本文介绍一个多视角的3D检测模型:BEVDepth,论文收录于 AAAI2023。在这篇文章中,作者提出了一种新的具有可信深度估计的三维物体检测器。本文提出的BEVDepth通过利用激光雷达显式深度监督来提高图像深度估计的可信度。作者引入了摄像机感知深度估计模块,以增强深度预测能力。此外,针对不精确特征投影带来的副作用,设计了一种新的深度细化模块。此外借助定制的高效体素池化和多帧机制,BEVDepth在nuScenes测试集上实现了60.9%NDS,NDS得分首次达到60%。
论文链接:https://arxiv.org/abs/2206.10092
项目链接:https://github.com/Megvii-BaseDetection/BEVDepth
文章目录
- 1. Introduction
- 2. Delving into Depth Prediction in Lift-splat
- 2.1 Model Architecture for Base Detector
- 2.2 Making Lift-splat work is easy
- 2.3 Making Lift-splat work well is hard
- 3. BEVDepth
- 4. Experiment
1. Introduction
引言部分作者提出了疑问:目前3D检测器学习到的深度估计质量真的能满足精确地3D目标检测要求吗?为了回答这个问题,作者首先可视化了基于Lift-splat检测器学习到的深度(下图所示)。尽管此检测器取得了30 mAP,但是它学到的深度非常差(虚线框中是相对准确的深度预测区域,通常是和地面相邻的区域)。
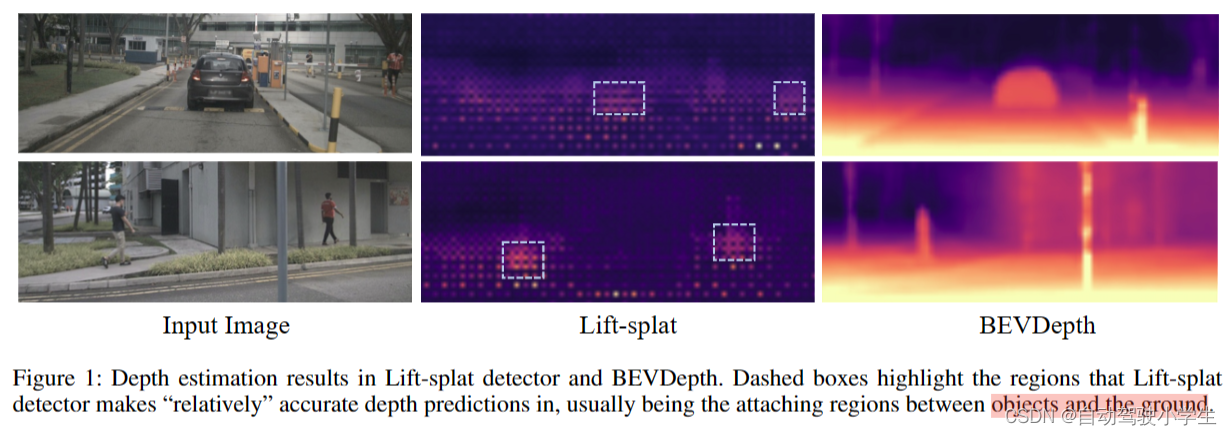
表1中作者将学习到的深度用LiDAR生成的深度来代替,可以看到mAP和NDS提高了20个点左右(0.282/0.470,0.327/0.515),显示了提高深度估计对摄像头3D检测非常关键。

2. Delving into Depth Prediction in Lift-splat
在引言中,作者发现基于LSS的检测器即使深度差得惊人,仍然可以获得合理的3D检测结果。在本节中,作者首先回顾建立在LSS上的基线3D检测器的总体结构。然后,在基线检测器上进行了简单的实验,以揭示为什么观察到前面的现象。最后,讨论了该检测器的三个不足之处,并指出了可能的解决方案。
2.1 Model Architecture for Base Detector
基线检测器使用CenterPoint检测头来代替原始LSS分割头。简单来说它包含4个组成部分:
- 1)图像编码器从 NNN 个图像中提取图像特征,F2d={Fi2d∈F^{2 d}=\left\{F_i^{2 d} \in\right.F2d={Fi2d∈ RCF×H×W,i=1,2,…,N}\left.\mathbb{R}^{C_F \times H \times W}, i=1,2, \ldots, N\right\}RCF×H×W,i=1,2,…,N} 。
- 2) 深度网络从图像特征中估计图像深度,Dpred={Dipred∈D^{pred}=\left\{D_i^{pred} \in\right.Dpred={Dipred∈ RCD×H×W,i=1,2,…,N}\left.\mathbb{R}^{C_D \times H \times W}, i=1,2, \ldots, N\right\}RCD×H×W,i=1,2,…,N},其中 CDC_DCD 表示深度区间个数。
- 3)视觉转换,将2D图像转换到3D空间,然后池化转为BEV特征,Fi3d=Fi2d⊗Dipred ,Fi3d∈RCF×CD×H×WF_i^{3 d}=F_i^{2 d} \otimes D_i^{\text {pred }}, \quad F_i^{3 d} \in \mathbb{R}^{C_F \times C_D \times H \times W}Fi3d=Fi2d⊗Dipred ,Fi3d∈RCF×CD×H×W。
- 4)3D检测头预测物体类别,3D box尺寸位置和其它属性。
2.2 Making Lift-splat work is easy
这里作者首先用一个随机初始化的张量替换 DpredD^{pred}Dpred,并在训练和测试阶段冻结它。结果如表1所示,用随机soft值替换 DpredD^{pred}Dpred 后,mAP仅下降3.7%(从28.2%降至24.5%)。即使特征深度灾难性地被破坏,深度分布的soft性质在一定程度上仍然有助于投影到正确的深度位置。
进一步将soft随机深度替换为hard随机深度,观察到有6.9%的降幅。这表明只要正确位置的深度有激活,检测头就可以工作。这也解释了为什么在图1中的大多数区域学习到的深度较差,但仍然有一定的检测mAP。



![【Python学习】 - - 链表推导式[ 2*x for x in X ]、匿名函数、并行迭代](https://img-blog.csdnimg.cn/20200219203905935.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxMjg5OTIw,size_16,color_FFFFFF,t_70)