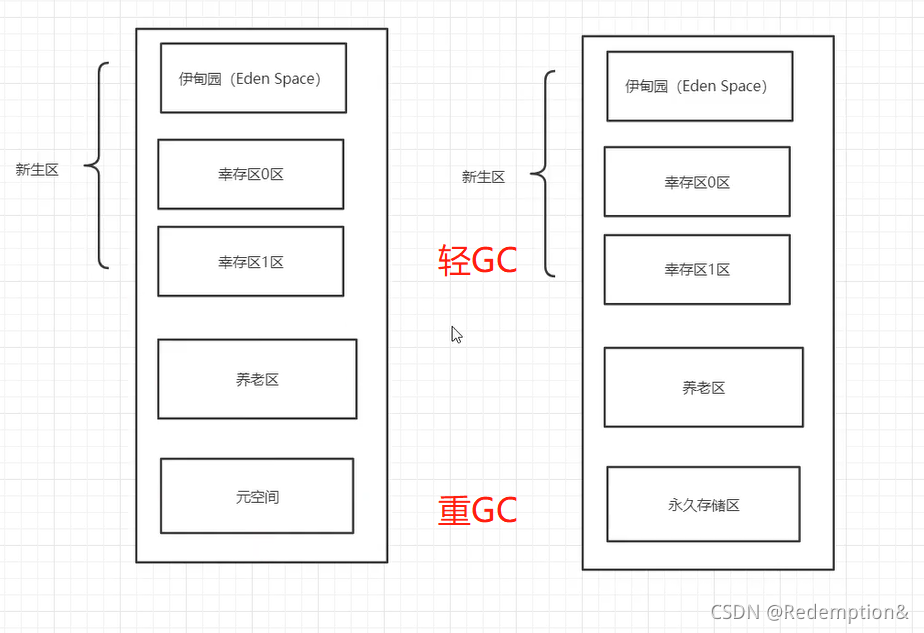
GC垃圾回收,主要是在伊甸园区和养老区~
假设内存满了,OOM(Out Of memory),堆内存不够!
java.lang.OutOfMemoryError: Java heap space
在JDK8以后,永久存储区改了个名字(元空间);
12.新生区、老年区
新生区:
类诞生和成长的地方,甚至死亡
- 伊甸园区:所有的对象都是在伊甸园区new出来的
- 幸存(0区,1区)
真理:经过研究,99%的对象都是临时对象!
13.永久区
这个区域常驻内存的,用来存放jdk自身携带的class对象,interface元数据
存储的是Java运行时的一些环境或类信息
这个区域不存在垃圾回收
关闭虚拟机就会释放这个区域的内存
一个启动类,加载了大量的第三方jar包,、tomcat部署了太多应用,大量动态生成的反射类。不断地被加载直到内存满,就会出现OOM;
- jdk1.6以前:永久代,常量池在方法区
- jdk1.7:永久代,但是慢慢退化了,去永久代,常量池在堆中
- jdk1.8:无永久区,常量池在元空间
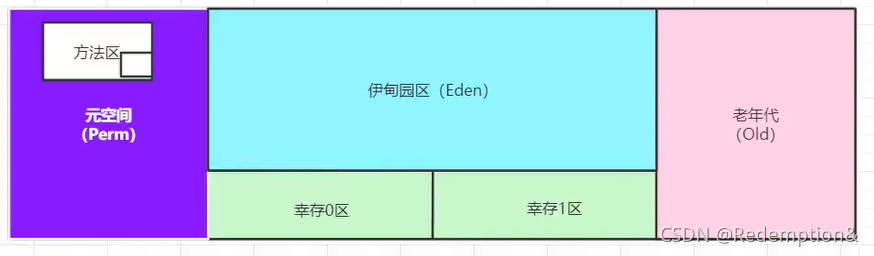
堆:新生区+老年区
元空间:非堆(逻辑上存在,物理上不存在)
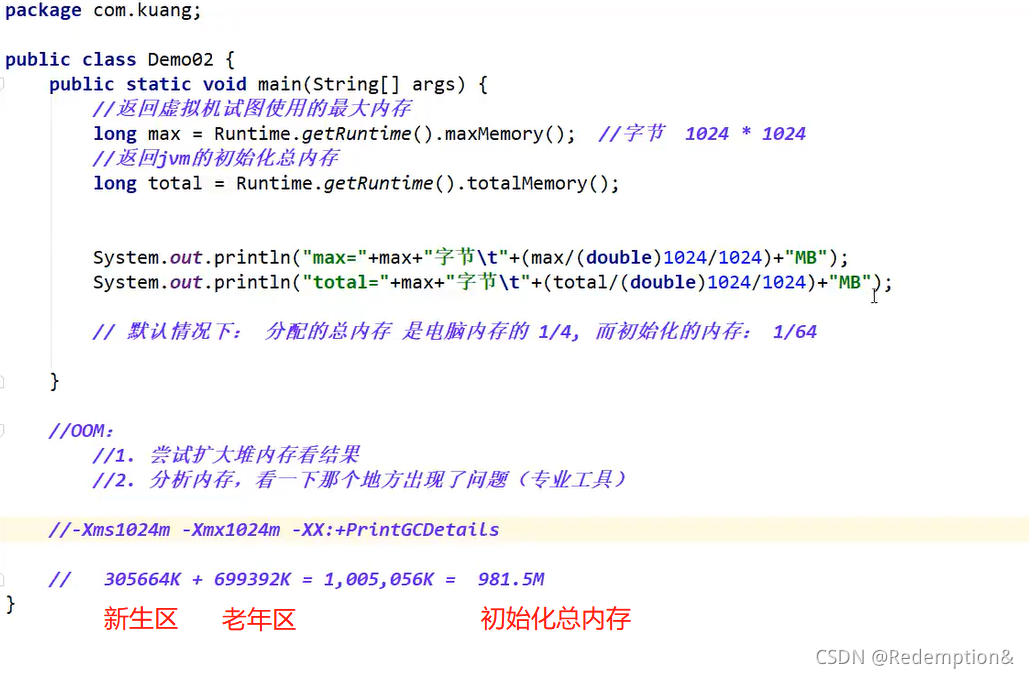
OOM:
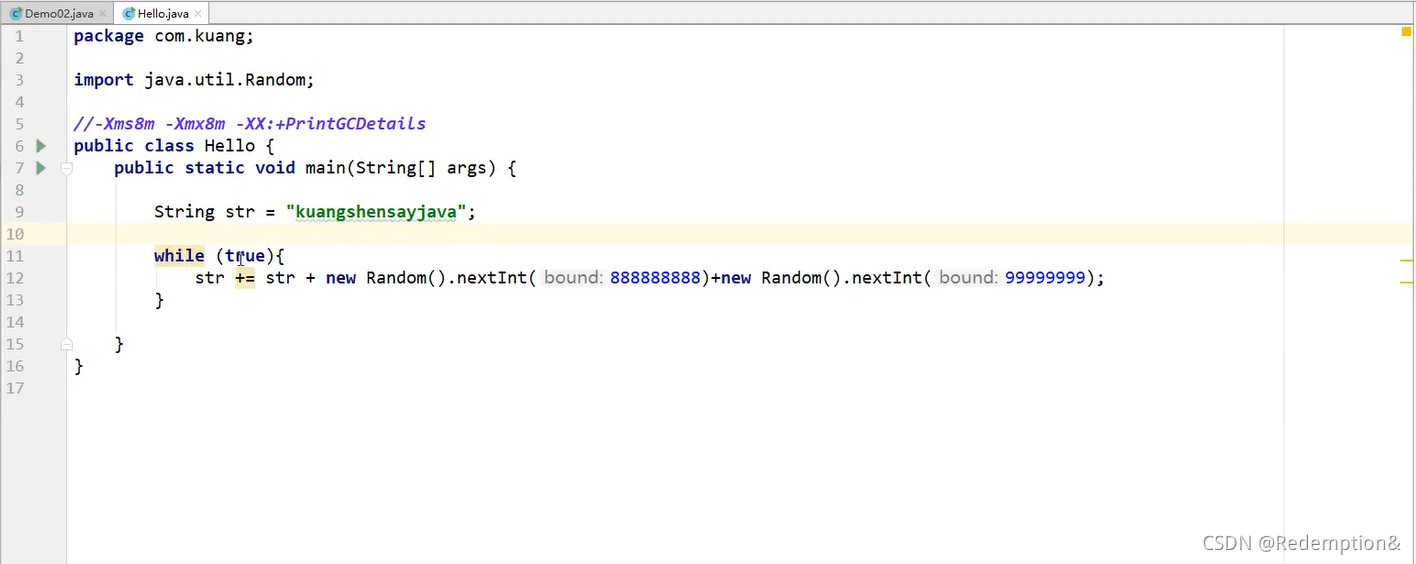
在一个项目中突然出现了OOM故障,那么如何排除,研究为什么错
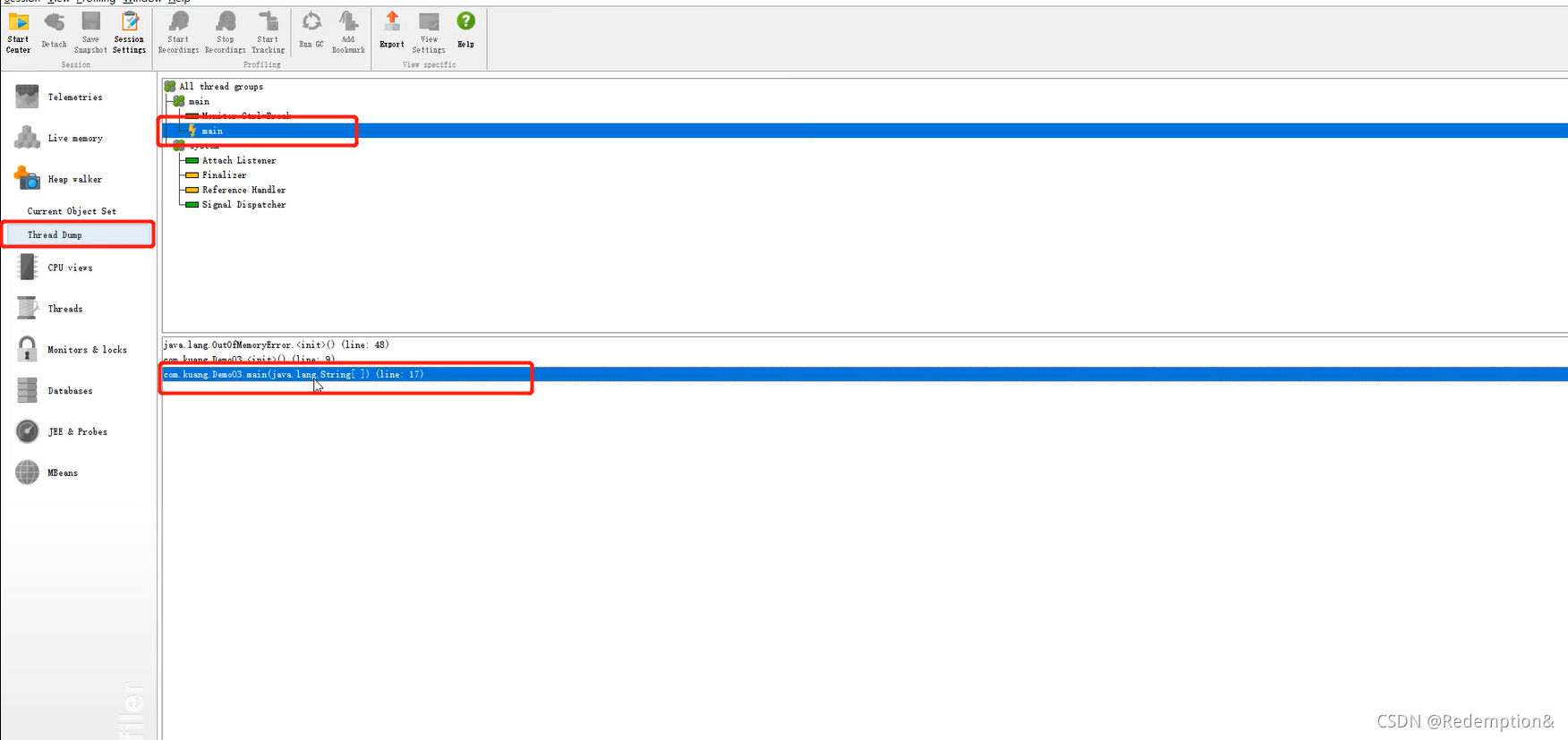
- 能够看到代码第几行出错:内存快照分析工具
- Debug:一行行分析代码
MAT、Jprofiler的作用:
- 分析Dump内存文件,快速定位内存泄漏;
- 获得堆中的数据
- 获得大的对象
14.堆内存调优
Settings–Plugins–JProfiler
JProfiler客户端官网下载
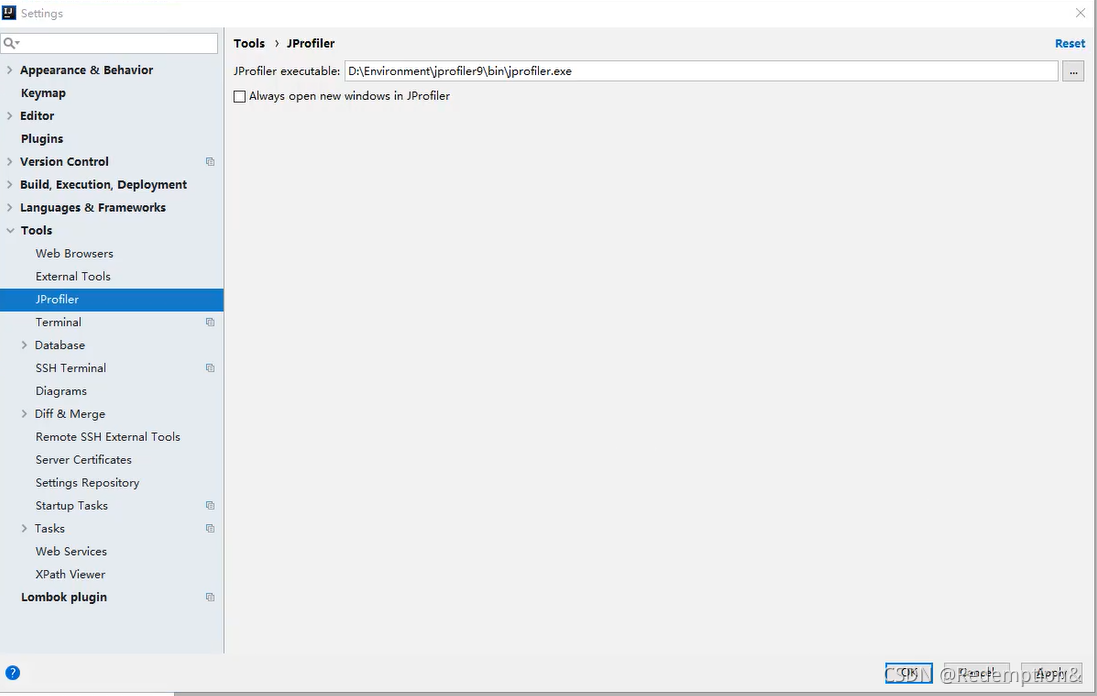
-Xm:设置初始化内存分配大小,默认1/64
-Xmx:设置最大分配内存,默认 1/4
-XX:+PrintGCDetails (打印GC垃圾回收信息)
-XX:+HeapDumpOutOfMenoryError(oom Dump)
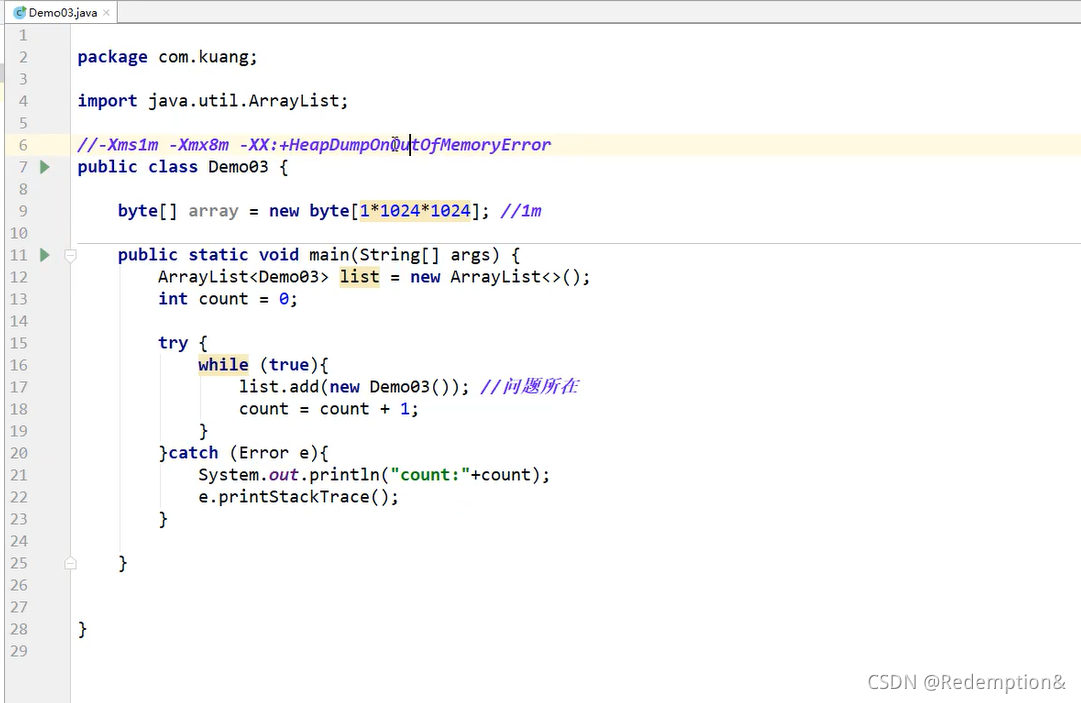
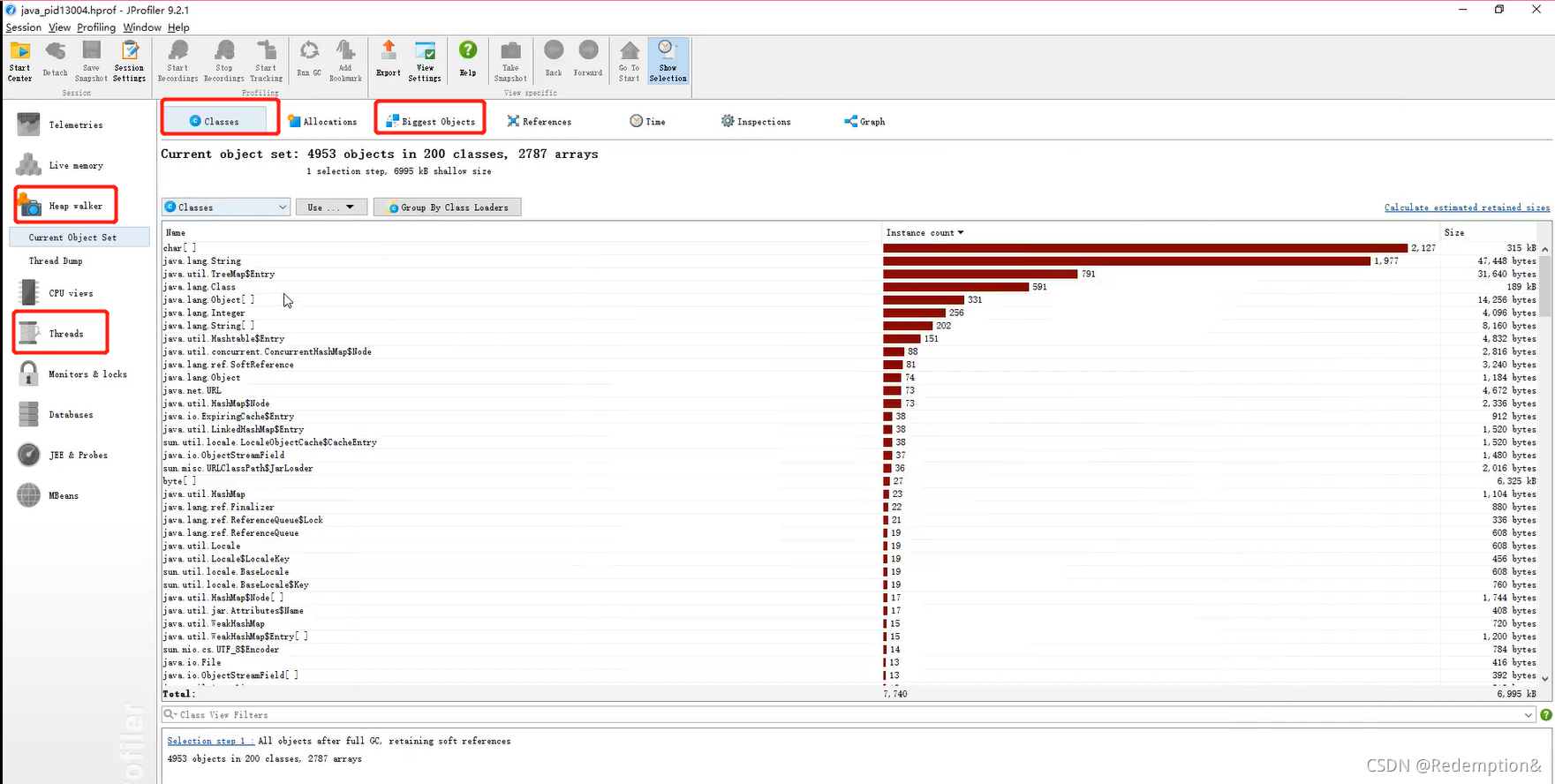
biggest object–Thread Dump–main
15.GC以及常用算法
JVM在进行GC时,并不是对堆中这三个区域统一回收,大部分时候回收都是新生代
GC:垃圾分代收集算法
- 轻GC:
- 重GC:全局GC

GC题目:
- JVM的内存模型和分区,详细到每个区放什么?
- 堆里面的分区有哪些?Eden、from、to、老年区、说说他们的特点
- GC算法有哪些?标记清除法、标记压缩、复制算法,引用计数器(比较少)怎么用?
- 轻GC和重GC分别在什么时候发生?
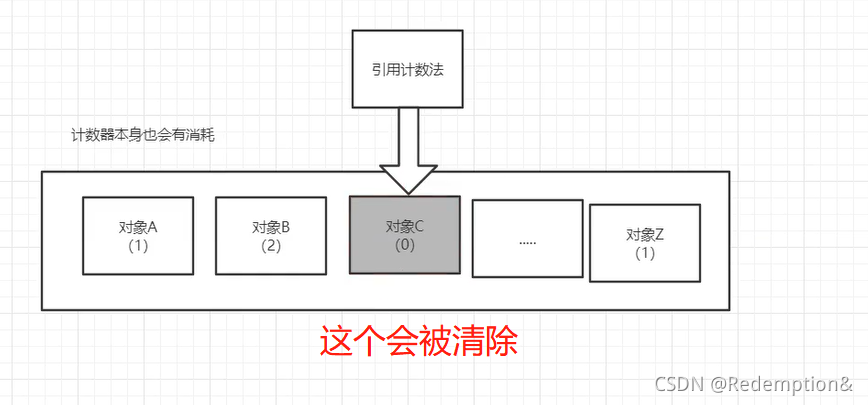
引用计数法:
JVM一般不会采用这种方式,不高效,计数器繁琐,一个大项目有很多对象
复制算法:
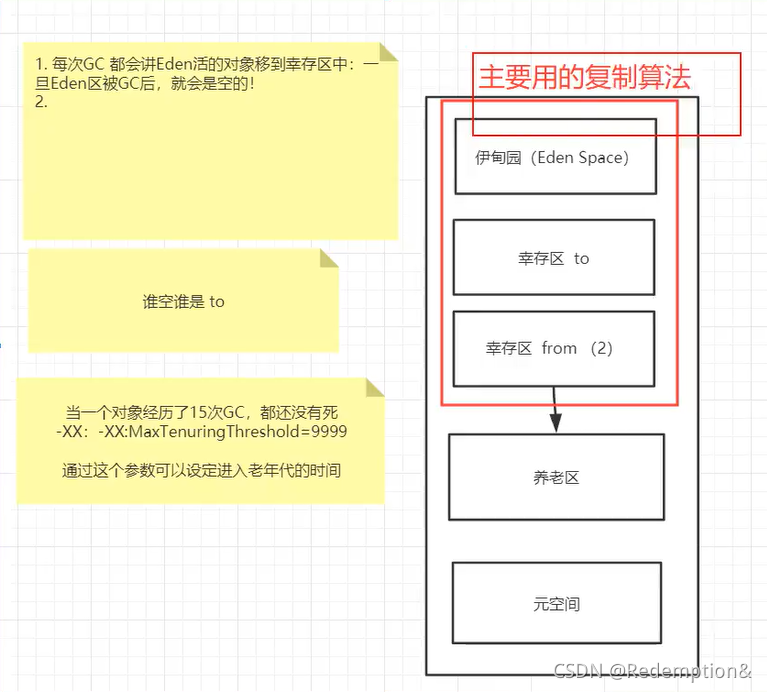
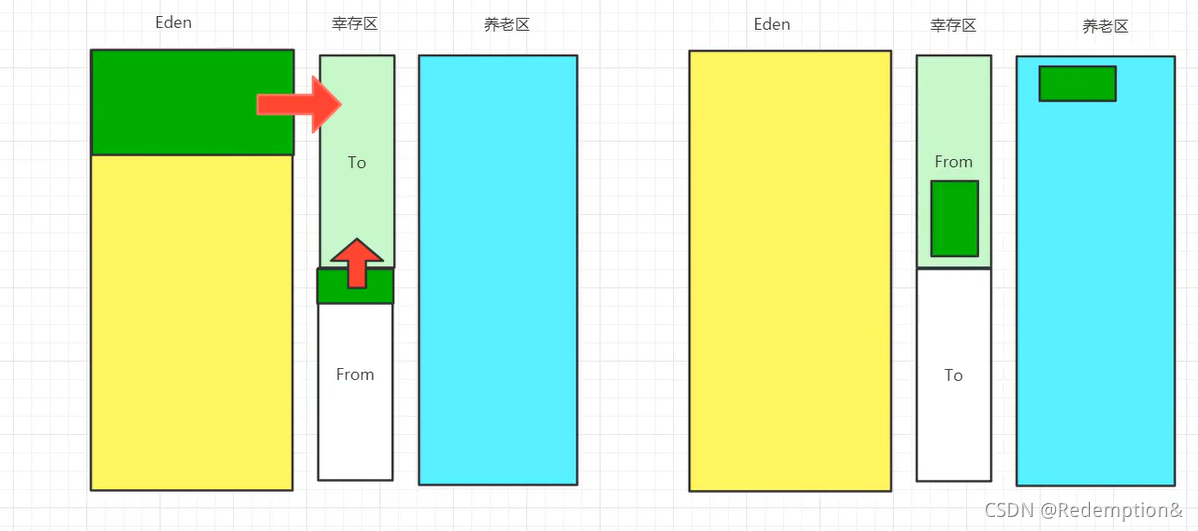
- 好处:没有内存的碎片
- 坏处:浪费了内存空间,多了一半空间永远是空的(浪费一个幸存区)
- 极端情况下:
- 假设对象100%存活,把所有拷贝到幸存区,所有地址重新做一遍
- 假设from区是满的,全部复制到to区,成本很高。
- 复制算法最佳使用场景:对象存活度较低的时候(新生区)
标记清除算法:
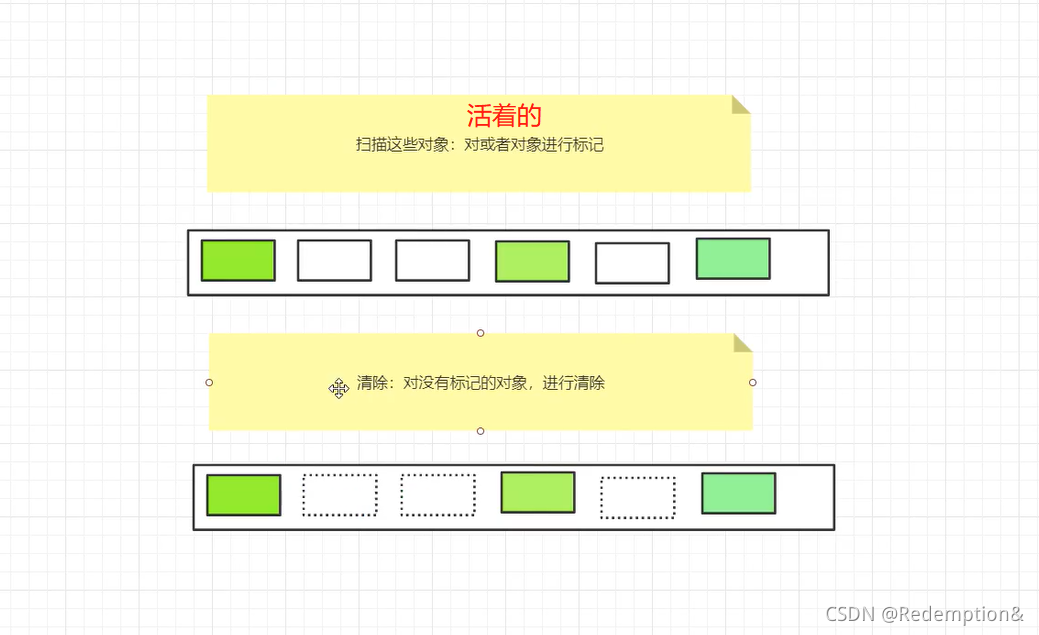
缺点:两次扫描,严重浪费时间,会产生内存碎片
优点:不需要额外的空间
标记压缩算法:
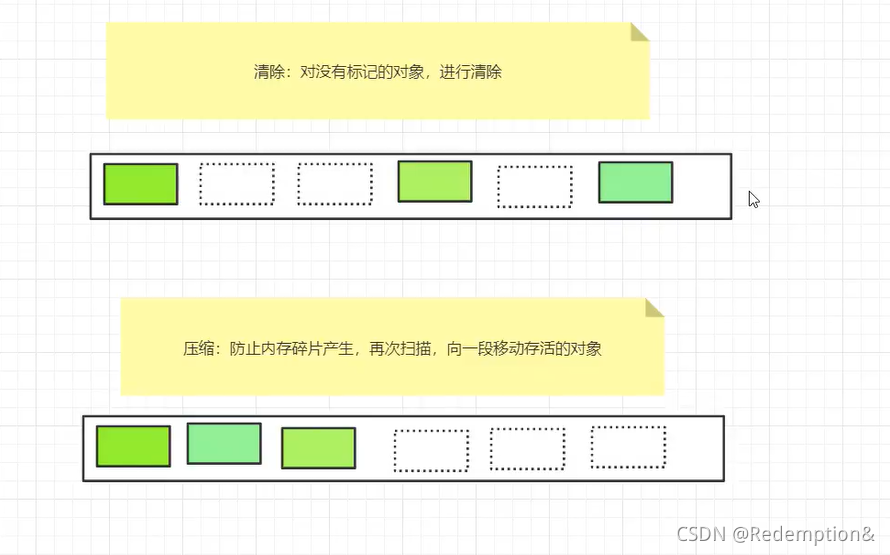
优点:再次扫描,向一端移动存活的对象,防止内存碎片产生
缺点:又多了一次扫描成本
总结
- 内存效率:复制算法>标记清除算法>标记压缩算法(时间复杂度)
- 内存整齐度:复制算法=标记压缩算法>标记清除算法
- 内存利用率:标记压缩算法=标记清除算法>复制算法
思考一个问题:难道没有最优算法吗?
答案:没有,没有最好的算法,只有最合适的算法 —>( GC:分代收集算法)
- 分代收集算法:
- 年轻代:存活率低(复制算法)!
- 老年代:区域大,存活率高(标记清除 (内存碎片不是太多) + 标记压缩混合实现
一天时间学JVM,不现实,要深究,必须要下去花时间,和多看面试题,以及《深入理解JVM》
但是,我们可以掌握一个学习JVM的方法~
16.JMM
1、什么是JMM?
JMM:(Java Memory Model的缩写):Java内存模型【百度百科】
2、它干嘛的?
官方,其他人的博客,对应的视频!
作用:缓存一致性协议,用于定义数据读写的规则 (遵守,找到这个规则)。
JMM定义了线程工作内存和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),是从主内中拷贝的。
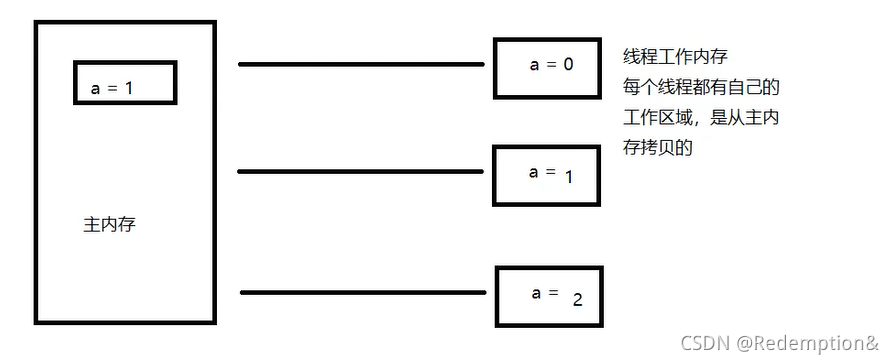
解决共享对象可见性这个问题: volilate;一旦刷新了就会很快的同步到主内存中。
3、它该如何学习?
JMM:抽象的概念,理论
JMM对这八种指令的使用,制定了如下规则:
-
不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write;
-
不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存;
-
不允许一个线程将没有assign的数据从工作内存同步回主内存;
-
一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过assign和load操作;
-
一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁;
-
如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值;
-
如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量;
-
对一个变量进行unlock操作之前,必须把此变量同步回主内存
JMM对这八种操作规则和对volatile的一些特殊规则就能确定哪里操作是线程安全,哪些操作是线程不安全的了。但是这些规则实在复杂,很难在实践中直接分析。所以一般我们也不会通过上述规则进行分析。更多的时候,使用java的happen-before规则来进行分析。
搜索:JMM面试题
17.总结
学习新东西是常态:
- 如何针对面试学习。
- 如何针对技术学习。
针对面试学习:3/10–pass,总结面经,分析这10,再触类旁通一下:百度面试题
通过大量的面试总结,得出一套解题思路;
学习方式:在线画图网站推荐搜索
https://www.processon.com/popular?criterion=jvm
百度:JVM参数(调优)+jvm内存的年轻代/老年代/持久代






)

![记录 Parameter with that position [1] did not exist; nested exception is java.lang.IllegalArgumentExce](http://pic.xiahunao.cn/记录 Parameter with that position [1] did not exist; nested exception is java.lang.IllegalArgumentExce)
![[转]简单的动态修改RDLC报表页边距和列宽的方法](http://pic.xiahunao.cn/[转]简单的动态修改RDLC报表页边距和列宽的方法)









